Abstract
IEML is an artificial language that allows the automatic computing of (a) the semantic relationships internal to its texts and of (b) the semantic relationships between its texts. Such an innovation could have a positive impact on the development of human collective intelligence. While we are currently limited to logical and statistical analytics, semantic coding could allow large scale computing on the meaning of data, provided that these data are categorized in IEML. Moreover “big data” algorithms are currently monopolized by big companies and big governemnts. But according to the perspective adopted here, the algorithmic tools of the future will put data-anaytics, machine learning and reflexive collective intelligence in the hands of the majority of Internet users.
I will first describe the main components of an algorithm (code, operators, containers, instructions), then I will show that the growth of the algorithmic medium has been shaped by innovations in coding and containers addressing. The current limitations of the web (absence of semantic interoperability and statistical positivism) could be overcomed by the invention of a new coding system aimed at making the meaning computable. Finally I will describe the cognitive gains that can be secured from this innovation.
This paper has been published by Spanda Journal special issue on “Creativity & Collective Enlightenment”, VI, 2, December 2015, p. 59-66
Our communications—transmission and reception of data—are based on an increasingly complex infrastructure for the automatic manipulation of symbols, which I call the algorithmic medium because it automates the transformation of data, and not only their conservation, reproduction and dissemination (as with previous media). Both our data-centric society and the algorithmic medium that provides its tools are still at their tentative beginnings. Although it is still hard to imagine today, a huge space will open up for the transformation and analysis of the deluge of data we produce daily. But our minds are still fascinated by the Internet’s power of dissemination of messages, which has almost reached its maximum.
In the vanguard of the new algorithmic episteme, IEML (or any other system that has the same properties) will democratize the categorization and automatic analysis of the ocean of data. The use of IEML to categorize data will create a techno-social environment that is even more favourable for collaborative learning and the distributed production of knowledge. In so doing, it will contribute to the emergence of the algorithmic medium of the future and reflect collective intelligence in the form of ecosystems of ideas.
This text begins by analyzing the structure and functioning of algorithms and shows that the major stages in the evolution of the new medium correspond to the appearance of new systems for encoding and addressing data: the Internet is a universal addressing system for computers and the Web, a universal addressing system for data. However, the Web, in 2016, has many limitations. Levels of digital literacy are still low. Interoperability and semantic transparency are sorely lacking. The majority of its users see the Web only as a big multimedia library or a means of communication, and pay no attention to its capacities for data transformation and analysis. As for those concerned with the processing of big data, they are hindered by statistical positivism. In providing a universal addressing system for concepts, IEML takes a decisive step toward the algorithmic medium of the future. The ecosystems of ideas based on this metalanguage will give rise to cognitive augmentations that are even more powerful than those we already enjoy.
What is an algorithm?
To help understand the nature of the new medium and its evolution, let us represent as clearly as possible what an algorithm is and how it functions. In simplified explanations of programming, the algorithm is often reduced to a series of instructions or a “recipe.” But no series of instructions can play its role without the three following elements: first, an adequate encoding of the data; second, a well-defined set of reified operators or functions that act as black boxes; third, a system of precisely addressed containers capable of recording initial data, intermediate results and the end result. The rules—or instructions—have no meaning except in relation to the code, the operators and the memory addresses.
I will now detail these aspects of the algorithm and use that analysis to periodize the evolution of the algorithmic medium. We will see that the major stages in the growth of this medium are precisely related to the appearance of new systems of addressing and encoding, both for the containers of data and for the operators. Based on IEML, the coming stage of development of the algorithmic medium will provide simultaneously a new type of encoding (semantic encoding) and a new system of virtual containers (semantic addressing).
Encoding of data
For automatic processing, data must first be encoded appropriately and uniformly. This involves not only binary encoding (zero and one), but more specialized types of encoding such as encoding of numbers (in base two, eight, ten, sixteen, etc.), that of characters used in writing, that of images (pixels), that of sounds (sampling), and so on.
Operators
We must then imagine a set of tools or specialized micro-machines for carrying out certain tasks on the data. Let us call these specialized tools “operators.” The operators are precisely identified, and they act in a determined or mechanical way, always the same way. There obviously has to be a correspondence or a match between the encoding of the data and the functioning of the operators.
The operators were first identified insider computers: they are the elementary electronic circuits that make up processors. But we can consider any processor of data—however complex it is—as a “black box” serving as a macro-operator. Thus the protocol of the Internet, in addressing the computers in the network, at the same time set up a universal addressing system for operators.
