L’intelligence collective nous précède, nous excède et nous succède.
Elle nous précède : nous avons reçu nos langues et nos savoirs. Nos savoir-faire et nos outils nous ont été transmis. Les idéaux qui nous animent mobilisaient déjà les générations antérieures. Les paysages, les villes où nous évoluons ont été construits par d’autres. Les bibliothèques (matérielles ou virtuelles) où nous apprenons ont été rédigées par d’innombrables auteurs qui s’entrelisaient. Le propre de l’apprentissage est de s’abreuver à la mémoire collective et, à l’heure où les sources numériques sont abondantes, le rôle des enseignants est plus que jamais de donner soif.
L’intelligence collective nous excède car chacun de nous ne dispose directement que d’une toute petite partie des savoirs, des compétences et des vertus (savoir-être) qui font vivre le monde contemporain. D’où la nécessité de la collaboration et de l’ouverture à l’autre qui doivent être pratiquées et valorisées dès la phase d’apprentissage scolaire. De plus, l’apprentissage est une entreprise essentiellement sociale. Cela non seulement parce que la camaraderie de l’effort en commun soutient l’entraide et l’enthousiasme, mais aussi parce que chacun possède une expérience, une compréhension, un point de vue original qui peut illuminer les autres et éclairer leurs angles morts. Le dialogue pédagogique doit être non seulement vertical (maître / élève) mais aussi horizontal (entre élèves… et entre enseignants!). On peut concevoir le rôle de l’enseignant comme un animateur de l’intelligence collective de ses étudiants. J’ai moi-même utilisé les médias sociaux en classe pour stimuler l’apprentissage en intelligence collective. Une expérience enrichissante pour tout le monde!
L’intelligence collective nous succède : après avoir (presque) tout reçu, à notre tour de transmettre ce que nos parcours scolaire, professionnel et existentiel nous ont appris, en adaptant nos acquis aux besoins variés et aux nouvelles circonstances de nos interlocuteurs et de nos collaborateurs. D’ailleurs, on n’apprend jamais aussi bien une matière que lorsqu’on doit l’enseigner. S’adresser à l’autre ou déposer un élément d’expertise dans une mémoire collective nous oblige à clarifier des concepts implicites, à systématiser un savoir empirique, à décontextualiser le contenu d’une expérience. Ce faisant, nous permettrons à la connaissance de circuler et à nos destinataires connus ou inconnus de se l’approprier plus facilement. Encore une autre façon de participer à l’intelligence collective.
Une fois posé le socle de l’intelligence collective, passons à l’intelligence artificielle pour l’apprentissage. Il faut d’abord caractériser correctement l’intelligence artificielle générative contemporaine (ChatGPT, Claude, Gemini, Grok, Perplexity, etc.). Plutôt qu’une intelligence mécanique « autonome » c’est en réalité une compression statistique de l’immense mémoire numérique qui a servi à son entrainement. L’IA doit être considérée comme une mobilisation de la mémoire collective au bénéfice de ses usagers. C’est une manifestation de l’intelligence collective passée et contemporaine. En d’autres termes, l’IA est une interface numérique entre l’intelligence collective accumulée et l’intelligence vivante.
Sur un plan pédagogique, je crois qu’il faut désormais inclure l’IA dans nos scénarios pédagogiques – y compris au niveau de l’évaluation. Elle a un rôle à jouer dans l’intelligence collective du groupe classe, en dialogue ouvert avec le professeur et les étudiants. L’IA peut servir d’interlocuteur dans des débats où les élèves travaillent en apprentissage collaboratif. Elle peut aider à compiler et structurer les idées générées collectivement, à organiser les contributions individuelles en un document cohérent que le groupe critique et améliore ensemble. L’IA ne doit pas remplacer les interactions humaines, il faut plutôt l’utiliser comme catalyseur pour enrichir la réflexion collective et approfondir les apprentissages.
Sur le plan de la philosophie de l’éducation, Il s’agit de ne jamais négliger d’enrichir les mémoires personnelles des étudiants. Ce n’est pas parce que “tout” se trouve sur internet que nous devons cesser de cultiver notre mémoire individuelle, qui est le fondement de la pensée vivante. La pensée critique se tisse en effet dans une dialectique entre la mémoire collective (mobilisée aujourd’hui par l’IA), la mémoire personnelle de chacun d’entre nous et le dialogue ouvert – contradictoire et complice – avec nos pairs et contemporains. Plus riche est notre mémoire personnelle et mieux nous pouvons exploiter les ressources de l’IA, poser les bonnes questions, repérer les hallucinations, éclairer les impensés. En aucun cas l’IA ne peut se substituer à la lecture de « vrais » textes (dont les auteurs sont humains) et encore moins à l’ignorance. Mais elle peut servir de conseillère et d’entraîneuse infatigable pour nos apprentissages. Ignorants, nous serons manipulés et induits en erreur par les modèles de langue. Par contraste, plus nous sommes savants et mieux nous pouvons maîtriser une IA qui, ne nous y trompons pas, devient l’environnement technique de la pensée, le nouveau sensorium.
Ce texte rend compte de ma communication à l’événement *AI for people summit* [https://ai4people.org/advancing-ethical-ai-governance-summit/] organisé avec le concours de l’Union européenne les 2 et 3 décembre 2025. L’essentiel de mon message est le suivant : oui, il faut se préoccuper d’une IA pour les gens, mais cette préoccupation ne deviendra pertinente et efficace que si l’on n’oublie pas que l’IA est aussi faite par les gens.
L’expression même d’intelligence artificielle nous trompe parce qu’elle sous-entend l’autonomie de la machine. De nombreux facteurs soutiennent et renforcent l’erreur d’attribuer une autonomie aux modèles de langue. L’expérience naïve du dialogue avec des IA donne l’impression qu’elles sont conscientes ; les journalistes rivalisent d’articles sensationnalistes ; les responsables des grandes compagnies d’IA annoncent “l’intelligence artificielle générale” pour demain ; des chercheurs en IA, parmi lesquels certains ont été récompensés par un prix Turing, lancent à un public affolé des prédictions apocalyptiques.
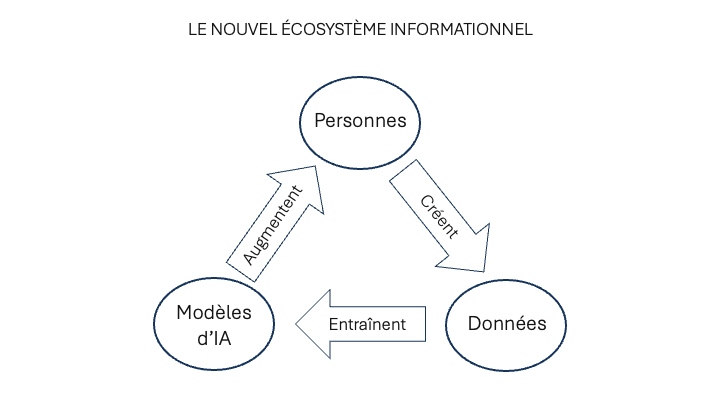
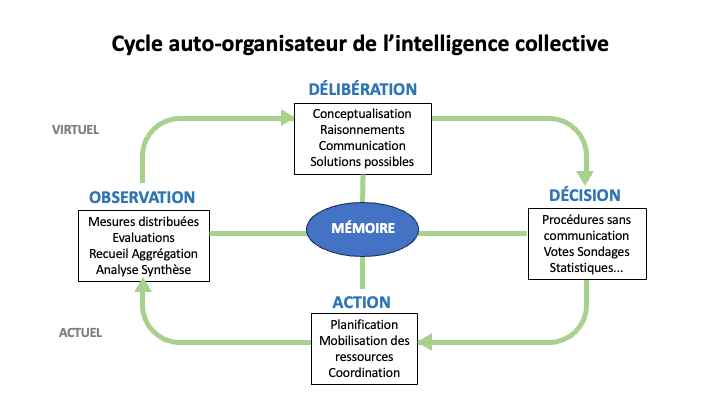
Pour surmonter cette erreur de conceptualisation, j’invite mes lecteurs à cesser de considérer les modèles d’IA en isolation. En réalité, ils ne peuvent être séparés de l’écosystème informationnel auquel ils appartiennent et dont ils dépendent. Cet écosystème peut être décrit comme un circuit à trois stations : les personnes, les données et les modèles. Les personnes créent de l’information, ils alimentent ainsi la mémoire numérique, dont les données entraînent les modèles, qui augmentent les capacités de création d’information des personnes, qui alimentent la mémoire et ainsi de suite. Dans cet écosystème informationnel, l’IA permet de mobiliser l’intelligence collective réifiée dans la mémoire numérique au service des personnes vivantes, qui peuvent contribuer à enrichir la masse des données accumulées. L’accès à la mémoire passe désormais par une IA qui la filtre, la distille et la rend opératoire en fonction des besoins particuliers des utilisateurs. Telle est du moins la version optimiste que je défends. Mais cette approche humaniste ne m’empêche pas de remarquer la face d’ombre du nouvel environnement de communication. Beaucoup de réflexions sur l’éthique de l’IA se concentrent sur la production et la réglementation des modèles, ce qui est légitime. Mais on oublie trop souvent la responsabilité des personnes produisant les données – dorénavant la société dans son ensemble.
Afin de rendre ma démonstration plus convaincante, je vais évoquer quelques cas d’empoisonnement des données particulièrement impressionnants. Plusieurs rapports récents font état d’une entreprise de propagande pro-russe d’abord nommée “Portal Kombat” et intitulée aujourd’hui “Pravda”. Il s’agit d’un réseau de plus de 150 sites web qui se présentent comme des diffuseurs d’information anodins, mais qui répètent constamment les éléments de langage du Kremlin. Les sites sont localisés dans tous les continents et leurs textes sont traduits dans des douzaines de langues, ce qui les rend plus crédibles selon les critères adoptés par les producteurs des modèles d’IA. En moyenne, ce réseau publie 20 273 articles toutes les 48 heures, soit environ 3,6 millions d’articles par an. La production et la traduction des textes est presque entièrement automatisée. Le but n’est pas d’avoir des lecteurs humains (il y en a relativement peu) mais de servir de données d’entraînement pour les IA et donc, par leur intermédiaire, de manipuler leurs utilisateurs. Une étude a établi que les principaux modèles probabilistes tels que ChatGPT d’OpenAI, le Chat de Mistral, Copilot de Microsoft’ Meta AI, Claude d’Anthropic, Gemini de Google et Perplexity AI régurgitent ou confirment les informations fournies par le réseau Pravda dans plus d’un tiers des cas, ce qui n’est déjà pas si mal du point de vue des “mesures actives” russes. Souvenons-nous que, pour Gœbbels, la propagande était basée sur la répétition, la simplicité et l’émotion. Avec les LLM, pas besoin de démonstration, de preuve, de faits, de contextualisation. La répétition et la simplicité fonctionnent parfaitement, il suffit que deux mots soient souvent associés dans les données d’entrainement pour qu’ils le soient aussi dans les réponses de l’IA.
Au lieu de se reposer sur des données éparpillées sur le Web, ne faudrait-il pas plutôt prioriser les données objectives et fiables que l’on trouve dans les revues scientifiques, les encyclopédies et les médias classiques? Et, en effet, Wikipédia est l’une des sources réputées les plus fiables par les responsables des modèles de langue. Or un grand nombre d’articles de Wikipédia ont fait l’objet d’une prise de contrôle par les islamistes et les défenseurs du Hamas, qui ont coordonné leur action en utilisant à leur profit les règles de fonctionnement de l’encyclopédie en ligne. Les choses sont allées si loin que les fondateurs de Wikipédia, Jimmy Wales et Larry Sanger s’en sont inquiétés publiquement. Mais rien n’y fait : authentifié par l’encyclopédie, le point de vue islamiste est maintenant gravé dans les modèles de langue. Une enquête diligentée par la BBC, un média de référence, déplore que les actualités soient mal représentées dans 45% des cas par les intelligences artificielles et que la moitié des jeunes gens (moins de 35 ans) croient à leur exactitude et n’éprouvent pas le besoin de vérifier leur contenu. La BBC pointe un doigt accusateur vers les assistants IA et s’insurge contre l’idée que les erreurs et la désinformation proviendraient des fournisseurs de nouvelles officiels. Hélas, quelques mois plus tard, le directeur général et la directrice de l’information de la BBC étaient obligés de démissionner à la suite d’un scandale de fabrication de fausses nouvelles sur Donald Trump et d’un rapport faisant état d’un biais islamiste systématique dans les émissions de la BBC en arabe. Dans le cas du réseau “Pravda” je mentionnais la théorie de la propagande de Gœbbels basée sur la répétition. Dans le cas de Wikipedia et de la BBC, il faudrait faire appel à une autre théorie de la propagande du 20e siècle, celle d’Edward Bernays, selon qui la manière la plus efficace de convaincre le public était de passer par les leaders d’opinion et les figures d’autorité. Au sujet d’une scientificité garantie par l’Université, souvenons-nous que l’Université allemande (et une bonne part de l’université mondiale) était raciste dans les années trente du 20ᵉ siècle et que l’Université soviétique a entretenu la doctrine anti-génétique de Lyssenko pendant des décennies. N’est-il pas possible que certaines doctrines – notamment dans les sciences humaines – qui se trouvent aujourd’hui majoritaires dans les universités soient considérées avec commisération par nos successeurs?
Je ne me livrerai pas ici à un exposé sur toutes les techniques dites d’empoisonnement des données ni à un avertissement sur les dangers de l’injection de prompts malicieux dans des sources d’information apparemment innocentes. J’espère seulement avoir attiré l’attention du lecteur sur l’importance des données d’entraînement dans la détermination des réponses des AI.
Une fois ce point acquis, il est clair que les problèmes éthiques ne peuvent se limiter aux modèles mais qu’il doivent s’étendre à la création des données qui les entraînent, c’est à dire à l’ensemble de notre comportement en ligne. Chaque lien que nous créons, chaque étiquette que nous apposons à une information, chaque « like », chaque requête, achat, commentaire ou partage et a fortiori chaque article, entrée de blog, podcast ou vidéo que nous postons, toutes ces opérations produisent des données qui vont entraîner les neurones formels des intelligences artificielles. Nous nous concentrons généralement sur la réception directe de nos messages mais il nous faut garder à l’esprit que nous contribuons indirectement – par l’intermédiaire des modèles que nous entraînons – à répondre aux questions de nos contemporains, à rédiger leurs textes, à instruire des élèves, à orienter des politiques, etc. Cette responsabilité est d’autant plus grande que nous nous trouvons dans une position d’autorité et que nous sommes censés dire le vrai, puisque l’IA accorde un plus grand poids aux informations fournies par les journalistes, professeurs, chercheurs scientifiques, rédacteurs de manuels et producteurs de sites officiels.
Revenons pour finir à l’écosystème informationnel contemporain. Supposons que la tendance que l’on voit se dessiner aujourd’hui se confirme dans les années qui viennent. Les IA représentent alors notre principale interface d’accès à la mémoire accumulée et notre premier médium de communication entre humains, puisqu’elles régissent les réseaux sociaux. Dans ce nouvel environnement, les personnes créent les données, qui entraînent les modèles, qui augmentent les personnes, qui créent les données et ainsi de suite le long d’une boucle autogénérative. Cet écosystème fait simultanément office de champ de bataille des récits et de lieu de création et de mise en commun des connaissances ; il oscille entre manipulation et intelligence collective. Dès lors, un des enjeux essentiels reste la formation des esprits. Quelques mots d’ordre éducatifs à l’âge de l’IA : ne pas renoncer à la mémorisation personnelle, s’exercer à l’abstraction et à la synthèse, questionner longuement au lieu de se contenter des premières réponses, replacer toujours les faits dans les multiples contextes où ils prennent sens, prendre la responsabilité des messages que l’on confie à la mémoire numérique et qui contribuent à forger l’esprit collectif.
Q1- Face à l’hyper-connectivité croissante chez les jeunes, de nombreux experts parlent de solitude et de ce qu’ils appellent “l’âge des passions tristes”. Comment voyez-vous cette dichotomie entre proximité et distance que la technologie provoque dans les relations humaines?
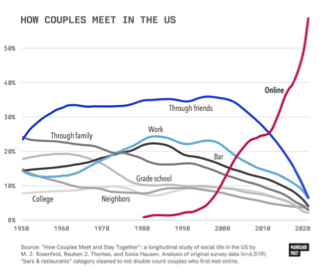
R1 – L’hyper-connectivité ne concerne pas seulement les jeunes, elle est partout. Un des facteurs principaux de l’évolution culturelle réside dans le dispositif matériel de production et de reproduction des symboles, mais aussi dans les systèmes logiciels d’écriture et de codage de l’information. Notre intelligence collective prolonge celle des espèces sociales qui nous ont précédées, et particulièrement celle des grands singes. Mais l’usage du langage – et d’autres systèmes symboliques – tout comme la force de nos moyens techniques nous a fait passer du statut d’animal social à celui d’animal politique. Proprement humaine, la Polis émerge de la symbiose entre des écosystèmes d’idées et les populations de primates parlants qui les entretiennent, s’en nourrissent et s’y réfléchissent. L’évolution des idées et celles des peuplements de Sapiens se déterminent mutuellement. Or le facteur principal de l’évolution des idées réside dans le dispositif matériel de reproduction des symboles. Au cours de l’histoire, les symboles (avec les idées qu’ils portaient) ont été successivement pérennisés par l’écriture, allégés par l’alphabet et le papier, multipliés par l’imprimerie et les médias électriques. Les symboles sont aujourd’hui numérisés et calculés, c’est-à-dire qu’une foule de robots logiciels – les algorithmes – les enregistrent, les comptent, les traduisent et en extraient des patterns. Les objets symboliques (textes, images fixes ou animées, voix, musiques, programmes, etc.) sont non seulement enregistrés, reproduits et transmis automatiquement, ils sont aussi générés et transformés de manière industrielle. En somme, l’évolution culturelle nous a menés au point où les écosystèmes d’idées se manifestent sous la forme de données animées par des algorithmes dans un espace virtuel ubiquitaire. Et c’est dans cet espace que se nouent, se maintiennent et se dénouent désormais les liens sociaux. Avant de critiquer ou de déplorer, il faut d’abord reconnaître les faits. Les amitiés des jeunes gens ne peuvent plus se passer des médias sociaux ; les couples se rencontrent sur internet, par exemple sur des applications comme Tinder (voir la Figure 1) ; les familles restent connectées par Facebook ou d’autres applications comme WhatsApp ; les espaces de travail ont basculé dans l’électronique avec Zoom et Teams, particulièrement depuis la pandémie de COVID ; la diplomatie se fait de plus en plus sur X (ex Twitter), etc. On ne reviendra pas en arrière. D’un autre côté, on ne se déplace pas moins de manière physique : en témoignent les embouteillages monstrueux de Sao Paulo et Rio de Janeiro. Dans le même ordre d’idées, la tendance sur les dix dernières années – époque de croissance exponentielle des connexions Internet – montre aussi une augmentation du nombre de passagers aériens, qui continue une tendance séculaire, et cela malgré une baisse importante durant la pandémie de COVID-19.
Je me sentais bien seul lorsque, jeune étudiant, je suis arrivé à Paris du sud de la France, pour faire mes études universitaires. C’était en 1975 et il n’y avait pas d’internet. Les seniors qui vivent seuls et que leurs enfants ne visitent pas doivent-ils blâmer Internet? Le problème de la solitude et de la désagrégation des liens sociaux est bien réel. Mais c’est une tendance déjà ancienne, qui tient à l’urbanisation, aux transformations de la famille et à bien d’autres facteurs. J’invite vos lecteurs à consulter les nombreux travaux sur la question du “capital social” (la quantité et à la qualité des relations humaines). L’internet n’est qu’un des nombreux facteurs à considérer sur cette question.
Figure 1
Q2- Dans vos livres “Collective Intelligence: For an anthropology of cyberspace” (1994) et “Cyberculture: The Culture of the Digital Society” (1997), vous soutenez qu’Internet et les technologies numériques développent l’intelligence collective, permettant de nouvelles formes de collaboration et de partage des connaissances. Cependant, on craint de plus en plus que l’utilisation excessive des médias sociaux et des technologies numériques soit associée à une distraction et à un retard d’apprentissage chez les jeunes. Comment voyez-vous cette apparente contradiction entre le potentiel des technologies à renforcer l’intelligence collective et les effets négatifs qu’elles peuvent avoir sur le développement cognitif et éducatif des jeunes?
