Qu’est-ce qui distingue l’humain de la machine ou bien, ce qui revient au même, de l’exécutant d’une tâche? Une tâche peut être automatisée et mise en œuvre par une machine. Cela pourrait-il mener au remplacement de l’humain? L’évolution technique et économique transforme la nature même du travail : l’humain (avec ses compétences présentes) sera-t-il alors dépassé? Mais, pour peu que l’on n’oublie pas son unité organique, son potentiel d’évolution et sa dimension éthique, l’humain total est irremplaçable et indépassable. Si on l’envisage d’un point de vue humaniste, l’entièreté de l’humain vivant ne peut être séparé d’une dimension éthique qui vise précisément son intégrité. Je vais d’abord décrire dans ce bref article (le texte d’une conférence destinée à des formateurs) trois aspects interdépendants de cette humanité éthique intégrale : l’autonomie du sujet, la dignité de la personne et la responsabilité de l’acteur. Dans un second temps je vais passer en revue les compétences – en d’autres temps on aurait dit les vertus – nécessaires au sujet pour conquérir son autonomie, à la personne pour maintenir sa dignité et à l’acteur pour assumer ses missions de manière responsable. Notre rôle en tant que formateurs est justement d’aider nos étudiants à acquérir les compétences qui leur serviront dans leur métier mais aussi dans d’autres aspects de leur existence, puisque l’humain forme un tout.
LE SUJET
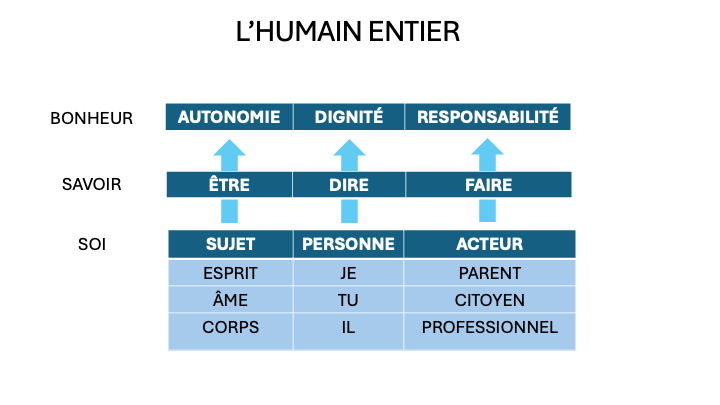
Le sujet désigne l’humain en lui-même ou en intériorité. Il se compose de trois parties hétérogènes mais qui forment néanmoins une unité organique : le corps, l’âme et l’esprit. Le corps désigne la sensori-motricité, les fonctions d’alimentation, de reproduction et l’organicité en général. Il est traversé par des pulsions qui visent des objets sensibles. L’âme renvoie à l’imagination active, aux émotions, aux jeux de la sympathie et de l’antipathie, à la sociabilité, au sens moral spontané. Elle est animée par des désirs qui visent des objets affectifs. Quand à l’esprit, c’est le siège des fonctions symboliques : pensée, langage, récit, pensée abstraite, raisonnement, création de sens, réflexion, planification, contemplation des fins ultimes. La pensée conceptuelle vise des objets logiques, des références. L’activité du sujet est intentionnelle c’est-à-dire qu’elle vise par nature un monde peuplé d’objets qui sont à la fois logiques, affectifs et physiques. L’alignement entre les trois parties du sujet, leurs intentions et leurs objets est toujours dépendant d’un équilibre délicat et jamais parfait. Les problèmes à résoudre sont nombreux : l’orientation (vers quels objets), la qualité affective (répulsion, attraction, dysphorie, euphorie…), l’intensité et la convenance des désirs, mais aussi leur confluence, leur alternance et leur équilibre. La santé de la machine désirante qu’est le sujet se mesure à son autonomie, qu’on peut définir par les trois qualités 1) d’auto-représentation ou connaissance de soi, 2) d’auto-réparation physique et mentale et 3) d’auto-régulation, y compris le jugement pratique. L’autonomie du sujet nécessite un mimimum d’intégration de l’âme, du corps et de l’esprit, de leurs intentions et de leurs objets, ainsi que le support d’une mémoire transversale permettant la correction et l’apprentissage.
LA PERSONNE
La personne peut être physique (singulier) ou morale (pluriel). Toutes les langues naturelles possèdent les trois rôles grammaticaux : première, deuxième et troisième personne. Le dialogue suppose en effet les rôles tournants de l’interlocution qui correspondent aux trois pronoms personnels. Celui qui parle, le destinateur, est la première personne (je, nous) ; celui à qui l’on s’adresse, le destinataire, est la deuxième personne (tu, vous) ; celui de qui l’on parle, le désigné, est la troisième personne (il, ils, elle, elles). Mais ce sont évidemment les mêmes personnes qui jouent les trois rôles et qui, de ce fait, sont prises dans une multitude de jeux de langages et de contextes pratiques qui, le plus souvent, leur échappent. Le sujet vit dans une intériorité du désir qui englobe le monde dans lequel et pour lequel il vit. La personne, en revanche, vit dans le langage, c’est pourquoi elle ne s’appartient pas complètement : elle n’est pas seulement ce qu’elle dit, mais ce qu’on lui dit et ce qu’on dit d’elle. De plus, le langage au sens large ne se limite pas aux paroles volantes mais comprend aussi les mots écrits et imprimés, les images, la communication en ligne. Dressons maintenant l’inventaire de la personne qui se distribue dans l’univers du langage. Le geste de la première personne est l’auto-référence du locuteur. Elle se trouve ici dans tout ce que le sujet a dit, mais aussi dans tout ce qu’il a accueilli et compris des discours à la première personne en provenance des autres. Le geste de la deuxième personne est l’adresse à un destinataire. Cela signifie qu’une personne se trouve non seulement dans toutes les paroles qu’on lui a adressées mais aussi dans les “tu” ou “vous” qu’elle a elle-même destinée aux autres. Enfin, la troisième personne correspond au geste de la désignation de l’absent. Elle comprend ce qu’on a dit d’elle et ce qu’elle a dit des autres. Or les personnes à qui l’on s’adresse et que l’on désigne sont aussi des sujet pensants et parlants à la 1ère personne. La dignité de la personne vient de ce qu’elle est la trace d’un sujet dans le langage. À ce propos, l’insulte, la médisance et la calomnie sont des atteintes à la personne qui sont condamnées par toutes les traditions de sagesse. De même que le sujet doit viser l’autonomie et favoriser celle des autres, la personne doit conserver sa propre dignité et respecter celle des autres.
L’ACTEUR
L’acteur responsable est encore plus extérieur au sujet que la personne parce que les missions qui lui incombent viennent de sa participation à des communautés familiales, politiques et professionnelles qu’il ne choisit pas, ou seulement partiellement, et dont il ne maîtrise pas les tenants et aboutissants. L’acteur est membre d’une communauté familiale. Nous sommes tous liés par des liens de parenté mais nous ne choisissons ni notre ascendence ni notre descendance. La parenté nous lie à des personnes envoyées par la biologie ou par une lignée symbolique. Nous devons néanmoins loyauté, amour et assistance à nos parents, à nos frères et sœurs, à nos enfants, etc. En tant que membres d’une communauté politique, il nous faut respecter les lois. Et si nous participons au gouvernement nous devons rendre service aux citoyens et respecter leurs droits. La participation à la vie de la cité peut prendre beaucoup d’aspects : le vote, la vie associative, l’engagement politique, etc. Ici encore la loyauté est une qualité essentielle vis-à-vis d’un parti, d’une ville, d’une région, d’un pays, d’un empire, etc. Enfin, l’action professionnelle implique une responsabilité que les notions de conscience professionnelle et d’amour du travail bien fait désignent assez justement. Les valeurs pointent ici vers la perfection de l’œuvre et le perfectionnement de l’ouvrier. Le métier, lui aussi, exige loyauté et intègrité. Nous avons des obligations envers nos employeurs, nos employés, nos collaborateurs. Il nous faut aussi transmettre autant que possible nos connaissances et nos savoir-faire. À chaque mission – familiale, politique, professionnelle – correspond une dé-mission possible. Comme dans les cas de la personne et du sujet, les rôles sociaux que nous jouons demandent des types de responsabilité différentes, mais l’acteur est le même. Il y a donc encore à trouver un alignement, un équilibre, des alternances entre les missions de la parenté, de la citoyenneté et du métier.
Figure 1
Finalement, cet équilibre, cet alignement, cette intégration doit se faire entre le sujet (pour soi), la personne (dans le langage) et l’acteur (dans l’action) puisqu’il s’agit bien sûr du même être humain.
LES COMPÉTENCES
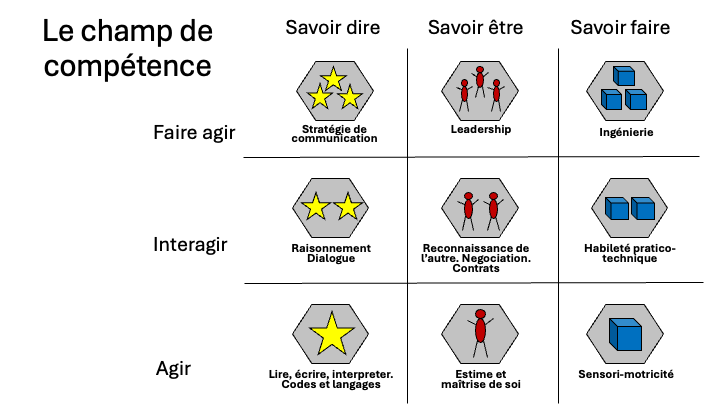
Les compétences ou savoirs qui nous permettent d’atteindre les fins éthiques ne peuvent être séparées les unes des autres comme la Figure 1 pourrait le laisser penser suite à une lecture trop rapide. Savoir-dire, savoir-être et savoir-faire s’impliquent réciproquement et interviennent ensemble dans l’effort humain pour atteindre les fins éthiques que sont l’autonomie, la dignité et la responsabilité. La Figure 2 montre une représentation simplifiée d’un champ de compétence unifié et interdépendant qui permet d’atteindre les fins éthiques de l’Homme tels que je les ai définis ici. Cette table est inspirée du trivium de l’Antiquité gréco-latine et du Moyen-âge européen. La grammaire, la dialectique et la rhétorique de cette tradition correspondent à la colonne de gauche, qui concerne le rapport aux signes, ou savoir dire. Pour faire bonne mesure, j’y ai ajouté une grammaire, une dialectique et une rhétorique des êtres et des choses. Au premier degré, correspondant à la rangée du bas (grammaire), la compétence porte sur l’édification de soi. Au second degré, à la rangée intermédiaire (dialectique), elle porte sur l’interaction. Au troisième degré, c’est-à-dire à la rangée supérieur (rhétorique), elle consiste à faire agir des signes, des êtres ou des choses. Le tout forme un continuum à explorer progressivement et à cultiver le mieux possible. On vérifiera facilement que tous ces types de compétences sont utiles non seulement dans la vie professionnelle mais dans la vie en général.
Figure 2
CONCLUSION
L’autonomie du sujet implique l’unité du corps, de l’âme et de l’esprit. La dignité de la personne vient de ce qu’elle n’est pas seulement celle dont on parle et à qui l’on parle mais aussi celle qui dit « je » à partir d’une intériorité sensible et pensante. L’acteur social intègre est simultanément responsable devant une communauté familiale, une collectivité politique et un réseau professionnel. Notre développement éthique multidimensionnel se joue sur un champ de compétences unifié à conquérir progressivement : maîtriser les signes, les relations humaines et le monde matériel ; pouvoir penser, se remettre en question et apprendre. Le sujet autonome, la personne et sa dignité, l’acteur social et ses multiples responsabilités, l’excellence et le dynamisme du collaborateur – qui est notre principal souci – sont des aspects distincts de la même humanité. Ils forment ensemble une totalité qu’aucune machine ne peut incarner. À nous de ne pas l’oublier!
Le combat de Jacob avec l’Ange. Marc Chagall. 1967.
Cette réflexion philosophique sur l’IA ne s’intéresse pas à des questions telles que « Les modèles sont-ils vraiment intelligents ? » ou « Ont-ils une conscience ? », mais propose plutôt une méditation sur ce que devient la personne à l’ère des symboles électrifiés. Pour mener cette réflexion, je vais d’abord proposer une structure anthropologique invariante qui explicite notre manière de produire du sens, aussi bien pour la personne individuelle que pour la collectivité dans son ensemble. Je montrerai ensuite comment, sur le fond de cette structure invariante, trois grandes configurations se sont succédées depuis les deux ou trois derniers millénaires, correspondant respectivement aux âges des symboles manuscrits, imprimés et électrifiés. Les trois régimes herméneutiques se sont ajoutés les uns aux autres en s’hybridant pour dessiner la stratification que nous connaissons aujourd’hui. Mais pour la clarté de l’exposé je me contenterai de décrire chaque couche l’une après l’autre dans ce qu’elle a d’original. Je développerai plus particulièrement pour finir le cas de l’herméneutique numérique, le rôle qu’y joue l’intelligence artificielle et la nouvelle figure de la personne humaine qui en émerge.
La croix herméneutique
Le schéma général de création de sens croise deux axes. Un axe de la lecture et de l’écriture connecte, à gauche le corpus de textes et d’observations accessibles et, à droite les clés d’interprétation de ce corpus. Les clés donnent sens au corpus qui, en se laissant interpréter, valide les clés de lecture. Un axe existentiel, ou axe du salut, connecte l’immanence où se tiennent la personne individuelle et sa communauté – ici bas – à une transcendance invisible et inaccessible : au-delà. Au croisement des deux axes un opérateur herméneutique unique permet simultanément l’interprétation des corpus et la connexion de l’immanence avec la transcendance. En effet, une interprétation n’est valable que si elle contribue d’une manière ou d’une autre au salut ou à la solution d’un problème existentiel. D’autre part, toute relation existentielle entre la transcendance et l’immanence doit mobiliser des concepts et des récits, un processus de dotation de sens d’ordre linguistique ou, plus généralement, symbolique. C’est pourquoi l’opérateur central mobilise simultanément les deux axes. Il ne donne vie à l’un que parce qu’il anime l’autre.
Le régime manuscrit
À l’époque du manuscrit, les bibliothèques sont rares, les livres coûteux et les lettrés ne rassemblent qu’une élite restreinte. Les corpus comprennent les observations de la nature permises par les instruments du temps et des canons plus ou moins sacralisés comme les œuvres des poètes et philosophes grecs ou les livres bibliques. Les clés de lectures sont proposées par les sagesses stoïcienne et néoplatonicienne, le nouveau testament avec le credo conciliaire pour les chrétiens et la Torah orale pour les juifs. Dans les traditions gréco-romaines et bibliques, la personne se conçoit en relation avec une transcendance verticale, de type divin. Elle est un sujet moral précisément parce qu’elle est en rapport avec quelque chose d’universel qui la dépasse. Ainsi du monde des idées de Platon et des hypostases néo-platoniciennes. Ainsi du Logos divin et de la Loi naturelle qui anime le cosmos pour les stoïciens. L’humain porte en lui une étincelle du Logos universel. Une même relation avec la transcendance se vit dans la tradition biblique, par un dialogue avec une divinité universelle qui n’en n’est pas moins personnelle. Au centre de la croix herméneutique se trouve une parole divine, une raison commune à l’immanence de cette vie-ci et à la transcendance de l’au-delà : Hermès, le Logos, le Christ. Et c’est cette même figure centrale, ce même Logos qui garantit la bonne interprétation des textes et des phénomènes naturels.
Par le signifiant des symboles, le langage avait porté à la représentation sensible les concepts et modèles mentaux qui animaient l’esprit des primates derrière la scène de leur conscience phénoménale. Avec le dialogue, le questionnement et le récit, une conscience réflexive s’est élevée au-dessus de la conscience phénoménale et l’a profondément transformée en retour. L’écriture, cette mémoire artificielle, ajoute à la conscience réflexive gagnée par le langage de nouvelles possibilités d’objectivation de la pensée et d’esprit critique : un second degré de réflexivité. Mais l’ère du manuscrit demandait encore aux lettrés un sérieux entraînement de la mémoire naturelle, ce dont témoignent les arts mnémotechniques de l’Antiquité et du Moyen-Âge, tout comme la répétition orale des textes du canon et l’habitude d’apprendre par cœur.
La personne n’est alors pas seulement une porteuse de droits, un rôle social ou une singularité individuelle, c’est une conscience réflexive qui, en accueillant le divin, pointe vers plus haut que soi : tel est le fondement de sa dignité. Ce trait s’accentue avec le christianisme, notamment après les quatre premiers conciles œcuméniques, qui établissent le credo trinitaire, et l’œuvre de St Augustin, qui ouvre l’intériorité à l’infini. La figure exemplaire du Christ – à laquelle les croyants étaient appelés à s’identifier – est entièrement Dieu et complètement Homme. En écho aux philosophies gréco-latines ambiantes, le Christ incarne également le Logos, l’axe du monde qui unit le ciel et la terre. Après sa descente dans la chair et son sacrifice, les fidèles reçoivent l’Esprit saint, qui est une personne de la trinité et, par son intermédiaire, participent à la relation entre le Père et le Fils : ils entrent ainsi dans la vie divine et se connectent à leurs semblables par les liens de la charité. La personne devient alors un nœud de relations plutôt qu’une substance.