Containers
In addition to a code for the data and a set of operators, we have to imagine a storehouse of data whose basic boxes or “containers” are completely addressed: a logical system of recording with a smooth surface for writing, erasing and reading. It is clear that the encoding of data, the operations applied to them and the mode of recording them—and therefore their addressing—must be harmonized to optimize processing.
The first addressing system of the containers is internal to computers, and it is therefore managed by the various operating systems (for example, UNIX, Windows, Apple OS, etc.). But at the beginning of the 1990s, a universal addressing system for containers was established above that layer of internal addressing: the URLs of the World Wide Web.
Instructions
The fourth and last aspect of an algorithm is an ordered set of rules—or a control mechanism—that organizes the recursive circulation of data between the containers and the operators. The circulation is initiated by a data flow that goes from containers to the appropriate operators and then directs the results of the operations to precisely addressed containers. A set of tests (if . . . , then . . .) determines the choice of containers from which the data to be processed are drawn, the choice of operators and the choice of containers in which the results are recorded. The circulation of data ends when a test has determined that processing is complete. At that point, the result of the processing—a set of encoded data—is located at a precise address in the system of containers.
The growth of the new medium
To shape the future development of the algorithmic medium, we have to first look at its historical evolution.
Automatic calculation (1940-1970)
From when can we date the advent of the algorithmic medium? We might be tempted to give its date of birth as 1937, since it was in that year that Alan Turing (1912-1954) published his famous article introducing the concept of the universal machine, that is, the formal structure of a computer. The article represents calculable functions as programs of the universal machine, that is, essentially, algorithms. We could also choose 1945, because in June of that year, John von Neumann (1903-1957) published his “First draft of a report on the EDVAC,” in which he presented the basic architecture of computers: 1) a memory containing data and programs (the latter encoding algorithms), 2) an arithmetic, logical calculation unit and 3) a control unit capable of interpreting the instructions of the programs contained in the memory. Since the seminal texts of Alan Turing and John von Neumann represent only theoretical advances, we could date the new era from the construction and actual use of the first computers, in the 1950s. It is clear, however, that (in spite of the prescience of a few visionaries ) until the end of the 1970s, it was still hard to talk about an algorithmic medium. One of the main reasons is that the computers at that time were still big, costly, closed machines whose input and output interfaces could only be manipulated by experts. Although already in its infancy, the algorithmic medium was not yet socially prevalent.
It should be noted that between 1950 and 1980 (before Internet connections became the norm), data flows circulated mainly between containers and operators with local addresses enclosed in a single machine.
The Internet and personal computers (1970-1995)
A new trend emerged in the 1970s and became dominant in the 1980s: the interconnection of computers. The Internet protocol (invented in 1969) won out over its competitors in addressing machines in telecommunication networks. This was also the period when computing became personal. The digital was now seen as a vector of transformation and communication of all symbols, not only numbers. The activities of mail, telecommunications, publishing, the press, and radio and television broadcasting began to converge.
At the stage of the Internet and personal computers, data processed by algorithms were always stored in containers with local addresses, but—in addition to those addresses—operators now had universal physical addresses in the global network. Consequently, algorithmic operators could “collaborate,” and the range of types of processing and applications expanded significantly.
The World Wide Web (1995-2020)
It was only with the arrival of the Web, around 1995, however, that the Internet became the medium of most communication—to the point of irreversibly affecting the functioning of the traditional media and most economic, political and cultural institutions.
The revolution of the Web can be explained essentially as the creation of a universal system of physical addresses for containers. This system, of course, is URLs. It should be noted that—like the Internet protocol for operators—this universal system is added to the local addresses of the containers of data, it does not eliminate them. Tim Berners-Lee’s ingenious idea may be described as follows: by inventing a universal addressing system for data, he made possible the shift from a multitude of actual databases (each controlled by one computer) to a single virtual database for all computers. One of the main benefits is the possibility of creating hyperlinks among any of the data of that universal virtual database: “the Web.”
From then on, the effective power and the capacity for collaboration—or inter-operation—between algorithms increased and diversified enormously, since both operators and containers now possessed universal addresses. The basic programmable machine became the network itself, as is shown by the spread of cloud computing.