R2- Je n’ai jamais soutenu qu’Internet et les technologies numériques, par eux-mêmes et comme si les techniques étaient des sujets autonomes, développent l’intelligence collective. J’ai soutenu que le meilleur usage que nous pouvions faire d’internet et des technologies numériques était de développer l’intelligence collective humaine, ce qui est bien différent. Et c’est d’ailleurs toujours ce que je pense. L’idée d’un « espace du savoir » qui pourrait se déployer au-dessus de l’espace marchand est un idéal régulateur pour l’action, non une prédiction de type factuel. Lorsque j’ai rédigé L’Intelligence Collective – de 1992 à 1993 – moins de 1% de l’humanité était branchée sur l’Internet et le Web n’existait pas. Vous ne trouverez nulle part le mot « web » dans l’ouvrage. Or nous avons aujourd’hui – en 2024 – largement dépassé les deux tiers de la population mondiale connectée à l’Internet. Le contexte est donc complètement différent mais le changement de civilisation que je prévoyais il y a 30 ans semble évident aujourd’hui, bien qu’il faille attendre normalement plusieurs générations pour confirmer ce type de mutation. A mon sens, nous ne sommes qu’au commencement de la révolution numérique.
Quant à l’augmentation de l’intelligence collective, de nombreux pas ont été franchis pour mettre les connaissances à la portée de tous. Wikipédia est l’exemple classique d’une entreprise qui fonctionne en intelligence collective avec des millions de contributeurs bénévoles de tous les pays et des groupes de discussion entre experts pour chaque article. Il y a près de sept millions d’articles en anglais, deux millions et demi d’articles en français et plus d’un million d’articles en portugais. Wikipédia est consulté par plusieurs dizaines de millions de personnes par jour et plusieurs milliards par an! Le logiciel libre – maintenant largement adopté et diffusé, y compris par les grandes entreprises du Web – est un autre grand domaine où l’intelligence collective est au poste de commande. Parmi les plus utilisés des logiciels libres citons le système d’exploitation Linux, les navigateurs Mozilla et Chromium, la suite Open Office, le serveur http Apache (qui est le plus utilisé sur Internet), le système de contrôle des versions GIT, la messagerie Signal, et bien d’autres qu’il serait trop long de citer. J’ajoute que les bibliothèques et les musées numérisés, comme les articles scientifiques en accès libre et les sites de type ArXiv.org, sont monnaie courante, ce qui transforme les pratiques de recherche et de communication scientifique. Tout le monde peut aujourd’hui publier des textes sur son blog, des vidéos et des podcasts sur YouTube ou d’autres sites, ce qui n’était pas le cas il y a trente ans. Les médias sociaux permettent d’échanger des nouvelles et des idées très rapidement, comme on le voit par exemple sur LinkedIn ou X (ex Twitter). Internet a donc réellement permis le développement de nouvelles formes d’expression, de collaboration et de partage des connaissances. Beaucoup reste à faire. Nous ne sommes qu’au tout début de la mutation anthropologique en cours.
Bien entendu, il nous faut prendre en compte les phénomènes d’addiction aux jeux vidéos, aux médias sociaux, à la pornographie en ligne, etc. Mais depuis plus de trente ans, la majorité des journalistes, des hommes politiques, des enseignants et de tous ceux qui font l’opinion ne cessent de dénoncer les dangers de l’informatique, puis de l’Internet et maintenant de l’intelligence artificielle. Je ne ferais rien de très utile si j’ajoutais mes lamentations aux leurs. J’essaye donc de faire prendre conscience d’une mutation de civilisation de grande ampleur qu’on n’arrêtera pas et d’indiquer les meilleurs moyens de diriger cette grande transformation vers les finalités les plus positives pour le développement humain. Ceci dit, il est clair que les phénomènes d’addiction trouvent partiellement leur source dans notre dépendance à l’architecture sociotechnique toxique des grandes compagnies du Web, qui utilise la stimulation dopaminergique et les renforcements narcissiques de la communication numérique pour nous faire produire toujours plus de données et vendre plus de publicité. Malheureusement la santé mentale des populations adolescentes est peut-être une des victimes collatérales des stratégies commerciales de ces grandes entreprises oligopolistiques. Comment s’opposer à la puissance de leurs centres de calcul, à leur efficacité logicielle et à la simplicité de leurs interfaces? Il est plus facile de poser la question que d’y répondre. En plus de la biopolitique évoquée par Michel Foucault, il faut maintenant considérer une psychopolitique à base de neuromarketing, de données personnelles et de gamification du contrôle. Les enseignants doivent avertir les étudiants de ces dangers et les former à la pensée critique.
Q3- Avec le phénomène des “bulles connectives”, où les réseaux sociaux ont tendance à renforcer des croyances et des idées préexistantes, limitant les contacts avec des perspectives différentes, comment voyez-vous l’évolution des liens sociaux à mesure qu’Internet et les plateformes numériques continuent de se développer? Ce type de segmentation pourrait-il affaiblir l’intelligence collective que vous prônez, ou y a-t-il encore de la place pour des connexions plus larges et plus collaboratives à l’avenir?
R3 – Il est clair que si l’on se contente de « liker » instinctivement ce que l’on voit défiler et de réagir émotionnellement aux images et aux messages les plus simplistes, le bénéfice cognitif ne sera pas très grand. Je ne me pose pas en modèle à suivre absolument, je voudrais seulement donner un exemple de ce qu’il est possible de faire si l’on un peu d’imagination et que l’on est prêt à remettre en cause l’inertie des institutions. Lorsque j’étais professeur en communication numérique à l’Université d’Ottawa, je forçais mes étudiants à s’inscrire sur Twitter, à choisir une demi-douzaine de sujets intéressants pour eux et à dresser des listes de comptes à suivre pour chaque sujet. Quelque soit le thème – politique, science, mode, art, sports, etc. – ils devaient construire des listes équilibrées comprenant des experts ou des partisans d’avis opposés afin d’élargir leur sphère cognitive au lieu de la restreindre. Sur les médias sociaux les plus courants comme Facebook et LinkedIn, il est possible de participer à un grand nombre de communautés spécialisées dans des domaines culturels (histoire, philosophie, arts) ou professionnels (affaires, technologie, etc.) afin de se tenir au courant et de discuter avec des experts. Les groupes de discussion locaux par villages ou quartiers sont aussi très utiles. Tout est question de méthode et de pratique. Il faut se détacher du modèle des médias de masse (journaux papier, radio, télévision) dans lequel des récepteurs passifs consomment une programmation faite par d’autres. C’est à chacun de se bricoler sa propre programmation et de se construire ses réseaux personnels d’apprentissage.
Avant l’imprimerie, on ne parlait qu’avec les gens de sa paroisse. Dans les années soixante du XXe siècle on n’avait le choix qu’entre deux ou trois chaines de télévision et deux ou trois journaux. Aujourd’hui nous avons accès à une énorme diversité de sources en provenance de tous les pays et de tous les secteurs de la société. Les enseignants doivent alphabétiser les étudiants, leur apprendre les langues étrangères, leur donner une bonne culture générale et les guider dans ce nouvel univers de communication.
Q4- Actuellement, il y a un débat croissant sur les effets négatifs de la technologie sur la santé mentale des jeunes, en mettant l’accent sur des problèmes tels que l’anxiété, la dépression et l’isolement social. Considérant le rôle central que jouent les technologies numériques dans notre société, comment comprenez-vous cette relation entre l’usage intensif des technologies et l’augmentation des problèmes de santé mentale chez les jeunes? Existe-t-il un moyen d’équilibrer les avantages de la technologie avec la nécessité de préserver le bien-être mental?
R4 – Le problème de la santé mentale des jeunes est bien sûr tout à fait réel, mais il serait réducteur de l’attribuer uniquement aux médias sociaux. Néanmoins je vais essayer d’énumérer quelques problèmes psychologiques qui naissent de l’usage des Technologies numériques.
Il y a d’abord la transformation de l’autoréférence subjective, qui risque de mener à des problèmes de type schizophrénique. Notre champ d’expérience est médiatisé par le support numérique : la boucle d’autoréférence est plus large que jamais. Nous interagissons avec des personnes, des robots, des images, des musiques par le biais de plusieurs interfaces multimédias : écran, écouteurs, manettes… Notre expérience subjective est contrôlée par les algorithmes de multiples applications qui déterminent en boucle (si nous n’avons pas appris à les maîtriser) notre consommation de données et nos actions en retour. Notre mémoire est dispersée dans de nombreux fichiers, bases de données, en local et dans le cloud… Lorsqu’une grande partie de nous-mêmes est ainsi collectivisée et externalisée, le problème des limites et de la détermination de l’identité devient prépondérant. À qui appartiennent les données me concernant, qui les produit ?
Le problème du narcissisme est particulièrement évident sur Instagram et les applications même genre. Notre ego est nourri par l’image que les autres nous renvoient dans le médium algorithmique. L’obsession de l’image atteint des proportions inquiétantes. Combien d’abonnés, combien de likes, combien d’impressions? Pour ceux qui ont sombré dans ce gouffre, la valeur de l’être n’est plus que dans le regard de l’autre. Avant d’être un problème de santé mentale il s’agit d’un problème de sagesse élémentaire.
A l’opposé du narcissisme, nous avons une tendance vers l’autisme. Ici le moi est enfermé dans sa vie intérieure, mais alimenté par des sources d’information en ligne. Le code ou certains aspects de la culture populaire deviennent obsessionnels. C’est le domaine des geeks, des Otakus et des joueurs compulsifs. Il est évidemment malsain de se passer de toute vie sociale en chair et en os.
Il existe un problème de santé mentale si les affects sont constamment euphoriques, ou constamment dysphoriques, ou si un objet exclusif devient addictif. En effet, Internet peut nous rendre dépendants à certains objets (actualités, séries, jeux, pornographie) ou à certaines émotions, qu’elles soient positives (contenu « feel-good » de type chats mignons, danse, humour, etc.) ou négatives (actualités catastrophiques, « doom scrolling ») de manière déséquilibrée. On peut aussi se demander dans quelle mesure il est bon que le langage corporel soit entièrement remplacé par des emojis, des mèmes, des images, des avatars, etc.
L’addiction est créée par l’excitation (dopamine) et la satisfaction (endorphine) que nous voulons reproduire sans arrêt. Or, comme je l’ai dit plus haut, les modèles d’affaire des grandes entreprise du web qui sont axés sur l’engagement (sécrétion de dopamine-endorphine) conduisent presque inévitablement à la dépendance si les utilisateurs ne font pas attention. L’intensité d’engagement élevée pendant de trop longs moments mène inévitablement à une dépression.
Le contrôle des impulsions (agressivité, par exemple) est plus difficile dans les médias sociaux que dans la vie réelle parce que nos interlocuteurs ne se trouvent pas en face de nous. La « gestion des comportements toxiques » est d’ailleurs un problème majeur dans les jeux en ligne et les médias sociaux.
En somme, il faut être vigilant, prévenir les jeunes utilisateurs des dangers encourus et ne pas commettre d’excès.
Q5 – Certains prédisent que les générations futures pourraient ne plus jamais fréquenter l’école. Comment voyez-vous l’avenir de l’éducation dans un monde de plus en plus hyperconnecté et dominé par la technologie?
R5 – Je ne crois pas que l’école va disparaître. Mais elle doit se transformer. Il faut prendre les étudiants où ils sont et de préférence utiliser les produits grands public auxquels ils sont habitués pour en faire quelque chose d’utile sur le plan de l’apprentissage. Les élèves sont des « digital natives » mais cela ne veut pas dire qu’ils ont une véritable maîtrise des outils numériques. Il faut non seulement développer la littéracie numérique mais la littéracie tout court, qui en est indissociable. Je suis un grand partisan de la lecture des classiques et de la culture générale, qui est indispensable pour former l’esprit critique.
Pour revenir à mes propres méthodes pédagogiques, dans les cours que je donnais à l’Université d’Ottawa, je demandais à mes étudiants de participer à un groupe Facebook fermé, de s’enregistrer sur Twitter, d’ouvrir un blog s’ils n’en n’avaient pas déjà un et d’utiliser une plateforme de curation collaborative de données.
L’usage de plateformes de curation de contenu me servait à enseigner aux étudiants comment choisir des catégories ou « tags » pour classer les informations utiles dans une mémoire à long terme, afin de les retrouver facilement par la suite. Cette compétence leur sera fort utile dans le reste de leur carrière.
Les blogs étaient utilisés comme supports de « devoir final » pour les cours gradués (c’est-à-dire avant le master), et comme carnets de recherche pour les étudiants en maîtrise ou en doctorat : notes sur les lectures, formulation d’hypothèses, accumulation de données, première version d’articles scientifiques ou de chapitres des mémoires ou thèses, etc. Le carnet de recherche public facilite la relation avec le superviseur et permet de réorienter à temps les directions de recherche hasardeuses, d’entrer en contact avec les équipes travaillant sur les mêmes sujets, etc.
Le groupe Facebook était utilisé pour partager le Syllabus ou « plan de cours », l’agenda de la classe, les lectures obligatoires, les discussions internes au groupe – par exemple celles qui concernent l’évaluation – ainsi que les adresses électroniques des étudiants (Twitter, blog, plateforme de curation sociale, etc.). Toutes ces informations étaient en ligne et accessibles d’un seul clic, y compris les lectures obligatoires numérisées et gratuites. Les étudiants pouvaient participer à l’écriture de mini-wikis à l’intérieur du groupe Facebook sur des sujets de leur choix, ils étaient invités à suggérer des lectures intéressantes reliées au sujet du cours en ajoutant des liens commentés. J’utilisais Facebook parce que la quasi-totalité des étudiants y étaient déjà abonnés et que la fonctionnalité de groupe de cette plateforme est bien rodée. Mais j’aurais pu utiliser n’importe quel autre support de gestion de groupe collaboratif, comme Slack ou les groupes de LinkedIn.
Sur Twitter (maintenant X), la conversation propre à chaque classe était identifiée par un hashtag. Au début, j’utilisais le médium à l’oiseau bleu de manière ponctuelle. Par exemple, à la fin de chaque classe je demandais aux étudiants de noter l’idée la plus intéressante qu’ils avaient retenu du cours et je faisais défiler leurs tweets en temps réel sur l’écran de la classe. Puis, au bout de quelques semaines, je les invitais à relire leurs traces collectives sur Twitter pour rassembler et résumer ce qu’ils avaient appris et poser des questions – toujours sur Twitter – si quelque chose n’était pas clair, questions auxquelles je répondais par le même canal.
Au bout de quelques années d’utilisation de Twitter en classe, je me suis enhardi et j’ai demandé aux étudiants de prendre directement leurs notes sur ce medium social pendant le cours de manière à obtenir un cahier de notes collectif. Pouvoir regarder comment les autres prennent des notes (que ce soit sur le cours ou sur des textes à lire) permet aux étudiants de comparer leurs compréhensions et de préciser ainsi certaines notions. Ils découvrent ce que les autres ont relevé et qui n’est pas forcément ce qui les a stimulés eux-mêmes… Quand je sentais que l’attention se relâchait un peu, je leur demandais de s’arrêter, de réfléchir à ce qu’ils venaient d’entendre et de noter leurs idées ou leurs questions, même si leurs remarques n’étaient pas directement reliées au sujet du cours. Twitter leur permettait de dialoguer librement entre eux sur les sujets étudiés sans déranger le fonctionnement de la classe. Je consacrais toujours la fin du cours à une période de questions et de réponses qui s’appuyais sur un visionnement collectif du fil Twitter. Cette méthode est particulièrement pertinente dans les groupes trop grands (parfois plus de deux cents personnes) pour permettre à tous les étudiants de s’exprimer oralement. Je pouvais ainsi répondre tranquillement aux questions après la classe en sachant que mes explications restaient inscrites dans le fil du groupe. La conversation pédagogique se poursuit entre les cours. Bien entendu, tout cela n’était possible que parce que l’évaluation (la notation des étudiants) était basée sur leur participation en ligne.
En utilisant Facebook et Twitter en classe, les étudiants n’apprenaient pas seulement la matière du cours mais aussi une façon « cultivée » de se servir des médias sociaux. Documenter ses petits déjeuners ou la dernière fête bien arrosée, disséminer des vidéos de chats et des images comiques, échanger des insultes entre ennemis politiques, s’extasier sur des vedettes du show-business ou faire de la publicité pour telle ou telle entreprise sont certainement des usages légitimes des médias sociaux. Mais on peut également entretenir des dialogues constructifs dans l’étude d’un sujet commun. En somme, je crois que l’éducation doit progresser en direction de l’apprentissage collaborative en utilisant les outils numériques.
Q6 – Quelles sont, selon vous, les principales opportunités qu’Internet et les nouveaux outils d’IA peuvent apporter au domaine de l’éducation? Compte tenu de l’avancée accélérée des technologies numériques et de l’intelligence artificielle, comment voyez-vous évoluer le rôle de l’enseignant dans les années à venir?
R6 – Concernant l’intelligence artificielle (par exemple ChatGPT, MetaAI, Grok ou Gemini, qui sont tous gratuits et assez bons), elle peut être fort utile comme mentor des étudiants ou comme encyclopédie de premier recours, pour donner des réponses et des orientations très rapidement. Les étudiants utilisent déjà ces outils, il ne faut donc pas interdire leur usage mais, une fois encore, le cultiver, le faire passer à un niveau supérieur. Comme l’IA générative est de nature statistique et probabiliste, elle fait régulièrement des erreurs. Il faut donc toujours vérifier les informations sur de véritables encyclopédies, des moteurs de recherche, des sites spécialisés ou même… dans une bibliothèque! J’ajoute que plus on est cultivé et mieux on connaît un sujet et plus l’usage des IA génératives est fructueux, car on est alors capable de poser de bonnes questions et de demander des informations complémentaires lorsque l’on sent que quelque chose manque. L’IA n’est pas un substitut à l’ignorance, elle donne au contraire une prime à ceux qui ont déjà de bonnes connaissances.
Utiliser les IA génératives pour rédiger à notre place ou faire des résumés de texte au lieu de lire des livres n’est pas une bonne idée, au moins dans un usage pédagogique. Sauf bien sûr si cette pratique est encadrée par l’enseignant afin de stimuler l’esprit critique et le goût du beau style. Au moins en 2024, les textes de l’IA sont généralement redondants, banals et facilement reconnaissables. De plus, leurs résumés de documents ne parviennent pas à saisir ce qu’il y a de plus original dans un texte, puisqu’ils n’ont pas été entraînés sur des idées rares mais au contraire sur l’avis général que l’on retrouve partout. On apprend à penser en lisant et en écrivant en personne : donc les IA sont de bons auxiliaires mais en aucun cas de purs et simples remplacements de l’activité intellectuelle humaine.
Q-7- On craint de plus en plus que l’IA puisse supprimer de nombreux emplois à l’avenir. Comment pensez-vous que cela affectera le marché du travail et quelles pourraient être les solutions possibles?
Q-7 Du fait même de son nom, l’intelligence artificielle évoque naturellement l’idée d’une intelligence autonome de la machine, qui se pose en face de l’intelligence humaine, pour la simuler ou la dépasser. Mais si nous observons les usages réels des dispositifs d’intelligence artificielle, force est de constater que, la plupart du temps, ils augmentent, assistent ou accompagnent les opérations de l’intelligence humaine. Déjà, à l’époque des systèmes experts – lors des années 80 et 90 du XXe siècle – j’observais que les savoirs critiques de spécialistes au sein d’une organisation, une fois codifiés sous forme de règles animant des bases de connaissances, pouvaient être mis à la portée des membres qui en avaient le plus besoin, répondant précisément aux situations en cours et toujours disponibles. Plutôt que d’intelligences artificielles prétendument autonomes, il s’agissait de médias de diffusion des savoir-faire pratiques, qui avaient pour principal effet d’augmenter l’intelligence collective des communautés utilisatrices.
Dans la phase actuelle du développement de l’IA, le rôle de l’expert est joué par les foules qui produisent les données et le rôle de l’ingénieur cogniticien qui codifie le savoir est joué par les réseaux neuronaux. Au lieu de demander à des linguistes comment traduire ou à des auteurs reconnus comment produire un texte, les modèles statistiques interrogent à leur insu les multitudes de rédacteurs anonymisés du web et ils en extraient automatiquement des patterns de patterns qu’aucun programmeur humain n’aurait pu tirer au clair. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. Bien loin d’être autonome, cette IA prolonge et amplifie l’intelligence collective. Des millions d’utilisateurs contribuent au perfectionnement des modèles en leur posant des questions et en commentant les réponses qu’ils en reçoivent. On peut prendre l’exemple de Midjourney (qui génère des images), dont les utilisateurs s’échangent leurs consignes (prompts) et améliorent constamment leurs compétences. Les serveurs Discord de Midjourney sont aujourd’hui les plus populeux de la planète, avec plus d’un million d’utilisateurs. Une nouvelle intelligence collective stigmergique émerge de la fusion des médias sociaux, de l’IA et des communautés de créateurs. Derrière « la machine » il faut entrevoir l’intelligence collective qu’elle réifie et mobilise.
