
An IEML paradigm projected onto a sphere.
Communication presented at The Future of Text symposium IV at the Google’s headquarters in London (2014).
Symbolic manipulation accounts for the uniqueness of human cognition and consciousness. This symbolic manipulation is now augmented by algorithms. The problem is that we still have not invented a symbolic system that could fully exploit the algorithmic medium in the service of human development and human knowledge.

The slide above describes the successive steps in the augmentation of symbolic manipulation.
The first revolution is the invention of writing with symbols endowed with the ability of self-conservation. This leads to a remarquable augmentation of social memory and to the emergence of new forms of knowledge.
The second revolution optimizes the manipulation of symbols like the invention of the alphabet (phenician, hebrew, greek, roman, arab, cyrilic, korean, etc.), the chinese rational ideographies, the indian numeration system by position with a zero, paper and the early printing techniques of China and Korea.
The third revolution is the mecanization and the industrialization of the reproduction and diffusion of symbols, like the printing press, disks, movies, radio, TV, etc. This revolution supported the emergence of the modern world, with its nation states, industries and its experimental mathematized natural sciences.
We are now at the beginning of a fourth revolution where an ubiquitous and interconnected infosphere is filled with symbols – i.e. data – of all kinds (music, voice, images, texts, programs, etc.) that are being automatically transformed. With the democratization of big data analysis, the next generations will see the advent of a new scientific revolution… but this time it will be in the humanities and social sciences.

Let’s have a closer look to the algorithmic medium. Four layers have been added since the middle of the 20th century.
– The first layer is the invention of the automatic digital computer itself. We can describe computation as « processing on data ». It is self-evident that computation cannot be programmed if we don’t have a very precise addressing system for the data and for the specialized operators/processors that will transform the data. At the beginning these addressing systems were purely local and managed by operating systems.
– The second layer is the emergence of a universal addressing system for computers, the Internet protocol, that allowed for exchange of data and collaborative computing across the telecommunication network.
– The third layer is the invention of a data universal addressing and displaying system (http, html), welcoming a hypertextual global database: the World Wide Web. We all know that the Web has had a deep social, cultural and economic impact in the last fifteen years.
– The construction of this algorithmic medium is ongoing. We are now ready to add a fourth layer of addressing and, this time, we need a universal addressing system for metadata, and in particular for semantic metadata. Why? First, we are still unable to resolve the problem of semantic interoperability across languages, classifications and ontologies. And secondly, except for some approximative statistical and logical methods, we are still unable to compute semantic relations, including distances and differences. This new symbolic system will be a key element to a future scientific revolution in the humanities and social sciences leading to a new kind of reflexive collective intelligence for our species. There lies the future of text.

My version of a universal semantic addressing system is IEML, an artificial language that I have invented and developped over the last 20 years.
IEML is based on a simple algebra with six primitive variables (E, U, A, S, B, T) and two operations (+, ×). The multiplicative operation builds the semantic links. This operation has three roles: a depature node, an arrival node and a tag for the link. The additive operation gathers several links to build a semantic network and recursivity builds semantic networks with multiple levels of complexity: it is « fractal ». With this algebra, we can automatically compute an internal network corresponding to any variable and also the relationships between any set of variables.
IEML is still at the stage of fundamental research but we now have an extensive dictionary – a set of paradigms – of three thousand terms and grammatical algorithmic rules that conform to the algebra. The result is a language where texts self-translate into natural language, manifest as semantic networks and compute collaboratively their relationships and differences. Any library of IEML texts then self-organizes into ecosystems of texts and data categorized in IEML will self-organize according to their semantic relationships and differences.
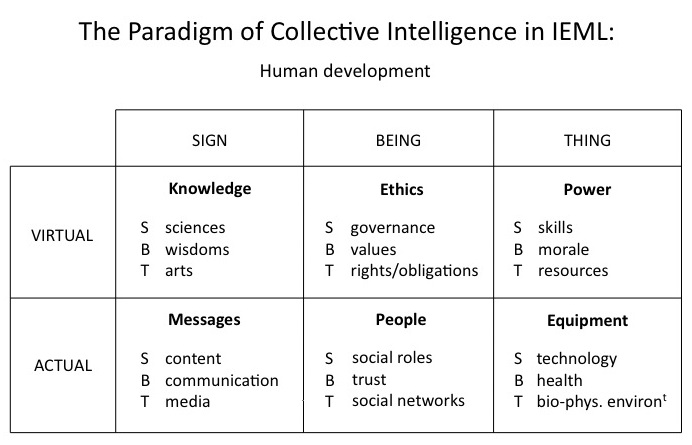
Now let’s take an example of an IEML paradigm, the paradigm of “Collective Intelligence in the service of human development” for instance, where we will grasp the meaning of the primitives and in which way they are being used.
-First, let’s look at the dialectic between virtual (U) and actual (A) human development represented by the rows.
-Then, the ternary dialectic between sign (S), being (B) and thing (T) are represented by the columns.
-The result is six broad interdependent aspects of collective intelligence corresponding to the intersections of the rows (virtual/actual) and columns (sign/being/thing).
– Each of these six broad aspects of CI are then decomposed into three sub-aspects corresponding to the sign/being/thing dialectic.
The semantic relations (symmetries and inclusions) between the terms of a paradigm are all explicit and therefore computable. All IEML paradigms are designed with the same principles as this one, and you can build phrases by assembling the terms through multiplications and additions.
Fortunatly, fundamental research is now finished. I will spend the next months preparing a demo of the automatic computing of semantic relations between data coded in IEML. With tools to come…


“Fundamental research is now finished” : now that Drupal 8 is around the corner (with a module already offering connection to a graph database – Neo4J), it’s finally starting to sound like a good time for a side-project !
Quick question though : as I was looking at ways to implement IEML primitives as “Taxonomies” (Drupal core entities) and IEML operations as “Relations” (Drupal contrib. module entities), would you already be able to point in any direction regarding how data should be coded in IEML (say, for agents crawling web pages), such as perhaps JSON-LD ?
LikeLike
meanwhile it’s D+1 since D0 of the brand new whitepaper of IEML, I’m still wondering why this ambiguation between “whitepaper” and / or “manifesto”… and thus, could IEML be able to translate those two terms and calculate semantically what is worth the best for collective intelligence…?
if, this is a project for the society, creating a lingua in mind of calling the humaninities to make community, then that would be a manifesto. but if we live in a complex world, meaning raising for rising, then whitepaper is fine… but… shhhhhhh…
what I’m still really really really curious about while in search of visual representations, is how did you projected an IEML paradigm onto a sphere…? can it be developped? would it be some kind of visualisation that could matter to expand the adoption of IEML’s lang(U)(s)age…?
I’ll have 7 more days left to meditate about it.
LikeLike