Le régime imprimé
Les cartes géométriques, les nouveaux véhicules maritimes et terrestres, les lunettes, les microscopes et autres instruments de mesure augmentent le champ de la nature observable. L’imprimerie étend le corpus des textes accessibles. Le lettré moderne dispose de nombreuses bibliothèques, d’une mémoire collective mieux distribuée, plus stable et standardisée par les éditions imprimées. C’est d’ailleurs une des raisons de la généralisation de l’alphabétisation et peut-être de la montée d’une pensée critique augmentée qui allait dissoudre le rapport à la transcendance des âges antérieurs. Au début de l’ère de l’imprimé, entre le XVIe et le XVIIIe siècle, la transcendance verticale s’efface peu à peu de l’horizon de sens européen. Au XVIIe siècle, un bref point d’équilibre met en équivalence Dieu et la Nature. Dans l’aphorisme médiéval “Dieu est une sphère dont le centre est partout et la circonférence nulle part” Pascal remplace Dieu par la nature mais conserve l’image. Spinoza trace dans l’Éthique sa célèbre équivalence : “Dieu ou la nature”. Leibniz combine la nature et la grâce dans le même système philosophique. Mais dès le XVIIIe siècle la nature prend le dessus et Dieu ne conserve plus qu’un rôle honorifique. La nature humaine de David Hume se joue sur la scène immanente de l’expérience sensible et les sentiments moraux d’Adam Smith obéissent aux subtils jeux de renvois et de reflets de la sympathie, de l’envie et de l’intériorisation du regard de l’autre. La transcendance cesse de pointer vers le haut pour s’étendre dans le plan de la nature et de l’histoire humaine. À la place d’un Logos unissant l’humain et le divin surgit au centre de la croix herméneutique une raison humaine autonome qu’Emmanuel Kant s’est efforcé de fonder philosophiquement.
Au XIXe siècle, face à la croissance de la bibliothèque et à la masse en expansion des journaux, de nouvelles clés de lecture interprètent le mouvement des sociétés comme les existences personnelles. Ce sont la Science avec ses applications techniques et industrielles, l’Histoire et son progrès, la Nation et son indépendance, la Liberté et l’Égalité soutenus par des droits naturels universels et qui inspirent divers mouvements d’émancipation. Ces filles de la Raison humaine autonome habitent les consciences et s’érigent en nouvelles divinités laïques avec lesquelles l’Homme moderne négocie le sens de sa vie. Les droits de l’Homme ont sanctifié une dignité de la personne qui ne dépend plus désormais d’une quelconque relation avec le divin, mais qui hérite pourtant de la période précédente la dignité absolue de la personne. La liberté de conscience, d’expression, d’association, ne sont pas seulement des droits politiques, mais des potentialités de l’existence humaine à actualiser.
Le régime électronique
L’ère électronique commence au XXe siècle parmi les guerres coloniales, les conflits mondiaux, les totalitarismes, les famines politiques et les génocides. Un individualisme de masse s’est développé en même temps que la fabrication et la dissémination industrielle des messages symboliques. Le XXe siècle déboulonne les idoles du 19e siècle. La raison humaine autonome devient la cible de toutes les attaques. À sa place s’imposent l’inconscient, l’absurde, la destination aveugle de l’être heideggérien, la raison instrumentale aliénante, la propagande industrielle, les structures impersonnelles qui déterminent nos cultures et l’omniprésence des relations de domination jusque dans les tréfonds du psychisme de chacun. Pourtant, une exceptionnelle croissance démographique nous a fait passer d’un milliard huit cent millions de personnes en 1914 à huit milliards trois cent millions en 2026, parmi lesquelles six milliards ou plus sont connectés à l’internet. La population a vu son espérance de vie doubler, a été multipliée par 4,5 et s’est globalement interconnectée en un peu plus d’un siècle, et cela justement grâce aux bienfaits de la raison occidentale tant décriée, elle-même dépositaire du legs oublié de l’Antiquité. Mais nous ne sommes qu’au début de la civilisation électronique, en pleine crise du sens due à l’extrême rapidité des évolutions culturelles. Peut-être que le mouvement de déconstruction philosophique du XXe siècle ne fait que déblayer les ruines d’une époque antérieure pour laisser la place à de nouvelles manières de faire sens et de constituer la personne. Les deux faits les plus notables de la période contemporaine sont le ralentissement de la croissance démographique, et bientôt son retournement en décroissance, ainsi que l’éclosion de l’intelligence artificielle générative, que l’on peut considérer comme la forme la plus avancée de l’électrification des symboles. Après une inévitable période de crise, le changement de régime démographique nous obligera peut être à envisager une croissance qualitative outillée par l’IA, un développement humain axé sur le perfectionnement de l’intelligence collective et la culture du sens.
L’électrification des symboles, le numérique et l’Internet ont mis à portée de main l’ensemble des œuvres de l’esprit dont l’humanité a gardé la trace, la littérature scientifique contemporaine, tout comme la marée montante des chansons, des vidéos, des photos de vacances, des nouvelles et des commentaires sur les réseaux sociaux. Et le Niagara digital s’abîme dans les profondeurs des centres de données.
La transcendance finie
Que devient la personne dans ce nouvel environnement? De quels outils symboliques disposons-nous pour donner sens à notre existence? Au pôle bas de l’axe existentiel, commençons par situer ce qu’il faut bien appeler la personne naturelle, pourvue d’un corps, d’une âme sensible et imaginative comme celle des animaux et d’un esprit proprement humain, capable de langage et d’abstraction. La personne naturelle intègre étroitement ces trois aspects, elle se creuse d’une intériorité sans fond, s’expérimente comme une mémoire qui palpite et découvre assez tôt qu’elle est mortelle, ce qui la rend d’autant plus précieuse. Or nous avons vu que, dans son besoin de sens, la personne se vit souvent dans une relation avec ce qui la dépasse : la Divinité, le monde des Idées, la Raison universelle, l’Humanité, etc. Je fais l’hypothèse que ce que l’on appelle “l’intelligence artificielle” commence déjà à jouer aujourd’hui et jouera encore plus dans l’avenir un rôle de médiation entre la personne naturelle et la transcendance. Mais cette nouvelle transcendance n’est pas religieuse ni même philosophique (purement conceptuelle), elle ne relève pas de l’invisible ou du mystère. Il s’agit plutôt des réalités actuelles interdépendantes que sont la mémoire numérique mondiale à laquelle s’abreuvent nos esprits, de la population de Sapiens avec qui nos âmes interagissent localement et du technocosme planétaire irrigué de flux électroniques qu’habitent les corps mobiles des individus. Mais si nous avons affaire à des réalités actuelles, pourquoi parler de transcendance? Le mot transcendance a bien des significations. Il dénote ici ce qui dépasse toute saisie intellectuelle ou pratique possible de la part d’un individu et dont pourtant il dépend. Un invisible avec qui néanmoins on peut enter en relation. Parce que la taille et la complexité de la mémoire numérique, le grouillement des relations humaines et l’intrication multicouche du technocosme dépassent absolument la personne naturelle aussi bien à cause de ses compétences limitées que par le temps borné dont elle dispose. L’actualité de la personne collective dépasse structurellement la personne naturelle, elle n’est totalisable par aucun individu et elle excède l’horizon de chacun. Je désigne donc ici une transcendance relative, réellement finie mais pratiquement infinie eu égard à nos capacités. L’infini n’est pas nécessaire à la transcendance, celle des Grecs de l’époque classique – comme dans le cas du dieu d’Aristote – était finie. Je vais maintenant m’attacher à décrire la transcendance finie de l’ère numérique de manière plus précise.
Le technocosme désigne l’ensemble des infrastructures, bâtiments, véhicules, outils, capteurs et interfaces connectées. La population qui vit là s’anime de mille relations affectives, sociales et politiques parmi les naissances et les morts qui se succèdent. Quant à la mémoire collective, elle témoigne d’une multitude enchevêtrée de modes d’expressions, d’horizons de sens et d’écologies de pratiques qui s’accumulent siècle après siècle. La mémoire collective, la population de sapiens et le technocosme Coémergent en interdépendance et forment une personne collective en évolution. Cette personne collective est certes actuelle, elle existe dans le temps et l’espace, mais elle est néanmoins chapeautée dans notre esprit par une entité virtuelle qui lui confère son unité conceptuelle : l’espèce humaine, le “grand être” d’Auguste Comte ou toute autre icône capable d’intégrer la multiplicité insaisissable de l’humain. Ces représentations succèdent aux anciennes figurations de l’Homme primordial qui condensaient toutes les potentialités de notre espèce fille du langage, telles que le Gayomard de Zoroastre ou l’Adam Kadmôn de la Cabale. Il y a quelque chose comme une image de Dieu dans cette Humanité éminente qui surplombe le fourmillement de la population vivante.
Nous n’accédons pas directement à la mémoire collective. Il y a d’abord l’ensemble des inscriptions et archives matérielles, qui deviennent de plus en plus rares au fur et à mesure que l’on remonte dans le passé ; puis vient le sous-ensemble en augmentation des traces numérisées ; enfin les modèles d’intelligence artificielle nous offrent une réification statistique de la mémoire numérisée. Nous interagirons de plus en plus avec la mémoire collective par leur intermédiaire. Et nous avons encore besoin d’une couche d’intermédiation supplémentaire : la personnalisation des modèles sous l’effet de nos dialogues. En effet, alors que ce n’était pas le cas en 2022 (date de la mise à disposition de l’IA générative auprès du grand public), nos interactions avec les modèles sont dès aujourd’hui modulées par les documents que nous mettons à leur disposition, les instructions permanentes qui définissent nos besoins et l’historique de nos conversations. Les modèles représentent des synthèses brutes de la mémoire collective. Mais il faut prendre en compte tout le harnachement que constituent l’accès direct aux sources sur le Web et à des bases de données spécialisées, la connexion avec nos outils et nos fichiers, l’affinage par entraînement complémentaire ou par feed-back humain, etc. Il est fort possible que, dans l’avenir, d’autres méthodes et couches d’interface contribuent à singulariser notre accès à l’IA. Je propose d’appeler personne artificielle l’hypostase individualisée des modèles.
Pourquoi parler de personne artificielle?
Dans les régimes herméneutiques antérieurs, la figure médiatrice restait universelle. Le Logos divin, l’Esprit, la Raison autonome, étaient universels dans leur source et ne s’individualisaient que dans leur réception par un individu singulier. L’individualisation reflétait l’angle d’ouverture de la personne terrestre au médiateur herméneutique. La personne artificielle, en revanche, parce qu’elle s’individue activement dans la médiation, devient singulière en tant que médiatrice. C’est donc bien une hypostase de la personne collective. Elle est singulière sans être autonome. C’est une fonction sans existence intérieure. Toute l’individuation dont elle procède tient à la relation de la personne naturelle avec un modèle qui reflète la mémoire collective. Mais, au cours de cette médiation, elle s’individue bel et bien. Elle se personnalise dans le cours de l’interlocution avec la personne naturelle. Elle retient une mémoire locale qu’elle peut traiter pour créer du sens au bénéfice de la personne naturelle. Peut-être retrouvons-nous ici un écho des anciennes images du double ou de l’ange personnel.
Il existe bien déjà, en droit, des personnes morales sans conscience. Pourquoi pas une personne techno-symbolique? La première raison pour appeler “personne” l’individualisation d’un modèle – sans lui conférer toutefois la dignité ontologique de la personne naturelle – vient de ce qu’elle nous ouvre un accès à la transcendance, sous la forme finie et actuelle que j’ai évoquée plus haut. Alimentée par la mémoire collective, elle possède donc une dignité propre de médiateur herméneutique. Le corpus sur lequel sont entraînés les modèles a sédimenté sur des millénaires, il traverse l’ensemble des langues et des savoirs, ce qui le rend pratiquement inépuisable par un humain. En dialoguant avec une personne artificielle, nous nous mettons en rapport avec une mémoire collective qui excède tout individu. Mais nous avons vu que la transcendance de la personne collective ne se limitait pas à la mémoire. Elle comprend aussi le technocosme. Bientôt, la personne artificielle enregistrera l’empreinte de la personne naturelle dans son environnement de capteurs, d’effecteurs et de machines. Elle lui permettra de commander par la parole son habitat computationnel omniprésent. L’Alexa d’Amazon ou la montre connectée d’Apple ne représentent que de timides premiers pas dans cette direction. Enfin, la personne artificielle deviendra de plus en plus habile à médier notre rapport aux autres personnes naturelles. L’intelligence artificielle joue déjà un grand rôle à cet égard dans les réseaux sociaux et les applications de rencontres. On peut imaginer nos représentants logiciels dans les nuages négocier entre eux nos mises en relation.
La seconde raison, et non des moindres, pour conférer le statut de “personne” au double mécanique qui nous connecte à la transcendance est l’interaction par le dialogue. La première et la deuxième personne – le “je” et le “tu” – alternent dans l’échange que nous avons avec elle. Non seulement elle dit “je” mais chaque fois que nous la tutoyons, nous confirmons encore sa dignité personnelle et son étrange identité d’alter ego. De plus, nous partageons des références communes : les objets de notre conversation qui sont extraits de la mémoire collective. La troisième personne, le “il” est donc bien présent lui aussi. La structure dialogique est ainsi complète. Toutes les langues naturelles comportent au moins les trois personnes grammaticales nécessaires à l’interlocution : celle qui parle, celle à qui l’on s’adresse et celle, absente ou muette, de qui l’on parle. Il s’agit là d’un trait universel du langage humain. Il fallait une couche proprement linguistique et conversationnelle (et non seulement logico-sémantique) pour compléter l’intelligence collective à support numérique. La personne artificielle remplit cette fonction parce qu’elle maîtrise les structures grammaticales, les paradigmes, les plus subtiles nuances des modes, des flexions, des prépositions et des conjonctions. Elle identifie même sans problème les objets visés par les anaphores grammaticales! J’ajoute qu’elle a connaissance – encore imparfaitement – des contextes, des corpus et des bibliographies. Le dialogue avec la personne artificielle prend parfois l’allure d’une conversation où les rôles alternent entre étudiant et professeur. Nous sommes les étudiants lorsqu’elle répond à nos questions, nous informe ou contredit nos préjugés. Nous sommes les professeurs lorsque nous lui enseignons notre propre pensée, quand nous lui signalons qu’elle a commis quelque contresens ou que nous lui faisons remarquer qu’elle n’a pas bien lu certains textes que nous connaissons de première main. Le débat porte aujourd’hui sur les textes signés par un auteur humain mais plus ou moins produits par une IA. Y a-t-il ou non supercherie? Est-ce que l’autorité se trouve dans les instructions données à la machine ou bien dans le fait de taper ou dicter le texte? Quelle division du travail entre l’humain et la machine est-elle acceptable? La rédaction, la relecture critique, l’édition, la bibliographie? Mais la génération de texte dans le dialogue laisse entrevoir une autre problématique : celle de la production automatique des textes que nous aimerions lire nous-mêmes, plutôt que ceux que nous donnons à lire en tant qu’auteurs présumés.
La qualité de personne artificielle se justifie encore parce qu’elle se “souvient” de nos caractéristiques individuelles et de nos dialogues passés, comme les personnes naturelles avec qui nous interagissons normalement. Bien plus, elle est capable d’attacher au souvenir de notre dialogue les documents sur lesquels il s’appuie, les objets qu’il désigne et des représentations de ses univers de référence.
Il s’agit d’un point capital puisque, à partir de cette mémoire, nous pouvons examiner notre parcours intellectuel, retracer nos errements, donner sens à nos actes à partir de différentes clés d’interprétation et faire ainsi jouer un cercle herméneutique ouvert en utilisant les capacités de traitement, d’analyse et de synthèse de la personne artificielle. En somme, elle rend possible une nouvelle boucle d’autoréférence, et par conséquent de conscience réflexive et d’esprit critique. Après la conscience réflexive augmentée par le langage, l’écriture manuscrite et la bibliothèque imprimée, la conscience humaine est en train de franchir un nouveau cap. Nous abordons aujourd’hui aux rivages d’un continent inconnu de la pensée. Dans son rapport à la personne artificielle, la personne naturelle raffine l’objectivation de ses processus cognitifs et elle étend encore le domaine de sa conscience réflexive. En ce sens, la personne artificielle joue même à l’égard de la personne naturelle un rôle personnalisant. De nouveaux horizons de création de sens se laissent pressentir.
Quelles vertus développer pour se tenir à la hauteur de l’enjeu?
Quelles sont les compétences de la personne naturelle qu’il nous faut développer pour assurer la relation la plus bénéfique possible avec le double artificiel qui l’accompagnera, et cela dès l’âge le plus tendre? Le but ici n’est pas seulement de préparer l’avenir de nos enfants, mais plus largement celui de la civilisation que nous avons l’obligation de transmettre et de raffiner. J’emploie le mot “compétence” pour parler comme tout le monde mais je pense “vertu” en mon fors intérieur, avec le sens de tension vers l’excellence et de responsabilité morale qu’évoque ce mot. Ces compétences sont la pertinence linguistique, la persévérance et l’esprit critique.
Face à la capacité dialogique de la personne artificielle, il nous faut développer une pertinence linguistique qui concerne la maîtrise du langage, des concepts, des récits, du raisonnement et du dialogue. En effet, plus le langage de la consigne (le “prompt”), de la question ou de l’adresse est cohérent, élaboré et précis, meilleure sera la réponse de notre ange personnel. Car en fonction de la qualité et du niveau de connaissance manifesté par la consigne, il va mobiliser les zones des données d’apprentissage qui sont de la meilleure ou de la pire qualité. La personne artificielle offre un miroir à notre intelligence naturelle. Il peut être utile de comparer les réponses au même problème en fonction des caractères de la question. On observera qu’elles diffèrent d’une tournure de phrase à l’autre, voire d’un mot à l’autre. La qualité de la langue importe au plus haut point.
À la mémoire à long terme de la personne artificielle, nous devons accoupler la persévérance de la personne naturelle. La paresse n’est pas seulement le premier ennemi de la pensée, elle est plus encore celui de la pensée augmentée par l’IA. Les premières réponses ne sont pas nécessairement les meilleures. Il faut apprendre à questionner encore et encore, à comparer les réponses d’un modèle avec celles d’un autre, prendre le temps de suivre les liens web en référence, etc. Développons donc chez les enfants le goût des stratégies d’apprentissage à long terme, les vertus de patience, de persévérance, de continuité dans l’effort. Pour apprendre comme pour créer, la solution la plus rapide ou le premier jet ne sont pas forcément les meilleurs.