L’IA nous offre un nouvel accès à la mémoire numérique mondiale. C’est aussi une manière de mobiliser cette mémoire pour automatiser des opérations symboliques de plus en plus complexes, impliquant l’interaction d’univers sémantiques et de systèmes de comptabilité hétérogènes.
Je ne crois pas une seconde à la fin du travail. L’automatisation fait disparaître certains métiers et en fait naître de nouveaux. Il n’y a plus de maréchaux ferrants, mais les garagistes les ont remplacés. Les porteurs d’eau ont fait place aux plombiers. La complexification de la société augmente le nombre des problèmes à résoudre. Les machines « intelligentes » vont surtout augmenter la productivité du travail cognitif en automatisant ce qui peut l’être. Il y aura toujours besoin de gens intelligents, créatifs et compassionnés mais ils devront apprendre à travailler avec les nouveaux outils.
Q-8 Certains auteurs évoquent l’inversion de “l’effet Flynn”, suggérant que les générations futures auront un niveau cognitif inférieur à celui de leurs parents. Comment voyez-vous cet enjeu dans le contexte des technologies émergentes? Pensez-vous que l’usage intensif des technologies numériques puisse contribuer à cette tendance, ou offrent-elles de nouvelles façons d’élargir nos capacités cognitives?
R-8 La baisse du niveau cognitif (et moral), est déplorée depuis des siècles par chaque génération, alors que l’effet Flynn montre justement l’inverse. Il est normal que l’on assiste à une stabilisation des scores de Quotient Intellectuel (QI) : l’espoir d’une augmentation constante n’est jamais très réaliste et il serait normal d’atteindre une limite ou un palier, comme dans n’importe quel autre phénomène historique ou même biologique. Mais admettons que les jeunes gens d’aujourd’hui aient de moins bons scores de QI que les générations qui les précèdent immédiatement. Il faut d’abord se demander ce que mesurent ces tests : principalement une intelligence scolaire. Ils ne prennent en compte ni l’intelligence émotionnelle, ni l’intelligence relationnelle, ni la sensibilité esthétique, ni les habiletés physiques ou techniques, ni même le bon sens pratique. Donc on ne mesure là quelque chose de limité. D’autre part, si l’on reste sur l’adaptation au fonctionnement scolaire que mesurent les tests de QI, pourquoi accuser d’abord les technologies? Peut-être y-t-il démission des familles face à la tâche éducative (notamment parce que les familles se défont), ou bien défaillance des écoles et des universités qui deviennent de plus en plus laxistes (parce que les étudiants sont devenus des clients à satisfaire à tout prix) ? Quand j’étais étudiant, le « A » aux examens n’était pas encore un droit… Il l’est quasiment devenu aujourd’hui.
Finalement, et il faut le répéter sans cesse, « l’usage des technologies numériques » n’a pas grand sens. Il y a des usages abrutissants, qui glissent sur la pente de la paresse intellectuelle, et des usages qui ouvrent l’esprit, mais qui demandent une prise de responsabilité personnelle, un effort d’autonomie et – oui – du travail. C’est le rôle des éducateurs de favoriser les usages positifs.
Q-9 Existe-t-il des frontières claires entre le monde réel et le monde virtuel? Qu’est-ce qui pourrait nous motiver à continuer dans le monde réel alors que le monde virtuel offre des possibilités d’interaction et de réussite quasi illimitées?
R-9 Il n’y a jamais eu de frontière claire entre le monde virtuel et le monde actuel. Où se trouve la présence humaine? Dès que nous assumons une situation dans l’existence, nous nous retrouvons immanquablement entre deux. Entre le virtuel et l’actuel, entre l’âme et le corps, entre le ciel et la terre, entre le yin et le yang. Notre existence s’étire dans un intervalle et la relation fondamentale entre le virtuel et l’actuel est une transformation réciproque. C’est un morphisme qui projette le sensible sur l’intelligible et inversement.
Une situation pratique comprend un contexte actuel : notre posture, notre position, ce qui se trouve autour de nous en ce moment précis, de nos interlocuteurs à l’environnement matériel. Elle implique aussi un contexte virtuel : le passé dans notre mémoire, nos plans et nos attentes, nos idées de ce qui nous arrive. C’est ainsi que nous discernons les lignes de force et les tensions de la situation, son univers de problèmes, ses obstacles et ses échappées. Les configurations corporelles n’ont de sens que par le paysage virtuel qui les entoure.
Nous ne vivons donc pas seulement dans la réalité physique dite « matérielle », mais aussi dans le monde des significations. C’est ce qui fait de nous des humains. Maintenant, si l’on veut parler des médias dits « numériques » , en plus de leur aspect logiciel (les programmes et les données) ils sont évidemment aussi matériels : les centres de données, les câbles, les modems, les ordinateurs, les smartphones, les écrans, les écouteurs sont tout ce qu’il y a de plus matériels et actuels. Par ailleurs, je ne sais pas très bien à quoi vous faites allusion lorsque vous dites que « le monde virtuel offre des possibilités d’interaction et de réussite quasi illimitées ». Les possibilités d’interactions offertes par le médium numérique sont certes plus diverses que celles qui étaient fournies par l’imprimerie ou la télévision, mais elles ne sont en aucun cas « illimitées » puisque le temps disponible n’est pas extensible à l’infini. Ces possibilités dépendent aussi fortement des capacités et de l’environnement culturel et social des utilisateurs. La toute puissance est toujours une illusion. Par ailleurs, si vous voulez dire que la fiction et le jeu (qu’ils soient ou non à support électronique) offrent des possibilités illimitées, oui, c’est une idée qui a sa part de vérité. Maintenant, si vous sous-entendez qu’il est malsain de passer la plus grande partie de son temps à jouer à des jeux vidéo en ligne au détriment de sa santé, de ses études, de son environnement familial ou de son travail, on ne peut qu’être d’accord avec vous. Mais ce sont ici l’excès et l’addiction qui sont en question, avec leurs causes multiples, et pas « le monde virtuel ».
Q-10 Avec les progrès des technologies numériques, le concept d’immortalité numérique émerge, où nos identités peuvent être préservées indéfiniment en ligne. Comment comprenez-vous la relation entre la spiritualité et cette idée d’immortalité numérique?
R-10 Cette fausse immortalité n’a rien à voir avec la spiritualité. Pourquoi ne pas parler d’immortalité calcaire – ou architecturale – face aux pyramides d’Égypte? Une autre comparaison : Shakespeare ou Victor Hugo, voire Newton ou Einstein, sont probablement plus « immortels » qu’une personne dont on n’a pas supprimé le compte Facebook après la mort. S’il faut absolument rapporter le numérique au sacré, je dirais que les centres de données sont les nouveaux temples et qu’en échange du sacrifice de nos données, nous obtenons les bénédictions pratiques des intelligences artificielles et des médias sociaux.
Q-11 De nombreux experts ont souligné les problèmes moraux présents dans l’organisation et la construction de normes basées sur les données rapportées et exploitées par l’IA (préjugés, racisme et autres formes de déterminisme). Comment contrôler ces problèmes dans le scénario numérique? Qui est responsable ou peut être tenu responsable de problèmes de cette nature? L’IA pourrait-elle avoir des implications juridiques?
R-11 On parle beaucoup des « biais » de tel ou tel modèle d’intelligence artificielle, comme s’il pouvait exister une IA non-biaisée ou neutre. Cette question est d’autant plus importante que l’IA devient notre nouvelle interface avec les objets symboliques : stylo universel, lunettes panoramiques, haut-parleur général, programmeur sans code, assistant personnel. Les grands modèles de langue généralistes produits par les plateformes dominantes s’apparentent désormais à une infrastructure publique, une nouvelle couche du méta-médium numérique. Ces modèles généralistes peuvent être spécialisés à peu de frais avec des jeux de données issues d’un domaine particulier et de méthodes d’ajustement. On peut aussi les munir de bases de connaissances dont les faits ont été vérifiés.
Les résultats fournis par une IA découlent de plusieurs facteurs qui contribuent tous à son orientation ou si l’on préfère, à ses « biais ».
a) Les algorithmes proprement dits sélectionnent les types de calcul statistique et les structures de réseaux neuronaux.
b) Les données d’entraînement favorisent les langues, les cultures, les options philosophiques, les partis-pris politiques et les préjugés de toutes sortes de ceux qui les ont produites.
c) Afin d’aligner les réponses de l’IA sur les finalités supposées des utilisateurs, on corrige (ou on accentue!) « à la main » les penchants des données par ce que l’on appelle le RLHF (Reinforcement Learning from Human Feed-back – en français : apprentissage par renforcement à partir d’un retour d’information humain).
d) Finalement, comme pour n’importe quel outil, l’utilisateur détermine les résultats au moyen de consignes en langue naturelle (les fameux prompts). Comme je l’ai dit plus haut, des communautés d’utilisateurs s’échangent et améliorent collaborativement de telles consignes. La puissance de ces systèmes n’a d’égal que leur complexité, leur hétérogénéité et leur opacité. Le contrôle règlementaire de l’IA, sans doute nécessaire, semble difficile.
La responsabilité est donc partagée entre de nombreux acteurs et processus, mais il me semble que ce sont les utilisateurs qui doivent être tenus pour les responsables principaux, comme pour n’importe quelle technique. Les questions éthiques et juridiques reliées à l’IA sont aujourd’hui passionnément discutées un peu partout. C’est un champ de recherche académique en pleine croissance et de nombreux gouvernements et organismes multinationaux ont émis des lois et règlement pour encadrer le développement et l’utilisation de l’IA.
Aujourd’hui, le monde entier se précipite vers l’IA statistique, les modèles neuronaux et/ou l’IA générative. Mais nous savons que, bien que ces modèles soient utiles, nous avons toujours besoin de modèles symboliques ou, si vous préférez, de graphes de connaissances, en particulier dans le domaine de la gestion des connaissances.
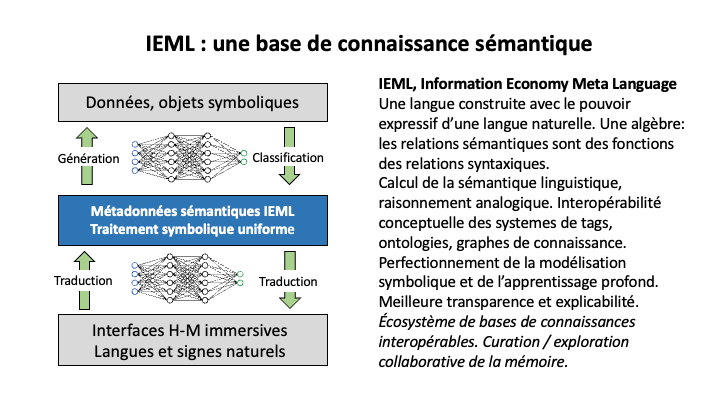
Mais pourquoi exactement avons-nous encore besoin de modèles symboliques en plus des modèles neuronaux ? Parce que les modèles symboliques sont capables de représenter la connaissance de manière explicite, ce qui comporte beaucoup d’avantages, notamment la transparence et l’explicabilité. Dans cet exposé, je vais plaider en faveur de l’interopérabilité sémantique (ou conceptuelle) entre les graphes de connaissances, et je présenterai IEML, un langage que j’ai inventé à la Chaire de Recherche du Canada en intelligence collective (2002-2016) avec l’aide de mon équipe d’ingénieurs.
Figure 1
Si vous êtes familier avec le domaine de la gestion des connaissances, vous savez qu’il existe une dialectique entre les connaissances implicites (en bleu sur la Figure 1) et les connaissances explicites (en rouge sur la Figure 1).
Il existe actuellement deux façons principales de traiter les données pour la gestion des connaissances.
Via des modèles neuronaux, basés principalement sur les statistiques, pour l’aide à la décision, la compréhension automatique et la génération de données.
Via des modèles symboliques, basés sur la logique et la sémantique, pour l’aide à la décision et la recherche avancée.
Ces deux approches sont généralement distinctes et correspondent à deux cultures d’ingénieurs différentes. En raison de leurs avantages et de leurs inconvénients, les gens essaient de les combiner.
Clarifions maintenant la différence entre les modèles ” neuronaux ” et ” symboliques ” et comparons-les à la cognition neuronale et symbolique chez les êtres humains.
Le grand avantage des modèles neuronaux est leur capacité à synthétiser et à mobiliser la mémoire numérique “juste à temps”, ou “à la demande”, et à le faire automatiquement, ce qui est impossible pour un cerveau humain. Mais leur processus de reconnaissance et de génération de données est statistique, ce qui signifie qu’ils ne peuvent pas organiser un monde, ils ne maîtrisent pas la conservation des objets, ils n’ont pas de compréhension du temps et de la causalité, ou de l’espace et de la géométrie. Ils ne peuvent pas toujours reconnaître les transformations d’images d’un même objet comme le font les êtres vivants.
En revanche, les neurones vivants peuvent faire des choses que les neurones formels actuels ne peuvent pas faire. Les animaux, même sans modèles symboliques, avec leurs neurones naturels, sont capables de modéliser le monde, d’utiliser des concepts, ils conservent les objets malgré leurs transformations, ils appréhendent le temps, la causalité, l’espace, etc. Et les cerveaux humains ont la capacité de faire fonctionner des systèmes symboliques, comme le langage.
Quels sont les aspects positifs des modèles symboliques de l’IA, ou graphes de connaissances?
Il s’agit de modèles explicites du monde, plus précisément d’un monde pratique local.
Ils sont en principe auto-explicatifs, si le modèle n’est pas trop complexe.
ils ont de fortes capacités de raisonnement.
Tout cela les rend plutôt fiables, comparativement aux modèles neuronaux, qui sont probabilistes. Cependant, les modèles symboliques actuels présentent deux faiblesses.
Leur conception prend du temps. Ils sont coûteux en termes de main-d’œuvre spécialisée.
Ils n’ont ni “conservation des concepts” ni “conservation des relations” entre les ontologies ou domaines. Dans un domaine particulier donné, chaque concept et chaque relation doivent être définis logiquement un par un.
S’il existe une interopérabilité au niveau des formats de fichiers pour les métadonnées sémantiques (ou les systèmes de classification), cette interopérabilité n’existe pas au niveau sémantique des concepts, ce qui cloisonne les graphes de connaissances, et par conséquent l’intelligence collective.
En revanche, dans la vie réelle, des humains issus de métiers ou de domaines de connaissances différents se comprennent en partageant la même langue naturelle. En effet, dans la cognition humaine, un concept est déterminé par un réseau de relations inhérent aux langues naturelles.
Mais qu’est-ce que j’entends par “le sens d’un concept est déterminé par un réseau de relations inhérent aux langues naturelles” ? Quel est ce réseau de relations ? Et pourquoi est-ce que je le souligne dans cet article ? Parce que je crois que l’IA symbolique actuelle passe à côté de l’aspect sémantique des langues. Faisons donc un peu de linguistique pour mieux comprendre.
Figure 2
Toute langue naturelle tisse trois types de relations : l’interdéfinition, la composition et la substitution.
Tout d’abord, le sens de chaque mot est défini par une phrase qui implique d’autres mots, eux-mêmes définis de la même manière. Un dictionnaire englobe notamment une inter-définition circulaire ou enchevêtrée de concepts.
Ensuite, grâce aux règles de grammaire, on peut composer des phrases originales et comprendre de nouveaux sens.
Enfin, tous les mots d’une phrase ne peuvent pas être remplacés par n’importe quel autre ; il existe des règles pour les substitutions possibles qui contribuent au sens des mots et des phrases.
Vous comprenez la phrase “Je peins la petite pièce en bleu” (voir Figure 2) parce que vous connaissez les définitions de chaque mot, vous connaissez les règles grammaticales qui donnent à chaque mot son rôle dans la phrase, et vous savez par quoi les mots actuels pourraient être remplacés. C’est ce qu’on appelle la sémantique linguistique.
Il n’est pas nécessaire de définir une à une ces relations d’inter-définition, de composition et de substitution entre concepts chaque fois que l’on parle de quelque chose. Tout cela est inclus dans la langue. Malheureusement, nous ne disposons d’aucune de ces fonctions sémantiques lorsque nous construisons les graphes de connaissances actuels. Et c’est là qu’IEML pourrait contribuer à améliorer les méthodes de l’IA symbolique et de la gestion des connaissances.
Pour comprendre mon argumentation, il est important de faire la distinction entre la sémantique linguistique et la sémantique référentielle. La sémantique linguistique concerne les relations entre les concepts. La sémantique référentielle concerne les relations entre les propositions et les états de choses ou entre les noms propres et les individus.
Si la sémantique linguistique tisse des relations entre les concepts, pourquoi ne pouvons-nous pas utiliser les langues naturelles dans les modèles symboliques ? Nous connaissons tous la réponse. Les langues naturelles sont ambiguës (grammaticalement et lexicalement) et les machines ne peuvent pas désambiguïser le sens en fonction du contexte. Dans l’IA symbolique actuelle, nous ne pouvons pas compter sur le langage naturel pour susciter organiquement des relations sémantiques.
Alors, comment construit-on un modèle symbolique aujourd’hui ?
Pour définir les concepts, nous devons les relier à des URI (Uniform Resource Identifier) ou à des pages web, selon le modèle de la sémantique référentielle.
Mais comme la sémantique référentielle est insuffisante pour décrire un réseau de relations, au lieu de s’appuyer sur la sémantique linguistique, il faut imposer des relations sémantiques aux concepts un par un.
C’est la raison pour laquelle la conception des graphes de connaissances prend tant de temps et c’est aussi pourquoi il n’existe pas d’interopérabilité sémantique générale des graphes de connaissances entre les ontologies ou les domaines de connaissance. Encore une fois, je parle ici d’interopérabilité au niveau sémantique ou conceptuel et non au niveau du format.
Afin de pallier les insuffisances des modèles symboliques actuels, j’ai construit un métalangage qui présente les mêmes avantages que les langues naturelles, à savoir un mécanisme inhérent de construction de réseaux sémantiques, mais qui n’a pas leurs inconvénients, puisqu’il est sans ambiguïté et calculable.
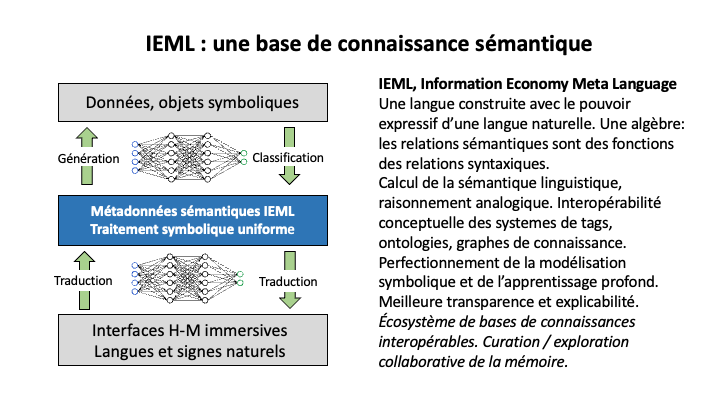
IEML (le méta-langage de l’économie de l’information), est un métalangage sémantique non ambigu et calculable qui inclut un système d’inter-définition, de composition et de substitution de concepts.
L’objectif de cette invention est de faciliter la conception de graphes de connaissances et d’ontologies, d’assurer leur interopérabilité sémantique et de favoriser leur conception collaborative. La vision qui inspire IEML est une intelligence collective à support numérique et augmentée par l’IA.
IEML a le pouvoir d’expression d’un langage naturel et possède une structure algébrique qui lui permet d’être entièrement calculable. IEML n’est pas seulement calculable dans sa dimension syntaxique, mais aussi dans sa dimension sémantique linguistique, car ses relations sémantiques (en particulier les relations de composition et de substitution) sont des fonctions calculables de ses relations syntaxiques. Il n’existe aujourd’hui aucun autre système symbolique ayant ces propriétés.
IEML dispose d’une grammaire entièrement régulière et récursive ainsi que d’un dictionnaire de trois mille mots organisés en paradigmes (systèmes de substitution) permettant la construction (récursive et grammaticale) de n’importe quel concept. En somme, tout concept peut être construit à partir d’un petit nombre de briques lexicales selon des règles de composition universelles simples.
