Première réflexion au sujet d’un IEML_GPT à venir.

Rappel : ” Je travaille dans une perspective d’intelligence artificielle dédiée à l’augmentation de l’intelligence collective. J’ai conçu IEML pour servir de protocole sémantique, permettant la communication des significations et des connaissances dans la mémoire numérique, tout en optimisant l’apprentissage automatique et le raisonnement automatique.”
Pour tout savoir sur IEML, l’article scientifique définitif : https://journals.sagepub.com/doi/10.1177/26339137231207634
L’article scientifique sur IEML en français:
https://journals.openedition.org/revuehn/3836
Au sujet du GPT Builder : https://help.openai.com/en/articles/8554397-creating-a-gpt
VISION
Imaginons un dispositif destiné au partage des connaissances et qui tire le maximum des possibilités techniques contemporaines. Au cœur de ce dispositif évolue un écosystème ouvert de bases de connaissances catégorisées en IEML, qui émergent d’une multitude de communautés de recherche et de pratique. Entre ce noyau de bases de connaissances interopérables et les utilisateurs humains vivants s’interpose une interface neuronale (un écosystème de modèles) « no code » qui donne accès au contrôle, à l’alimentation, à l’exploration et à l’analyse des données. Tout se passe de manière intuitive et directe, selon les modalités sensorimotrices sélectionnées. C’est aussi par l’intermédiaire de ce giga-perceptron – un métavers immersif, social et génératif – que les collectifs échangent et discutent les modèles de données et réseaux sémantiques qui organisent leurs mémoires. En bonne gestion des connaissances, le nouveau dispositif de partage des savoirs favorise l’enregistrement des créations, accompagne les parcours d’apprentissage et présente les informations utiles aux acteurs engagés dans leurs pratiques. Le modèle IEML_GPT évoqué ici se veut un premier pas dans cette direction.
Maintenant que l’IA a été déchaînée sur Internet et qu’elle se couple aux médias sociaux, il nous faut apprivoiser et harnacher le monstre. Comment rendre l’IA raisonnable? Comment faire en sorte qu’elle « comprenne » ce qu’on lui dit et ce qu’elle nous dit, plutôt que de seulement calculer les probabilités d’apparition des mots à partir des données d’entraînement? Il faudrait lui apprendre le sens des mots et des phrases de telle sorte qu’elle (l’IA) se fasse une représentation abstraite *compréhensible pour elle* non seulement du monde physique (je laisse la tâche à Yann LeCun), mais aussi une représentation du monde humain et, plus généralement, du monde des idées.
En d’autres termes, comment greffer des capacités de codage et décodage symbolique sur un modèle neuronal qui ne peut au départ que reconnaître et générer des formes sensibles ou des agrégats de signifiants? Ce défi rappelle le processus de l’hominisation – quand des réseaux de neurones biologiques sont devenus capables de manipuler des systèmes symboliques – ce qui n’est pas pour me déplaire.
COMPRÉHENSION / CONNAISSANCE / INTEROPÉRABILITÉ
Comprendre une phrase, c’est l’inclure dans la dynamique auto-définitionnelle d’une langue, et cela avant même de saisir la référence extralinguistique de la phrase. L’IA comprendra ce qu’on lui dit lorsqu’elle sera capable de transformer automatiquement une chaîne de caractères en un réseau sémantique qui plonge dans la boucle auto-référentielle et auto-définitoire d’une langue. Le dictionnaire d’une langue, avec ses définitions, est un élément crucial de cette boucle. De même qu’une déduction représente en fin de compte une tautologie logique, le dictionnaire d’une langue exhibe une *tautologie sémantique*. C’est pourquoi IEML_GPT doit contenir un fichier avec le dictionnaire IEML-français-anglais (et peut-être d’autres langues) avec l’ensemble des relations entre les mots sous forme de phrases IEML. Le dictionnaire est une méta-ontologie qui est la même pour tous les utilisateurs. D’autres fichiers pourront contenir des modèles locaux ou ontologies correspondant aux écosystèmes de pratiques des communautés d’utilisateurs.
1) Compréhension linguistique. Les agents raisonnables sont capables de reconnaître et de générer des séquences de caractères IEML syntaxiquement valides, notamment au moyen d’un parseur. Ils ont une compréhension d’IEML : ils reconstituent les arbres syntagmatiques récursivement enchâssés et les relations entre concepts qui découlent du dictionnaire et des matrices paradigmatiques (ou groupes de substitution) qui organisent les concepts. Chaque concept (représenté par un mot ou une phrase IEML) se trouve ainsi au centre d’une étoile de relations syntaxiques et sémantiques.
2) Connaissance des domaines pratiques. Les agents raisonnables sont animés par des bases de connaissances qui leur permettent de comprendre (localement) le monde où ils sont amenés à intervenir. Ils disposent de modèles (ontologies ou graphes de connaissances en IEML) des situations pratiques auxquelles leurs utilisateurs sont confrontés. Ils sont capables de raisonner à partir de ces modèles. Ils sont capables de rapporter les données qu’ils acquièrent et les questions qu’on leur pose à ces modèles.