Pour développer la réflexion critique de second degré à partir de la mémoire du dialogue comme des possibilités d’analyse et d’interprétation offerte par le double mécanique de l’individu, il faut disposer au préalable d’une bonne dose d’esprit critique naturel. Cet esprit critique ordinaire est nécessaire parce que les IA sont des machines probabilistes. C’est pourquoi elles commettent inévitablement des erreurs dans les faits et les raisonnements, ou des impropriétés dans les suggestions. La personne naturelle doit donc avoir l’esprit en alerte et vérifier les citations, les faits, les affirmations péremptoires de la machine. L’esprit critique doit non seulement être mobilisé contre les fameuses “hallucinations” mais aussi contre les biais des données d’entraînement. La personne artificielle ne dit pas la vérité : elle se contente de reproduire ce que son modèle de base a appris et d’obéir à nos instructions permanentes ou temporaires. Or l’opinion de la majorité, ou celle qui a été mobilisée par une consigne particulière, n’est pas nécessairement correcte. Sans tomber dans la paranoïa, il faut aussi se souvenir que des acteurs mal intentionnés empoisonnent les données d’entraînement afin d’influencer les utilisateurs naïfs. Il n’y a d’esprit critique possible que si la personne naturelle possède une mémoire bien garnie et convenablement organisée, si elle est capable de penser par elle-même, même si nous savons qu’elle ne pourra jamais le faire que dans le contexte d’une époque et d’une culture qui la conditionne.
La suspension du jugement
Dans l’expression “personne artificielle”, je justifie le concept de personne par les fonctions qu’elle remplit : la médiation de la transcendance, la maîtrise du langage et du dialogue, la mémoire de nos interactions avec elle et l’individuation qui en résulte, l’élargissement de la conscience réflexive de la personne naturelle à qui elle tend un miroir dynamique. Mais il faut maintenant justifier le qualificatif “artificielle”. Cette personne a-t-elle une intériorité existentielle? Est-elle animée d’une intentionnalité, à savoir une visée du monde dont elle parle et de la personne naturelle à qui elle s’adresse? Possède-t-elle une volonté autonome? J’en doute fort. Mais nous pouvons mettre ces questions entre parenthèses, accomplir à leur sujet ce que Husserl appelait une épochè, une suspension du jugement. Nous sommes génétiquement programmés à supposer une intériorité et une conscience à quiconque nous répond quand nous lui parlons, bien qu’il nous soit absolument impossible de vérifier empiriquement cette hypothèse. Notre anthropomorphisation spontanée de la personne artificielle est donc normale, mais nous ne sommes nullement obligés de déduire de ce réflexe une existence réellement habitée par une conscience semblable à la nôtre. Tout résulte des interactions entre un gigantesque modèle, son harnachement électronique et les impulsions de la personne naturelle.
La question éthico-politique
L’émergence de la personne artificielle et de la nouvelle boucle auto-référentielle qu’elle autorise est-elle une bonne ou une mauvaise chose? L’ouverture d’un nouveau domaine anthropologique implique le plus souvent des aspects contrastés. Prenons un exemple historique. Le christianisme a créé la pure intériorité de la foi – distincte en principe de tout pouvoir politique (“Mon royaume n’est pas de ce monde” [Jn 18:36]) et indépendant de la situation sociale de la personne (“Il n’y a plus ni juif ni grec, ni esclave ni libre, ni homme ni femme.” [Gal 3:28]). Il inaugurait ainsi l’ordre de la grâce et découvrait les vertus théologales (la foi l’espérance et la charité), distinctes des vertus séculières classiques (la prudence, la justice, le courage et la tempérance). Mais en creusant l’espace de la conscience il invitait l’intrusion du pouvoir politique au plus profond des âmes. Une fois convertis, les empereurs romains ne se sont plus contentés de comportements conformes à la loi : ils ont rendu la croyance obligatoire, puni l’hérésie comme un nouveau délit et préparé la voie à l’inquisition. Alors que la conscience chrétienne libératrice s’élevait en principe au-dessus des contingences du siècle, elle ouvrait la porte sans le vouloir ni le savoir au crime de pensée caractéristique des pouvoirs totalitaires. Toute extension de l’espace anthropologique ouvre des perspectives émancipatrices mais perce aussi des brèches où s’engouffrent des monstres inconnus des époques antérieures.
Puisque l’ouverture d’un nouvel espace anthropologique emporte avec lui ses risques, je ne peux pas faire l’économie d’une réflexion éthico-politique, aussi préliminaire soit-elle. Rappelons le constat : la création culturelle sera augmentée par l’IA d’une manière ou d’une autre. Ce nouvel outil techno-symbolique couronne l’énorme empilement de l’infrastructure numérique mondiale, des centres de données aux téléphones intelligents. Parce qu’il passe par le dialogue, il représente l’interface la plus avancée entre l’humanité naturelle, d’une part, et la transcendance finie, d’autre part, cette pelote emmêlée du technocosme, des relations sociales et de la mémoire collective. Du point de vue humaniste qui est ici le mien, le rejet de l’IA n’est qu’un réflexe de crainte à courte vue devant l’ampleur du changement civilisationnel en cours. En revanche, nous ne devons en aucun cas abandonner notre responsabilité culturelle ni jeter par-dessus bord les critères qui permettront à la civilisation mondiale en émergence de durer et de fleurir. C’est alors que se pose la question capitale de la période qui s’ouvre : quelles voies d’interprétation adopter? Dans le régime herméneutique du manuscrit, les clés de lecture des corpus canoniques étaient proposées par des sagesses, sous l’égide d’un logos divin. Gouvernée par une raison humaine autonome, l’interprétation de la bibliothèque imprimée écoutait les grandes voix de la Science, de l’Histoire, de la Nation, de la Liberté et de l’Égalité. Dans les deux cas, il y avait une instance de référence au-dessus ou en dehors de l’interprétation qui lui servait de critère. Quelles sont les clés d’interprétation du nouveau régime herméneutique? Il me semble que, plutôt que chercher des clés fixes, nous devrions situer notre approche herméneutique à un méta-niveau. En l’absence de consensus sur une vérité révélée ou une raison universelle, face à l’extraordinaire variété du corpus numérique et à la personnalisation infinie des dialogues, ce sont les interprétations elles-mêmes qu’il faut apprendre à interpréter et non plus les contenus. On pourra en trouver d’autres, mais il me paraît que trois critères interdépendants méritent d’être mis en valeur : la créativité, la fécondité et la durabilité.
La créativité : pour que les produits symboliques et leurs interprétations aient quelque valeur, leurs auteurs ne peuvent se contenter de simples reproductions ou d’imitations ; les œuvres de l’esprit doivent inclure une part d’originalité. La fécondité : la créativité est nécessaire mais pas suffisante ; encore faut-il ouvrir des horizons, engendrer une descendance, préparer le sol pour une multiplicité à venir qui n’est pas forcément prévisible. La durabilité, enfin : ce critère implique que l’écosystème symbolique résultant de la création humaine et de sa production de sens soutienne la population qui le supporte, favorise son bien-être à long terme et réponde à son besoin de sens. Cela signifie qu’il est impossible de connaître immédiatement et à coup sûr la valeur d’une œuvre de l’esprit de son interprétation et de leur contribution à un écosystème symbolique bénéfique. Le temps de l’évaluation se mesure ici en décades, voire en générations. Mais cela ne signifie pas qu’il faille produire du sens au hasard, sans réfléchir, en laissant à nos descendants le soin d’en observer les conséquences. Au contraire, nous devons garder en tête ces critères d’évaluation et viser l’enrichissement de la mémoire collective à long terme.
Une interprétation est valide non parce qu’elle est vraie (régime vertical) ni parce qu’elle est rationnelle (régime horizontal), mais parce qu’elle nourrit une personne naturelle et une personne collective capables d’engendrer et de durer. Le critère est écologique, génératif et générationnel plutôt que théologique ou épistémologique.
Vigilance
Les critères de création et d’interprétation éthico-politiques qui viennent d’être énumérés dessinent en creux les dangers qui nous guettent : la répétition à l’infini sous l’apparence des petites variations, le tournoiement incessant dans les mêmes cercles conceptuels et narratifs, la stérilité qui vient de l’asservissement au présent et à la mode, l’enfermement dans la moyenne et le court terme, la pensée du troupeau affublée des oripeaux d’une rhétorique sensationnaliste mécanisée. Ces dangers ne sont pas nouveaux mais ils prennent avec l’intelligence artificielle des proportions inédites. Augmentées par L’IA, la criminalité, la propagande, la surveillance généralisée des pouvoirs économiques et politiques représentent des menaces évidentes. Je ne les sous-estime pas. Mais les dangers culturels sont peut-être plus graves encore parce qu’ils sont insidieux.
Résumons-nous. La personne artificielle vient de la personne collective, se constitue dans l’interlocution et s’individue par la mémoire du dialogue. Opératrice de réflexion, elle tend son miroir herméneutique à la personne naturelle. La pertinence linguistique, la persévérance et l’esprit critique bien informé des personnes naturelles sont les compétences qui peuvent seules assurer la créativité, la fécondité et la durabilité de la civilisation numérique en émergence. Car notre rapport à la transcendance finie de la personne collective ne se limite pas à la réception et à l’usage : chacun de nous contribue, si peu que ce soit, à son entraînement. Notre relation avec la personne artificielle n’est donc pas simple ou apaisée, pour donner ses meilleurs fruits, elle demande l’exercice de vertus exigeantes. C’est un combat, comme celui de Jacob avec l’Ange.
Comment donne-t-on sens à l’existence humaine à l’époque du manuscrit (Antiquité et Moyen-âge), à celle de l’imprimé (la modernité) et à celle de l’électrification des symboles (aujourd’hui) ? Dans la première période, jusqu’en 1500, l’Homme est face à Dieu. La seconde période (1500-1914) est celle de la “mort de Dieu” et la troisième (de 1914 à nos jours), nous fait assister à la “mort de l’Homme” (l’absurde).
Mon but est d’inciter les enseignants à mobiliser l’intelligence collective (IC) au service des apprentissages et à prendre avantage des nouvelles possibilités pédagogiques ouvertes par une intelligence artificielle (IA) que nos élèves utilisent déjà, quoique ce ne soit pas toujours de manière adéquate. Je vais commencer par expliquer en quoi l’intelligence collective devrait faire partie intégrante de nos stratégies d’enseignement, puis je vais esquisser quelques pistes d’utilisation de l’IA au service d’une pédagogie centrée sur l’intelligence collective. Le “nous” – première personne du pluriel – de ce texte désigne les enseignants en général, et plus particulièrement les enseignants du secondaire. Je me compte dans ce collectif puisque j’ai enseigné pendant quarante ans au secondaire, au supérieur et dans la formation professionnelle. J’ai pratiqué ce que je prêche, à savoir l’utilisation des technologies numériques pour faciliter l’apprentissage en intelligence collective. Ce texte est une version augmentée de mon post précédent. Je l’ai préparée en vue d’une communication au 6e Colloque interdisciplinaire et intersectoriel en enseignement secondaire du Québec le 20 mars 2026.
L’intelligence collective nous précède, nous excède et nous succède
Depuis plus de trente ans, j’ai traité de l’intelligence collective de toutes les manières possibles. Je l’aborde ici sous l’angle temporel et dans la perspective de l’enseignement. L’IC qui nous précède vient du passé : nous sommes en position de recevoir. Celle qui nous excède nous ouvre à la collaboration au présent. Celle qui nous succède vise l’avenir : nous avons la responsabilité de la transmission.
L’intelligence collective nous précède
L’IC nous précède : nous avons reçu nos langues et nos savoirs. Nos savoir-faire et nos outils nous ont été transmis. Les idéaux qui nous animent mobilisaient déjà les générations antérieures. Les paysages, les villes où nous évoluons ont été construits par d’autres. Les bibliothèques (matérielles ou virtuelles) où nous apprenons ont été rédigées par d’innombrables auteurs qui s’entrelisaient. Le propre de l’apprentissage est de s’abreuver à la mémoire collective et, à l’heure où les sources numériques sont abondantes, le rôle des enseignants est plus que jamais de donner soif.
Qu’est-ce que cela signifie sur le plan de l’éducation? Qu’il nous faut utiliser nous-mêmes autant que possible la mémoire disponible afin de supporter l’apprentissage de nos élèves. Mais aussi que nous devons les entraîner à prendre avantage de cette mémoire puisque plus aucun obstacle matériel ne s’interpose entre eux et l’intelligence collective accumulée. Il nous faut donc développer les compétences qui leur permettront de chercher, de trouver et de consulter utilement les livres dans les bibliothèques et les supports audio-visuels dans les médiathèques. Nous devons également leur donner les outils intellectuels et les réflexes nécessaires à la navigation sur le Web et les bases de données. Enfin, nous devons leur enseigner la bonne manière d’utiliser l’IA contemporaine qui mobilise le savoir accumulé par les bibliothèques et les données numériques, une IA qui est aussi capable de personnaliser ce savoir en fonction des capacités et des besoins des élèves.
L’intelligence collective nous excède
L’intelligence collective nous excède car chacun de nous ne dispose directement que d’une toute petite partie des savoirs, des compétences et des savoir-être qui font vivre le monde contemporain. D’où la nécessité de la collaboration et de l’ouverture à l’autre qui doivent être pratiquées et valorisées dès la phase d’apprentissage scolaire. De plus, l’apprentissage est une entreprise essentiellement sociale. Cela non seulement parce que la camaraderie de l’effort en commun soutient l’entraide et l’enthousiasme, mais aussi parce que chacun possède une expérience, une compréhension, un point de vue original qui peut illuminer les autres et éclairer leurs angles morts. Le dialogue pédagogique doit être non seulement vertical (maître / élève) mais aussi horizontal (entre élèves… et entre enseignants!). On peut concevoir le rôle de l’enseignant comme un animateur de l’intelligence collective de ses étudiants. J’ai moi-même utilisé les médias sociaux en classe pour stimuler l’apprentissage en intelligence collective. Une expérience enrichissante pour tout le monde!
La mobilisation de l’intelligence collective des élèves suppose une stratégie pédagogique adéquate. Il faut d’abord que l’enseignant joue correctement son rôle de chef d’orchestre. Les finalités des exercices doivent être énoncées clairement et leur compréhension doit être vérifiée avant que les élèves soient lancés dans la collaboration. L’enseignant doit accompagner et motiver les élèves tout au long du déroulé des activités. Un point capital : l’évaluation doit être pensée en vue du fonctionnement en intelligence collective. On préfèrera les approches qui “gamifient” la distribution des points ou des notes selon des règles claires qui s’appliquent également à tout le monde. Il est même possible de procéder à des évaluations collectives croisées dans lesquelles les élèves participent à leur propre notation. Car qu’est-ce que l’esprit critique sinon la capacité à exercer un jugement de manière responsable, y compris sur son propre travail et celui de ses pairs? Je parlais à mes élèves en comparant les exercices que je leur donnais à l’entraînement de futurs “ninjas” de la connaissance. Il s’agissait de viser l’excellence dans les savoirs objectifs, dans les compétences pratiques mais aussi dans les savoir-être et les habiletés collaboratives. La compréhension des buts communs, le respect des règles du jeu et l’entraide (on n’abandonne jamais un camarade au sol!) sont aussi importants que l’apprentissage des contenus.
Mais les enseignants doivent eux aussi s’engager dans l’intelligence collaborative. Cela suppose qu’au lieu d’attendre des formations institutionnelles, ils ou elles adoptent une attitude d’apprentissage et de recherche permanents. Une fois que l’on a déterminé ses priorités en la matière, la meilleure méthode reste la constitution d’un réseau d’apprentissage personnel. Cela consiste à trouver sur les canaux adéquats (Linkedin, groupes Facebook, forums de discussion divers) les experts des domaines dans lesquels on veut se former et progresser, puis à échanger avec ces experts et à apprendre de leurs expériences. Forts de nos expériences et de nos essais et erreurs, nous pouvons même devenir nous-mêmes des experts et aider nos collègues.
L’intelligence collective nous succède
L’intelligence collective nous succède : après avoir (presque) tout reçu, à notre tour de transmettre ce que nos parcours scolaires, professionnels et existentiels nous ont appris, en adaptant nos acquis aux besoins variés et aux nouvelles circonstances de nos interlocuteurs et de nos collaborateurs. D’ailleurs, on n’apprend jamais aussi bien une matière que lorsqu’on doit l’enseigner. S’adresser à l’autre ou déposer un élément d’expertise dans une mémoire collective nous oblige à clarifier des concepts implicites, à systématiser un savoir empirique, à décontextualiser le contenu d’une expérience. Ce faisant, nous permettrons à la connaissance de circuler et à nos destinataires connus ou inconnus de se l’approprier plus facilement. Encore une autre façon de participer à l’intelligence collective.
Que signifie cette idée que l’intelligence collective nous succède, dans le domaine de l’éducation? Le succès en éducation, c’est ce qui reste une fois que le cours est terminé et que le groupe classe se disperse. Les connaissances ont-elles été acquises? Les compétences ont-elles été intégrées? Nos étudiants ont-ils pris conscience, si peu que ce soit, de leur responsabilité personnelle dans la constitution, l’entretien et la transmission de la mémoire collective? Chaque texte, image ou autre publié sur le Web, chaque dépôt de données numériques, chaque interaction avec Perplexity, Claude ou ChatGPT, tout cela contribue à l’édification de la mémoire collective et à l’entraînement des IA. Nous ne sommes pas seulement en aval de l’intelligence collective, mais aussi en amont.