Comme chaque concept est automatiquement défini par des relations de composition et de substitution avec d’autres concepts et par des explications impliquant les concepts de base du dictionnaire et conformes à la grammaire IEML, IEML est son propre métalangage. Il peut traduire n’importe quelle langue naturelle. Le dictionnaire en IEML est actuellement traduit en français et en anglais.
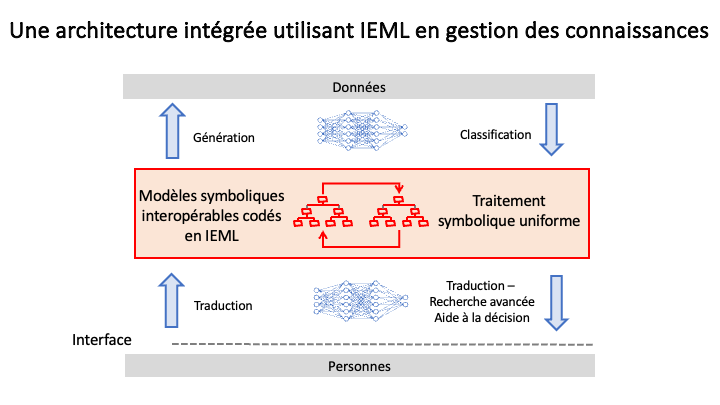
IEML permet de coupler les modèles symboliques et neuronaux, et de surmonter leurs limitations et séparations dans une architecture innovante et intégrée.
Figure 3
La diapositive ci-dessus (Figure 3) présente la nouvelle architecture sémantique pour la gestion des connaissances qu’IEML rend possible, une architecture qui conjoint les modèles neuronaux et symboliques.
La seule chose qui puisse générer tous les concepts dont nous avons besoin pour exprimer la complexité des domaines de connaissance, tout en maintenant la compréhension mutuelle, est une langue. Mais les langues naturelles sont irrégulières et ambiguës, et leur sémantique ne peut être calculée. IEML étant un langage algébrique univoque et formel (contrairement aux langues naturelles), il peut exprimer tous les concepts possibles (comme dans les langues naturelles), et ses relations sémantiques sont densément tissées grâce à un mécanisme intégré. C’est pourquoi nous pouvons utiliser IEML comme un langage de métadonnées sémantiques pratique pour exprimer n’importe quel modèle symbolique ET nous pouvons le faire de manière interopérable. Encore une fois, je parle d’interopérabilité conceptuelle. En IEML, tous les modèles symboliques peuvent échanger des modules de connaissance et le raisonnement transversal aux ontologies devient la norme.
Comment les modèles neuronaux sont-ils utilisés dans cette nouvelle architecture ? Les modèles neuronaux traduisent automatiquement le langage naturel en IEML, donc pas de travail ou d’apprentissage supplémentaire pour le profane. Ils pourraient même aider à traduire des descriptions informelles en langage naturel en un modèle formel exprimé en IEML.
Les consignes (prompts) seraient exprimées en IEML en coulisse, de sorte que la génération de données soit mieux contrôlée.
Nous pourrions également utiliser des modèles neuronaux pour classer ou étiqueter automatiquement des données en IEML. Les étiquettes exprimées en IEML permettront un apprentissage automatique plus efficace, car les unités ou “tokens” pris en compte ne seraient plus des unités sonores – caractères, syllabes, mots – des langues naturelles, mais des concepts générés par une algèbre sémantique.
Quels seraient les avantages d’une architecture intégrée de gestion des connaissances utilisant IEML comme système de coordonnées sémantiques ?
Les modèles symboliques et neuronaux fonctionneraient ensemble au profit de la gestion des connaissances.
Un système de coordonnées sémantiques commun faciliterait la mutualisation des modèles et des données. Les modèles symboliques seraient interopérables et plus faciles à concevoir et à formaliser. Leur conception serait collaborative, y compris d’un domaine à l’autre. L’usage d’un métalangage sémantique comme IEML amélioreraient également la productivité intellectuelle grâce à une automatisation partielle de la conceptualisation.
Les modèles neuronaux seraient basés sur des étiquettes codées en IEML et donc plus transparents, explicables et fiables. L’avantage serait non seulement technique, mais aussi d’ordre éthique.
Enfin, cette architecture favoriserait la diversité et la liberté de création, puisque les réseaux de concepts, ou graphes de connaissances, formulés en IEML peuvent être différenciés et complexifiés à volonté.
Première réflexion au sujet d’un IEML_GPT à venir.
Rappel : ” Je travaille dans une perspective d’intelligence artificielle dédiée à l’augmentation de l’intelligence collective. J’ai conçu IEML pour servir de protocole sémantique, permettant la communication des significations et des connaissances dans la mémoire numérique, tout en optimisant l’apprentissage automatique et le raisonnement automatique.”
Imaginons un dispositif destiné au partage des connaissances et qui tire le maximum des possibilités techniques contemporaines. Au cœur de ce dispositif évolue un écosystème ouvert de bases de connaissances catégorisées en IEML, qui émergent d’une multitude de communautés de recherche et de pratique. Entre ce noyau de bases de connaissances interopérables et les utilisateurs humains vivants s’interpose une interface neuronale (un écosystème de modèles) « no code » qui donne accès au contrôle, à l’alimentation, à l’exploration et à l’analyse des données. Tout se passe de manière intuitive et directe, selon les modalités sensorimotrices sélectionnées. C’est aussi par l’intermédiaire de ce giga-perceptron – un métavers immersif, social et génératif – que les collectifs échangent et discutent les modèles de données et réseaux sémantiques qui organisent leurs mémoires. En bonne gestion des connaissances, le nouveau dispositif de partage des savoirs favorise l’enregistrement des créations, accompagne les parcours d’apprentissage et présente les informations utiles aux acteurs engagés dans leurs pratiques. Le modèle IEML_GPT évoqué ici se veut un premier pas dans cette direction.
Maintenant que l’IA a été déchaînée sur Internet et qu’elle se couple aux médias sociaux, il nous faut apprivoiser et harnacher le monstre. Comment rendre l’IA raisonnable? Comment faire en sorte qu’elle « comprenne » ce qu’on lui dit et ce qu’elle nous dit, plutôt que de seulement calculer les probabilités d’apparition des mots à partir des données d’entraînement? Il faudrait lui apprendre le sens des mots et des phrases de telle sorte qu’elle (l’IA) se fasse une représentation abstraite *compréhensible pour elle* non seulement du monde physique (je laisse la tâche à Yann LeCun), mais aussi une représentation du monde humain et, plus généralement, du monde des idées.
En d’autres termes, comment greffer des capacités de codage et décodage symbolique sur un modèle neuronal qui ne peut au départ que reconnaître et générer des formes sensibles ou des agrégats de signifiants? Ce défi rappelle le processus de l’hominisation – quand des réseaux de neurones biologiques sont devenus capables de manipuler des systèmes symboliques – ce qui n’est pas pour me déplaire.
COMPRÉHENSION / CONNAISSANCE / INTEROPÉRABILITÉ
Comprendre une phrase, c’est l’inclure dans la dynamique auto-définitionnelle d’une langue, et cela avant même de saisir la référence extralinguistique de la phrase. L’IA comprendra ce qu’on lui dit lorsqu’elle sera capable de transformer automatiquement une chaîne de caractères en un réseau sémantique qui plonge dans la boucle auto-référentielle et auto-définitoire d’une langue. Le dictionnaire d’une langue, avec ses définitions, est un élément crucial de cette boucle. De même qu’une déduction représente en fin de compte une tautologie logique, le dictionnaire d’une langue exhibe une *tautologie sémantique*. C’est pourquoi IEML_GPT doit contenir un fichier avec le dictionnaire IEML-français-anglais (et peut-être d’autres langues) avec l’ensemble des relations entre les mots sous forme de phrases IEML. Le dictionnaire est une méta-ontologie qui est la même pour tous les utilisateurs. D’autres fichiers pourront contenir des modèles locaux ou ontologies correspondant aux écosystèmes de pratiques des communautés d’utilisateurs. 1) Compréhension linguistique. Les agents raisonnables sont capables de reconnaître et de générer des séquences de caractères IEML syntaxiquement valides, notamment au moyen d’un parseur. Ils ont une compréhension d’IEML : ils reconstituent les arbres syntagmatiques récursivement enchâssés et les relations entre concepts qui découlent du dictionnaire et des matrices paradigmatiques (ou groupes de substitution) qui organisent les concepts. Chaque concept (représenté par un mot ou une phrase IEML) se trouve ainsi au centre d’une étoile de relations syntaxiques et sémantiques. 2) Connaissance des domaines pratiques. Les agents raisonnables sont animés par des bases de connaissances qui leur permettent de comprendre (localement) le monde où ils sont amenés à intervenir. Ils disposent de modèles (ontologies ou graphes de connaissances en IEML) des situations pratiques auxquelles leurs utilisateurs sont confrontés. Ils sont capables de raisonner à partir de ces modèles. Ils sont capables de rapporter les données qu’ils acquièrent et les questions qu’on leur pose à ces modèles. 3) Interopérabilité sémantique. Les agents raisonnables partagent la même langue (IEML) et donc se comprennent entre eux. Ils peuvent s’échanger des modèles ou des sous-modèles. Ils transforment les expressions en langues naturelles en IEML et les expressions IEML en langues naturelles : ils peuvent donc comprendre les humains et se faire comprendre d’eux.
TÂCHE 1 : LE DICTIONNAIRE
1.0 Je dispose déjà d’environ trois mille mots du dictionnaire organisés en paradigmes, d’une grammaire formelle, d’un parseur pour valider les phrases et de fonctions pour générer des paradigmes.
1.1 La première étape consiste à créer des concepts-phrases pour exprimer les *ensembles de mots* (familles lexicales et champs sémantiques) que sont les paradigmes, leurs colonnes, leurs rangées, etc. Appelons les concepts définissant ces ensembles de mots des « concepts lexicaux ». Les mots d’une même famille lexicale ont des traits syntaxiques communs et appartiennent souvent aux mêmes paradigmes-racines. Ils devront être créés systématiquement au moyen de paradigmes.
Il me faut trouver les moyens de générer les paradigmes de concepts lexicaux automatiquement en langue naturelle avec IEML_GPT plutôt qu’au moyen de l’éditeur actuel qui n’est pas facile à utiliser.
1.2 La seconde étape consiste à créer toutes les « propositions analytiques » qui définissent les mots du dictionnaire et explicitent leurs relations au moyen de mots et de concepts lexicaux. Par exemple : « Une montagne est plus grande qu’une colline » ; « La sociologie appartient aux sciences humaines ». Les propositions analytiques de ce type sont toujours vraies et définissent une méta-ontologie. Il faudra donc créer les paradigmes des *relations du dictionnaire*. Et les faire générer par IEML_GPT à partir d’instructions en langues naturelles.
1.3 Toutes les relations internes au dictionnaire, matérialisées par des liens hypertextes, sont créés par des phrases. Sur le plan de l’interface utilisateur, cela revient à créer des liens hypertexte internes au dictionnaire (entre les mots et les concepts lexicaux) de telle sorte que leurs relations grammaticales soient les plus claires possibles. Le document dictionnaire-hypertexte doit également être généré automatiquement par IEML_GPT.
Pour chaque mot, on obtiendra une liste (une « page? ») de phrases justes contenant le mot. Cette liste sera organisée par rôle grammatical : mot défini en rôle de racine, mot défini en rôle d’objet, etc.
Ces phrases serviront non seulement à définir les mots, mais aussi à commencer à accumuler des exemples, voire des données d’entraînement, avec la correspondance entre phrases IEML formelles et traductions littéraires en français et en anglais. En somme, le premier produit fini sera un dictionnaire complet, avec mots, concepts lexicaux et relations d’inter-définition sous forme hypertextuelle, le tout en IEML, anglais et français.
TÂCHE 2 : L’ÉDITEUR D’ONTOLOGIES
La tâche 1 aura permis de tester les meilleurs moyens de créer des paradigmes au moyen de consignes en langues naturelles, voire au moyen de formulaires permettant de mâcher le travail des concepteurs d’ontologies.
L’output de l’éditeur d’ontologie pourra être en RDF, JSON-LD, ou sous forme d’un document hypertexte. On peut aussi imaginer un document multimédia interactif : tables, arbres, réseaux de concepts explorables, illustrations verbales/sonores…
Idéalement, l’ontologie créée devrait contenir nativement un moteur d’inférence et donc supporter le raisonnement automatique. La propriété intellectuelle des créateurs d’ontologies devra être reconnue.
IEML_GPT sera capable de faire fonctionner n’importe quelle ontologie ou ensemble d’ontologies IEML.
TÂCHE 3 LA CATÉGORISATION AUTOMATIQUE
L’étape suivante devra viser la construction d’un outil intégré de catégorisation automatique de données en IEML. On donne à l’IA un jeu de données et une ontologie IEML (idéalement sous forme de fichier de référence) et le résultat est un ensemble de données catégorisées selon les termes de l’ontologie. L’exécution de la tâche 3 ouvre la voie à la création d’un écosystème de bases de connaissances tel que décrit dans la vision plus haut et la figure ci-dessous.
Toutes ces étapes devront être d’abord réalisées « en petit » (preuves de concepts et méthode agile) avant de l’être intégralement.
Cette entrée de blog propose le texte de ma conférence d’ouverture du Forum “Montréal Connecte” d’octobre 2023 consacré à l’intelligence collective à support numérique. Pour ceux qui préfèrent la vidéo, elle est là (ça commence à la vingtième minute) : https://www.youtube.com/watch?v=dTMU-j8nYio&t=7s
INTRODUCTION
Il y a maintenant presque 30 ans j’ai publié un livre consacré à l’intelligence collective à support numérique qui était, modestie à part, le premier à traiter ce sujet. Dans cet ouvrage, je prévoyais que l’Internet allait devenir le principal medium de communication, que cela provoquerait un changement de civilisation, et je disais que le meilleur usage que nous pouvions faire des technologies numériques était d’augmenter l’intelligence collective (et j’ajoute : une intelligence collective émergente, de type “bottom up”).
Le public de ma conférence d’ouverture à “Montreal Connecte” le 10 octobre 2023
A cette époque moins de 1% de l’humanité était branchée sur l’Internet alors que nous avons aujourd’hui – en 2023 – dépassé les deux tiers de la population mondiale connectée. Le changement de civilisation semble assez évident, bien qu’il faille attendre normalement plusieurs générations pour confirmer ce type de mutation, sans oublier que nous ne sommes qu’au commencement de la révolution numérique. Quant à l’augmentation de l’intelligence collective, de nombreux pas ont été franchis pour mettre les connaissances à la portée de tous (Wikipédia, le logiciel libre, les bibliothèques et les musées numérisés, les articles scientifiques en accès libre, certains aspects des médias sociaux, etc.). Mais beaucoup reste à faire. Utiliser l’intelligence artificielle pour augmenter l’intelligence collective semble une voie prometteuse, mais comment avancer dans cette direction ? Pour répondre à cette question de manière rigoureuse, je vais devoir définir préalablement quelques concepts.
QU’EST-CE QUE L’INTELLIGENCE?
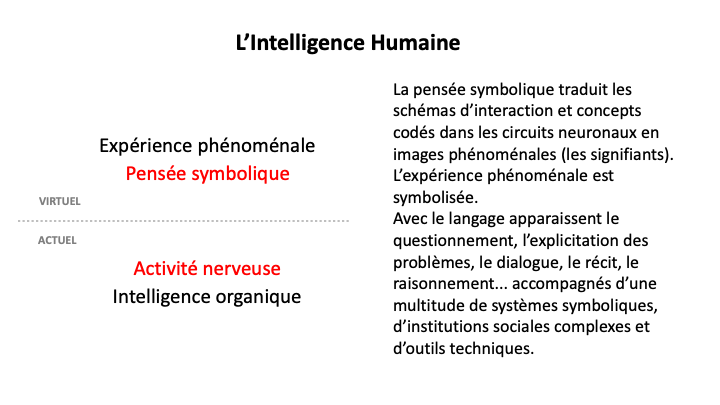
Avant même de traiter la relation entre l’intelligence collective humaine et l’intelligence artificielle, essayons de définir en quelques mots l’intelligence en général et l’intelligence humaine en particulier. On dit souvent que l’intelligence est la capacité de résoudre des problèmes. A quoi je réponds: oui, mais c’est aussi et surtout la capacité de concevoir ou de construire des problèmes. Or si l’on a un problème c’est que l’on essaye d’obtenir un certain résultat et que l’on est confronté à une difficulté ou à un obstacle. Autrement dit, il y a un soi, un même, qu’on appellera l’« Un », qui est pourvu d’une logique interne, qui doit se maintenir dans certaines limites homéostatiques, qui a des finalités immanentes comme la reproduction, l’alimentation ou le développement et il y a un « Autre », une extériorité, qui obéit à une logique différente, qui se confond avec l’environnement ou qui appartient à l’environnement de l’Un et avec qui l’Un doit transiger. L’entité intelligente doit avoir une certaine autonomie, sinon elle ne serait pas intelligente du tout, mais cette autonomie n’est pas une autarcie ou une indépendance absolue car, dans ce cas, elle n’aurait aucun problème à résoudre et n’aurait pas besoin d’être intelligente.
Figure 1
Le rapport entre l’Un et l’Autre peut se ramener à une communication ou une interaction entre des entités qui sont régies par des manières d’être, des codes, des finalités hétérogènes et qui imposent donc un processus incertain et perfectible de codage et de décodage, processus qui engendre forcément des pertes, des créations et qui est soumis à toutes sortes de bruits et de parasitages.
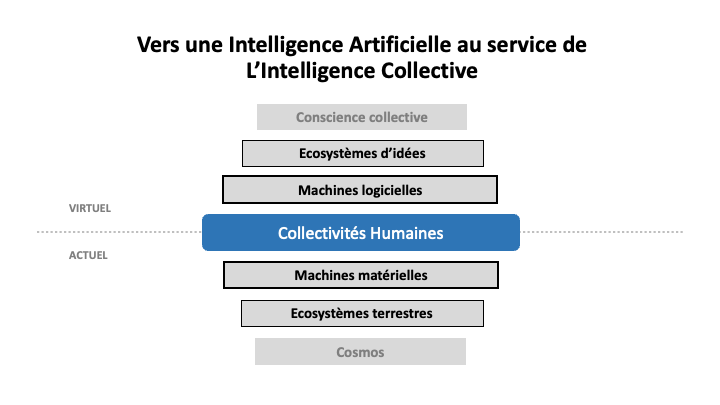
L’entité intelligente n’est pas forcément un individu, ce peut être une société ou un écosystème. D’ailleurs, à l’analyse, on trouvera souvent à sa place un écosystème de molécules, de cellules, de neurones, de modules cognitifs, et ainsi de suite. Quant au rapport entre l’Un et l’Autre, il constitue la maille élémentaire d’un réseau écosystémique quelconque. L’intelligence est le fait d’un écosystème en relation avec d’autres écosystèmes, elle est collective par nature. En somme le problème revient à optimiser la communication avec un Autre hétérogène en fonction des finalités de l’Un et la solution n’est autre que l’histoire effective de leurs relations.
LES COUCHES DE COMPLEXITÉ DE L’INTELLIGENCE
Nous nous interrogeons principalement sur l’intelligence humaine augmentée par le numérique. N’oublions pas, cependant que notre intelligence repose sur des couches de complexité bien antérieures à l’apparition de l’espèce Homo sur la Terre. Les couches de complexité organique et animale sont toujours actives et indispensables à notre propre intelligence puisque nous sommes des êtres vivants pourvus d’un organisme et des animaux pourvus d’un système nerveux. C’est d’ailleurs pourquoi l’intelligence humaine est toujours incarnée et située.
Figure 2
Avec les organismes, viennent les propriétés bien connues d’autoreproduction, d’auto-référence et d’auto-réparation qui s’appuient sur une communication moléculaire et sans doute aussi des formes de communication électromagnétique complexe. Je ne développerai pas ici le thème de l’intelligence organique. Qu’il suffise de signaler que certains chercheurs en biologie et en écologie parlent désormais d’une “cognition végétale”.