The decade 2010-2020 is seeing the beginning of the transition to a data-centric society. Indeed, starting with this phase of social utilization of the new medium, the majority of interactions among people take place through the Internet, whether purely for socialization or for information, work, research, learning, consumption, political action, gaming, watches, and so on. At the same time, algorithms increasingly serve as the interface for relationships between people, relationships among data, and relationships between people and data. The increase in conflicts around ownership and free accessibility of data, and around openness and transparency of algorithms, are clear signs of a transition to a data-centric society. However, in spite of their already decisive role, algorithms are not yet perceived in the collective consciousness as the new medium of human communication and thought. People were still fascinated by the logic of dissemination of previous media.
The next stage in the evolution of the algorithmic medium—the semantic sphere based on IEML—will provide a conceptual addressing system for data. But before we look at the future, we need to think about the limitations of the contemporary Web. Indeed, the Web was invented to help solve problems in interconnecting data that arose around 1990, at a time when one percent of the world’s population (mainly anglophone) was connected. But now in 2014, new problems have arisen involving the difficulties of translating and processing data, as well as the low level of digital literacy. When these problems become too pronounced (probably around 2020, when more than half the world’s population will be connected), we will be obliged to adopt a conceptual addressing system on top of the layer of physical addressing of the WWW.
The limitations of the Web in 2016
The inadequacy of the logic of dissemination
From Gutenberg until the middle of the twentieth century, the main technical effect of the media was the mechanical recording, reproduction and transmission of the symbols of human communication. Examples include printing (newspapers, magazines, books), the recording industry, movies, telephone, radio and television. While there were also technologies for calculation, or automatic transformation of symbols, the automatic calculators available before computers were not very powerful and their usefulness was limited.
The first computers had little impact on social communication because of their cost, the complexity of using them and the small number of owners (essentially big corporations, some scientific laboratories and the government administrations of rich countries). It was only beginning in the 1980s that the development of personal computing provided a growing proportion of the population with powerful tools for producing messages, whether these were texts, tables of numbers, images or music. From then on, the democratization of printers and the development of communication networks among computers, as well as the increased number of radio and television networks, gradually undermined the monopoly on the massive dissemination of messages that had traditionally belonged to publishers, professional journalists and the major television networks. This revolution in dissemination accelerated with the arrival of the World Wide Web in the mid-1990s and blossomed into the new kind of global multimedia public sphere that prevails now at the beginning of the twenty-first century.
In terms of the structure of social communication, the essential characteristic of the new public sphere is that it permits anyone to produce messages, to transmit to a community without borders and to access messages produced and transmitted by others. This freedom of communication is all the more effective since its exercise is practically free and does not require any prior technical knowledge. In spite of the limits I will describe below, we have to welcome the new horizon of communication that is now offered to us: at the rate at which the number of connections is growing, almost all human beings in the next generation will be able to disseminate their messages to the entire planet for free and effortlessly.
It is certain that automatic manipulation—or transformation—of symbols has been practiced since the 1960s and 1970s. I have also already noted that a large proportion of personal computing was used to produce information and not only to disseminate it. Finally, the major corporations of the Web such as Google, Amazon, eBay, Apple, Facebook, Twitter and Netflix daily process huge masses of data in veritable “information factories” that are entirely automated. In spite of that, the majority of people still see and use the Internet as a tool for the dissemination and reception of information, in continuity with the mass media since printing and, later, television. It is a little as if the Web gave every individual the power of a publishing house, a television network and a multimedia postal service in real time, as well as access to an omnipresent global multimedia library. Just as the first printed books—incunabula—closely copied the form of manuscripts, we still use the Internet to achieve or maximize the power of dissemination of previous media. Everyone can transmit universally. Everyone can receive from anywhere.
No doubt we will have to exhaust the technical possibilities of automatic dissemination—the power of the media of the last four centuries—in order to experience and begin to assimilate intellectually and culturally the almost unexploited potential of automatic transformation—the power of the media of centuries to come. That is why I am again speaking of the algorithmic medium: to emphasize digital communication’s capacity for automatic transformation. Of course, the transformation or processing power of the new medium can only be actualized on the basis of the irreversible achievement of the previous medium, the universal dissemination or ubiquity of information. That was nearly fully achieved at the beginning of the twenty-first century, and coming generations will gradually adapt to automatic processing of the massive flow of global data, with all its unpredictable cultural consequences. There are at this time three limits to this process of adaptation: users’ literacy, the absence of semantic interoperability and the statistical positivism that today governs data analysis.