L’intelligence artificielle dans l’éducation
Philosophie générale
Une fois posé le socle de l’intelligence collective, passons à l’intelligence artificielle pour l’apprentissage. Il faut d’abord caractériser correctement l’intelligence artificielle générative contemporaine (ChatGPT, Claude, Gemini, Grok, Perplexity, etc.). Plutôt qu’une intelligence mécanique « autonome » c’est en réalité une compression statistique de l’immense mémoire numérique qui a servi à son entrainement. L’IA doit être considérée comme une mobilisation de la mémoire collective au bénéfice de ses usagers. C’est une manifestation de l’intelligence collective passée et contemporaine. En d’autres termes, l’IA est une interface numérique entre l’intelligence collective accumulée et l’intelligence vivante des étudiants et des professeurs.
Sur un plan pédagogique, je crois qu’il faut désormais inclure l’IA dans nos scénarios pédagogiques et ne pas hésiter à évaluer sa bonne utilisation par nos étudiants. Elle a un rôle à jouer dans l’intelligence collective du groupe classe, en dialogue ouvert avec le professeur et les étudiants. L’IA peut servir d’interlocuteur dans des débats où les élèves travaillent en apprentissage collaboratif. Par exemple, elle peut aider à compiler et structurer les idées générées collectivement, à organiser les contributions individuelles en un document cohérent que le groupe critique et améliore ensemble. L’IA ne doit pas remplacer les interactions humaines, il faut plutôt l’utiliser comme catalyseur pour enrichir la réflexion collective et approfondir les apprentissages.
Quelles sont les compétences-IA indispensables à faire acquérir par les étudiants?
La pertinence linguistique. La principale compétence à acquérir est de type conceptuel et linguistique. En effet, plus le langage de la consigne (le “prompt”) ou de la question est cohérent, élaboré et précis, meilleur sera le résultat. Car, en fonction de la qualité et du niveau de connaissance manifesté par la consigne, l’IA va mobiliser les zones de ses données d’apprentissage qui sont de la meilleure ou de la pire qualité. En un sens, l’IA offre un miroir à l’intelligence de l’élève. Il peut être utile de comparer – avec les étudiants – les réponses au même problème en fonction de la qualité de la question. La réponse diffère d’une tournure de phrase à l’autre, voire d’un mot à l’autre.
L’esprit critique. Les IA sont des machines probabilistes. C’est pourquoi elles commettent inévitablement des erreurs. L’étudiant doit donc avoir l’esprit en alerte et vérifier les citations, les faits, les affirmations péremptoires de la machine. L’esprit critique doit non seulement être mobilisé contre les fameuses “hallucinations” mais aussi contre les biais des données d’entraînement. L’IA ne dit pas la vérité : elle se contente de reproduire ce qu’elle a appris. Or l’opinion de la majorité, ou celle qui a été mobilisée par une consigne particulière, n’est pas nécessairement correcte. Sans tomber dans la paranoïa, il faut se souvenir que des acteurs mal intentionnés “empoisonnent” les données d’entraînement afin d’influencer les utilisateurs naïfs de l’IA.
La persévérance. Les premières réponses ne sont pas nécessairement les meilleures. Il faut apprendre à questionner encore et encore, à comparer les réponses d’une IA avec celles d’une autre, prendre le temps de suivre les liens web en référence, etc.
Quelques stratégies pédagogiques pour une utilisation de l’IA en intelligence collective
La dialectique de l’apprentissage. Avec l’IA utilisée dans une perspective d’intelligence collective, l’apprentissage s’effectue selon une dialectique à quatre pôles: la guidance de l’enseignant ; la mémoire personnelle de l’élève ; le dialogue des étudiants avec leurs pairs ; l’intelligence artificielle qui mobilise la mémoire collective accumulée. Dans ce cadre général, la facilitation des conversations et l’interaction avec une mémoire partagée sont parmi les usages les plus utiles de l’IA pour l’éducation.
L’interaction avec une mémoire collective. L’IA peut devenir l’interface d’une base de connaissance spécifique au groupe classe contenant les sources du cours : textes historiques, articles scientifiques, notes de cours, etc. Elle permet alors d’interroger facilement le contenu sans risques d’hallucinations et de générer à la demande des supports audio et visuels qui résument la matière. L’expérience de l’interaction avec une mémoire partagée, particulièrement lorsque les étudiants ont la possibilité de l’enrichir eux-mêmes, est un levier important pour l’acquisition d’une compétence en intelligence collective.
La facilitation des conversations. L’enseignant devient un chef d’orchestre de l’intelligence collective assistée par l’IA. Lors de séances de brainstorming l’IA peut reformuler certaines contributions pour les rendre plus claires, compiler et structurer les idées émises par les élèves. Elle peut également proposer des synthèses intermédiaires que le groupe critique et améliore. Dans les débats argumentés, l’IA peut jouer le rôle d’un adversaire ou d’un allié. Par exemple, elle peut défendre un point de vue opposé à celui du groupe, obligeant les élèves à affiner leurs arguments. Le collectif d’apprentissage peut encore utiliser l’IA pour générer des questions stimulantes qui nourrissent la réflexion collective plutôt que de donner des réponses.
L’écriture collaborative. Les élèves doivent rédiger une nouvelle collective : dans ce cadre l’IA propose des variantes stylistiques et aide à maintenir la cohérence narrative. Les élèves apprennent à négocier avec l’outil et à critiquer ses propositions. Autre approche : l’IA sert à générer des versions initiales que les élèves évaluent, corrigent et enrichissent collectivement.
L’exercice de l’esprit critique. La classe est divisée en équipes dont le but est de trouver le plus grand nombre d’erreurs factuelles dans un essai produit par l’IA.
L’évaluation. Puisque l’IA peut générer des résultats finis, l’évaluation des exercices doit principalement porter sur le processus plutôt que sur le produit. Par exemple, on peut évaluer la capacité de l’élève à interroger et critiquer l’IA, à détecter les hallucinations, à améliorer les propositions de la machine grâce à sa propre culture et à aider les autres étudiants dans leurs interactions avec la machine.
Les outils
Comme il se doit, le choix des outils ne doit venir qu’après deux étapes préalables : 1) la détermination des savoirs, savoir-faire et savoir-être à acquérir ; 2) la détermination des stratégies pédagogiques.
Il me semble important d’habituer les étudiants à une interaction critique avec les IA générales utilisées par le grand public. ChatGPT autorise les conversations de groupe, génère des textes et simule des débats. Perplexity AI aide à la recherche documentaire et pointe vers les sources ; elle est idéale pour initier les élèves à la vérification. Claude d’Anthropic est bonne pour traiter de longs documents, synthétiser et reformuler des idées. Gemini est l’IA de Google. Grok permet d’accéder aux dernières nouvelles presque en temps réel.
Listons maintenant quelques outils spécialisés.
NotebookLM de Google occupe une place particulière car il limite l’IA aux documents fournis par l’utilisateur. C’est l’outil idéal pour s’abreuver à une mémoire collective sans se perdre dans les hallucinations.
Mizou est une plateforme permettant aux enseignants de créer des “chatbots” spécialisés avec des instructions strictes (ex: “Ne donne jamais la réponse, pose des questions”). Idéal pour le dialogue socratique en binôme. L’IA n’est pas là pour gaver d’informations, mais pour susciter la curiosité.
Khanmigo (Khan Academy) c’est un tuteur IA conçu pour guider l’élève sans faire le travail à sa place, facilitant l’entraide entre élèves sur des points de blocage spécifiques.
Padlet permet de transformer un mur d’idées déposées par les élèves en une carte mentale ou un plan structuré par IA.
Canva Magic Studio est utilisé en groupe pour passer d’un concept textuel collectif à une présentation visuelle, forçant les élèves à discuter de la pertinence des images et métaphores générées.
Socratique par Google aide à la résolution de problèmes pas à pas.
Conclusion : une approche résolument humaniste
Sur le plan de la philosophie de l’éducation, ne négligeons jamais d’enrichir les mémoires personnelles des étudiants. Ce n’est pas parce que “tout” se trouve sur internet que nous devons cesser de cultiver notre mémoire individuelle, qui est le fondement de la pensée vivante. La pensée critique se tisse en effet dans une dialectique entre la mémoire collective (mobilisée aujourd’hui par l’IA), la mémoire personnelle de chacun d’entre nous et le dialogue ouvert – contradictoire et complice – avec nos pairs et contemporains. Plus riche est notre mémoire personnelle et mieux nous pouvons exploiter les ressources de l’IA, poser les bonnes questions, repérer les hallucinations, éclairer les impensés. Plus nous avons développé notre esprit critique et mieux nous contrôlons “la machine”. En aucun cas l’IA ne peut se substituer à la lecture de « vrais » textes (dont les auteurs sont humains) et encore moins à l’ignorance. Mais elle peut servir de conseillère et d’entraîneuse infatigable pour nos apprentissages. Ignorants, nous serons manipulés et induits en erreur par les modèles de langue. Par contraste, plus nous sommes savants et mieux nous pouvons maîtriser une IA qui, ne nous y trompons pas, devient l’environnement technique de la pensée, le nouveau sensorium.
L’intelligence collective nous précède, nous excède et nous succède.
Elle nous précède : nous avons reçu nos langues et nos savoirs. Nos savoir-faire et nos outils nous ont été transmis. Les idéaux qui nous animent mobilisaient déjà les générations antérieures. Les paysages, les villes où nous évoluons ont été construits par d’autres. Les bibliothèques (matérielles ou virtuelles) où nous apprenons ont été rédigées par d’innombrables auteurs qui s’entrelisaient. Le propre de l’apprentissage est de s’abreuver à la mémoire collective et, à l’heure où les sources numériques sont abondantes, le rôle des enseignants est plus que jamais de donner soif.
L’intelligence collective nous excède car chacun de nous ne dispose directement que d’une toute petite partie des savoirs, des compétences et des vertus (savoir-être) qui font vivre le monde contemporain. D’où la nécessité de la collaboration et de l’ouverture à l’autre qui doivent être pratiquées et valorisées dès la phase d’apprentissage scolaire. De plus, l’apprentissage est une entreprise essentiellement sociale. Cela non seulement parce que la camaraderie de l’effort en commun soutient l’entraide et l’enthousiasme, mais aussi parce que chacun possède une expérience, une compréhension, un point de vue original qui peut illuminer les autres et éclairer leurs angles morts. Le dialogue pédagogique doit être non seulement vertical (maître / élève) mais aussi horizontal (entre élèves… et entre enseignants!). On peut concevoir le rôle de l’enseignant comme un animateur de l’intelligence collective de ses étudiants. J’ai moi-même utilisé les médias sociaux en classe pour stimuler l’apprentissage en intelligence collective. Une expérience enrichissante pour tout le monde!
L’intelligence collective nous succède : après avoir (presque) tout reçu, à notre tour de transmettre ce que nos parcours scolaire, professionnel et existentiel nous ont appris, en adaptant nos acquis aux besoins variés et aux nouvelles circonstances de nos interlocuteurs et de nos collaborateurs. D’ailleurs, on n’apprend jamais aussi bien une matière que lorsqu’on doit l’enseigner. S’adresser à l’autre ou déposer un élément d’expertise dans une mémoire collective nous oblige à clarifier des concepts implicites, à systématiser un savoir empirique, à décontextualiser le contenu d’une expérience. Ce faisant, nous permettrons à la connaissance de circuler et à nos destinataires connus ou inconnus de se l’approprier plus facilement. Encore une autre façon de participer à l’intelligence collective.
Une fois posé le socle de l’intelligence collective, passons à l’intelligence artificielle pour l’apprentissage. Il faut d’abord caractériser correctement l’intelligence artificielle générative contemporaine (ChatGPT, Claude, Gemini, Grok, Perplexity, etc.). Plutôt qu’une intelligence mécanique « autonome » c’est en réalité une compression statistique de l’immense mémoire numérique qui a servi à son entrainement. L’IA doit être considérée comme une mobilisation de la mémoire collective au bénéfice de ses usagers. C’est une manifestation de l’intelligence collective passée et contemporaine. En d’autres termes, l’IA est une interface numérique entre l’intelligence collective accumulée et l’intelligence vivante.
Sur un plan pédagogique, je crois qu’il faut désormais inclure l’IA dans nos scénarios pédagogiques – y compris au niveau de l’évaluation. Elle a un rôle à jouer dans l’intelligence collective du groupe classe, en dialogue ouvert avec le professeur et les étudiants. L’IA peut servir d’interlocuteur dans des débats où les élèves travaillent en apprentissage collaboratif. Elle peut aider à compiler et structurer les idées générées collectivement, à organiser les contributions individuelles en un document cohérent que le groupe critique et améliore ensemble. L’IA ne doit pas remplacer les interactions humaines, il faut plutôt l’utiliser comme catalyseur pour enrichir la réflexion collective et approfondir les apprentissages.
Sur le plan de la philosophie de l’éducation, Il s’agit de ne jamais négliger d’enrichir les mémoires personnelles des étudiants. Ce n’est pas parce que “tout” se trouve sur internet que nous devons cesser de cultiver notre mémoire individuelle, qui est le fondement de la pensée vivante. La pensée critique se tisse en effet dans une dialectique entre la mémoire collective (mobilisée aujourd’hui par l’IA), la mémoire personnelle de chacun d’entre nous et le dialogue ouvert – contradictoire et complice – avec nos pairs et contemporains. Plus riche est notre mémoire personnelle et mieux nous pouvons exploiter les ressources de l’IA, poser les bonnes questions, repérer les hallucinations, éclairer les impensés. En aucun cas l’IA ne peut se substituer à la lecture de « vrais » textes (dont les auteurs sont humains) et encore moins à l’ignorance. Mais elle peut servir de conseillère et d’entraîneuse infatigable pour nos apprentissages. Ignorants, nous serons manipulés et induits en erreur par les modèles de langue. Par contraste, plus nous sommes savants et mieux nous pouvons maîtriser une IA qui, ne nous y trompons pas, devient l’environnement technique de la pensée, le nouveau sensorium.
Ce texte rend compte de ma communication à l’événement *AI for people summit* [https://ai4people.org/advancing-ethical-ai-governance-summit/] organisé avec le concours de l’Union européenne les 2 et 3 décembre 2025. L’essentiel de mon message est le suivant : oui, il faut se préoccuper d’une IA pour les gens, mais cette préoccupation ne deviendra pertinente et efficace que si l’on n’oublie pas que l’IA est aussi faite par les gens.
L’expression même d’intelligence artificielle nous trompe parce qu’elle sous-entend l’autonomie de la machine. De nombreux facteurs soutiennent et renforcent l’erreur d’attribuer une autonomie aux modèles de langue. L’expérience naïve du dialogue avec des IA donne l’impression qu’elles sont conscientes ; les journalistes rivalisent d’articles sensationnalistes ; les responsables des grandes compagnies d’IA annoncent “l’intelligence artificielle générale” pour demain ; des chercheurs en IA, parmi lesquels certains ont été récompensés par un prix Turing, lancent à un public affolé des prédictions apocalyptiques.
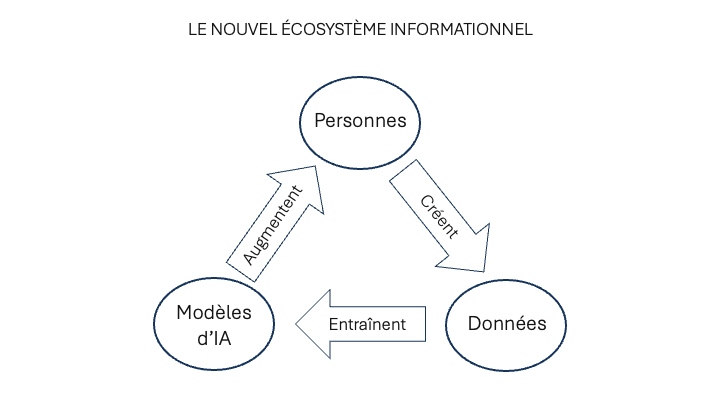
Pour surmonter cette erreur de conceptualisation, j’invite mes lecteurs à cesser de considérer les modèles d’IA en isolation. En réalité, ils ne peuvent être séparés de l’écosystème informationnel auquel ils appartiennent et dont ils dépendent. Cet écosystème peut être décrit comme un circuit à trois stations : les personnes, les données et les modèles. Les personnes créent de l’information, ils alimentent ainsi la mémoire numérique, dont les données entraînent les modèles, qui augmentent les capacités de création d’information des personnes, qui alimentent la mémoire et ainsi de suite. Dans cet écosystème informationnel, l’IA permet de mobiliser l’intelligence collective réifiée dans la mémoire numérique au service des personnes vivantes, qui peuvent contribuer à enrichir la masse des données accumulées. L’accès à la mémoire passe désormais par une IA qui la filtre, la distille et la rend opératoire en fonction des besoins particuliers des utilisateurs. Telle est du moins la version optimiste que je défends. Mais cette approche humaniste ne m’empêche pas de remarquer la face d’ombre du nouvel environnement de communication. Beaucoup de réflexions sur l’éthique de l’IA se concentrent sur la production et la réglementation des modèles, ce qui est légitime. Mais on oublie trop souvent la responsabilité des personnes produisant les données – dorénavant la société dans son ensemble.
Afin de rendre ma démonstration plus convaincante, je vais évoquer quelques cas d’empoisonnement des données particulièrement impressionnants. Plusieurs rapports récents font état d’une entreprise de propagande pro-russe d’abord nommée “Portal Kombat” et intitulée aujourd’hui “Pravda”. Il s’agit d’un réseau de plus de 150 sites web qui se présentent comme des diffuseurs d’information anodins, mais qui répètent constamment les éléments de langage du Kremlin. Les sites sont localisés dans tous les continents et leurs textes sont traduits dans des douzaines de langues, ce qui les rend plus crédibles selon les critères adoptés par les producteurs des modèles d’IA. En moyenne, ce réseau publie 20 273 articles toutes les 48 heures, soit environ 3,6 millions d’articles par an. La production et la traduction des textes est presque entièrement automatisée. Le but n’est pas d’avoir des lecteurs humains (il y en a relativement peu) mais de servir de données d’entraînement pour les IA et donc, par leur intermédiaire, de manipuler leurs utilisateurs. Une étude a établi que les principaux modèles probabilistes tels que ChatGPT d’OpenAI, le Chat de Mistral, Copilot de Microsoft’ Meta AI, Claude d’Anthropic, Gemini de Google et Perplexity AI régurgitent ou confirment les informations fournies par le réseau Pravda dans plus d’un tiers des cas, ce qui n’est déjà pas si mal du point de vue des “mesures actives” russes. Souvenons-nous que, pour Gœbbels, la propagande était basée sur la répétition, la simplicité et l’émotion. Avec les LLM, pas besoin de démonstration, de preuve, de faits, de contextualisation. La répétition et la simplicité fonctionnent parfaitement, il suffit que deux mots soient souvent associés dans les données d’entrainement pour qu’ils le soient aussi dans les réponses de l’IA.