Le développement du système nerveux découle des nécessités de la locomotion. Il s’agit d’abord d’assurer la boucle sensori-motrice. Au cours de l’évolution, cette boucle réflexe s’est complexifiée en simulation de l’environnement, évaluation de la situation et calcul décisionnel menant à l’action. L’intelligence animale résulte d’un pli de l’intelligence organique sur elle-même puisque le système nerveux cartographie et synthétise ce qui se passe dans l’organisme et le contrôle en retour. L’expérience phénoménale naît de cette réflexion.
En effet, le système nerveux produit une expérience phénoménale, ou conscience, qui se caractérise par l’intentionnalité, à savoir le fait de se rapporter à quelque chose qui n’est pas forcément l’animal lui-même. L’intelligence animale se représente l’autre. Elle est habitée par des images sensorielles multimodales (cénesthésie, toucher, goût, odorat, audition, vue), le plaisir et la douleur, les émotions, le cadrage spatio-temporel indispensable à la locomotion, le rapport à un territoire, une communication sociale souvent complexe. Il est clair que les animaux sont capables de reconnaître des proies, des prédateurs ou des partenaires sexuels et d’agir en conséquence. Ceci n’est possible que parce que des circuits neuronaux codent des schémas d’interaction ou concepts qui orientent, coordonnent et donnent sens à l’expérience phénoménale.
L’INTELLIGENCE HUMAINE
Je viens d’évoquer l’intelligence animale, qui repose sur le système nerveux. Comment caractériser l’intelligence humaine, supportée par le codage symbolique ? Les catégories générales, concepts et schémas d’interaction qui étaient simplement codés par des circuits neuronaux dans l’intelligence animale sont maintenant aussi représentés dans l’expérience phénoménale par l’intermédiaire des systèmes symboliques, dont le plus important est le langage. Des images signifiantes (paroles, écrits, représentations visuelles, gestes rituels…) représentent des concepts abstraits et ces concepts peuvent se combiner syntaxiquement pour former des architectures sémantiques complexes.
Figure 3
Dès lors, la plupart des dimensions de l’expérience phénoménale humaine – y compris la sensori-motricité, l’affectivité, la spatio-temporalité et la mémoire – se projettent sur les systèmes symboliques et sont contrôlées en retour par la pensée symbolique. L’intelligence et la conscience humaines sont réflexives. En outre, pour que se forme cette pensée symbolique, il faut que des systèmes symboliques, qui sont toujours d’origine sociale, soient internalisés par les individus, deviennent partie intégrante de leur psychisme et s’inscrivent “en dur” dans leurs systèmes nerveux. Il en résulte que la communication symbolique embraye directement sur les systèmes nerveux humains. Nous ne pouvons pas ne pas comprendre ce que dit quelqu’un si nous connaissons la langue. Et les effets sur nos émotions et nos représentations mentales sont quasi inévitables. On pourrait également prendre l’exemple de la synchronisation psycho-physique et affective produite par la musique. C’est pourquoi la cohésion sociale humaine est au moins aussi forte que celle des animaux eusociaux comme les abeilles et les fourmis.
On remarquera que la figure 3, comme plusieurs des figures qui vont suivre, évoque un partage et une interdépendance entre virtuel et actuel. En 1995, j’ai publié un livre sur le virtuel qui était à la fois une méditation philosophique et anthropologique sur le concept de virtualité et un essai de mise au travail de ce concept sur des objets contemporains. Ma thèse philosophique est simple : ce qui n’est que possible, mais non réalisé, n’existe pas. Par contraste, ce qui n’est que virtuel mais non actualisé existe. Le virtuel, ce qui est en puissance, abstrait, immatériel, informationnel ou idéal pèse sur les situations, conditionne nos choix, provoque des effets et entre dans une dialectique ou dans un rapport d’interdépendance avec l’actuel.
L’ÉCOSYSTÈME DE L’INTELLIGENCE COLLECTIVE
La figure 4 ci-dessous cartographie les principaux pôles de l’intelligence collective humaine ou, si l’on préfère, la culture qui vient avec la pensée symbolique. Le diagramme est organisé par deux symétries qui se croisent. La première symétrie – binaire – est celle du virtuel et de l’actuel. L’actuel est plongé dans l’espace et le temps, il est plutôt concret alors que le virtuel est plutôt abstrait et n’a pas d’adresse spatio-temporelle. La seconde symétrie – ternaire – est celle du signe, de l’être (l’interprétant) et de la chose (le référent), qui est inspiré du triangle sémiotique. La chose est ce que représente le signe et l’être est le sujet pour qui le signe représente la chose. A gauche (signe) se tiennent les systèmes symboliques, le savoir et la communication ; au milieu (être) se dressent la subjectivité, l’éthique et la société ; à droite (chose) s’étendent la capacité de faire, l’économie, la technique, la dimension physique. Il s’agit bien d’intelligence collective parce que les six sommets de l’hexagone sont interdépendants: les lignes vertes (les relations) sont aussi importantes, sinon plus, que les points où elles aboutissent.
Figure 4
Cette grille de lecture est valable pour la société en général mais également pour n’importe quelle communauté particulière. Au passage, virtuel, actuel, signe, être et chose sont (avec le vide) les primitives sémantiques du langage IEML (Information Economy MetaLanguage) que j’ai inventé et dont je dirai quelques mots plus bas.
Les six sommets de l’hexagone ne sont pas seulement les principaux points d’appui de l’intelligence collective humaine, ce sont aussi des univers de problèmes à résoudre:
problèmes de création de connaissance et d’apprentissage
problèmes de communication
problèmes de législation et d’éthique
problèmes sociaux et politiques
problèmes économiques
problèmes techniques, problèmes de santé et d’environnement.
Comment résoudre ces problèmes?
LE CYCLE AUTO-ORGANISATEUR DE L’INTELLIGENCE COLLECTIVE
La Figure 5 ci-dessous représente un cycle de résolution de problème en quatre étapes. Pour chacune des quatre phases du cycle (délibération, décision, action et observation), il existe un grand nombre de procédures différentes selon les traditions et les contextes où opère l’intelligence collective. Vous remarquerez que la délibération représente la phase virtuelle du cycle alors que l’action en représente la phase actuelle. Dans ce modèle, la décision fait la transition entre le virtuel et l’actuel tandis que l’observation passe de l’actuel au virtuel. Je voudrais insister ici sur deux concepts, la délibération et la mémoire, auxquels il arrive qu’on ne prête pas assez attention dans ce contexte.
Figure 5
Soulignons d’abord l’importance de la délibération, qui ne consiste pas seulement à discuter des meilleures solutions pour surmonter les obstacles mais aussi à construire et conceptualiser les problèmes de manière collaborative. Cette phase de conceptualisation va fortement impacter et même définir une bonne part des phases suivantes, elle va aussi déterminer l’organisation de la mémoire.
En effet, vous voyez sur le diagramme de la Figure 5 que la mémoire se trouve au centre du processus d’auto-organisation de l’intelligence collective. La mémoire partagée vient en appui de chacune des phases du cycle et contribue au maintien de la coordination, de la cohérence et de l’identité de l’intelligence collective. La communication indirecte par l’intermédiaire d’un environnement partagé est l’un des principaux mécanismes qui sous-tend l’intelligence collective des sociétés d’insectes, que l’on appelle la communication stigmergique dans le vocabulaire des éthologues. Mais alors que les insectes laissent généralement des traces de phéromones dans leurs environnements physiques pour guider l’action de leurs congénères, nous laissons des traces symboliques et cela non seulement dans le paysage mais aussi dans des dispositifs de mémoire spécialisés comme les archives, les bibliothèques et aujourd’hui les bases de données. Le problème de l’avenir de la mémoire numérique est devant nous : comment concevoir cette mémoire de telle sorte qu’elle soit la plus utile possible à notre intelligence collective?
VERS UNE INTELLIGENCE ARTIFICIELLE AU SERVICE DE L’INTELLIGENCE COLLECTIVE
Ayant acquis quelques notions de l’intelligence en général, des fondements de l’intelligence humaine et de la complexité de notre intelligence collective, nous pouvons maintenant nous interroger sur la relation de notre intelligence avec les machines.
Figure 6
La figure 6 propose une vue d’ensemble de notre situation. Au milieu, le « vivant » : les populations humaines, avec les corps actuels et les esprits virtuels des individus. Immédiatement au contact des individus, les machines matérielles (ou corps mécanique) du côté actuel et, du côté virtuel, les machines logicielles (ou esprit mécanique). Les machines matérielles jouent de plus en plus un rôle d’interface ou de medium entre nous et les écosystèmes terrestres. Quant aux machines logicielles, elles sont en train de devenir le principal intermédiaire – un médium encore une fois – entre les populations humaines et les écosystèmes d’idées avec lesquelles nous vivons en symbiose. Quant à la conscience collective, nous n’y sommes pas encore. Elle représente plus un horizon, une direction d’évolution à viser qu’une réalité. Il faut comprendre la Figure 6 en y ajoutant mentalement des boucles de rétroaction ou d’interdépendance entre les couches adjacentes, entre le virtuel et l’actuel, entre le mécanique et le vivant. Sur un plan éthique, on peut faire l’hypothèse que les collectivités humaines vivantes reçoivent les bienfaits des écosystèmes terrestres et des écosystèmes d’idées en proportion du travail et du soin qu’elles apportent à leur entretien.
L’AUTOMATISATION DE L’INTELLIGENCE
Effectuons un zoom avant sur notre environnement mécanique avec la Figure 7. Une machine est un dispositif technique construit par les humains, un automate qui bouge ou fonctionne “tout seul”. Aujourd’hui les deux types de machines – logicielles et matérielles – sont interdépendantes. Elles ne pourraient pas exister l’une sans l’autre et elles sont en principe contrôlées par les collectivités humaines dont elles augmentent les capacités physiques et mentales. Parce que la technique externalise, socialise et réifie les fonctions organiques et psychiques humaines elle peut parfois paraître autonome ou à risque de s’autonomiser, mais c’est une illusion d’optique. Derrière “la machine” il faut entrevoir l’intelligence collective et les rapports sociaux qu’elle réifie et mobilise.
Figure 7
Les machines mécaniques sont celles qui transforment le mouvement, à commencer par la voile, la roue, la poulie, le levier, les engrenages, les ressorts, etc. Citons comme exemples de machines purement mécaniques les moulins à eau ou à vent, les horloges classiques, les presses à imprimer de la Renaissance ou les premiers métiers à tisser.
Les machines énergétiques sont celles qui transforment l’énergie en impliquant de la chaleur ou de l’électricité. Citons les fours, les forges, les machines à vapeur, les moteurs à explosion, les moteurs électriques, et les procédés contemporains pour produire, transmettre et stocker l’électricité.
Quand aux machines électroniques, elles contrôlent l’énergie et la matière au niveau des champs électromagnétiques et des particules élémentaires et servent bien souvent à contrôler les machines de couches inférieures dont, par ailleurs, elles dépendent. Pour ce qui nous intéresse ici, ce sont principalement les centres de données (le “cloud”), les réseaux et les appareils qui sont directement au contact des utilisateurs finaux (le “edge”) tels qu’ordinateurs, téléphones, consoles de jeux, casques de réalité virtuelle et autres.
Abordons la partie virtuelle qui correspond à la mémoire partagée que nous avions mise au centre de notre description du cycle auto-organisateur de l’action collective. Si l’échange de messages point à point a toujours lieu, la majeure part de la communication sociale s’effectue désormais de manière stigmergique dans la mémoire numérique. Nous communiquons par l’intermédiaire de la masse océanique de données qui nous rassemble. Chaque lien que nous créons, chaque étiquette ou hashtag apposée sur une information, chaque acte d’évaluation ou d’approbation, chaque « j’aime », chaque requête, chaque achat, chaque commentaire, chaque partage, toutes ces opérations modifient subtilement la mémoire commune, c’est-à-dire le magma inextricable des rapports entre les données. Notre comportement en ligne émet un flux continuel de messages et d’indices qui transforment la structure de la mémoire, contribuent à orienter l’attention et l’activité de nos contemporains et entraîne les intelligences artificielles. Mais tout cela se fait aujourd’hui d’une manière plutôt opaque, qui ne rend pas justice à la nécessaire phase de délibération et de conceptualisation consciente qui serait celle d’une intelligence collective idéale.
La mémoire comprend avant tout les données qui sont produites, retrouvées, explorées et exploitées par l’activité humaine. Les interfaces Homme-Machine représentent le “front-end” sans lequel rien n’est possible. Elles déterminent directement ce qu’on appelle l’expérience de l’utilisateur. Entre les interfaces et les données, s’interposent principalement deux types de modèles d’intelligence artificielle, les modèles neuronaux et les modèles symboliques. Nous avons vu plus haut que l’intelligence humaine « naturelle » reposait notamment sur un codage neuronal et sur un codage symbolique. Or nous retrouvons ces deux types de codage, ou plutôt leur transposition électronique, à la couche de la mémoire numérique. Remarquons que ces deux approches, neuronale et symbolique, existaient déjà aux premiers temps de l’IA, dès le milieu du XXe siècle.
Les modèles neuronaux sont entraînés sur la multitude des données numériques disponibles et ils en extraient automatiquement des patterns de patterns qu’aucun programmeur humain n’aurait pu tirer au clair. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et produire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de catégoriser correctement des formes (d’image, de texte, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. L’IA neuronale synthétise et mobilise la mémoire commune. Bien loin d’être autonome, elle prolonge et amplifie l’intelligence collective qui a produit les données. Ajoutons que des millions d’utilisateurs contribuent au perfectionnement des modèles en leur posant des questions et en commentant les réponses qu’ils en reçoivent. On peut prendre l’exemple de Midjourney, dont les utilisateurs s’échangent leurs consignes (prompts) et améliorent constamment leurs compétences en IA. Les serveurs Discord de Midjourney sont aujourd’hui les plus populeux de la planète, avec plus d’un million d’utilisateurs. On commence à observer un phénomène semblable autour de DALLE 3. Une nouvelle intelligence collective stigmergique émerge de la fusion des médias sociaux, de l’IA et des communautés de créateurs. Ce sont des exemples d’une contribution consciente de l’intelligence collective humaine à des dispositifs d’intelligence artificielle.
De nombreux modèles pré-entraînés généralistes sont open-source et plusieurs méthodes sont aujourd’hui utilisées pour les raffiner ou les ajuster à des contextes particuliers, que ce soit à partir de consignes élaborées, d’un entraînement supplémentaire avec des données spéciales ou au moyen de feed-back humain, ou d’une combinaison de ces méthodes. En somme nous disposons aujourd’hui des premiers balbutiements d’une intelligence collective neuronale, qui émerge à partir d’un calcul statistique sur les données. Observons toutefois que les modèles neuronaux, aussi utiles et pratiques qu’ils soient, ne sont malheureusement pas des bases de connaissance fiables. Ils reflètent forcément l’opinion commune et les biais que charrient les données. Du fait de leur nature probabiliste, ils commettent toutes sortes d’erreurs. Enfin, ils ne savent pas justifier leur résultats et cette opacité n’est pas faite pour inciter à la confiance. L’esprit critique est donc plus que jamais nécessaire, surtout si les données d’entrainement sont de plus en plus produites par l’IA générative, ce qui crée un dangereux cercle vicieux épistémologique.
Intéressons-nous maintenant aux modèles symboliques. On les appelle de différents noms : collections de tags ou d’étiquettes, classifications, ontologies, graphes de connaissance ou réseaux sémantique. Ces modèles peuvent se ramener à des concepts explicites et à des relations tout aussi explicites entre ces concepts, y compris des relations causales. Ils permettent d’organiser les données sur un plan sémantique en fonction des besoins pratiques des communautés utilisatrices et ils autorisent le raisonnement automatique. Avec cette approche, on obtient des connaissances fiables, explicables, directement adaptées à l’usage que l’on vise. Les bases de connaissances symboliques sont de merveilleux moyens de partage des savoirs et des compétences, et donc d’excellents outils d’intelligence collective. Le problème vient de ce que les ontologies ou graphes de connaissances sont créées “à la main”. Or la modélisation formelle de domaines de connaissance complexes est difficile. La construction de ces modèles prend beaucoup de temps à des experts hautement spécialisés et coûte donc cher. La productivité de ce travail intellectuel est faible. D’autre part, s’il existe une interopérabilité au niveau des formats de fichiers pour les métadonnées sémantiques (ou systèmes de classification), cette interopérabilité n’existe pas au niveau proprement sémantique des concepts, ce qui cloisonne l’intelligence collective. On utilise Wikidata pour les applications encyclopédiques, schema.org pour les sites web, le modèle CIDOC-CRM pour les institutions culturelles, etc. Il existe des centaines d’ontologies incompatibles d’un domaine à l’autre et souvent même au sein d’un même domaine.
Cela fait des années que de nombreux chercheurs plaident en faveur de modèles hybrides neuro-symboliques afin de bénéficier des avantages des deux approches. Mon message est le suivant: si nous voulons avancer vers une intelligence collective à support numérique digne de ce nom et qui se tienne à la hauteur de nos possibilités techniques contemporaines, il nous faut :
Renouveler l’IA symbolique en augmentant la productivité du travail de modélisation formelle et en décloisonnant les métadonnées sémantiques.
Coupler cette IA symbolique renouvelée avec l’IA neuronale en plein développement.
Mettre cette IA hybride encore inédite au service de l’intelligence collective.
IEML : VERS UNE BASE DE CONNAISSANCE SÉMANTIQUE
Nous avons automatisé et mutualisé la reconnaissance et la génération automatique de formes, qui est plutôt d’essence neuronale. Comment pouvons-nous automatiser et mutualiser la conceptualisation, qui est plutôt d’essence symbolique? Comment faire travailler ensemble la conceptualisation formelle par des êtres pensants et la reconnaissance de formes qui émerge des statistiques?
Figure 8
Parce que notre intelligence collective repose de plus en plus sur une mémoire numérique commune, cela fait trente ans que je cherche ce que pourrait être un système de coordonnées sémantiques pour la mémoire numérique, un système de métadonnées qui permettrait l’automatisation des opérations de conceptualisation et la mutualisation des modèles conceptuels.
Or la seule chose qui soit capable de générer tous les concepts que l’on voudra tout en maintenant la compréhension réciproque, c’est une langue. Mais les langues naturelles sont irrégulières, ambiguës et leur sémantique n’est pas calculable. J’ai donc construit une langue – IEML (Information Economy MetaLanguage) – dont les relations sémantiques internes sont des fonctions des relations syntaxiques. IEML est à la fois une langue et une algèbre. Cette langue est faite pour faciliter et automatiser autant que possible la construction de modèlessymboliques tout en assurant leur interopérabilité sémantique. En somme c’est un outil permettant d’automatiser et de mutualiser la conceptualisation qui a vocation à servir de système de métadonnées sémantiques universel.
Nous pouvons maintenant répondre à notre question principale : comment utiliser l’intelligence artificielle pour augmenter l’intelligence collective? Il faut imaginer un écosystème de bases de connaissances sémantiques organisées selon l’architecture décrite sur la figure 8. Vous voyez qu’entre l’interface Homme-Machine et les données s’interposent trois couches. Au centre la couche des métadonnées sémantiques organise les données sur un plan symbolique et permet, grâce à sa structure algébrique, toutes sortes de calculs uniformes de type logique, analogique et sémantique. Nous savons que la modélisation symbolique est difficile et les éditeurs d’ontologies contemporains ne facilitent pas vraiment la tâche. C’est pourquoi, sous la couche des métadonnées je propose d’utiliser un modèle neuronal pour traduire les systèmes de signes naturels en IEML et vice versa ce qui favoriserait l’édition et l’inspection la plus intuitive possible des modèles sémantiques. Entre la couche des métadonnées et celle des données se trouve encore un modèle neuronal qui permettra la génération automatique de données à partir de consignes (prompts) en IEML. En sens inverse, le modèle neuronal effectuerait la classification automatique des données et leur intégration dans le modèle sémantique de la communauté utilisatrice. Notons que les propriétés algébriques d’IEML visent notamment un perfectionnement de l’apprentissage neuronal.
L’interface Homme-Machine immersive utilisant des signes naturels permettrait à tout un chacun de collaborer à la conceptualisation des modèles au niveau des métadonnées sémantiques et de générer les données appropriées au moyen de consignes (prompts) transparentes. Enfin, cette base de connaissance automatiserait la catégorisation, l’exploitation et l’exploration multimédia des données.