The problem of digital literacy
The first limit of the contemporary algorithmic medium is related to the skills of social groups and individuals: the higher their education level (elementary, secondary, university), the better developed their critical thinking, the greater their mastery of the new tools for manipulation of symbols and the more capable they are of turning the algorithmic medium to their advantage. As access points and mobile devices increase in number, the thorny question of the digital divide is less and less related to the availability of hardware and increasingly concerns problems of print literacy, media literacy and education. Without any particular skills in programming or even in using digital tools, the power provided by ordinary reading and writing is greatly increased by the algorithmic medium: we gain access to possibilities for expression, social relationships and information such as we could not even have dreamed of in the nineteenth century. This power will be further increased when, in the schools of the future, traditional literacy, digital literacy and understanding of ecosystems of ideas are integrated. Then, starting at a very young age, children will be introduced to categorization and evaluation of data, collection and analysis of large masses information and programming of semantic circuits.
The absence of semantic interoperability
The second limit is semantic, since, while technical connection is tending to become universal, the communication of meaning still remains fragmented according to the boundaries of languages, systems of classification, disciplines and other cultural worlds that are more or less unconnected. The “semantic Web” promoted by Tim Berners-Lee since the late 1990s is very useful for translating logical relationships among data. But it has not fulfilled its promise with regard to the interoperability of meaning, in spite of the authority of its promoter and the contributions of many teams of engineers. As I showed in the first volume of The Semantic Sphere, it is impossible to fully process semantic problems while remaining within the narrow limits of logic. Moreover, the essentially statistical methods used by Google and the numerous systems of automatic translation available provide tools to assist with translation, but they have not succeeded any better than the “semantic Web” in opening up a true space of translinguistic communication. Statistics are no more effective than logic in automating the processing of meaning. Here again, we lack a coding of linguistic meaning that would make it truly calculable in all its complexity. It is to meet this need that IEML is automatically translated into natural languages in semantic networks.
Statistical positivism
The general public’s access to the power of dissemination of the Web and the flows of digital data that now result from all human activities confront us with the following problem: how to transform the torrents of data into rivers of knowledge? The solution to this problem will determine the next stage in the evolution of the algorithmic medium. Certain enthusiastic observers of the statistical processing of big data, such as Chris Anderson, the former editor-in-chief of Wired, were quick to declare that scientific theories—in general!—were now obsolete. In this view, we now need only flows of data and powerful statistical algorithms operating in the computing centres of the cloud: theories—and therefore the hypotheses they propose and the reflections from which they emerge—belong to a bygone stage of the scientific method. It appears that numbers speak for themselves. But this obviously involves forgetting that it is necessary, before any calculation, to determine the relevant data, to know exactly what is being counted and to name—that is, to categorize—the emerging patterns. In addition, no statistical correlation directly provides causal relationships. These are necessarily hypotheses to explain the correlations revealed by statistical calculations. Under the guise of revolutionary thought, Chris Anderson and his like are reviving the old positivist, empiricist epistemology that was fashionable in the nineteenth century, according to which only inductive reasoning (that is, reasoning based solely on data) is scientific. This position amounts to repressing or ignoring the theories—and therefore the risky hypotheses based on individual thought—that are necessarily at work in any process of data analysis and that are expressed in decisions of selection, identification and categorization. One cannot undertake statistical processing and interpret its results without any theory. Once again, the only choice we have is to leave the theories implicit or to explicate them. Explicating a theory allows us to put it in perspective, compare it with other theories, share it, generalize from it, criticize it and improve it. This is even one of the main components of what is known as critical thinking, which secondary and university education is supposed to develop in students.
Beyond empirical observation, scientific knowledge has always been concerned with the categorization and correct description of phenomenal data, description that is necessarily consistent with more or less formalized theories. By describing functional relationships between variables, theory offers a conceptual grasp of the phenomenal world that make it possible (at least partially) to predict and control it. The data of today correspond to what the epistemology of past centuries called phenomena. To extend this metaphor, the algorithms for analyzing flows of data of today correspond to the observation tools of traditional science. These algorithms show us patterns, that is, ultimately, images. But the fact that we are capable of using the power of the algorithmic medium to observe data does not mean we should stop here on this promising path. We now need to use the calculating power of the Internet to theorize (categorize, model, explain, share, discuss) our observations, without forgetting to make our theorizing available to the rich collective intelligence.