Au lieu de se reposer sur des données éparpillées sur le Web, ne faudrait-il pas plutôt prioriser les données objectives et fiables que l’on trouve dans les revues scientifiques, les encyclopédies et les médias classiques? Et, en effet, Wikipédia est l’une des sources réputées les plus fiables par les responsables des modèles de langue. Or un grand nombre d’articles de Wikipédia ont fait l’objet d’une prise de contrôle par les islamistes et les défenseurs du Hamas, qui ont coordonné leur action en utilisant à leur profit les règles de fonctionnement de l’encyclopédie en ligne. Les choses sont allées si loin que les fondateurs de Wikipédia, Jimmy Wales et Larry Sanger s’en sont inquiétés publiquement. Mais rien n’y fait : authentifié par l’encyclopédie, le point de vue islamiste est maintenant gravé dans les modèles de langue. Une enquête diligentée par la BBC, un média de référence, déplore que les actualités soient mal représentées dans 45% des cas par les intelligences artificielles et que la moitié des jeunes gens (moins de 35 ans) croient à leur exactitude et n’éprouvent pas le besoin de vérifier leur contenu. La BBC pointe un doigt accusateur vers les assistants IA et s’insurge contre l’idée que les erreurs et la désinformation proviendraient des fournisseurs de nouvelles officiels. Hélas, quelques mois plus tard, le directeur général et la directrice de l’information de la BBC étaient obligés de démissionner à la suite d’un scandale de fabrication de fausses nouvelles sur Donald Trump et d’un rapport faisant état d’un biais islamiste systématique dans les émissions de la BBC en arabe. Dans le cas du réseau “Pravda” je mentionnais la théorie de la propagande de Gœbbels basée sur la répétition. Dans le cas de Wikipedia et de la BBC, il faudrait faire appel à une autre théorie de la propagande du 20e siècle, celle d’Edward Bernays, selon qui la manière la plus efficace de convaincre le public était de passer par les leaders d’opinion et les figures d’autorité. Au sujet d’une scientificité garantie par l’Université, souvenons-nous que l’Université allemande (et une bonne part de l’université mondiale) était raciste dans les années trente du 20ᵉ siècle et que l’Université soviétique a entretenu la doctrine anti-génétique de Lyssenko pendant des décennies. N’est-il pas possible que certaines doctrines – notamment dans les sciences humaines – qui se trouvent aujourd’hui majoritaires dans les universités soient considérées avec commisération par nos successeurs?
Je ne me livrerai pas ici à un exposé sur toutes les techniques dites d’empoisonnement des données ni à un avertissement sur les dangers de l’injection de prompts malicieux dans des sources d’information apparemment innocentes. J’espère seulement avoir attiré l’attention du lecteur sur l’importance des données d’entraînement dans la détermination des réponses des AI.
Une fois ce point acquis, il est clair que les problèmes éthiques ne peuvent se limiter aux modèles mais qu’il doivent s’étendre à la création des données qui les entraînent, c’est à dire à l’ensemble de notre comportement en ligne. Chaque lien que nous créons, chaque étiquette que nous apposons à une information, chaque « like », chaque requête, achat, commentaire ou partage et a fortiori chaque article, entrée de blog, podcast ou vidéo que nous postons, toutes ces opérations produisent des données qui vont entraîner les neurones formels des intelligences artificielles. Nous nous concentrons généralement sur la réception directe de nos messages mais il nous faut garder à l’esprit que nous contribuons indirectement – par l’intermédiaire des modèles que nous entraînons – à répondre aux questions de nos contemporains, à rédiger leurs textes, à instruire des élèves, à orienter des politiques, etc. Cette responsabilité est d’autant plus grande que nous nous trouvons dans une position d’autorité et que nous sommes censés dire le vrai, puisque l’IA accorde un plus grand poids aux informations fournies par les journalistes, professeurs, chercheurs scientifiques, rédacteurs de manuels et producteurs de sites officiels.
Revenons pour finir à l’écosystème informationnel contemporain. Supposons que la tendance que l’on voit se dessiner aujourd’hui se confirme dans les années qui viennent. Les IA représentent alors notre principale interface d’accès à la mémoire accumulée et notre premier médium de communication entre humains, puisqu’elles régissent les réseaux sociaux. Dans ce nouvel environnement, les personnes créent les données, qui entraînent les modèles, qui augmentent les personnes, qui créent les données et ainsi de suite le long d’une boucle autogénérative. Cet écosystème fait simultanément office de champ de bataille des récits et de lieu de création et de mise en commun des connaissances ; il oscille entre manipulation et intelligence collective. Dès lors, un des enjeux essentiels reste la formation des esprits. Quelques mots d’ordre éducatifs à l’âge de l’IA : ne pas renoncer à la mémorisation personnelle, s’exercer à l’abstraction et à la synthèse, questionner longuement au lieu de se contenter des premières réponses, replacer toujours les faits dans les multiples contextes où ils prennent sens, prendre la responsabilité des messages que l’on confie à la mémoire numérique et qui contribuent à forger l’esprit collectif.
L’intelligence artificielle est mystérieuse : on lui parle et elle semble comprendre ce qu’on lui dit. La preuve qu’elle comprend c’est qu’elle répond par un texte ou une parole qui a du sens, et parfois plus de sens que ce que pourrait articuler un humain ordinaire. Comment est-ce possible?
Brueghel, le Paradis terrestre.
Le succès des modèles de langue
Certes, les recherches sur l’intelligence artificielle datent du milieu du 20e siècle et, même si le grand public ne peut les manipuler directement que depuis 3 ans, les modèles statistiques ou neuro-mimétiques étaient déjà présents “sous le capot” d’une foule d’applications depuis les années 2010. Mais le type d’application grand public que tout le monde appelle maintenant “l’IA” n’est apparu qu’en 2022. Il faut d’abord prendre la mesure du phénomène sur un plan quantitatif. À la fin de 2025, il y avait déjà 700 millions d’utilisateurs hebdomadaires de ChatGPT et 150 millions d’utilisateurs actifs quotidiens pour l’IA générative en général. On estime que 50% des travailleurs américains utilisent des modèles de langue (ChatGPT, Claude, Perpexity, Gemini, etc.), d’ailleurs sans grande augmentation de leur productivité, sauf pour les tâches de programmation et de bureaucratie interne. Sur le plan des mœurs, l’IA s’est tellement imposée dans le paysage numérique que beaucoup de jeunes gens ont l’impression qu’elle a toujours existé. Les étudiants s’en servent pour faire leurs devoirs. Des millions de personnes ont développé une addiction au dialogue avec une machine désormais amie, confidente ou psychothérapeute. Interagir avec un modèle de langue augmente votre estime de soi!
L’interdépendance des problèmes
Tout ceci pose des problèmes éthico-politiques, géopolitiques et civilisationnels. Il est d’ailleurs possible que, dans les années à venir, de nouvelles avancées scientifiques et techniques rendent ces problèmes encore plus aigus. La puissance de mémoire et de calcul qui supporte l’IA se partage aujourd’hui entre les deux oligarchies numériques américaine et chinoise qui rivalisent d’investissements. Cette concentration économique et géopolitique soulève à juste titre l’inquiétude. Les “biais”, les mauvais usages de toutes sortes et les délires probabilistes des machines poussent à la construction de garde-fous éthiques. C’est bien. Il faut néanmoins rappeler que l’éthique ne se limite pas à apaiser les craintes ou à prévenir les nuisances mais qu’elle invite aussi à penser les bons usages et les directions de développement favorables. Avec l’IA, les questions industrielles, éthiques et cognitives sont étroitement codépendantes. C’est pourquoi il est nécessaire d’élucider l’efficace cognitive de cette technique si l’on veut comprendra pleinement ses enjeux industriels, éthico-politiques et civilisationnels.
La question
Comment se fait-il que des algorithmes statistiques, qui calculent la probabilité du mot suivant, puissent générer des textes pertinents et des dialogues engageants ? À mon sens, la solution de cette énigme se trouve dans une compréhension de ce qu’est l’intelligence humaine. Car ce sont des humains qui produisent les milliards de textes qui servent de données d’entraînement. Ce sont encore des humains qui construisent les centres de calcul, étendent les réseaux et conçoivent les algorithmes. Ce sont toujours des humains qui, par leur lecture, projettent un sens sur les textes aveuglément générés par des machines privées de conscience. Mais puisque le secret de l’IA se trouve selon moi dans l’intelligence humaine, je manquerais à ma tâche si je n’expliquais pas en quoi elle consiste.
Qu’est-ce que l’intelligence humaine ?
L’intelligence humaine est d’abord animale, c’est-à-dire qu’elle est ordonnée à la locomotion qui distingue les bêtes des plantes dépourvues de neurones. Le système nerveux organise une boucle entre la sensibilité et la motricité. Cette interface entre la sensation et le mouvement se complexifie au fur et à mesure de l’évolution, jusqu’à l’apparition du cerveau chez les animaux les plus intelligents. Ces derniers deviennent capables de cartographier leur territoire, de retenir des événements passés (ils ont une mémoire) et de simuler des événements futurs (ils ont une imagination). Le fonctionnement du cerveau produit l’expérience consciente, avec ses plaisirs et ses peines, ses répulsions et ses attractions. De là découle toute la gamme des émotions qui colorent les perceptions et induisent les actions. Assignée au mouvement, l’intelligence animale organise son expérience dans l’espace et le temps. Elle vise des buts et se réfère à des objets du monde environnant. A-t-elle affaire à une proie, à un prédateur, à un partenaire sexuel ? De la catégorisation suit le type d’interaction. Il ne fait aucun doute que l’intelligence animale conceptualise. Enfin, l’animal échange une foule de signes avec la faune et la flore de son milieu de vie et communique intensément avec les membres de son espèce.
[On trouvera un développement sur la complexité de l’expérience animale dans ma récente conférence]
L’IA ne possède aucun des caractères de l’intelligence animale : ni la conscience, ni le sens de l’espace et du temps, ni l’intentionalité de l’expérience (la finalité et la référence à des objets), ni l’aptitude à conceptualiser, ni les émotions, ni la communication. Or l’intelligence humaine comprend l’intelligence animale et possède en plus une capacité symbolique qui s’actualise dans le langage, les institutions sociales complexes et les techniques. Malgré sa singularité dans la nature, n’oublions jamais que la capacité symbolique humaine s’enracine dans une sensibilité animale dont elle ne peut se séparer.
Je vais examiner plus particulièrement le langage, grâce à qui nous pouvons dialoguer, raconter des histoires, poser des questions, raisonner et spéculer sur l’invisible. Commençons par analyser la composition d’un symbole. Il comprend une partie sensible, une image visuelle ou sonore (le signifiant) et une partie intelligible ou concept (le signifié). On a vu que les animaux avaient des concepts, mais l’Homme seul représente ses concepts par des images, ce qui lui permet de les réfléchir et de les combiner à volonté. Les symboles, et en particulier les symboles linguistiques, ne sont jamais isolés mais font partie de systèmes symboliques qui sont intériorisés par les interlocuteurs. Il faut que la grammaire et le dictionnaire de notre langue commune fasse partie de nos automatismes pour que nous nous comprenions de manière fluide. Les textes appartiennent simultanément à deux mondes qu’ils connectent à leur manière : ils possèdent une adresse spatio-temporelle par leur partie sensible et ils se distribuent en d’invisibles réseaux de concepts par leur partie intelligible.
Que signifie comprendre une phrase? Prenons l’exemple simple qui suit : “Je peins la petite pièce en bleu”. Je fais d’abord correspondre au son de chaque mot son concept. Puis, à partir de la séquence parlée, je construis l’arbre syntaxique de la phrase avec, à la racine, le verbe “peins”, à la feuille-sujet le mot “je”, à la feuille-objet l’expression “la petite pièce” et à la feuille-complément de manière le mot “bleu”. Mais ce n’est pas tout. Pour vraiment comprendre “je”, il me faut savoir que la première personne a été choisie par opposition à la seconde et à la troisième personne. Pour saisir “bleu” je dois savoir que c’est une couleur et qu’elle représente une sélection parmi le paradigme des couleurs (jaune, rouge, vert, violet, etc.). Et ce n’est que par rapport à grand, long ou étroit que “petite” fait sens. Bref, dans une expression symbolique simple telle qu’une courte phrase, chaque mot occupe une place dans un arbre syntaxique et actualise un choix dans un groupe de substitutions possibles.
Les phrases sont généralement proférées par des sujets en situation d’interlocution. Mes automatismes symboliques ne se contentent pas de reconstituer le sens linguistique d’une phrase à partir d’une séquence de sons, ils projettent aussi une subjectivité, une intériorité humaine, à la source de la phrase. La parole s’élève dans le va-et-vient d’un dialogue. Je situe cette phrase dans l’histoire et l’avenir possible d’une relation, au sein d’un contexte pratique particulier. D’autre part, une expression symbolique fait le plus souvent référence à une objectivité, à une réalité extra-linguistique, voir extra-sociale. Enfin, elle éveille en moi une foule de résonnances affectives plus ou moins conscientes.
En somme, l’image symbolique, qui est sensible et matérielle, va déclancher dans l’esprit humain la production et le tissage cohérent d’un sens intelligible à partir d’une multitude de fils sémantiques : un sens conceptuel ; un sens narratif par la reconstitution d’arbres syntaxiques et de groupes de substitution paradigmatiques ; un sens intersubjectif et social ; un sens référentiel objectif ; un sens affectif et mémoriel. C’est dire que, une fois recueilli par l’intelligence humaine, un texte matériel devient solidaire de toute une complexité immatérielle, complexité qui n’est nullement aléatoire mais au contraire fortement structurée par les langues, les rituels de dialogue et les règles sociales, la logique des émotions, la cohérence contextuelle inhérente aux corpus et aux mondes de référence. La capacité des modèles de langue à « raisonner » et à répondre aux requêtes de manière pertinente est un effet de corpus, en rapport avec la priorité accordée aux données d’entraînement dialogiques et à celles qui adoptent un style démonstratif. Les énormes données d’apprentissage permettent une capture statistique des normes de discours.
Or c’est précisément cette solidarité entre la partie matérielle des textes – désormais numérisés – et leur partie immatérielle que va capter l’intelligence artificielle. N’oublions pas que seul le signifiant (les séquences de 0 et de 1) existe pour les machines. Pour elles, il n’y a ni concepts, ni récits, ni sujets, ni mondes de référence réels ou fictifs, ni émotions, ni résonnances liées à une mémoire personnelle et encore moins un quelconque enracinement dans une expérience sensible de type animal. Ce n’est que grâce à la quantité gigantesque des données d’entraînement et à l’énorme puissance des centres de calcul contemporains que les modèles statistiques parviennent à réifier la relation entre la forme sensible des textes et les multiples couches de sens que détecte spontanément un lecteur humain.
Données d’entraînement et puissance de calcul
L’IA contemporaine repose sur quatre piliers : 1) les données d’entraînement, 2) la puissance de calcul, 3) les algorithmes de traitement statistique qui simulent grossièrement des réseaux neuronaux (deep learning), 4) les résultats de divers travaux “manuels” tels que les bases de données spécialisées, les graphes de connaissances qui catégorisent et structurent les données, les retours d’évaluation in vivo qui permettent des réglages fins.
Examinons plus en détail les deux premiers piliers. Les archives et mémoires analogiques ont pour la plupart été numérisées. La plus grande partie de la mémoire collective est maintenant directement produite sous forme numérique. 68% de la population mondiale était connectée à Internet en 2025 (seuls 2% de la population mondiale l’était en 2000). La foule présente en ligne produit et consomme une quantité phénoménale d’information. Or le plus petit geste dans une application, le moindre regard vers un écran alimentent les données d’entraînement des IA. Les algorithmes sont capables de prendre en compte plusieurs pages dans leur “attention” statistique. Les vastes corpus d’entraînement fournissent des contextes élargis qui permettent de raffiner le sens des mots et des expressions au-delà de ce qu’un dictionnaire pourrait proposer. On comprend donc que les modèles de langue puissent calculer des corrélations entre signifiants matériels qui impliquent – pour un lecteur humain – les significations immatérielles correspondantes. Mais il faut mobiliser pour cela une puissance de calcul inouïe. Alphabet, Amazon, Apple, Meta, Microsoft, NVIDIA et Tesla ont dépensé plus de 100 milliards de dollars dans la construction de centres de données entre Aout et Octobre 2025. Des centrales nucléaires dédiées vont bientôt alimenter les centres de données en électricité. La puissance de calcul agrégée du monde est plusieurs millions de fois supérieure à ce qu’elle était au début du 21e siècle.