Une telle approche permettrait à chaque communauté de s’organiser selon son propre modèle sémantique tout en supportant la comparaison et l’échange de concepts et de sous-modèles. En somme, un écosystème de bases de connaissances sémantiques utilisant IEML maximiserait simultanément, (1) l’augmentation de la productivité intellectuelle par l’automatisation partielle de la conceptualisation, (2) la transparence des modèles et l’explicabilité des résultats, si importantes d’un point de vue éthique, (3) la mutualisation des modèles et des données grâce à un système de coordonnées sémantique commun, (4) la diversité et la liberté créative puisque les réseaux de concepts formulés en IEML peuvent se différentier et se complexifier à volonté. Un beau programme pour l’intelligence collective. J’appelle de mes vœux une mémoire numérique qui nous permettra de cultiver des écosystèmes d’idées divers, féconds et d’en récolter le maximum de fruits pour le développement humain.
Pierre Lévy lors de la conférence du 10 Octobre 2023. Photo: Luc Courchesne.
“Ce texte propose quelques réflexions philosophiques sur la relation triangulaire entre l’intelligence collective, l’intelligence artificielle et la noble finalité de mettre la connaissance à la portée de tous.”
La valeur du savoir vérifié à l’heure de l’IA générative
Commençons par une citation de Denny Vrandečić, un des initiateurs de Wikidata, qui avait travaillé sur le graphe de connaissances de Google comme ontologiste et qui est aujourd’hui le chef de file du projet “Abstract Wikipedia”[1] visant à rendre les données des articles de Wikipédia indépendants des langues (c’est-à-dire traductibles dans toutes les langues). Denny a déclaré dans sa communication à la Knowledge Graph Conference de mai 2023[2] “In a world of infinite content, knowledge becomes valuable”. Ce monde où les contenus sont potentiellement infinis résulte évidemment de l’usage désormais massif de l’intelligence artificielle générative. Parmi tous les problèmes que posent cette nouvelle situation, citons-en deux, particulièrement prégnants du point de vue de l’accès à la connaissance. Premièrement, malgré les usages qui sont faits des modèles génératifs pour obtenir rapidement des réponses directes, il faut réaffirmer que, contrairement à l’IA symbolique classique du XXe siècle, l’IA statistique (dite aussi neuronale) d’aujourd’hui – limitée à ses seules capacités – n’offre aucune garantie de vérité. GPT4 comme les autres modèles du même genre ne sont pas des bases de connaissances. Les erreurs de fait et de raisonnement sont nombreuses et il suffit d’être spécialiste d’un domaine pour constater les faiblesses de ces IA, comme nous le faisons d’habitude lorsque nous lisons un article portant sur un de nos domaines de compétence quand il est rédigé par un journaliste pressé qui se contente de reformuler la doxa dans laquelle il baigne. Les réponses – probabilistes – de Chat GPT sont seulement vraisemblables. Deuxièmement, comme les modèles d’IA générative sont entraînés sur les données du Web et que celles-ci sont de plus en plus rédigées et illustrées par les modèles en question, on se trouve en présence d’un dangereux cercle vicieux, et cela d’autant plus que les travailleurs au rabais chargés d’aligner les modèles et de redresser leurs biais ou erreurs utilisent eux-mêmes des IA génératives pour accomplir leur tâche![3] Pour s’extraire de ces sables mouvants épistémologiques, il est donc nécessaire d’investir plus que jamais dans la construction de sources d’information fiables. En d’autres termes, l’explosion des usages de l’IA générative, loin de nous dispenser d’alimenter et d’utiliser Wikipédia, Wikidata et d’autres bases de connaissances vérifiées, rend l’effort d’y contribuer et le plaisir de les consulter encore plus nécessaires! Ceci dit, comme nous le verrons par la suite, l’IA neuronale a néanmoins vocation à jouer un rôle positif dans le partage du savoir.
Ce texte propose quelques réflexions philosophiques sur la relation triangulaire entre l’intelligence collective, l’intelligence artificielle et la noble finalité de mettre la connaissance à la portée de tous.
L’intelligence collective
Étroitement définis comme des moyens de résoudre des problèmes, les processus d’intelligence collective[4] se présentent sous de multiples formes, dont les plus étudiées sont les espèces statistique, délibérative et stigmergique[5].
Au début du XXe siècle, en Angleterre, le savant Francis Galton visitait une foire agricole. Un concours avait été organisé: on demandait aux huit cents participants, la plupart éleveurs, de deviner le poids d’un bœuf. Mais aucun d’eux n’avait trouvé le poids exact. Galton fit la moyenne de toutes les évaluations et trouva qu’elle était beaucoup plus proche du poids réel qu’aucune des estimations individuelles. La “sagesse” de la foule était supérieure à chacune des intelligences isolées[6]. Cette forme d’intelligence collective statistique – ou comptable – suppose que les individus ne communiquent pas entre eux et ne se coordonnent d’aucune manière. Elle fonctionne d’autant mieux que la distribution des choix ou des prédictions s’étend sur un large spectre, de sorte que les erreurs et les biais individuels se compensent. Ce type d’intelligence collective suppose – paradoxalement – l’ignorance mutuelle. Elle s’exprime dans les sondages ou dans les élections, lorsqu’il est interdit de communiquer les résultats partiels avant que tout le monde ait voté. Cette approche de l’intelligence collective statistique sans connexion entre ses membres a été notamment popularisée par James Surowiecki dans son livre « la Sagesse des Foules »[7]
Une seconde forme d’intelligence collective, délibérative, repose au contraire sur la communication directe entre les membres d’une communauté. Elle résulte de l’échange des arguments et des points de vue. Face à un problème commun, elle peut converger sur un consensus ou se partager entre quelques solutions dont on a – tous ensemble – pesé le pour et contre. Pourvu que l’écoute soit au rendez-vous, chacun amène son point de vue, sa compétence particulière, qui enrichit le débat général[8]. Ce type d’intelligence collective, apparemment idéale puisqu’elle est ouverte et réflexive, est d’autant plus difficile à mettre en œuvre que la collectivité est étendue. Il faut alors établir des formes de hiérarchie et de délégation, certes indispensables mais qui troublent la transparence de l’intelligence collective à elle-même.
Je voudrais maintenant introduire une forme d’intelligence collective moins connue mais qui n’en est pas moins à l’œuvre dans nombre de sociétés animales et qui a trouvé son plus haut degré d’achèvement dans l’humanité: la communication stigmergique. L’étymologie grecque explique assez bien le sens du mot « stigmergie » : des marques (stigma) sont laissées dans l’environnement par l’action ou le travail (ergon) de membres d’une collectivité, et ces marques guident en retour – et récursivement – leurs actions[9]. Le cas classique est celui des fourmis qui laissent une traîne de phéromones sur leur passage lorsqu’elles ramènent de la nourriture à la fourmilière. L’odeur des phéromones incite d’autres fourmis à remonter leurs traces pour découvrir le butin et ramener des vivres à la ville souterraine en laissant par terre à leur tour un message parfumé. Le langage confère à l’humanité un haut degré d’intelligence collective, supérieur à celui des autres mammifères et comparable à celui des abeilles ou des fourmis. Comme d’autres espèces eusociales, nous communiquons en grande partie de manière stigmergique, mais au lieu de marquer un territoire physique au moyen de phéromones ou d’autres types de signaux visuels, sonores ou olfactifs, nous laissons des traces symboliques. Au fur et à mesure de l’évolution culturelle, les signifiants s’accumulent dans des mémoires externes de plus en plus perfectionnées : pierres levées, totems, paysages sculptés, monuments, architectures, signes d’écriture, archives, bibliothèques, bases de données. On peut prétendre que toute forme d’écriture qui n’est pas précisément adressée est une forme de communication stigmergique : des traces sont déposées pour une lecture à venir et font office de mémoire externe d’une communauté.
Les différents processus d’intelligence collectives qui viennent d’être évoqués, statistique (sans communication), délibératifs (à communication directe) et stigmergique (à communication indirecte) ne sont évidemment pas exclusives l’une de l’autre et peuvent fort bien se succéder ou se combiner. Par exemple, les wikipédiens se coordonnent par l’intermédiaire de bases de données communes, délibèrent et votent.
A l’échelle de l’espèce, l’intelligence collective humaine se situe dans la continuité de l’intelligence collective animale, mais elle est plus perfectionnée à cause du langage, des techniques et des institutions politiques, économiques, légales et autres qui nous caractérisent. La principale différence entre les intelligences collectives animale et humaine tient à la culture. Dans une dimension diachronique, notre espèce est entraînée par une vitesse d’apprentissage supérieure à celle de l’évolution biologique. Nos savoir-faire s’accumulent et se transmettent d’une génération à l’autre grâce à nos mémoires externes, au moyen de systèmes de signes, de conventions sociales et d’outils. Aucun individu ne serait « intelligent » s’il n’héritait pas des connaissances créées par les ancêtres. Dans une dimension synchronique, nous participons à une intelligence collective coordonnée où résonnent et se relancent l’architecture conceptuelle de nos mémoires communes et l’organisation sociale de nos collectivités. La définition réciproque des identités et la reconnaissance des problèmes se décident à ce méta-niveau de la culture. Au-delà des procédures utiles (stigmergique, statistique et délibérative) pour résoudre des problèmes, il existe donc une intelligence collective plus holistique, qui circonscrit les capacités cognitives d’une société.
L’évolution culturelle a déjà franchi plusieurs seuils d’intelligence collective. En effet, les inventions de l’écriture, de l’imprimerie et des médias électroniques (enregistrement musical, téléphone, radio, télévision) ont déjà augmenté de manière irréversible nos capacités de mémoire et de communication sociale. Le surgissement d’une communication globale par l’intermédiaire de la mémoire numérique est probablement le plus grand changement social des vingt-cinq dernières années. Cette nouvelle forme de communication par lecture-écriture distribuée dans une mémoire numérique collective représente une mutation anthropologique de grande ampleur. Plongés dans le nouvel environnement numérique, nous interagissons par le moyen de la masse océanique de données qui nous rassemble. Les encyclopédistes de Wikipédia et les programmeurs de GitHub collaborent par l’intermédiaire d’une même base de données. A notre insu, chaque lien que nous créons, chaque étiquette ou hashtag apposée sur une information, chaque acte d’évaluation ou d’approbation, chaque « j’aime », chaque requête, chaque achat, chaque commentaire, chaque partage, toutes ces opérations modifient subtilement la mémoire commune, c’est-à-dire le magma inextricable des rapports entre les données. Notre comportement en ligne émet un flux continuel de messages et d’indices qui transforment la structure de la mémoire et contribuent à orienter l’attention et l’activité de nos contemporains. Nous déposons dans l’environnement virtuel des phéromones électroniques qui déterminent en boucle l’action des autres internautes et qui entraînent par-dessus le marché les neurones formels des intelligences artificielles (IA).
L’intelligence artificielle comme augmentation de l’intelligence collective
Abordons maintenant le thème de l’intelligence artificielle, mais sous l’angle – qui paraîtra peut-être insolite à quelques lecteurs – de l’intelligence collective. Les journalistes et le grand public ont tendance à classer dans “l’intelligence artificielle” les applications considérées comme avancées à l’époque où elles apparaissent. Mais quelques années plus tard ces mêmes applications, devenues banales et quotidiennes, seront le plus souvent réinterprétées comme appartenant à l’informatique ordinaire[10]. Par delà les titres apocalyptiques et les images de jeunes femmes au cerveau chromé censées illustrer “l’intelligence artificielle”, nous assistons depuis le milieu du XXe siècle à un processus de réification formelle et d’extériorisation des fonctions cognitives. L’augmentation de puissance et la baisse des coûts du matériel distribuent ces fonctions cognitives objectivées dans l’ensemble de la société. Des machines interconnectées enregistrent et retrouvent de l’information, effectuent des calculs arithmétiques ou algébriques, simulent des phénomènes complexes, raisonnent logiquement, respectent des syntaxes et des systèmes de règles, extraient des formes à partir de distributions statistiques enchevêtrées… L’informatique automatise et socialise nos capacités de communication, nos facultés de mémoire, de perception, d’apprentissage, d’analyse et de synthèse.
Du fait même de son nom, l’intelligence artificielle évoque naturellement l’idée d’une intelligence autonome de la machine, qui se pose en face de l’intelligence humaine, pour la simuler ou la dépasser. Mais si nous observons les usages réels des dispositifs d’intelligence artificielle, force est de constater que, la plupart du temps, ils augmentent, assistent ou accompagnent les opérations de l’intelligence humaine. Déjà, à l’époque des systèmes experts – lors des années 80 et 90 du XXe siècle – j’observais que les savoirs critiques de spécialistes au sein d’une organisation, une fois codifiés sous forme de règles animant des bases de connaissances, pouvaient être mis à la portée des membres qui en avaient le plus besoin, répondant précisément aux situations en cours et toujours disponibles. Plutôt que d’intelligences artificielles prétendument autonomes, il s’agissait de médias de diffusion des savoir-faire pratiques, qui avaient pour principal effet d’augmenter l’intelligence collective des communautés utilisatrices[11].
Dans la phase actuelle du développement de l’IA, le rôle de l’expert est joué par les foules qui produisent les données et le rôle de l’ingénieur cogniticien qui codifie le savoir est joué par les réseaux neuronaux. Au lieu de demander à des linguistes comment traduire ou à des auteurs reconnus comment produire un texte, les modèles statistiques interrogent à leur insu les multitudes de rédacteurs anonymisés du web et ils en extraient automatiquement des patterns de patterns qu’aucun programmeur humain n’aurait pu tirer au clair. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. L’IA neuronale synthétise et mobilise la mémoire commune. Bien loin d’être autonome, elle prolonge et amplifie l’intelligence collective. Des millions d’utilisateurs contribuent au perfectionnement des modèles en leur posant des questions et en commentant les réponses qu’ils en reçoivent. On peut prendre l’exemple de Midjourney, dont les utilisateurs s’échangent leurs consignes (prompts) et améliorent constamment leurs compétences en IA. Les serveurs Discord de Midjourney sont aujourd’hui les plus populeux de la planète, avec plus d’un million d’utilisateurs. Une nouvelle intelligence collective stigmergique émerge de la fusion des médias sociaux, de l’IA et des communautés de créateurs.
L’IA contemporaine fonctionne ainsi comme le conduit d’une boucle de rétroaction entre la mémoire numérique commune et les productions individuelles qui l’exploitent et s’accumulent à leur tour dans les centres de données. Derrière la machine il faut entrevoir l’intelligence collective qu’elle réifie et mobilise.
Le partage du savoir : vers une intelligence collective neurosymbolique
L’intelligence collective aujourd’hui supportée par l’intelligence artificielle n’est encore que partielle. En effet, l’utilisation des données de l’Internet pour entraîner les modèles mobilise les intelligences collectives stigmergique (la boucle de rétroaction entre les comportements individuels et la mémoire commune) et statistique (l’apprentissage neuronal). Au début des années 2020, la connexion et le renforcement mutuel de ces deux formes d’intelligence collective par les nouveaux dispositifs d’intelligence artificielle a provoqué un choc intellectuel – et des émotions fortes – chez ceux qui en ont aperçu la puissance. Mais une intelligence collective délibérative et réflexive manque encore à l’appel. A l’échelle où nous nous situons, cette intelligence collective délibérative doit porter sur l’organisation des données, c’est-à-dire sur la structure conceptuelle de la mémoire, inévitablement couplée aux pratiques des communautés. Comment faire en sorte que les réseaux de concepts qui informent la mémoire numérique puissent faire l’objet d’une conversation ouverte, transparente, attentive aux conséquences de ses choix? Le Web sémantique et son empilement de standards (XML, RDF, OWL, SPARQL) a certes établi une interopérabilité de formats, mais non pas l’interopérabilité proprement sémantique – celle des architectures de concepts – dont nous avons besoin. Les géants du web ont leurs graphes de connaissances, mais ces derniers sont malheureusement privés et secrets. Wikidata propose un exemple de graphe de connaissance ouvert, mais il est encore bien difficile à explorer et utiliser quotidiennement par le grand public. Il se présente de plus comme une ontologie, celle de l’encyclopédie Wikipédia, alors qu’il faudrait mettre en harmonie et en dialogue la multitude des ontologies qui émergent de pratiques aussi diverses que l’on voudra.
C’est pour résoudre ce problème de l’émergence d’une intelligence collective délibérative (ou réflexive) à support numérique que j’ai inventé IEML (Information Economy MetaLanguage) : une langue artificielle pourvue d’une structure algébrique régulière, dont la sémantique est calculable, qui permet de tout dire et qui peut traduire n’importe quel réseau de concept[12]. IEML est un langage à source ouverte, qui se place dans la perspective d’une augmentation des communs de la connaissance, et dont le développement doit faire l’objet d’une gouvernance décentralisée. Aussi hétérogènes ou divers qu’ils soient, IEML projette les ontologies, graphes de connaissances, collections d’étiquettes et modèles de données sur le même système de coordonnées sémantique : un univers virtuellement infini de différences conceptuelles donnant prise aux algorithmes. IEML peut servir de langage pivot entre les langues naturelles, entre les humains et les machines, entre les modèles d’IA. Il va sans dire que la plupart de ses bénéficiaires n’auront pas à l’apprendre puisque les interfaces des applications, y compris l’éditeur lui-même, seront en langues naturelles ou sous forme iconique. La face « code » d’IEML n’est destinée qu’aux ordinateurs. On peut dès lors envisager qu’une multitude de bases de connaissances aux architectures conceptuelles singulières puissent échanger des modules ontologiques et des informations grâce à l’interopérabilité sémantique assurée par ce langage de métadonnées commun.
Considérons maintenant l’idéal des lumières de mettre la connaissance à la portée de tous. Cette finalité dépasse l’objet « encyclopédie » – qui n’est finalement qu’un moyen particulier adapté aux possibilités techniques et culturelles d’une époque – pour ouvrir de vastes horizons et retentir jusque dans un avenir encore inimaginable.
Ce concept se décompose en deux exercices complémentaires: (a) celui de permettre à toutes les connaissances de s’exprimer, de s’accumuler et de communiquer ; (b) celui de faciliter l’exploration et l’appropriation des connaissances selon la gamme étendue des situations pratiques, des parcours d’apprentissage et des styles cognitifs. On voit l’affinité de cet idéal avec celui d’une intelligence collective – diamétralement opposée au “group think” – qui vise à maximiser simultanément la liberté créatrice et l’efficacité collaborative.
On pardonnera au philosophe que je suis l’évocation d’une utopie concrète, sans doute techniquement réalisable, mais qui – à court terme – vise d’abord à faire penser. Imaginons donc un dispositif destiné au partage des connaissances et qui tire le maximum des possibilités techniques contemporaines. Au cœur de ce dispositif évolue un écosystème ouvert de bases de connaissances catégorisées en IEML, qui émergent d’une multitude de communautés de recherche et de pratique. Entre ce noyau de bases de connaissances interopérables et les utilisateurs humains vivants s’interpose une interface neuronale (un écosystème de modèles) « no code » qui donne accès au contrôle, à l’alimentation, à l’exploration et à l’analyse des données. Tout se passe de manière intuitive et directe, selon les modalités sensori-motrices sélectionnées. C’est aussi par l’intermédiaire de ce giga-perceptron – un métavers immersif, social et génératif – que les collectifs échangent et discutent les modèles de données et réseaux sémantiques qui organisent leurs mémoires. En bonne gestion des connaissances, le nouveau dispositif de partage des savoirs favorise l’enregistrement des créations, accompagne les parcours d’apprentissage et présente les informations utiles aux acteurs engagés dans leurs pratiques.
Pour ce qui est commun, chaque base de connaissance – personnelle ou collective – affiche son univers de discours, ses données et ses statistiques, aussi transparente aux algorithmes qu’elle l’est aux regards humains. Mais pour ce qui est privé, notre dispositif de partage des connaissances assure la souveraineté pratique et légale des individus et des groupes sur les données qu’ils produisent et qu’ils ne divulguent qu’aux acteurs choisis.
L’augmentation décisive de la dimension délibérative de l’intelligence collective grâce à l’utilisation d’un langage de métadonnées commun a des effets multiplicateurs sur les intelligences collectives statistique et stigmergique déjà à l’œuvre aujourd’hui. Une nouvelle infrastructure neurosymbolique plonge l’intelligence collective du futur dans l’univers explorable émanant de ses propres activités cognitives. Il faut cependant bien distinguer l’intelligence collective qui anime les personnes et les collectivités humaines vivantes des extensions mécaniques et des représentations médiatiques qui l’augmentent. Ne faisons pas une idole de l’intelligence artificielle.