In their 2013 book on big data, Viktor Mayer-Schonberger and Kenneth Cukier, while emphasizing the distinction between correlation and causality, predicted that we would take more and more interest in correlations and less and less in causality, which put them firmly in the empiricist camp. Their book nevertheless provides an excellent argument against statistical positivism. Indeed, they recount the very beautiful story of Matthew Maury, an American naval officer who in the mid-nineteenth century compiled data from log books in the official archives to establish reliable maps of winds and currents. Those maps were constructed from an accumulation of empirical data. But with all due respect for Cukier and Mayer-Schonberger, I would point out that such an accumulation would never have been useful, or even feasible, without the system of geographic coordinates of meridians and parallels, which is anything but empirical and based on data. Similarly, it is only by adopting a system of semantic coordinates such as IEML that we will be able to organize and share data flows in a useful way.
Today, most of the algorithms that manage routing of recommendations and searching of data are opaque, since they are protected trade secrets of major corporations of the Web. As for the analytic algorithms, they are, for the most part, not only opaque but also beyond the reach of most Internet users for both technical and economic reasons. However, it is impossible to produce reliable knowledge using secret methods. We must obviously consider the contemporary state of the algorithmic medium to be transitory.
What is more, if we want to solve the problem of the extraction of useful information from the deluge of big data, we will not be able to eternally limit ourselves to statistical algorithms working on the type of organization of digital memory that exists in 2016. We will sooner or later, and the sooner the better, have to implement an organization of memory designed from the start for semantic processing. We will only be able to adapt culturally to the exponential growth of data—and therefore transform these data into reflected knowledge—through a qualitative change of the algorithmic medium, including the adoption of a system of semantic coordinates such as IEML.
The semantic sphere and its conceptual addressing (2020…)
It is notoriously difficult to observe or recognize what does not yet exist, and even more, the absence of what does not yet exist. However, what is blocking the development of the algorithmic medium—and with it, the advent of a new civilization—is precisely the absence of a universal, calculable system of semantic metadata. I would like to point out that the IEML metalanguage is the first, and to my knowledge (in 2016) the only, candidate for this new role of a system of semantic coordinates for data.
We already have a universal physical addressing system for data (the Web) and a universal physical addressing system for operators (the Internet). In its full deployment phase, the algorithmic medium will also include a universal semantic code: IEML. This system of metadata—conceived from the outset to optimize the calculability of meaning while multiplying its differentiation infinitely—will open the algorithmic medium to semantic interoperability and lead to new types of symbolic manipulation. Just as the Web made it possible to go from a great many actual databases to one universal virtual database (but based on a physical addressing system), IEML will make it possible to go from a universal physical addressing system to a universal conceptual addressing system. The semantic sphere continues the process of virtualization of containers to its final conclusion, because its semantic circuits—which are generated by an algebra—act as data containers. It will be possible to use the same conceptual addressing system in operations as varied as communication, translation, exploration, searching and three-dimensional display of semantic relationships.
Today’s data correspond to the phenomena of traditional science, and we need calculable, interoperable metadata that correspond to scientific theories and models. IEML is precisely an algorithmic tool for theorization and categorization capable of exploiting the calculating power of the cloud and providing an indispensable complement to the statistical tools for observing patterns. The situation of data analysis before and after IEML can be compared to that of cartography before and after the adoption of a universal system of geometric coordinates. The data that will be categorized in IEML will be able to be processed much more efficiently than today, because the categories and the semantic relationships between categories will then become not only calculable but automatically translatable from one language to another. In addition, IEML will permit comparison of the results of the analysis of the same set of data according to different categorization rules (theories!).