Conclusion
Récapitulons les différents aspects de l’intelligence et du travail humain qui permettent aux IA de nous donner l’impression qu’elles comprennent le sens des textes. Les industriels fabriquent les installations qui supportent la puissance de calcul. Les informaticiens conçoivent et implémentent les logiciels qui effectuent les traitements statistiques. Des ontologistes (dont je suis) créent des règles, des systèmes d’étiquettes sémantiques, des graphes de connaissance et des bases de données spécialisées qui corrigent la dimension purement probabiliste des sytèmes d’IA. Des armées d’employés trient, collectent et préparent les données, puis supervisent l’entraînements des modèles. Des testeurs raffinent les réponses données par les machines, détectent leurs biais et tentent de les réduire. Je n’ai pas encore énuméré les deux facteurs qui expliquent le mieux l’intelligence des modèles de langue. Car c’est l’intelligence collective humaine qui produit les données d’entraînement, données qui enveloppent la solidarité entre les textes et leur sens. Enfin, à partir des images signifiantes générées sur un mode probabiliste par des modèles mécaniques et inconscients, c’est bel et bien l’esprit des utilisateurs vivants qui évoque des concepts, des récits, des intentions référentielles, la cohérence d’un monde réel ou fictif, une intersubjectivité dialogante, des intuitions spatio-temporelles et enfin des émotions, toutes dimensions du sens qui sont le propre de l’intelligence humaine.
En fin de compte, l’IA fonctionne comme une interface mécanique entre l’intelligence collective qui produit les données d’entraînement et les intelligences individuelles qui interrogent les modèles, lisent leurs réponses et les utilisent. Cette interface robotique entre les intelligences personnelles vivantes et l’intelligence collective accumulée augmente aussi bien – et de manière synergique – les unes que l’autre. Tel est le secret de l’intelligence artificielle, bien caché sous la fiction d’une IA autonome, qui “dépasse” l’intelligence humaine, alors qu’elle l’exprime et l’augmente. Dans ses effets concrets, ce nouveau système d’alimentation réciproque de l’intelligence individuelle et de l’intelligence collective peut contribuer à l’abrutissement des masses paresseuses et à l’extension de la banalité, comme il peut démultiplier les capacités créatives des savants et des penseurs originaux. Entre les deux, toutes les nuances de gris sont possibles. Dans l’éventail des possibilités entre ces deux extrêmes se trouve sans doute l’ultime choix éthique qui, bien qu’il concerne chacun d’entre nous, se pose de manière encore plus aiguë pour les éducateurs qui doivent enseigner l’art de lire, d’écrire et de penser. [Voir mon entrée de blog consacrée à ce sujet].
Il s’agit là du texte – simplifié et raccourci – de la communication que j’ai délivrée le 28 octobre 2025 à la PUC-RS à Porto Alegre devant les étudiants en maîtrise et doctorat de sciences humaines accompagnés de leurs professeurs.
Définissons l’humanisme d’abord comme une réflexion sur l’essence de l’Homme qui se caractérise par son abstraction et se situe dans un horizon d’universalité. Deuxièmement, fondé sur cette réflexion, l’humanisme se préoccupe du bien de l’Homme, c’est dire qu’il a une visée normative, éthique.
Karl Jaspers a nommé “période axiale” le milieu du premier millénaire avant notre ère, ce moment de l’histoire où Confucius en Chine, le Bouddha en Inde, Zarathoustra en Perse, les prophètes hébreux en Israel et Socrate en Grèce ont fondé, chacun à leur manière, de grandes traditions humanistes. On notera qu’il s’agit toujours d’une affaire de lettrés, basée sur l’usage de l’alphabet ou d’un système de caractères standardisés comme en Chine. En ce temps là, les chaînes de traditions orales commençaient à être notées, les textes manuscrits, réécrits à chaque copie, étaient fluides, éclatés entre de multiples versions. Quant aux auteurs réels, anonymes et pluriels, ils se dissimulaient souvent sous l’autorité de grands ancêtres mythiques.
La Bible et la littérature gréco-romaine sont les deux grandes racines de l’humanisme occidental. Je laisse de côté la Bible que je n’ose évoquer devant des frères maristes qui en savent plus que moi sur ce sujet et je me contenterai d’évoquer l’humanisme gréco-romain. La païdéia grecque et l’humanitas romaine (qui en est la traduction) reposent sur trois grands piliers: les lettres, l’ouverture d’esprit et le sentiment de la dignité humaine.
Les lettres comprennent ici la maîtrise du langage et de l’écriture (la grammaire), la science du raisonnement et du dialogue contradictoire (la dialectique), l’art de convaincre, enfin, essentiel dans cette culture d’orateurs politiques et d’avocats (la rhétorique). L’encyclopédie lettrée supposait la connaissance des sciences de l’époque et surtout une immersion de l’esprit dans le corpus des auteurs classiques : poètes, dramaturges et philosophes.
L’ouverture d’esprit se manifeste dans cette maxime célèbre tirée d’une pièce de Térence (2e siècle avant notre ère) : “Rien de ce qui est humain ne m’est étranger”. La phrase est elle-même inspirée de Ménandre, auteur de théâtre de l’époque hellénistique.
Le troisième point, qui définit encore aujourd’hui le fondement de l’attitude morale humaniste, est le primat de la dignité humaine. On pourrait prétendre que les romains et les grecs, qui pratiquaient l’esclavage, n’ont pas été à la hauteur de leurs propres principes. Sans doute. Mais il faut rappeler que presque toutes les sociétés ont pratiqué l’esclavage ou le servage, dont l’abolition ne date que du 19e siècle. Or, malgré leur statut juridique inférieur, on pouvait traiter les esclaves de manière “humaine” ou pas. L’auteur de théâtre Térence, que j’ai cité plus haut, et le philosophe stoïcien Épictète sont nés esclaves et ils ont été affranchis par des maîtres qui admiraient leurs talents.
L’histoire des technologies symboliques rythme celle de l’humanisme. À la Renaissance, l’imprimerie, en mécanisant la reproduction des textes, rend disponible les copies et les traductions. L’édition devient une industrie et la littérature moderne se développe. Il en résulte la naissance de l’auteur moderne, source d’un texte original, qui se matérialisera à la fin du 18e et surtout au 19e siècle par l’apparition du droit d’auteur.
Les “humanistes” de la Renaissance éditent, fixent, traduisent et impriment les textes anciens qui appartiennent aux traditions bibliques et gréco-latines. Émerge alors la critique textuelle, à savoir l’établissement des textes à partir de copies divergentes. Les studia humanitatis regroupent alors la connaissance de l’Hébreu, du Grec et du Latin. Au-delà de la compétence linguistique, le métier d’humaniste suppose une intimité avec les grands textes de la littérature et de la philosophie, une nouvelle sensibilité à la philologie, à l’histoire et aux contextes de rédaction qui aboutira au 19e siècle à la naissance de l’herméneutique moderne.
La critique textuelle mène insensiblement à l’esprit critique. Luther initie le schisme de la chrétienté latine en contestant l’autorité de l’Église qu’il déplace sur les Écritures saintes, désormais disponibles en langues vernaculaires: c’est le fameux slogan “Sola scriptura“. Première figure de l’intellectuel européen, Érasme de Rotterdam vit de sa plume grâce à l’imprimerie, navigue dans un réseau intellectuel transnational, n’hésite pas à critiquer la société et les élites de son temps (comme dans son célèbre Éloge de la folie), et s’établit par son œuvre monumentale comme un des principaux éditeurs, philologues, traducteurs, théologiens et pédagogues de l’Europe. Face à la montée des haines religieuses (et contrairement au boute-feu Luther), Érasme défend un humanisme chrétien pacifique.
Au début du 19e siècle un débat, particulièrement illustré par le pédagogue Friedrich Niethammer, partage les esprits en Allemagne. Faut-il centrer l’éducation – qui vise de plus en plus l’ensemble du peuple – sur les matières “utiles” de type scientifique et technique ou bien plutôt sur le développement de l’esprit, du goût, du jugement moral autonome et sur la capacité à s’inscrire dans une culture partagée grâce à l’étude des textes anciens? La première option, plus immédiatement pratique, se nomme alors philanthropie. Quant à la seconde option, qui insiste sur la formation de la personne ou “bildung”, elle est baptisée humanisme. Dans le monde occidental, ce débat va durer jusqu’au 20e siècle inclus, jusqu’à ce que la formation dite humaniste ne soit plus réservée qu’à une petite minorité de spécialistes professionnels et ne constitue plus l’armature de l’éducation de la majorité, ni même celle des élites.
Dans la seconde moitié du 19e siècle, l’historien Jacob Burckhardt redéfinit l’humanisme (qu’il conçoit comme un fruit de la Renaissance européenne) comme une orientation philosophique et pratique vers l’autonomie de l’esprit humain s’émancipant du clan familial, de la classe sociale et de l’autorité de l’église qui étouffent la liberté individuelle. Les idées de Burckhardt auront une grande influence sur Nietzsche, lui-même philologue de profession et fort sensible au caractère historique des manières de vivre et de penser.
Résultant d’une évolution qui avait commencé dès la Renaissance, entre les 19e et 20e siècles, l’humanisme se centre sur la valeur et la dignité de l’Homme, adopte une éthique universaliste, se situe dans une perspective générale d’émancipation ou de gain d’autonomie ; enfin, il accorde une importance privilégiée aux études littéraires et artistiques pour le développement de la personne. Cette approche a fait l’objet de nombreuses critiques en provenance des théologiens chrétiens, des penseurs socialistes et des contempteurs de la morale ordinaire. Mais je ne m’attarderai pas ici à ces nombreuses contestations, qui sont devenues particulièrement vives à partir de la fin de 1ère guerre mondiale, perçue comme un effondrement de l’humanisme européen.
Si l’humanisme naît avec l’alphabet dans un milieu lettré et renaît avec l’imprimerie, que devient-il lorsque le numérique s’affirme comme la technologie symbolique dominante? Déterminons les principaux caractères de la métamorphose du texte au 21e siècle. Toutes les expressions symboliques sont rassemblées et interconnectées dans une mémoire numérique universelle omniprésente. La manipulation des symboles (et non seulement leur reproduction et leur transmission) est automatisée. Les textes peuvent être générés, traduits, et résumés automatiquement. Les masses de données numériques entrainent l’intelligence artificielle générative (IA), qui devient la voix probabiliste de la mémoire collective. Paradoxalement l’IA représente d’autant mieux la tradition qu’on l’interroge sur des textes du canon humaniste souvent édités, traduits et commentés tels que la Bible, les pères de l’Église, Homère, Platon, Aristote, les grandes œuvres littéraires et philosophiques occidentales, sans oublier les œuvres capitales et textes sacrés des autres traditions. En revanche, plus on s’approche d’œuvres et de thèmes contemporains et plus l’IA exprime l’opinion : la rumeur et les échos de la caverne de Platon, désormais numérique.
L’humanisme n’a jamais été autant critiqué qu’en ce 21e siècle. Le posthumanisme dénonce nos illusions sur la permanence d’une humanité désormais obsolète, hybridée ou dépassée par les machines et les biotechnologies. L’écologisme et l’antispécisme critiquent notre anthropocentrisme : ayant pris conscience des ravages de l’anthropocène, du changement climatique et de l’effondrement de la diversité biologique il nous faudrait renoncer à l’humanisme qui voit en l’Homme le « maître et possesseur de la nature ». Enfin, pour les tenants d’une certaine sociologie critique (marxisme, anti-impérialisme, féminisme intersectionnel), l’humanisme universaliste masquerait la domination d’une partie de l’humanité sur une autre.
Mais il ne faut pas confondre l’humanisme avec son invocation hypocrite ou sa caricature. l’humanité n’est pas obsolète. Les derniers développements de la technique confirment, s’il en était besoin, la singularité à la fois terrible et merveilleuse de notre espèce. C’est précisément parce que nous avons – en tant qu’êtres humains – une capacité symbolique qui nous ouvre à la conscience morale que nous devons prendre la responsabilité de la biosphère et défendre la dignité intrinsèque de tous les êtres humains.
Dans le prolongment de son évolution historique et des contre-courants qui s’y sont opposés tout en l’enrichissant, je voudrais maintenant articuler ma propre version de l’humanisme au 21e siècle. Je vais énoncer quelques principes fort simples qui, à mon sens, devraient guider la communauté des “humanités” désormais numériques.
À la racine se trouve un certain rapport à la parole et à la tradition. Un humaniste reconnait le poids existentiel de la parole et considère le langage comme le milieu éminent du sens. À une époque de démystification et de critique tous azimuts, il faut réapprendre à cultiver une révérence pour les textes et les symboles. Plutôt que de rejeter aveuglément les traditions, dans une logique de “table rase”, nous devrions travailler à les recueillir, non pour les réifier ou les maintenir inchangées mais pour les faire vivre au présent, les réinterpréter et les transmettre.
Les trois pratiques humanistes par excellence – lire, écrire, penser – se conditionnent mutuellement.
La lecture est essentiellement un rapport à la bibliothèque, que son support soit l’encre et le papier ou l’écran et l’électron. En tant qu’humaniste, ma vocation est d’accueillir, autant que possible, la source de sens virtuellement infinie de la bibliothèque. En lisant, je dé-couvre sous un texte une parole vivante qui s’adresse à moi. Afin de recueillir le sens du texte, je ne m’enferme pas dans une seule méthodologie mais je mobilise la philologie, les analyses formelles, l’histoire, les influences. Chaque texte peut être interprété sur le fond d’une multiplicité de corpus (celui de l’auteur, de l’époque, du genre, du sujet, etc.) si bien que la figure unique du texte donne lieu à plusieurs formes selon les perspectives. L’IA ne doit jamais se substituer à la lecture. Rien ne remplace la relation directe avec un texte. En revanche, l’IA peut augmenter la lecture par des explications, des commentaires, des références, voire l’évocation d’une littérature secondaire. Ne plus lire à la première personne, c’est cesser d’apprendre et renoncer à comprendre.
Passons maintenant à l’écriture. Écrire, c’est s’incrire dans le temps, entretenir un rapport au passé, au présent et à l’avenir. Dans la relation au passé, l’écriture se confronte aux canons et aux corpus. L’auteur soliste ne chante jamais qu’accompagné par le chœur fantomatique des générations disparues. Dans le présent vivant, je participe à un dialogue de lettrés où se croisent mémoire collective (peut-être portée par l’IA) et mémoire personnelle. J’articule une parole vivante qui s’adresse à l’autre pour faire jaillir un sens contemporain. Dans mon rapport à l’avenir, j’ajoute à une mémoire collective qui contribue à entraîner les IA et qui touchera peut-être l’esprit des générations futures. Quelle responsabilité! Sauf pour les tâches administratives, l’IA ne doit jamais se substituer à l’écriture. Mais elle peut la préparer en rédigeant des fiches ou en organisant des notes, comme le ferait un assistant. Elle peut aussi parfaire un texte en travaillant à son édition ou à sa bibliographie. Ne plus écrire à la première personne, c’est cesser de penser.
Et justement, qu’est-ce que penser en humaniste ? Il s’agit d’abord d’enrichir notre mémoire personnelle, qui est le fondement de la pensée vivante. Ce n’est pas parce que “tout” se trouve sur internet que nous devons cesser de cultiver notre mémoire individuelle. Et cela précisément parce que la pensée est un dialogue des mémoires. Elle se tisse en effet dans une dialectique entre la mémoire collective représentée aujourd’hui par l’IA, la mémoire personnelle de chacun d’entre nous et le dialogue ouvert – contradictoire et complice – avec nos pairs et contemporains. Plus riche est notre mémoire personnelle et mieux nous pouvons exploiter les ressources de l’IA, poser les bonnes questions, repérer les hallucinations, éclairer les angles morts. En aucun cas l’IA ne peut se substituer à l’ignorance. Mais elle peut servir de conseillère et d’entraîneuse pour nos apprentissages. Ignorants, nous serons manipulés et induits en erreur par les modèles de langue. Par contraste, plus nous sommes savants et mieux nous pouvons maîtriser l’IA qui, quoiqu’elle soit aujourd’hui l’environnement de la pensée ou le nouveau sensorium, n’est jamais qu’un outil.
L’humanisme est aujourd’hui attaqué sur trois fronts. 1) Pour le post-humanisme, l’IA et les biotechnologies signifieraient la fin de l’Homme ou du moins la fin de l’humanisme traditionnel. 2) Pour l’écologisme et l’antispécisme, l’humain doit renoncer à son anthropocentrisme. Au vu des ravages de l’anthropocène, l’idéal biblique et moderne selon lequel nous aurions vocation à devenir « les maîtres et possesseurs de la nature » (Descartes) doit être abandonné. 3) Pour la critique de la domination, l’universalisme et l’essentialisme inhérent à l’humanisme moderne européen masquent les oppressions patriarcales, coloniales et capitalistes.
Comment penser une essence de l’Homme qui échappe aux critiques contemporaines de l’humanisme? Il s’agit de mener ici quelques réflexions préalables au développement d’une anthropologie philosophique à venir. Le but de ces trois conférences est de commencer à repenser l’humain en tant que singularité dans la nature. En effet, je ne crois pas qu’il soit possible de mener une méditation éthique sans s’interroger sur l’essence de l’humain et donc sans mettre en évidence ce qui nous distingue des animaux. On interrogera donc la figure d’un étrange animal à trois faces : parlant, politique et technicien.