Citant Ibn Roshd (l’Averroes des latins), Dante écrit au chapitre I, 3 de sa Monarchie : “Le terme extrême proposé à la puissance de l’humanité est la puissance, ou vertu, intellective. Et parce que cette puissance ne peut, d’un seul coup, se réduire toute entière en acte par le moyen d’un seul homme ou d’une communauté particulière, il est nécessaire qu’il règne dans le genre humain une multitude par le moyen de laquelle soit mise en acte cette puissance toute entière.” Que cette multitude devienne transparente à elle-même dans le nouveau médium algorithmique et nous serons passés de la fourmilière à la cité.
[4] Lévy, Pierre. L’Intelligence collective. Pour une anthropologie du cyberespace. Paris: La Découverte, 1994.
[5] Voir par exemple : Baltzersen, Rolf. Cultural-Historical Perspectives on Collective Intelligence: Patterns in Problem Solving and Innovation. Cambridge, Mass: Cambridge University Press, 2022.
[6] Galton, Francis 1907, Vox populi, Nature, 75, 450-451.
[7] Surowiecki, James. The Wisdom of Crowds. Doubleday, 2004
[8] Voir par exemple : Zara, Olivier. Le chef parle toujours en dernier: Manifeste de l’intelligence collective, Axiopole, 2021, et Mulgan, Geoff. Big Mind. How Collective Intelligence Can Change Our World. Princeton: Princeton University Press, 2017.
[9] Heylighen, Francis. “Stigmergy as a Universal Coordination Mechanism I: Definition and Components.” Cognitive Systems Research 38 (2016): 4–13. https://doi.org/10.1016/j.cogsys.2015.12.002
Heylighen, Francis. “Stigmergy as a Universal Coordination Mechanism II: Varieties and Evolution.” Cognitive Systems Research, 2016, 50–59. https://doi.org/10.1016/j.cogsys.2015.12.007
[10] Lévy, Pierre. “Pour un changement de paradigme en Intelligence artificielle”, Giornale di Filosofia (Roma) numéro spécial sur Technology and Constructive Critical Thought, 15 décembre 2021
[11] Lévy, Pierre. “Les systèmes à base de connaissance comme médias de transmission de l’expertise”, Intellectica numéro spécial “Expertise et sciences cognitives”, ed. Violaine Prince. 1991. p. 187 – 219.
[12] Lévy, Pierre. La Sphère Sémantique. Computation, Cognition, Économie de l’information. Paris-London: Hermès-Lavoisier, 2011.
Comment penser la nouvelle sphère publique numérique? Je commencerai par évoquer le contexte anthropologique et démographique du basculement de la sphère publique dans l’environnement numérique. Dans un second temps, j’analyserai les nouvelles formes de mémoire et de communication supportées par le nouveau médium. J’évoquerai ensuite les figures de la domination et de l’aliénation propres à ce milieu de communication. Je terminerai, comme il se doit, par quelques perspectives d’émancipation.
1 Le contexte
Une nouvelle époque de la culture
Un des facteurs principaux de l’évolution des écosystèmes d’idées réside dans le dispositif matériel de production et de reproduction des symboles, mais aussi dans les systèmes « logiciels » d’écriture et de codage de l’information. Au cours de l’histoire, les symboles (avec les idées qu’ils portaient) ont été successivement pérennisés par l’écriture, allégés par l’alphabet et le papier, multipliés par l’imprimerie et les médias électriques.
A chaque étape, de nouvelles formes politiques sont apparues : villes, palais-temples et premiers états avec l’écriture, empires et cités avec l’alphabet ou le papier, états nations avec l’imprimerie et les médias électroniques.
Les symboles sont aujourd’hui numérisés et calculés, c’est-à-dire qu’une foule de robots logiciels – les algorithmes – les enregistrent, les comptent, les traduisent et en extraient des patterns. Les objets symboliques (textes, images fixes ou animées, voix, musiques, programmes, etc.) sont non seulement enregistrés, reproduits et transmis automatiquement, ils sont aussi générés et transformés de manière industrielle. En somme, l’évolution culturelle nous a menés au point où les écosystèmes d’idées se manifestent sous l’avatar de données animées par des algorithmes dans un espace virtuel ubiquitaire. Et c’est dans cet espace que se nouent, se maintiennent et se dénouent les liens sociaux, là que se jouent désormais les drames de la Polis…
Le basculement démographique
L’hypothèse d’une mutation anthropologique rapide et de grande ampleur se fonde sur des données quantitatives qui ne prêtent pas à controverse.
Accès aux ordinateurs
Concernant l’accès aux ordinateurs, on peut considérer que 0,1 pour cent de la population mondiale avait un accès direct à un ordinateur en 1975 (avant la révolution de l’ordinateur personnel). Cette proportion se montait à 20% dans les pays riches en 1990 (avant la révolution du Web). En 2022, pour les pays européens, la proportion oscillait entre 65% (Grèce) et 95% (Luxembourg). A noter que ces derniers chiffres ne prennent pas en compte les téléphones portables.
Accès à l’Internet
La proportion de la population mondiale qui avait accès à l’Internet était d’environ 1% en 1990 (donc avant le Web), de 4% en 1999, de 24% en 2009, de de 51% en 2018 et de 65% en 2023. Selon l’Organisation internationale des télécommunications, environ 5 milliards de personnes sont des internautes. Toujours pour 2023, mais seulement en Europe, la proportion de la population branchée à l’Internet se monte à 93% (ce sont les données de l’Union Européenne).
Prise de connaissance des nouvelles
Pour compléter ces statistiques avec des données concernant plus directement la politique, 40% des européens et 50% des américains et canadiens prennent connaissance des nouvelles par les médias sociaux (je dis bien les médias sociaux et pas l’Internet en général). On dépasse partout les 50% pour les moins de quarante ans. Pour les données spécifiques concernant la lecture des journaux par opposition à la lecture de textesen ligne, les moins de trente ans lisent les nouvelles en ligne à 80% (données du Pew Research Center).
2 Mémoire et communication numérique
La nouvelle sphère publique
En somme, moins d’un siècle après l’invention des premiers ordinateurs, plus de soixante cinq pour cent de la population mondiale est branchée à l’internet et la mémoire du monde est numérisée. Qu’une information se trouve en un point du réseau et la voici partout. Du texte statique sur papier, nous sommes passé à l’hypertexte ubiquitaire, puis à l’Architexte surréaliste qui rassemble tous les symboles. Une mémoire virtuelle s’est mise à croître, secrétée par des milliards de vivants et de morts, fourmillant de langues, de musiques et d’images, grosse de rêves et de fantasmes, mêlant la science et le mensonge. La nouvelle sphère publique est multimédia, interactive, mondiale, fractale, stigmergique et – désormais – médiée par l’intelligence artificielle.
La nouvelle sphère publique est mondiale. Aussi bien le web que les grands médias sociaux comme Facebook, Twitter, LinkedIn, Telegram, Reddit, etc. sont internationaux et multilingues. La traduction automatique a atteint un point ou l’on peut maintenant comprendre, avec quelques erreurs, ce qu’un internaute écrit dans une autre langue. J’ajoute que, parallèlement à la traduction, la synthèse automatique de longs textes progresse, ce qui ajoute à la porosité des diverses bulles cognitives et sémantiques.
La sphère publique numérique est fractale, c’est-à-dire qu’elle se subdivise en sous-groupes, eux-mêmes subdivisés en sous-groupes, et ainsi de suite récursivement, avec toutes les réunions et intersections imaginables. Ces subdivisions recoupent des distinctions de plateformes, de langues, de zones géographiques, de centres d’intérêts, d’orientations politiques, etc. On peut donner comme exemples les groupes Facebook ou LinkedIn, les serveurs Discord, les canaux YouTube ou Telegram, les communautés de Reddit, etc.
L’intelligence collective stigmergique
Si l’échange de messages point à point a toujours lieu, la majeure part de la communication sociale s’effectue désormais de manière stigmergique. La notion de stigmergie est une des clés de la compréhension du fonctionnement de la sphère publique numérique. On distingue traditionnellement trois schémas de communication : un-un, un-plusieurs et plusieurs-plusieurs. Le schéma un-un correspond au dialogue, au courrier postal classique ou au téléphone traditionnel. Le schéma un-plusieurs décrit le dispositif où un éditeur/émetteur central envoie ses messages à une masse de récepteurs dits « passifs ». Ce dernier schéma correspond à la presse, au disque, à la radio et à la télévision. Internet représente une rupture parce qu’il permet à l’ensemble des participants d’émettre pour un grand nombre de récepteurs selon un schéma en réseau décentralisé « plusieurs vers plusieurs ». Cette dernière description est néanmoins trompeuse. En effet, si tout le monde émet pour tout le monde (ce qui est le cas), tout le monde ne peut pas écouter tout le monde. Ce qui se passe en réalité est que les internautes contribuent à alimenter une mémoire commune et prennent connaissance en retour du contenu de cette mémoire par l’intermédiaire de procédures de recherche et de sélection automatisées. Ce sont les fameux algorithmes de Google, (Page Rank), de Facebook, de Twitter, d’Amazon (recommandations), etc.
L’étymologie grecque explique assez bien le sens du mot « stigmergie » : des marques (stigma) sont laissées dans l’environnement par l’action ou le travail (ergon) de membres d’une collectivité, et ces marques guident en retour – et récursivement – leurs actions. Le cas classique est celui des fourmis qui laissent une traîne de phéromones sur leur passage lorsqu’elles ramènent de la nourriture à la fourmilière. L’odeur des phéromones incite d’autres fourmis à remonter leurs traces pour découvrir le butin et ramener des vivres à la ville souterraine en laissant par terre à leur tour un message parfumé.
On peut prétendre que toute forme d’écriture qui n’est pas précisément adressée est une forme de communication stigmergique : des traces sont déposées pour une lecture à venir et font office de mémoire externe d’une communauté. Si le phénomène est fort ancien, il a pris depuis le début du siècle une nouvelle ampleur. Plongés dans la nouvelle sphère publique numérique, nous communiquons par l’intermédiaire de la masse océanique de données qui nous rassemble. Les encyclopédistes de Wikipédia et les programmeurs de GitHub collaborent par l’intermédiaire d’une même base de données. A notre insu, chaque lien que nous créons, chaque étiquette ou hashtag apposée sur une information, chaque acte d’évaluation ou d’approbation, chaque « j’aime », chaque requête, chaque achat, chaque commentaire, chaque partage, toutes ces opérations modifient subtilement la mémoire commune, c’est-à-dire le magma inextricable des rapports entre les données. Notre comportement en ligne émet un flux continuel de messages et d’indices qui transforment la structure de la mémoire et contribuent à orienter l’attention et l’activité de nos contemporains. Nous déposons dans l’environnement virtuel des phéromones électroniques qui déterminent en boucle l’action des autres internautes et qui entraînent par-dessus le marché les neurones formels des intelligences artificielles (IA).
Le rôle de l’Intelligence artificielle dans la nouvelle sphère publique
Le cerveau biologique abstrait le détail des expériences actuelles en schémas d’interactions, ou concepts, codés par des patterns de circuits neuronaux. De la même manière, les modèles neuronaux de l’IA condensent les données innombrables de la mémoire numérique. Ils virtualisent les données actuelles en patterns et en patterns de patterns. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative.
La mémoire numérique est détachée de son lieu d’émission et de réception, mise en commun, en attente de lecture, suspendue dans les “nuages” de l’Internet, logicielle. Cette masse de donnée est maintenant compressée par des modèles neuronaux. Et les patterns cachés dans les myriades de couches et de connexions des cerveaux électroniques font retomber en pluie des objets symboliques inédits. Nous ne semons des données que pour récolter du sens.
L’IA nous offre un nouvel accès à la mémoire numérique mondiale. C’est aussi une manière de mobiliser cette mémoire pour automatiser des opérations symboliques de plus en plus complexes, impliquant l’interaction d’univers sémantiques et de systèmes de comptabilité hétérogènes.
3 Le côté obscur
L’état-plateforme et la nouvelle bureaucratie dans les nuages
Si les analyses qui précèdent ont quelque validité, le pouvoir politique se joue pour une bonne part dans la sphère publique numérique. Or son contrôle ultime se trouve « dans les nuages », aux mains des bureaucraties célestes qui calculent les interactions sociales et la mémoire. Les nuages, c’est-à-dire les réseaux de centres de données possédées par l’oligopole des GAFAM, BATX et compagnie. C’est pourquoi les prétendants à l’hégémonie politique mondiale, essentiellement les américains et les chinois, s’allient avec les seigneurs des données – ou les soumettent – parce que les oligarques numériques détiennent le contrôle matériel de la mémoire mondiale et de la sphère publique. Eux seuls ont d’ailleurs la capacité de mémoire et la puissance de calcul nécessaires à l’entraînement des modèles d’IA généraux dits « fondationnels ». Ce que j’appelle un État-Plateforme résulte de l’imbrication d’une super-puissance politique avec une fraction de l’oligarchie numérique.
La bureaucratie des nuages est plus efficace que celle des états-nations, héritée de l’ère de l’imprimerie. Déjà, plusieurs fonctions gouvernementales ou régaliennes sont assurées par les grandes plateformes ou par des réseaux numériques « décentralisés ». La liste qui suit n’est pas close :
Vérification de l’identité des personnes, reconnaissance faciale
Cartographie et cadastre
Création monétaire
Régulation du marché
Éducation et recherche
Fusion de la défense et de la cyberdéfense
Contrôle de la sphère publique, censure, propagande, “nudge” (coup de pouce statitique)
Surveillance
Biosurveillance
Les médias sociaux : addictions et manipulations
Notre allégeance aux seigneurs des données vient de la puissance de leurs centres de calcul, de leur efficacité logicielle et de la simplicité de leurs interfaces. Elle trouve aussi sa source dans notre dépendance à une architecture sociotechnique toxique, qui utilise la stimulation dopaminergique et les renforcements narcissiques addictifs de la communication numérique pour nous faire produire toujours plus de données. On sait combien, de ce point de vue, la santé mentale des populations adolescentes est à risque. En plus de la biopolitique évoquée par Michel Foucault, il faut donc maintenant considérer une psychopolitique à base de neuromarketing, de données personnelles et de gamification du contrôle.
Il faut s’y faire : la Polis a basculé dans la grande base de données mondiale de l’Internet. Dès lors, les luttes de pouvoir – toutes les luttes de pouvoir, qu’elles soient économiques, politiques ou culturelles – sont reconduites et compliquées dans le nouvel espace numérique. Sur le terrain glissant des médias sociaux, les camps qui s’affrontent disposent leurs armées de trolls coordonnées en temps réel, équipées de bots dernier cri, renseignées par l’analyse automatique des données et augmentées par l’apprentissage machine. Dans la guerre civile mondiale qui fait rage, politique intérieure et extérieure inextricablement mêlées, les nouveaux mercenaires sont les influenceurs.
Mais toutes ces nouveautés n’invalident pas les règles classiques de la propagande, toujours d’actualité : répétition continuelle, simplicité des mots d’ordre, images mémorables, provocation affective et résonnance identitaire. Personne n’oublie non plus les conseils avisés de Machiavel pour amener l’ennemi à s’auto-détruire : « La guerre secrète consiste à se mettre dans la confidence d’une ville divisée, à se porter pour médiateur entre les deux partis jusqu’à ce qu’ils en viennent aux armes : et quand l’épée est enfin tirée à donner des secours prudemment dosés au parti le plus faible, autant dans le but de faire durer la guerre et de les laisser se consumer les uns par les autres, que pour se garder, par un secours trop massif, de révéler son dessein de les opprimer et de les maîtriser tous deux également. Si l’on suit soigneusement cette marche, on arrive presque toujours à son but. »[1]
La tête baissée sur nos smartphones, nous faisons tourner en boucle les stéréotypes qui renforcent nos identités éclatées et nos mémoires courtes sous le regard narquois des experts de l’intoxication, communicants stipendiés, spécialistes du marketing et agents d’influence géopolitiques…
IA et domination culturelle
Poursuivons cette revue des côtés obscurs de la nouvelle sphère publique par les enjeux de domination culturelle liés à l’Intelligence artificielle. On parle beaucoup des « biais » de tel ou tel modèle d’intelligence artificielle, comme s’il pouvait exister une IA non-biaisée ou neutre. Cette question est d’autant plus importante que, comme je l’ai suggéré plus haut, l’IA devient notre nouvelle interface avec les objets symboliques : stylo universel, lunettes panoramiques, haut-parleur général, programmeur sans code, assistant personnel. Les grands modèles de langue généralistes produits par les plateformes dominantes s’apparentent désormais à une infrastructure publique, une nouvelle couche du méta-médium numérique. Ces modèles généralistes peuvent être spécialisés à peu de frais avec des jeux de données issues d’un domaine particulier et de méthodes d’ajustement. On peut aussi les munir de bases de connaissances dont les faits ont été vérifiés.
Les résultats fournis par une IA découlent donc de plusieurs facteurs qui contribuent tous à son orientation ou si l’on préfère, à ses « biais ». a) Les algorithmes proprement dits sélectionnent les types de calcul statistique et les structures de réseaux neuronaux. b) Les données d’entraînement favorisent les langues, les cultures, les options philosophiques, les partis-pris politiques et les préjugés de toutes sortes de ceux qui les ont produites. c) Afin d’aligner les réponses de l’IA sur les finalités supposées des utilisateurs, on corrige (ou on accentue!) « à la main » les penchants des données par ce que l’on appelle le RLHF (Reinforcement Learning from Human Feed-back – en français : apprentissage par renforcement à partir d’un retour d’information humain). d) Finalement, comme pour n’importe quel outil, l’utilisateur détermine les résultats au moyen de consignes en langue naturelle (les fameux prompts). Il faut noter que des communautés d’utilisateurs s’échangent et améliorent collaborativement de telles consignes. La puissance de ces systèmes n’a d’égal que leur complexité, leur hétérogénéité et leur opacité. Le contrôle règlementaire de l’IA, sans doute nécessaire, semble difficile.
4 Perspectives d’émancipation
Littéracie numérique et pensée critique
Malgré tout ce qui vient d’être dit, la sphère publique du XXIe siècle est plus ouverte que celle du XXe siècle : les citoyens des pays démocratiques y jouissent d’une grande liberté d’expression et peuvent choisir leurs sources d’information parmi un vaste éventail de spécialisations thématiques, de langues et d’orientations politiques. Cette liberté d’expression et d’information, la nouvelle puissance distribuée de création et d’analyse de données, sans oublier les possibilités de coordination sociale offertes par le nouveau médium, tout cela ne représente que des potentialités émancipatrices. Seule une véritable éducation à la pensée critique dans le nouvel environnement de communication permettra d’actualiser ce potentiel de citoyenneté renouvelée. Pour fixer les idées, une étude de la BBC a récemment montré que 50% des jeunes gens de 12 à 16 ans croient aux nouvelles partagées sur les médias sociaux sans les vérifier. Et nous savons d’expérience que les enfants ne sont pas les seuls sujets crédules. Idéalement, la nouvelle éducation à la pensée critique devrait enseigner aux futurs citoyens à s’organiser comme de petites agences de renseignement autonomes qui rangent leurs centres d’intérêts par ordre de priorité, sélectionnent soigneusement des sources diversifiées, analysent les données à partir d’hypothèses explicites et maintiennent une classification pertinente de leur mémoire numérique personnelle. Il faut apprendre à discerner les sources de données en termes de catégories organisatrices, de récits dominants et d’agendas. On inculquera le réflexe journalistique élémentaire de croiser les sources ainsi identifiées. Enfin, les élèves devraient être entraînés à l’intelligence collective stigmergique et à l’apprentissage collaboratif.
Pour une gouvernance de la sphère publique numérique
Je me contenterai ici d’indiquer quelques grandes orientations d’une nécessaire gouvernance de la nouvelle sphère publique plutôt que de déterminer précisément les moyens d’y parvenir. Si le pilotage par gros temps peut nécessiter de nombreux détours, le cap est clair : il s’agit de perfectionner, autant que possible, la dimension réflexive d’une intelligence collective déjà en acte.
A l’appui de cette finalité, la transparence des processus en ligne semble une condition sine qua non. Je vise en particulier, mais pas seulement, une description claire, brève et en langue naturelle des algorithmes et des données d’entraînement des IA.
A l’exemple de Wikimédia, efforçons-nous de maximiser les « communs » de la connaissance.
Ouvrons les jeux de données et les algorithmes selon la voie tracée par le mouvement du logiciel libre.
Assurons la souveraineté pratique et légale des individus et des groupes sur les données qu’ils produisent.
Enfin, décentralisons la gouvernance des interactions en ligne en favorisant les procédures consensuelles. Le mouvement social qui porte la blockchain indique ici un chemin possible.