3) Interopérabilité sémantique. Les agents raisonnables partagent la même langue (IEML) et donc se comprennent entre eux. Ils peuvent s’échanger des modèles ou des sous-modèles. Ils transforment les expressions en langues naturelles en IEML et les expressions IEML en langues naturelles : ils peuvent donc comprendre les humains et se faire comprendre d’eux.
TÂCHE 1 : LE DICTIONNAIRE
1.0 Je dispose déjà d’environ trois mille mots du dictionnaire organisés en paradigmes, d’une grammaire formelle, d’un parseur pour valider les phrases et de fonctions pour générer des paradigmes.
1.1 La première étape consiste à créer des concepts-phrases pour exprimer les *ensembles de mots* (familles lexicales et champs sémantiques) que sont les paradigmes, leurs colonnes, leurs rangées, etc. Appelons les concepts définissant ces ensembles de mots des « concepts lexicaux ». Les mots d’une même famille lexicale ont des traits syntaxiques communs et appartiennent souvent aux mêmes paradigmes-racines. Ils devront être créés systématiquement au moyen de paradigmes.
Il me faut trouver les moyens de générer les paradigmes de concepts lexicaux automatiquement en langue naturelle avec IEML_GPT plutôt qu’au moyen de l’éditeur actuel qui n’est pas facile à utiliser.
1.2 La seconde étape consiste à créer toutes les « propositions analytiques » qui définissent les mots du dictionnaire et explicitent leurs relations au moyen de mots et de concepts lexicaux. Par exemple : « Une montagne est plus grande qu’une colline » ; « La sociologie appartient aux sciences humaines ». Les propositions analytiques de ce type sont toujours vraies et définissent une méta-ontologie. Il faudra donc créer les paradigmes des *relations du dictionnaire*. Et les faire générer par IEML_GPT à partir d’instructions en langues naturelles.
1.3 Toutes les relations internes au dictionnaire, matérialisées par des liens hypertextes, sont créés par des phrases. Sur le plan de l’interface utilisateur, cela revient à créer des liens hypertexte internes au dictionnaire (entre les mots et les concepts lexicaux) de telle sorte que leurs relations grammaticales soient les plus claires possibles. Le document dictionnaire-hypertexte doit également être généré automatiquement par IEML_GPT.
Pour chaque mot, on obtiendra une liste (une « page? ») de phrases justes contenant le mot. Cette liste sera organisée par rôle grammatical : mot défini en rôle de racine, mot défini en rôle d’objet, etc.
Ces phrases serviront non seulement à définir les mots, mais aussi à commencer à accumuler des exemples, voire des données d’entraînement, avec la correspondance entre phrases IEML formelles et traductions littéraires en français et en anglais. En somme, le premier produit fini sera un dictionnaire complet, avec mots, concepts lexicaux et relations d’inter-définition sous forme hypertextuelle, le tout en IEML, anglais et français.
TÂCHE 2 : L’ÉDITEUR D’ONTOLOGIES
La tâche 1 aura permis de tester les meilleurs moyens de créer des paradigmes au moyen de consignes en langues naturelles, voire au moyen de formulaires permettant de mâcher le travail des concepteurs d’ontologies.
L’output de l’éditeur d’ontologie pourra être en RDF, JSON-LD, ou sous forme d’un document hypertexte. On peut aussi imaginer un document multimédia interactif : tables, arbres, réseaux de concepts explorables, illustrations verbales/sonores…
Idéalement, l’ontologie créée devrait contenir nativement un moteur d’inférence et donc supporter le raisonnement automatique. La propriété intellectuelle des créateurs d’ontologies devra être reconnue.
IEML_GPT sera capable de faire fonctionner n’importe quelle ontologie ou ensemble d’ontologies IEML.
TÂCHE 3 LA CATÉGORISATION AUTOMATIQUE
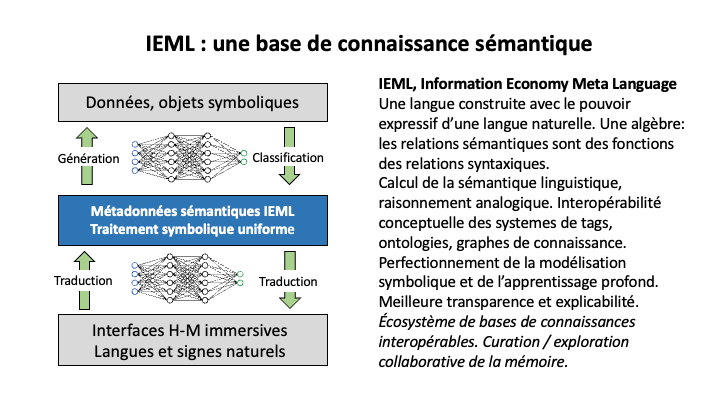
L’étape suivante devra viser la construction d’un outil intégré de catégorisation automatique de données en IEML. On donne à l’IA un jeu de données et une ontologie IEML (idéalement sous forme de fichier de référence) et le résultat est un ensemble de données catégorisées selon les termes de l’ontologie. L’exécution de la tâche 3 ouvre la voie à la création d’un écosystème de bases de connaissances tel que décrit dans la vision plus haut et la figure ci-dessous.
Toutes ces étapes devront être d’abord réalisées « en petit » (preuves de concepts et méthode agile) avant de l’être intégralement.