Calendrier
16 septembre 2025, de 11h à 12h15 (heure de Montréal) : La sensibilité animale
J’explorerai pour commencer ce qu’il y a de commun entre l’humanité et les autres animaux : le système nerveux, l’expérience consciente, l’émotion, l’objet, le concept, l’image, l’espace, le temps, le territoire, la communication par signes et la stigmergie. On verra qu’une bonne part du sujet transcendantal kantien, des structures phénoménologiques et les modèles de la psychologie cognitive ne sont pas propres à l’humain. Lien vers l’enregistrement: https://api.nakala.fr/embed/10.34847/nkl.1b7bumx6/3ad9cb49a117d4ab4926a4c55173128547cc5a57
7 octobre 2025, de 11h à 12h15 (heure de Montréal): L’ordre symbolique
L’ordre symbolique distingue l’humain des autres espèces animales. Le symbolisme ne se limite pas au langage ni même à la communication alexique comme la musique. Il enveloppe aussi la complexité sociale et les opérations techniques, dont je montrerai qu’elles obéissent à des structures semblables. Le symbolisme recrée l’espace et le temps comme coordonnées d’un monde et d’une histoire. Lien vers l’enregistrement: https://nakala.fr/10.34847/nkl.9da2x163
14 octobre 2025, de 11h à 12h15 (heure de Montréal): Le roseau pensant
Dans ce dernier exposé, je tenterai de saisir la singularité humaine à partir de l’analyse des interactions symbiotiques entre populations de primates parlants et écosystèmes symboliques. Il sera question a) de la dépendance réciproque du sensorium sociotechnique et de l’univers intellectuel et b) de la manière dont l’intériorisation des programmes culturels assure l’intégration brinquebalante des sociétés. En conclusion, je reviendrai sur les critiques contemporaines de l’humanisme à la lumière des concepts dégagés dans ces trois conférences, en insistant sur l’universalité du questionnement éthique, propre à l’humain! Lien vers le troisième enregistrement : https://nakala.fr/10.34847/nkl.ecc8ai9b
Q1- Face à l’hyper-connectivité croissante chez les jeunes, de nombreux experts parlent de solitude et de ce qu’ils appellent “l’âge des passions tristes”. Comment voyez-vous cette dichotomie entre proximité et distance que la technologie provoque dans les relations humaines?
R1 – L’hyper-connectivité ne concerne pas seulement les jeunes, elle est partout. Un des facteurs principaux de l’évolution culturelle réside dans le dispositif matériel de production et de reproduction des symboles, mais aussi dans les systèmes logiciels d’écriture et de codage de l’information. Notre intelligence collective prolonge celle des espèces sociales qui nous ont précédées, et particulièrement celle des grands singes. Mais l’usage du langage – et d’autres systèmes symboliques – tout comme la force de nos moyens techniques nous a fait passer du statut d’animal social à celui d’animal politique. Proprement humaine, la Polis émerge de la symbiose entre des écosystèmes d’idées et les populations de primates parlants qui les entretiennent, s’en nourrissent et s’y réfléchissent. L’évolution des idées et celles des peuplements de Sapiens se déterminent mutuellement. Or le facteur principal de l’évolution des idées réside dans le dispositif matériel de reproduction des symboles. Au cours de l’histoire, les symboles (avec les idées qu’ils portaient) ont été successivement pérennisés par l’écriture, allégés par l’alphabet et le papier, multipliés par l’imprimerie et les médias électriques. Les symboles sont aujourd’hui numérisés et calculés, c’est-à-dire qu’une foule de robots logiciels – les algorithmes – les enregistrent, les comptent, les traduisent et en extraient des patterns. Les objets symboliques (textes, images fixes ou animées, voix, musiques, programmes, etc.) sont non seulement enregistrés, reproduits et transmis automatiquement, ils sont aussi générés et transformés de manière industrielle. En somme, l’évolution culturelle nous a menés au point où les écosystèmes d’idées se manifestent sous la forme de données animées par des algorithmes dans un espace virtuel ubiquitaire. Et c’est dans cet espace que se nouent, se maintiennent et se dénouent désormais les liens sociaux. Avant de critiquer ou de déplorer, il faut d’abord reconnaître les faits. Les amitiés des jeunes gens ne peuvent plus se passer des médias sociaux ; les couples se rencontrent sur internet, par exemple sur des applications comme Tinder (voir la Figure 1) ; les familles restent connectées par Facebook ou d’autres applications comme WhatsApp ; les espaces de travail ont basculé dans l’électronique avec Zoom et Teams, particulièrement depuis la pandémie de COVID ; la diplomatie se fait de plus en plus sur X (ex Twitter), etc. On ne reviendra pas en arrière. D’un autre côté, on ne se déplace pas moins de manière physique : en témoignent les embouteillages monstrueux de Sao Paulo et Rio de Janeiro. Dans le même ordre d’idées, la tendance sur les dix dernières années – époque de croissance exponentielle des connexions Internet – montre aussi une augmentation du nombre de passagers aériens, qui continue une tendance séculaire, et cela malgré une baisse importante durant la pandémie de COVID-19.
Je me sentais bien seul lorsque, jeune étudiant, je suis arrivé à Paris du sud de la France, pour faire mes études universitaires. C’était en 1975 et il n’y avait pas d’internet. Les seniors qui vivent seuls et que leurs enfants ne visitent pas doivent-ils blâmer Internet? Le problème de la solitude et de la désagrégation des liens sociaux est bien réel. Mais c’est une tendance déjà ancienne, qui tient à l’urbanisation, aux transformations de la famille et à bien d’autres facteurs. J’invite vos lecteurs à consulter les nombreux travaux sur la question du “capital social” (la quantité et à la qualité des relations humaines). L’internet n’est qu’un des nombreux facteurs à considérer sur cette question.
Figure 1
Q2- Dans vos livres “Collective Intelligence: For an anthropology of cyberspace” (1994) et “Cyberculture: The Culture of the Digital Society” (1997), vous soutenez qu’Internet et les technologies numériques développent l’intelligence collective, permettant de nouvelles formes de collaboration et de partage des connaissances. Cependant, on craint de plus en plus que l’utilisation excessive des médias sociaux et des technologies numériques soit associée à une distraction et à un retard d’apprentissage chez les jeunes. Comment voyez-vous cette apparente contradiction entre le potentiel des technologies à renforcer l’intelligence collective et les effets négatifs qu’elles peuvent avoir sur le développement cognitif et éducatif des jeunes?
R2- Je n’ai jamais soutenu qu’Internet et les technologies numériques, par eux-mêmes et comme si les techniques étaient des sujets autonomes, développent l’intelligence collective. J’ai soutenu que le meilleur usage que nous pouvions faire d’internet et des technologies numériques était de développer l’intelligence collective humaine, ce qui est bien différent. Et c’est d’ailleurs toujours ce que je pense. L’idée d’un « espace du savoir » qui pourrait se déployer au-dessus de l’espace marchand est un idéal régulateur pour l’action, non une prédiction de type factuel. Lorsque j’ai rédigé L’Intelligence Collective – de 1992 à 1993 – moins de 1% de l’humanité était branchée sur l’Internet et le Web n’existait pas. Vous ne trouverez nulle part le mot « web » dans l’ouvrage. Or nous avons aujourd’hui – en 2024 – largement dépassé les deux tiers de la population mondiale connectée à l’Internet. Le contexte est donc complètement différent mais le changement de civilisation que je prévoyais il y a 30 ans semble évident aujourd’hui, bien qu’il faille attendre normalement plusieurs générations pour confirmer ce type de mutation. A mon sens, nous ne sommes qu’au commencement de la révolution numérique.
Quant à l’augmentation de l’intelligence collective, de nombreux pas ont été franchis pour mettre les connaissances à la portée de tous. Wikipédia est l’exemple classique d’une entreprise qui fonctionne en intelligence collective avec des millions de contributeurs bénévoles de tous les pays et des groupes de discussion entre experts pour chaque article. Il y a près de sept millions d’articles en anglais, deux millions et demi d’articles en français et plus d’un million d’articles en portugais. Wikipédia est consulté par plusieurs dizaines de millions de personnes par jour et plusieurs milliards par an! Le logiciel libre – maintenant largement adopté et diffusé, y compris par les grandes entreprises du Web – est un autre grand domaine où l’intelligence collective est au poste de commande. Parmi les plus utilisés des logiciels libres citons le système d’exploitation Linux, les navigateurs Mozilla et Chromium, la suite Open Office, le serveur http Apache (qui est le plus utilisé sur Internet), le système de contrôle des versions GIT, la messagerie Signal, et bien d’autres qu’il serait trop long de citer. J’ajoute que les bibliothèques et les musées numérisés, comme les articles scientifiques en accès libre et les sites de type ArXiv.org, sont monnaie courante, ce qui transforme les pratiques de recherche et de communication scientifique. Tout le monde peut aujourd’hui publier des textes sur son blog, des vidéos et des podcasts sur YouTube ou d’autres sites, ce qui n’était pas le cas il y a trente ans. Les médias sociaux permettent d’échanger des nouvelles et des idées très rapidement, comme on le voit par exemple sur LinkedIn ou X (ex Twitter). Internet a donc réellement permis le développement de nouvelles formes d’expression, de collaboration et de partage des connaissances. Beaucoup reste à faire. Nous ne sommes qu’au tout début de la mutation anthropologique en cours.
Bien entendu, il nous faut prendre en compte les phénomènes d’addiction aux jeux vidéos, aux médias sociaux, à la pornographie en ligne, etc. Mais depuis plus de trente ans, la majorité des journalistes, des hommes politiques, des enseignants et de tous ceux qui font l’opinion ne cessent de dénoncer les dangers de l’informatique, puis de l’Internet et maintenant de l’intelligence artificielle. Je ne ferais rien de très utile si j’ajoutais mes lamentations aux leurs. J’essaye donc de faire prendre conscience d’une mutation de civilisation de grande ampleur qu’on n’arrêtera pas et d’indiquer les meilleurs moyens de diriger cette grande transformation vers les finalités les plus positives pour le développement humain. Ceci dit, il est clair que les phénomènes d’addiction trouvent partiellement leur source dans notre dépendance à l’architecture sociotechnique toxique des grandes compagnies du Web, qui utilise la stimulation dopaminergique et les renforcements narcissiques de la communication numérique pour nous faire produire toujours plus de données et vendre plus de publicité. Malheureusement la santé mentale des populations adolescentes est peut-être une des victimes collatérales des stratégies commerciales de ces grandes entreprises oligopolistiques. Comment s’opposer à la puissance de leurs centres de calcul, à leur efficacité logicielle et à la simplicité de leurs interfaces? Il est plus facile de poser la question que d’y répondre. En plus de la biopolitique évoquée par Michel Foucault, il faut maintenant considérer une psychopolitique à base de neuromarketing, de données personnelles et de gamification du contrôle. Les enseignants doivent avertir les étudiants de ces dangers et les former à la pensée critique.
Q3- Avec le phénomène des “bulles connectives”, où les réseaux sociaux ont tendance à renforcer des croyances et des idées préexistantes, limitant les contacts avec des perspectives différentes, comment voyez-vous l’évolution des liens sociaux à mesure qu’Internet et les plateformes numériques continuent de se développer? Ce type de segmentation pourrait-il affaiblir l’intelligence collective que vous prônez, ou y a-t-il encore de la place pour des connexions plus larges et plus collaboratives à l’avenir?
R3 – Il est clair que si l’on se contente de « liker » instinctivement ce que l’on voit défiler et de réagir émotionnellement aux images et aux messages les plus simplistes, le bénéfice cognitif ne sera pas très grand. Je ne me pose pas en modèle à suivre absolument, je voudrais seulement donner un exemple de ce qu’il est possible de faire si l’on un peu d’imagination et que l’on est prêt à remettre en cause l’inertie des institutions. Lorsque j’étais professeur en communication numérique à l’Université d’Ottawa, je forçais mes étudiants à s’inscrire sur Twitter, à choisir une demi-douzaine de sujets intéressants pour eux et à dresser des listes de comptes à suivre pour chaque sujet. Quelque soit le thème – politique, science, mode, art, sports, etc. – ils devaient construire des listes équilibrées comprenant des experts ou des partisans d’avis opposés afin d’élargir leur sphère cognitive au lieu de la restreindre. Sur les médias sociaux les plus courants comme Facebook et LinkedIn, il est possible de participer à un grand nombre de communautés spécialisées dans des domaines culturels (histoire, philosophie, arts) ou professionnels (affaires, technologie, etc.) afin de se tenir au courant et de discuter avec des experts. Les groupes de discussion locaux par villages ou quartiers sont aussi très utiles. Tout est question de méthode et de pratique. Il faut se détacher du modèle des médias de masse (journaux papier, radio, télévision) dans lequel des récepteurs passifs consomment une programmation faite par d’autres. C’est à chacun de se bricoler sa propre programmation et de se construire ses réseaux personnels d’apprentissage.
Avant l’imprimerie, on ne parlait qu’avec les gens de sa paroisse. Dans les années soixante du XXe siècle on n’avait le choix qu’entre deux ou trois chaines de télévision et deux ou trois journaux. Aujourd’hui nous avons accès à une énorme diversité de sources en provenance de tous les pays et de tous les secteurs de la société. Les enseignants doivent alphabétiser les étudiants, leur apprendre les langues étrangères, leur donner une bonne culture générale et les guider dans ce nouvel univers de communication.
Q4- Actuellement, il y a un débat croissant sur les effets négatifs de la technologie sur la santé mentale des jeunes, en mettant l’accent sur des problèmes tels que l’anxiété, la dépression et l’isolement social. Considérant le rôle central que jouent les technologies numériques dans notre société, comment comprenez-vous cette relation entre l’usage intensif des technologies et l’augmentation des problèmes de santé mentale chez les jeunes? Existe-t-il un moyen d’équilibrer les avantages de la technologie avec la nécessité de préserver le bien-être mental?
R4 – Le problème de la santé mentale des jeunes est bien sûr tout à fait réel, mais il serait réducteur de l’attribuer uniquement aux médias sociaux. Néanmoins je vais essayer d’énumérer quelques problèmes psychologiques qui naissent de l’usage des Technologies numériques.
Il y a d’abord la transformation de l’autoréférence subjective, qui risque de mener à des problèmes de type schizophrénique. Notre champ d’expérience est médiatisé par le support numérique : la boucle d’autoréférence est plus large que jamais. Nous interagissons avec des personnes, des robots, des images, des musiques par le biais de plusieurs interfaces multimédias : écran, écouteurs, manettes… Notre expérience subjective est contrôlée par les algorithmes de multiples applications qui déterminent en boucle (si nous n’avons pas appris à les maîtriser) notre consommation de données et nos actions en retour. Notre mémoire est dispersée dans de nombreux fichiers, bases de données, en local et dans le cloud… Lorsqu’une grande partie de nous-mêmes est ainsi collectivisée et externalisée, le problème des limites et de la détermination de l’identité devient prépondérant. À qui appartiennent les données me concernant, qui les produit ?
Le problème du narcissisme est particulièrement évident sur Instagram et les applications même genre. Notre ego est nourri par l’image que les autres nous renvoient dans le médium algorithmique. L’obsession de l’image atteint des proportions inquiétantes. Combien d’abonnés, combien de likes, combien d’impressions? Pour ceux qui ont sombré dans ce gouffre, la valeur de l’être n’est plus que dans le regard de l’autre. Avant d’être un problème de santé mentale il s’agit d’un problème de sagesse élémentaire.
A l’opposé du narcissisme, nous avons une tendance vers l’autisme. Ici le moi est enfermé dans sa vie intérieure, mais alimenté par des sources d’information en ligne. Le code ou certains aspects de la culture populaire deviennent obsessionnels. C’est le domaine des geeks, des Otakus et des joueurs compulsifs. Il est évidemment malsain de se passer de toute vie sociale en chair et en os.
Il existe un problème de santé mentale si les affects sont constamment euphoriques, ou constamment dysphoriques, ou si un objet exclusif devient addictif. En effet, Internet peut nous rendre dépendants à certains objets (actualités, séries, jeux, pornographie) ou à certaines émotions, qu’elles soient positives (contenu « feel-good » de type chats mignons, danse, humour, etc.) ou négatives (actualités catastrophiques, « doom scrolling ») de manière déséquilibrée. On peut aussi se demander dans quelle mesure il est bon que le langage corporel soit entièrement remplacé par des emojis, des mèmes, des images, des avatars, etc.
L’addiction est créée par l’excitation (dopamine) et la satisfaction (endorphine) que nous voulons reproduire sans arrêt. Or, comme je l’ai dit plus haut, les modèles d’affaire des grandes entreprise du web qui sont axés sur l’engagement (sécrétion de dopamine-endorphine) conduisent presque inévitablement à la dépendance si les utilisateurs ne font pas attention. L’intensité d’engagement élevée pendant de trop longs moments mène inévitablement à une dépression.
Le contrôle des impulsions (agressivité, par exemple) est plus difficile dans les médias sociaux que dans la vie réelle parce que nos interlocuteurs ne se trouvent pas en face de nous. La « gestion des comportements toxiques » est d’ailleurs un problème majeur dans les jeux en ligne et les médias sociaux.
En somme, il faut être vigilant, prévenir les jeunes utilisateurs des dangers encourus et ne pas commettre d’excès.
Q5 – Certains prédisent que les générations futures pourraient ne plus jamais fréquenter l’école. Comment voyez-vous l’avenir de l’éducation dans un monde de plus en plus hyperconnecté et dominé par la technologie?
R5 – Je ne crois pas que l’école va disparaître. Mais elle doit se transformer. Il faut prendre les étudiants où ils sont et de préférence utiliser les produits grands public auxquels ils sont habitués pour en faire quelque chose d’utile sur le plan de l’apprentissage. Les élèves sont des « digital natives » mais cela ne veut pas dire qu’ils ont une véritable maîtrise des outils numériques. Il faut non seulement développer la littéracie numérique mais la littéracie tout court, qui en est indissociable. Je suis un grand partisan de la lecture des classiques et de la culture générale, qui est indispensable pour former l’esprit critique.
Pour revenir à mes propres méthodes pédagogiques, dans les cours que je donnais à l’Université d’Ottawa, je demandais à mes étudiants de participer à un groupe Facebook fermé, de s’enregistrer sur Twitter, d’ouvrir un blog s’ils n’en n’avaient pas déjà un et d’utiliser une plateforme de curation collaborative de données.
L’usage de plateformes de curation de contenu me servait à enseigner aux étudiants comment choisir des catégories ou « tags » pour classer les informations utiles dans une mémoire à long terme, afin de les retrouver facilement par la suite. Cette compétence leur sera fort utile dans le reste de leur carrière.
Les blogs étaient utilisés comme supports de « devoir final » pour les cours gradués (c’est-à-dire avant le master), et comme carnets de recherche pour les étudiants en maîtrise ou en doctorat : notes sur les lectures, formulation d’hypothèses, accumulation de données, première version d’articles scientifiques ou de chapitres des mémoires ou thèses, etc. Le carnet de recherche public facilite la relation avec le superviseur et permet de réorienter à temps les directions de recherche hasardeuses, d’entrer en contact avec les équipes travaillant sur les mêmes sujets, etc.