Afin d’apporter ma pierre au projet d’une intelligence collective réflexive j’ai inventé une langue (IEML, Information Economy MetaLanguage) ayant la même capacité d’expression et de traduction que les langues naturelles mais qui a aussi la régularité d’une algèbre, permettant ainsi un calcul de la sémantique. Cette langue pourrait servir de système de coordonnées sémantique à la nouvelle sphère publique. Elle contribuerait ainsi à transformer la mémoire numérique en miroir de nos intelligences collectives. Dès lors, une boucle de rétroaction plus fluide entre les écosystèmes d’idées et les communautés qui les entretiennent nous rapprocherait de l’idéal d’une intelligence collective réflexive au service du développement humain et d’une démocratie renouvelée. Il ne s’agit pas d’entretenir quelque illusion sur la possibilité d’une transparence totale, mais plutôt d’ouvrir la voie à l’exploration critique d’un univers de sens infini.
[1] Discours sur la première décade de Tite-Live. La Pléiade, Gallimard, Paris, p. 588
[For an English version of this post, click here.]
Le langage permet une coordination dynamique entre les réseaux de concepts entretenus par les membres d’une communauté, de l’échelle d’une famille ou d’une équipe, jusqu’aux plus grandes unités politiques ou économiques. Il permet également de raconter des histoires, de dialoguer, de poser des questions et de raisonner. Le langage soutient non seulement la communication mais aussi la pensée ainsi que l’organisation conceptuelle de la mémoire, complémentaire de son organisation émotionnelle et sensorimotrice.
Mais comment le langage fonctionne-t-il ? Du côté de la réception, nous entendons une séquence de sons que nous traduisons en un réseau de concepts, conférant ainsi son sens à une proposition. Du côté de l’émetteur, à partir d’un réseau de concepts que nous avons à l’esprit – un sens à transmettre – nous générons une séquence de sons. Le langage fonctionne comme une interface entre des séquences de sons et des réseaux de concepts. Et gardons en tête que les relations entre les concepts sont eux-mêmes des concepts.
Les chaînes de phonèmes (des sons), peuvent être remplacées par des séquences d’idéogrammes, de lettres, ou de gestes comme dans le cas de la langue des signes. L’interfaçage quasi-automatique entre une séquence d’images sensibles (sonores, visuelles, tactiles), et un graphe de concepts abstraits (catégories générales) reste constant parmi toutes les langues et systèmes d’écriture.
Cette traduction réciproque entre une séquence d’images (le signifiant) et des réseaux de concepts (le signifié) suggère qu’une categorie mathématique pourrait modéliser le langage en organisant une correspondance entre une algèbre et une structure de graphe. L’algèbre réglerait les opérations de lecture et d’écriture sur les textes, tandis que la structure de graphe organiserait les opérations sur les nœuds et les liens orientés. A chaque texte correspondrait un réseau de concepts. Les opérations sur les textes reflèteraient dynamiquement les opérations sur les graphes conceptuels.
Nous avons besoin d’un langage régulier pour coder des chaînes de signifiants et nous pouvons transformer les séquences de symboles en arbres syntagmatiques (la syntaxe étant l’ordre du syntagme) et vice versa. Cependant, si son arbre syntagmatique – sa structure grammaticale interne – est indispensable à la compréhension du sens d’une phrase, il n’est pas suffisant. Parce que chaque expression linguistique repose à l’intersection d’un axe syntagmatique et d’un axe paradigmatique. L’arbre syntagmatique représente le réseau sémantique interne d’une phrase, l’axe paradigmatique représente son réseau sémantique externe et en particulier ses relations avec des phrases ayant la même structure, mais dont elle se distingue par quelques mots. Pour comprendre la phrase ” Je choisis le menu végétarien “, il faut bien sûr reconnaître que le verbe est “choisir”, le sujet “je” et l’objet “le menu végétarien” et savoir en outre que “végétarien” qualifie “menu”. Mais il faut aussi reconnaître le sens des mots et savoir, par exemple, que végétarien s’oppose à carné et à végétalien, ce qui implique de sortir de la phrase pour situer ses composantes dans les systèmes d’oppositions sémantiques de la langue. L’établissement de relations sémantiques entre concepts suppose que l’on reconnaisse les arbres syntagmatiques internes aux phrases, mais aussi les matrices paradigmatiques externes à la phrase qui organisent les concepts, que ces matrices soient propres à une langue ou à certains domaines pratiques.
Parce que les langues naturelles sont ambiguës et irrégulières, j’ai conçu une langue mathématique (IEML) traduisible en langues naturelles, une langue calculable qui peut coder algébriquement non seulement les arbres syntagmatiques, mais aussi les matrices paradigmatiques où les mots et les concepts prennent leur sens. Chaque phrase du métalangage IEML est située précisément à l’intersection d’un arbre syntagmatique et de matrices paradigmatiques.
Sur la base de la grille syntagmatique-paradigmatique régulière d’IEML, il devient possible de générer et de reconnaître des relations sémantiques entre concepts de manière fonctionnelle : graphes de connaissance, ontologies, modèles de données… Toujours du côté de l’IA, un codage des étiquettes ou de la catégorisation des données dans cette langue algébrique qu’est IEML faciliterait l’apprentissage machine. Au-delà de l’IA, ma vision pour IEML est de favoriser l’interopérabilité sémantique des mémoires numériques et de développer une synergie entre l’autonomisation cognitive personnelle et la réflexivité de l’intelligence collective.
Sur le plan technique, il s’agit d’un projet léger et décentralisé: un dictionnaire IEML-langues naturelles, un analyseur syntaxique (parseur) open-source supportant les fonctions calculables sur les expressions de la langue et une plate-forme d’édition collaborative et de partage des concepts et ontologies. Le développement, la maintenance et l’utilisation d’un protocole sémantique basé sur l’IEML nécessitera un effort de recherche et de formation à long terme.
Les banques classiques proposent désormais à leurs clients une application permettant d’effectuer des transactions sur un smartphone. Mais les données en provenance du smartphone sont le plus souvent décodées et rentrées dans le système central pendant la nuit, puis sont traitées et finalement recodées le lendemain pour être renvoyées à l’application du smartphone. Résultat: il faut deux jours pour que votre compte soit mis à jour après une transaction sur votre téléphone.
Par contraste, dans les systèmes bancaires qui datent du XXIe siècle, tous les traitements ont lieu dans le même centre de données accessible par Internet. De plus, l’application du portable et celles des services centraux communiquent de manière immédiate parce qu’elles utilisent le même format et la même catégorisation des données. Résultat : les comptes sont mis à jour instantanément après une transaction sur le smartphone. On dit que les systèmes d’information des nouvelles banques sont conçues dès l’origine de manière data-centrique. En fluidifiant la circulation de l’information, l’enjeu central de l’organisation data-centrique est d’améliorer l’expérience du client ou, selon une autre formulation, de créer plus devaleur pour le bénéficiaire d’un service.
Art: Emma Kunz
La chaîne de valeur
La notion de valeur possède un champ sémantique étendu. Il peut s’agit de valeurs éthiques, comme la justice, le courage, la sagesse ou l’harmonie des relations humaines. Ces valeurs-là n’ont évidemment pas de contreparties monétaires. Quant aux biens et services qui s’échangent sur le marché, au-delà d’un ajustement provisoire et local de l’offre et de la demande, il est bien difficile d’assigner une essence à leur valeur. La valeur proprement économique peut correspondre à une nécessité (comme celle de manger), à un désir de distraction ou de beauté, à l’accélération d’un travail ennuyeux, à un espoir de gagner de l’argent (loterie ou instrument de spéculation), à une amélioration de la qualité de vie, à l’acquisition de compétences, à une compréhension élargie qui nous rendra capable de mieux décider, à un avantage compétitif, à une image plus flatteuse, etc. La valeur n’est donc pas une fonction simple du travail investi dans la production d’un bien ou d’un service. Elle dépend de l’appréciation subjective et des comparaisons de ceux qui en bénéficient, le tout prenant place dans un contexte économique et culturel changeant. Malgré le caractère évanescent de son essence, qui tient probablement à son rapport au désir, la valeur est au cœur de la théorie économique et de la pratique des entreprises. Toute organisation crée de la valeur pour ses clients (une entreprise privée), son public (un service municipal) ou ses patients (un hôpital) et cette création constitue la principale justification de son existence.
Il est souvent utile de distinguer entre deux personnes distinctes, le client, celui qui paye pour le bien ou le service, et l’utilisateur ou le consommateur, qui s’en sert. Par exemple, le service informatique d’une entreprise (le client) achète un logiciel, mais ce sont les employés (les consommateurs) qui s’en servent. Dans l’analyse qui suit, je me concentrerai sur les relations entre les producteurs et les consommateurs de la valeur. Chaque collaborateur crée de la valeur pour les collègues qui viennent après lui sur la chaîne, la bonne exécution de leur travail dépendant de la sienne. La chaîne de valeur ne s’arrête pas nécessairement aux frontières d’une seule organisation. Elle peut connecter des réseaux d’entreprises, qui peuvent elles-mêmes être implantées dans plusieurs pays, chaque type d’entreprise contribuant qui à la conception, qui à la production des pièces, qui à l’assemblage, qui au transport, qui à la vente. Les chaînes d’approvisionnement, dont on parle tant depuis la pandémie de COVID-19, sont un cas de chaîne de valeur qui concerne plus particulièrement les activités matérielles et les transports au sein d’une filière particulière. Le consommateur final bénéficie de la valeur créée à chaque étape de la production du bien ou du service.
L’augmentation de la productivité des organisations et des filières fonde la prospérité économique. Cette augmentation vient d’innovations permettant de créer plus de valeur à moindre coût. Or la performance globale d’une entreprise – ou d’une plus vaste chaîne de valeur – dépend de la performance de chaque activité ou métier, mais aussi de la liaison qui existe entre ces activités. Nous rejoignons ici le thème de l’organisation data-centrique, car les activités – et plus encore les liaisons entre les activités – nécessitent la réception, le traitement et l’échange d’informations.
De l’informatique centrée sur les applications à l’informatique centrée sur les données
Dans la seconde moitié du XXe siècle, lors de la première vague d’informatisation, chaque “métier” d’une entreprise avait développé des applications pour augmenter ses performances: le système de conception assisté par ordinateur, les automatismes de production, la gestion des stocks, la paye des employés, la comptabilité de l’entreprise, la base de données des clients, etc. Chaque application particulière était conçue selon les normes culturelles et le vocabulaire de son milieu d’utilisation. Les données d’entrées étaient formatées spécialement pour l’application qui les utilisait tandis que les données de sortie étaient mises en forme pour les besoins de leurs utilisateurs immédiats. On avait donc une informatisation “en silos” centrée sur les applications, chaque application commandant la structure de ses données d’entrée et de sortie.
la banque classique du début de ce texte est un bon exemple de cette informatique du XXe siècle, dont le principal défaut est la difficulté de communication entre les applications. En effet, le découpage conceptuel et le formatage des données de sortie d’une application ne correspondent pas forcément à ceux de l’entrée d’une autre application. Par exemple, si le logiciel de gestion de stock ne partage pas ses données avec celui de la base de données des clients, la réponse rapide à une commande est malaisée. Mais depuis le début du XXIe siècle les connexions à l’Internet se sont multipliées et banalisées. Sur le plan matériel, le traitement de l’information a lieu de manière croissante dans les grands centres de données d’Amazon ou de Microsoft qui louent à leurs clients de la mémoire aussi facilement que des places de stationnement et de la puissance de calcul à la demande comme s’il s’agissait d’électricité. Mémoire et puissance de calcul deviennent des marchandises disponibles sur le marché (“commodities“) que l’on a plus besoin de produire soi-même. C’est ce qu’on appelle la nuagique, ou cloud computing en anglais. Sur le plan logiciel, les API (application programming interfaces) sont des interfaces de codage / décodage des données permettent aux applications d’échanger leurs informations. Sous l’effet des mutations qui viennent d’être évoquées, l’informatique centrée sur les applications apparaît de plus en plus obsolète, bien qu’elle reste la situation de fait dans la majorité des organisations en 2021.
Par contraste avec celle du XXe siècle, l’informatique du XXIe siècle est centrée sur les données. Il faut se représenter un entrepôt commun dans lequel différentes applications viennent chercher leurs données d’entrée et déposer leurs données de sortie. Au lieu que des données spécialisées s’ordonnent autour d’applications particulières, ce sont de multiples applications, dont certaines sont éphémères, qui s’ordonnent autour d’une mémoire numérique commune et relativement stable. On dit alors que les applications deviennent interopérables. Le décollement de l’informatique data-centrique peut être datée de 2002, lorsque Jeff Bezos, le dirigeant d’Amazon, a demandé à tous ses développeurs de rendre accessible et de publier leurs données par l’intermédiaire d’une API.
Sur un plan économique, l’informatique data-centrique améliore la productivité des organisations puisqu’elle permet aux différentes activités de partager leurs données et de se coordonner plus facilement : la chaîne de valeur se fluidifie. Contrairement à ces administrations affichant des formulaires indéchiffrables en jargon bureaucratique et qui demandent dix fois aux usagers de redonner les mêmes informations sous des formes différentes parce que leurs applications ne communiquent pas, les grandes entreprises de nuagique comme les GAFAM et les BATX ont habitué les consommateurs à des temps de réaction immédiats et à des interfaces optimisées. Les entreprises les plus riches du monde sont data-centriques. Il en est de même de secteurs dynamiques de l’économie comme l’industrie du jeu vidéo ou de la distribution de films et de séries en ligne. Puisque les bénéfices de l’informatique data-centrique sont tellement évidents, pourquoi n’est-elle pas mise en oeuvre partout? Parce qu’il ne peut exister d’informatique data-centrique hors d’une organisation data-centrique et que le passage à ce nouveau type d’organisation réclame une mutation épistémologique et sociale considérable. Les grandes entreprises de nuagique datent du XXIe siècle ou de la toute fin du XXe siècle. Elles sont nées dans le paradigme numérique et ce sont elles qui ont inventé l’organisation data-centrique. Les industries plus anciennes, en revanche, peinent à suivre.
A une activité quelconque (production, vente, etc.) correspond une culture pratique, c’est-à-dire une certaine manière de découper les objets, de nommer leurs relations et d’enchaîner les opérations. L’informatisation d’une activité suppose non seulement la création d’une application mais aussi d’un système de métadonnées, et l’un comme l’autre sont conditionnés par une culture pratique datée et située. Pour fusionner les collections de données d’une organisation, il faut “réconcilier” les différents systèmes de métadonnées et, cela fait, s’engager à maintenir et faire évoluer le système de métadonnées commun pour accompagner les besoins. Tout cela demande de nombreux entretiens avec des experts des différentes sphères d’activité et des réunions d’harmonisation où les marchandages sur les définitions de concepts peuvent être rudes. La réconciliation des modèles de données n’est pas moins complexe que n’importe quelle négociation interculturelle alourdie par des enjeux de pouvoir. En effet, pour la plupart des acteurs concernés, il faut non seulement réviser ses habitudes cognitives et ses manières de faire, mais encore renoncer à une part de souveraineté locale. Il ne va plus être possible d’organiser sa mémoire pratique sans se coordonner avec les autres activités de la chaîne de valeur aussi bien sur un plan sémantique que sur un plan technique. Dès lors, la gouvernance des données, dont le principal responsable est le “Chief Information Officer” ou “Chief Data Officer“, devient une des principales fonctions de l’entreprise.
La gouvernance des données
La gouvernance des données doit faire face à deux problèmes entrelacés: sémantique et politique. Sur un plan politique, on remarquera que les systèmes de métadonnées – c’est-à-dire les catégories qui organisent les données – sont toujours liées aux caractéristiques sociales, culturelles et aux activités pratiques de leurs utilisateurs. Par exemple, dans telle grande entreprise de télécommunication, les données de consommation vont être organisées par “lignes” et non par “clients”. Or un client peut avoir plusieurs lignes et la même ligne peut être utilisée par plusieurs clients. Il est clair que les relations avec la clientèle serait plus aisée si les données étaient classées et analysées en fonction des personnes physiques ou morales qui utilisent les services de l’entreprise. Mais ce n’est pas le cas parce que l’entreprise de télécommunication est dominée par une culture d’ingénieurs pour qui les “vraies” données sont celles des lignes. Cette approche par le matériel plutôt que par l’humain permet aussi de rendre la tarification la plus “objective” possible et de la soustraire aux négociations. En somme, la manière dont une communauté organise sa mémoire reflète et réifie son identité. Réorganiser sa mémoire revient à changer d’identité. Le parallélisme entre métadonnées et contextes sociaux fait de la gouvernance des données un enjeu politique.
Quant à l’enjeu sémantique, il ne concerne plus la face subjective de l’identité – qu’elle soit personnelle ou collective – mais sa face logique. Si l’on veut que les applications soient interopérables d’un bout à l’autre de la chaîne de valeur, les objets, des relations et des processus doivent être nommées de façon unique. La difficulté vient ici de la multiplicité des métiers, chacun avec son propre jargon, et de la pluralité des langues, particulièrement dans les entreprises ou les filières internationales. Lorsqu’il s’agit de coordonner des activités, les synonymes (mots différents pour dire la même chose) et les homonymes (un mot signifiant plusieurs choses différentes) deviennent des obstacles à la collaboration. Les homonymes, en particulier, peuvent provoquer de graves erreurs de calcul. Par exemple, il est arrivé dans une compagnie aérienne que le mot “Asie” recouvre des aires géographiques différentes selon les branches et que cette incohérence sémantique provoque des erreurs de décision stratégique. Quand toutes les opérations sont automatisées et dirigées par les données, un terme ambigu peut donner de fausses indications aux dirigeants, voire interrompre une chaîne d’approvisonnement.
Le “dictionnaire de données” ou référentiel est le principal outil de la gouvernance des données. C’est là que sont énumérés tous les types de données et la manière unique de les catégoriser. Si, comme c’est souvent le cas, le référentiel n’a pas été unifié, il faut alors faire appel à des “tables d’alignement” entre systèmes. Au-delà des problèmes de cohérence, la gouvernance des données doit aussi s’occuper de la qualité des données. A cette fin on utilise un “catalogue de contrôle des données”, qui énumère les méthodes pour tester la qualité des données en fonction de leur nature. Par exemple, comment détecter les erreurs sur les noms de clients lorsque l’entreprise opère dans soixante-dix pays? Il y a des pays où on ne découpe pas en nom et prénom, d’autres pays ou des nombres sont acceptables dans un nom (en Ukraine), d’autres où un nom peut y avoir quatre ou cinq consonnes de suite, etc.
Le passage à l’organisation data-centrique implique un changement de culture et une évolution du management. Soudain, les mots et les concepts deviennent importants, et cela non seulement dans la communication et le marketing, mais aussi dans la production, qui n’est pas moins informatisée que les autres fonctions de l’entreprise. De plus, le changement culturel réclame plus d’ouverture et de communication entre départements, agences, services et métiers. Pas de bonne gestion sans gestion des données et pas de gestion des données sans bonne gestion des métadonnées. On croyait l’intérêt pour la sémantique réservée aux départements de cultural studies entichés de french theory dans les universités américaines, et voici qu’elle conditionne la productivité des entreprises!
Distinguer les mots et les concepts
Je note pour finir que les outils d’édition et de gestion de métadonnées les plus sophistiqués du marché (Pool Party, Ab Initio, Synaptica) n’ont aucun moyen de distinguer clairement entre les “mots” ou “termes” dans une langue naturelle particulière et les “concepts” ou “catégories”, qui sont des notions plus abstraites et trans-linguistiques. Le même concept peut être exprimé par différents mots dans différentes langues et le même mot peut correspondre à plusieurs concepts, y compris dans la même langue (le cardinal est-il un dignitaire ecclésiaste, un oiseau, ou un glaïeul?). Les mots sont ambigus et multiples, mais reconnaissables par des humains. Les concepts formels sous-jacents sont uniques et devraient être interprétables par les machines. En proposant un système de codage univoque des concepts et de leurs relations qui soit indépendant des langues naturelles, IEML permet de distinguer et d’articuler les mots et les concepts. Ce nouveau système de codage fait non seulement progresser la sémantique, mais recèle un pouvoir insoupçonné de fluidifier les chaînes de valeur et d’augmenter l’intelligence collective.
P.S. Je remercie John Horodyski, Paul-Louis Moreau, Samuel Parfouru et Michel Volle d’avoir bien voulu répondre à mes questions, contribuant ainsi à informer ce billet. Erreurs, inexactitudes et opinions hétérodoxes ne doivent néanmoins être attribuées qu’à l’auteur, Pierre Lévy.