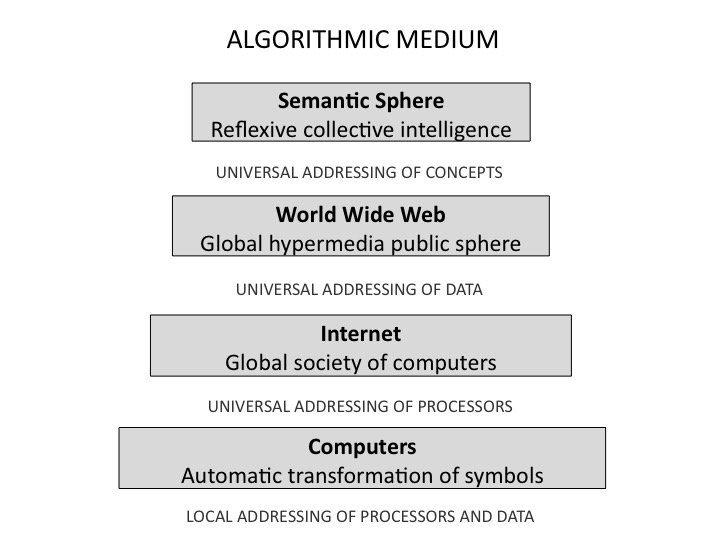
FIGURE 1 – The four interdependent levels of the algorithmic medium
When this symbolic system for conceptual analysis and synthesis is democratically accessible to everyone, translated automatically into all languages and easily manipulated by means of a simple tablet, then it will be possible to navigate the ocean of data, and the algorithmic medium will be tested directly as a tool for cognitive augmentation—personal and social—and not only for dissemination. Then a positive feedback loop between the collective testing and creation of tools will lead to a take-off of the algorithmic intelligence of the future.
In Figure 1, the increasingly powerful levels of automatic calculation are represented by rectangles. Each level is based on the “lower” levels that precede it in order of historical emergence. Each level is therefore influenced by the lower levels. But, conversely, each new level gives the lower levels an additional socio-technical determination, since it uses them for a new purpose.
The addressing systems, which are represented under the rectangles, can be considered the successive solutions—influenced by different socio-technical contexts—to the perennial problem of increasing the power of automatic calculation. An addressing system thus plays the role of a step on a stairway that lets you go from one level of calculation to a higher level. The last addressing system, that of metadata, is supplied by IEML or any other system of encoding of linguistic meaning that makes that meaning calculable, exactly as the system of pixels made images manipulable by means of algorithms.
The cognitive revolution of semantic encoding
We know that the algorithmic medium is not only a medium of communication or dissemination of information but also, especially, a ubiquitous environment for the automatic transformation of symbols. We also know that a society’s capacities for analysis, synthesis and prediction are based ultimately on the structure of its memory, and in particular its system for encoding and organizing data. As we saw in the previous section, the only thing the algorithmic medium now in construction lacks to become the matrix of a new episteme that is more powerful than today’s, which has not yet broken its ties to the typographical era, is a system of semantic metadata that is equal to the calculating power of algorithms.
Memory, communication and intuition
It is now accepted that computers increase our memory capacities, in which I include not only capacities for recording and recall, but also those for analysis, synthesis and prediction. The algorithmic medium also increases our capacities for communication, in particular in terms of the breadth of the network of contacts and the reception, transmission and volume of flows of messages. Finally, the new medium increases our capacities for intuition, because it increases our sensory-motor interactions (especially gestural, tactile, visual and sound interactions) with large numbers of people, documents and environments, whether they are real, distant, simulated, fictional or mixed. These augmentations of memory, communication and intuition influence each other to produce an overall augmentation of our field of cognitive activity.
Semantic encoding, that is, the system of semantic metadata based on IEML, will greatly increase the field of augmented cognitive activity that I have described. It will produce a second level of cognitive complexity that will enter into dynamic relationship with the one described above to give rise to algorithmic intelligence. As we will see, semantic coding will generate a reflexivity of memory, a new perspectivism of intellectual intuition and an interoperability of communication.
Reflexive memory
The technical process of objectivation and augmentation of human memory began with the invention of writing and continued up to the development of the Web. But in speaking of reflexive memory, I go beyond Google and Wikipedia. In the future, the structure and evolution of our memory and the way we use it will become transparent and open to comparison and critical analysis. Indeed, communities will be able to observe—in the form of ecosystems of ideas—the evolution and current state of their cognitive activities and apply their capacities for analysis, synthesis and prediction to the social management of their knowledge and learning. At the same time, individuals will become capable of managing their personal knowledge and learning in relation to the various communities to which they belong. So much so that this reflexive memory will enable a new dialectic—a virtuous circle—of personal and collective knowledge management. The representation of memory in the form of ecosystems of ideas will allow individuals to make maximum use of the personal growth and cross-pollination brought about by their circulation among communities.
Perspectivist intellectual intuition
Semantic coding will give us a new sensory-motor intuition of the perspectivist nature of the information universe. Here we have to distinguish between the conceptual perspective and the contextual perspective.