Le groupe Facebook était utilisé pour partager le Syllabus ou « plan de cours », l’agenda de la classe, les lectures obligatoires, les discussions internes au groupe – par exemple celles qui concernent l’évaluation – ainsi que les adresses électroniques des étudiants (Twitter, blog, plateforme de curation sociale, etc.). Toutes ces informations étaient en ligne et accessibles d’un seul clic, y compris les lectures obligatoires numérisées et gratuites. Les étudiants pouvaient participer à l’écriture de mini-wikis à l’intérieur du groupe Facebook sur des sujets de leur choix, ils étaient invités à suggérer des lectures intéressantes reliées au sujet du cours en ajoutant des liens commentés. J’utilisais Facebook parce que la quasi-totalité des étudiants y étaient déjà abonnés et que la fonctionnalité de groupe de cette plateforme est bien rodée. Mais j’aurais pu utiliser n’importe quel autre support de gestion de groupe collaboratif, comme Slack ou les groupes de LinkedIn.
Sur Twitter (maintenant X), la conversation propre à chaque classe était identifiée par un hashtag. Au début, j’utilisais le médium à l’oiseau bleu de manière ponctuelle. Par exemple, à la fin de chaque classe je demandais aux étudiants de noter l’idée la plus intéressante qu’ils avaient retenu du cours et je faisais défiler leurs tweets en temps réel sur l’écran de la classe. Puis, au bout de quelques semaines, je les invitais à relire leurs traces collectives sur Twitter pour rassembler et résumer ce qu’ils avaient appris et poser des questions – toujours sur Twitter – si quelque chose n’était pas clair, questions auxquelles je répondais par le même canal.
Au bout de quelques années d’utilisation de Twitter en classe, je me suis enhardi et j’ai demandé aux étudiants de prendre directement leurs notes sur ce medium social pendant le cours de manière à obtenir un cahier de notes collectif. Pouvoir regarder comment les autres prennent des notes (que ce soit sur le cours ou sur des textes à lire) permet aux étudiants de comparer leurs compréhensions et de préciser ainsi certaines notions. Ils découvrent ce que les autres ont relevé et qui n’est pas forcément ce qui les a stimulés eux-mêmes… Quand je sentais que l’attention se relâchait un peu, je leur demandais de s’arrêter, de réfléchir à ce qu’ils venaient d’entendre et de noter leurs idées ou leurs questions, même si leurs remarques n’étaient pas directement reliées au sujet du cours. Twitter leur permettait de dialoguer librement entre eux sur les sujets étudiés sans déranger le fonctionnement de la classe. Je consacrais toujours la fin du cours à une période de questions et de réponses qui s’appuyais sur un visionnement collectif du fil Twitter. Cette méthode est particulièrement pertinente dans les groupes trop grands (parfois plus de deux cents personnes) pour permettre à tous les étudiants de s’exprimer oralement. Je pouvais ainsi répondre tranquillement aux questions après la classe en sachant que mes explications restaient inscrites dans le fil du groupe. La conversation pédagogique se poursuit entre les cours. Bien entendu, tout cela n’était possible que parce que l’évaluation (la notation des étudiants) était basée sur leur participation en ligne.
En utilisant Facebook et Twitter en classe, les étudiants n’apprenaient pas seulement la matière du cours mais aussi une façon « cultivée » de se servir des médias sociaux. Documenter ses petits déjeuners ou la dernière fête bien arrosée, disséminer des vidéos de chats et des images comiques, échanger des insultes entre ennemis politiques, s’extasier sur des vedettes du show-business ou faire de la publicité pour telle ou telle entreprise sont certainement des usages légitimes des médias sociaux. Mais on peut également entretenir des dialogues constructifs dans l’étude d’un sujet commun. En somme, je crois que l’éducation doit progresser en direction de l’apprentissage collaborative en utilisant les outils numériques.
Q6 – Quelles sont, selon vous, les principales opportunités qu’Internet et les nouveaux outils d’IA peuvent apporter au domaine de l’éducation? Compte tenu de l’avancée accélérée des technologies numériques et de l’intelligence artificielle, comment voyez-vous évoluer le rôle de l’enseignant dans les années à venir?
R6 – Concernant l’intelligence artificielle (par exemple ChatGPT, MetaAI, Grok ou Gemini, qui sont tous gratuits et assez bons), elle peut être fort utile comme mentor des étudiants ou comme encyclopédie de premier recours, pour donner des réponses et des orientations très rapidement. Les étudiants utilisent déjà ces outils, il ne faut donc pas interdire leur usage mais, une fois encore, le cultiver, le faire passer à un niveau supérieur. Comme l’IA générative est de nature statistique et probabiliste, elle fait régulièrement des erreurs. Il faut donc toujours vérifier les informations sur de véritables encyclopédies, des moteurs de recherche, des sites spécialisés ou même… dans une bibliothèque! J’ajoute que plus on est cultivé et mieux on connaît un sujet et plus l’usage des IA génératives est fructueux, car on est alors capable de poser de bonnes questions et de demander des informations complémentaires lorsque l’on sent que quelque chose manque. L’IA n’est pas un substitut à l’ignorance, elle donne au contraire une prime à ceux qui ont déjà de bonnes connaissances.
Utiliser les IA génératives pour rédiger à notre place ou faire des résumés de texte au lieu de lire des livres n’est pas une bonne idée, au moins dans un usage pédagogique. Sauf bien sûr si cette pratique est encadrée par l’enseignant afin de stimuler l’esprit critique et le goût du beau style. Au moins en 2024, les textes de l’IA sont généralement redondants, banals et facilement reconnaissables. De plus, leurs résumés de documents ne parviennent pas à saisir ce qu’il y a de plus original dans un texte, puisqu’ils n’ont pas été entraînés sur des idées rares mais au contraire sur l’avis général que l’on retrouve partout. On apprend à penser en lisant et en écrivant en personne : donc les IA sont de bons auxiliaires mais en aucun cas de purs et simples remplacements de l’activité intellectuelle humaine.
Q-7- On craint de plus en plus que l’IA puisse supprimer de nombreux emplois à l’avenir. Comment pensez-vous que cela affectera le marché du travail et quelles pourraient être les solutions possibles?
Q-7 Du fait même de son nom, l’intelligence artificielle évoque naturellement l’idée d’une intelligence autonome de la machine, qui se pose en face de l’intelligence humaine, pour la simuler ou la dépasser. Mais si nous observons les usages réels des dispositifs d’intelligence artificielle, force est de constater que, la plupart du temps, ils augmentent, assistent ou accompagnent les opérations de l’intelligence humaine. Déjà, à l’époque des systèmes experts – lors des années 80 et 90 du XXe siècle – j’observais que les savoirs critiques de spécialistes au sein d’une organisation, une fois codifiés sous forme de règles animant des bases de connaissances, pouvaient être mis à la portée des membres qui en avaient le plus besoin, répondant précisément aux situations en cours et toujours disponibles. Plutôt que d’intelligences artificielles prétendument autonomes, il s’agissait de médias de diffusion des savoir-faire pratiques, qui avaient pour principal effet d’augmenter l’intelligence collective des communautés utilisatrices.
Dans la phase actuelle du développement de l’IA, le rôle de l’expert est joué par les foules qui produisent les données et le rôle de l’ingénieur cogniticien qui codifie le savoir est joué par les réseaux neuronaux. Au lieu de demander à des linguistes comment traduire ou à des auteurs reconnus comment produire un texte, les modèles statistiques interrogent à leur insu les multitudes de rédacteurs anonymisés du web et ils en extraient automatiquement des patterns de patterns qu’aucun programmeur humain n’aurait pu tirer au clair. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. Bien loin d’être autonome, cette IA prolonge et amplifie l’intelligence collective. Des millions d’utilisateurs contribuent au perfectionnement des modèles en leur posant des questions et en commentant les réponses qu’ils en reçoivent. On peut prendre l’exemple de Midjourney (qui génère des images), dont les utilisateurs s’échangent leurs consignes (prompts) et améliorent constamment leurs compétences. Les serveurs Discord de Midjourney sont aujourd’hui les plus populeux de la planète, avec plus d’un million d’utilisateurs. Une nouvelle intelligence collective stigmergique émerge de la fusion des médias sociaux, de l’IA et des communautés de créateurs. Derrière « la machine » il faut entrevoir l’intelligence collective qu’elle réifie et mobilise.
L’IA nous offre un nouvel accès à la mémoire numérique mondiale. C’est aussi une manière de mobiliser cette mémoire pour automatiser des opérations symboliques de plus en plus complexes, impliquant l’interaction d’univers sémantiques et de systèmes de comptabilité hétérogènes.
Je ne crois pas une seconde à la fin du travail. L’automatisation fait disparaître certains métiers et en fait naître de nouveaux. Il n’y a plus de maréchaux ferrants, mais les garagistes les ont remplacés. Les porteurs d’eau ont fait place aux plombiers. La complexification de la société augmente le nombre des problèmes à résoudre. Les machines « intelligentes » vont surtout augmenter la productivité du travail cognitif en automatisant ce qui peut l’être. Il y aura toujours besoin de gens intelligents, créatifs et compassionnés mais ils devront apprendre à travailler avec les nouveaux outils.
Q-8 Certains auteurs évoquent l’inversion de “l’effet Flynn”, suggérant que les générations futures auront un niveau cognitif inférieur à celui de leurs parents. Comment voyez-vous cet enjeu dans le contexte des technologies émergentes? Pensez-vous que l’usage intensif des technologies numériques puisse contribuer à cette tendance, ou offrent-elles de nouvelles façons d’élargir nos capacités cognitives?
R-8 La baisse du niveau cognitif (et moral), est déplorée depuis des siècles par chaque génération, alors que l’effet Flynn montre justement l’inverse. Il est normal que l’on assiste à une stabilisation des scores de Quotient Intellectuel (QI) : l’espoir d’une augmentation constante n’est jamais très réaliste et il serait normal d’atteindre une limite ou un palier, comme dans n’importe quel autre phénomène historique ou même biologique. Mais admettons que les jeunes gens d’aujourd’hui aient de moins bons scores de QI que les générations qui les précèdent immédiatement. Il faut d’abord se demander ce que mesurent ces tests : principalement une intelligence scolaire. Ils ne prennent en compte ni l’intelligence émotionnelle, ni l’intelligence relationnelle, ni la sensibilité esthétique, ni les habiletés physiques ou techniques, ni même le bon sens pratique. Donc on ne mesure là quelque chose de limité. D’autre part, si l’on reste sur l’adaptation au fonctionnement scolaire que mesurent les tests de QI, pourquoi accuser d’abord les technologies? Peut-être y-t-il démission des familles face à la tâche éducative (notamment parce que les familles se défont), ou bien défaillance des écoles et des universités qui deviennent de plus en plus laxistes (parce que les étudiants sont devenus des clients à satisfaire à tout prix) ? Quand j’étais étudiant, le « A » aux examens n’était pas encore un droit… Il l’est quasiment devenu aujourd’hui.
Finalement, et il faut le répéter sans cesse, « l’usage des technologies numériques » n’a pas grand sens. Il y a des usages abrutissants, qui glissent sur la pente de la paresse intellectuelle, et des usages qui ouvrent l’esprit, mais qui demandent une prise de responsabilité personnelle, un effort d’autonomie et – oui – du travail. C’est le rôle des éducateurs de favoriser les usages positifs.
Q-9 Existe-t-il des frontières claires entre le monde réel et le monde virtuel? Qu’est-ce qui pourrait nous motiver à continuer dans le monde réel alors que le monde virtuel offre des possibilités d’interaction et de réussite quasi illimitées?
R-9 Il n’y a jamais eu de frontière claire entre le monde virtuel et le monde actuel. Où se trouve la présence humaine? Dès que nous assumons une situation dans l’existence, nous nous retrouvons immanquablement entre deux. Entre le virtuel et l’actuel, entre l’âme et le corps, entre le ciel et la terre, entre le yin et le yang. Notre existence s’étire dans un intervalle et la relation fondamentale entre le virtuel et l’actuel est une transformation réciproque. C’est un morphisme qui projette le sensible sur l’intelligible et inversement.
Une situation pratique comprend un contexte actuel : notre posture, notre position, ce qui se trouve autour de nous en ce moment précis, de nos interlocuteurs à l’environnement matériel. Elle implique aussi un contexte virtuel : le passé dans notre mémoire, nos plans et nos attentes, nos idées de ce qui nous arrive. C’est ainsi que nous discernons les lignes de force et les tensions de la situation, son univers de problèmes, ses obstacles et ses échappées. Les configurations corporelles n’ont de sens que par le paysage virtuel qui les entoure.
Nous ne vivons donc pas seulement dans la réalité physique dite « matérielle », mais aussi dans le monde des significations. C’est ce qui fait de nous des humains. Maintenant, si l’on veut parler des médias dits « numériques » , en plus de leur aspect logiciel (les programmes et les données) ils sont évidemment aussi matériels : les centres de données, les câbles, les modems, les ordinateurs, les smartphones, les écrans, les écouteurs sont tout ce qu’il y a de plus matériels et actuels. Par ailleurs, je ne sais pas très bien à quoi vous faites allusion lorsque vous dites que « le monde virtuel offre des possibilités d’interaction et de réussite quasi illimitées ». Les possibilités d’interactions offertes par le médium numérique sont certes plus diverses que celles qui étaient fournies par l’imprimerie ou la télévision, mais elles ne sont en aucun cas « illimitées » puisque le temps disponible n’est pas extensible à l’infini. Ces possibilités dépendent aussi fortement des capacités et de l’environnement culturel et social des utilisateurs. La toute puissance est toujours une illusion. Par ailleurs, si vous voulez dire que la fiction et le jeu (qu’ils soient ou non à support électronique) offrent des possibilités illimitées, oui, c’est une idée qui a sa part de vérité. Maintenant, si vous sous-entendez qu’il est malsain de passer la plus grande partie de son temps à jouer à des jeux vidéo en ligne au détriment de sa santé, de ses études, de son environnement familial ou de son travail, on ne peut qu’être d’accord avec vous. Mais ce sont ici l’excès et l’addiction qui sont en question, avec leurs causes multiples, et pas « le monde virtuel ».
Q-10 Avec les progrès des technologies numériques, le concept d’immortalité numérique émerge, où nos identités peuvent être préservées indéfiniment en ligne. Comment comprenez-vous la relation entre la spiritualité et cette idée d’immortalité numérique?
R-10 Cette fausse immortalité n’a rien à voir avec la spiritualité. Pourquoi ne pas parler d’immortalité calcaire – ou architecturale – face aux pyramides d’Égypte? Une autre comparaison : Shakespeare ou Victor Hugo, voire Newton ou Einstein, sont probablement plus « immortels » qu’une personne dont on n’a pas supprimé le compte Facebook après la mort. S’il faut absolument rapporter le numérique au sacré, je dirais que les centres de données sont les nouveaux temples et qu’en échange du sacrifice de nos données, nous obtenons les bénédictions pratiques des intelligences artificielles et des médias sociaux.
Q-11 De nombreux experts ont souligné les problèmes moraux présents dans l’organisation et la construction de normes basées sur les données rapportées et exploitées par l’IA (préjugés, racisme et autres formes de déterminisme). Comment contrôler ces problèmes dans le scénario numérique? Qui est responsable ou peut être tenu responsable de problèmes de cette nature? L’IA pourrait-elle avoir des implications juridiques?
R-11 On parle beaucoup des « biais » de tel ou tel modèle d’intelligence artificielle, comme s’il pouvait exister une IA non-biaisée ou neutre. Cette question est d’autant plus importante que l’IA devient notre nouvelle interface avec les objets symboliques : stylo universel, lunettes panoramiques, haut-parleur général, programmeur sans code, assistant personnel. Les grands modèles de langue généralistes produits par les plateformes dominantes s’apparentent désormais à une infrastructure publique, une nouvelle couche du méta-médium numérique. Ces modèles généralistes peuvent être spécialisés à peu de frais avec des jeux de données issues d’un domaine particulier et de méthodes d’ajustement. On peut aussi les munir de bases de connaissances dont les faits ont été vérifiés.
Les résultats fournis par une IA découlent de plusieurs facteurs qui contribuent tous à son orientation ou si l’on préfère, à ses « biais ».
a) Les algorithmes proprement dits sélectionnent les types de calcul statistique et les structures de réseaux neuronaux.
b) Les données d’entraînement favorisent les langues, les cultures, les options philosophiques, les partis-pris politiques et les préjugés de toutes sortes de ceux qui les ont produites.
c) Afin d’aligner les réponses de l’IA sur les finalités supposées des utilisateurs, on corrige (ou on accentue!) « à la main » les penchants des données par ce que l’on appelle le RLHF (Reinforcement Learning from Human Feed-back – en français : apprentissage par renforcement à partir d’un retour d’information humain).
d) Finalement, comme pour n’importe quel outil, l’utilisateur détermine les résultats au moyen de consignes en langue naturelle (les fameux prompts). Comme je l’ai dit plus haut, des communautés d’utilisateurs s’échangent et améliorent collaborativement de telles consignes. La puissance de ces systèmes n’a d’égal que leur complexité, leur hétérogénéité et leur opacité. Le contrôle règlementaire de l’IA, sans doute nécessaire, semble difficile.
La responsabilité est donc partagée entre de nombreux acteurs et processus, mais il me semble que ce sont les utilisateurs qui doivent être tenus pour les responsables principaux, comme pour n’importe quelle technique. Les questions éthiques et juridiques reliées à l’IA sont aujourd’hui passionnément discutées un peu partout. C’est un champ de recherche académique en pleine croissance et de nombreux gouvernements et organismes multinationaux ont émis des lois et règlement pour encadrer le développement et l’utilisation de l’IA.