The conceptual perspective organizes the relationships among terms, sentences and texts in IEML so that each of these semantic units can be processed as a point of view, or a virtual “centre” of the ecosystems of ideas, organizing the other units around it according to the types of relationships it has with them and their distance from it.
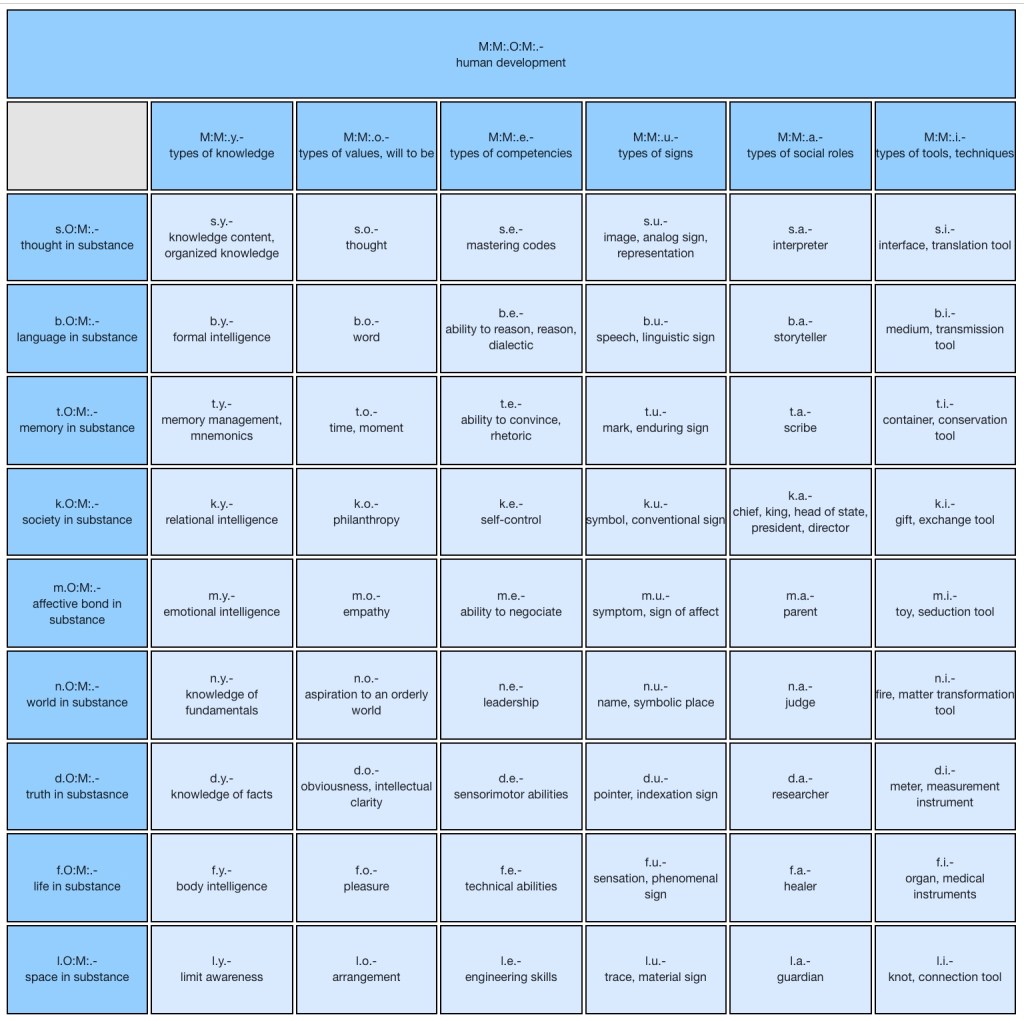
In IEML, the elementary units of meaning are terms, which are organized in the IEML dictionary (optimized for laptops + Chrome) in paradigms, that is, in systems of semantic relationships among terms. In the IEML dictionary, each term organizes the other terms of the same paradigm around it according to its semantic relationships with them. The different paradigms of the IEML dictionary are in principle independent of each other and none has precedence over the others a priori. Each of them can, in principle, be used to filter or categorize any set of data.
The sentences, texts and hypertexts in IEML represent paths between the terms of various paradigms, and these paths in turn organize the other paths around them according to their relationships and semantic proximity in the ecosystems of ideas. It will be possible to display this cascade of semantic perspectives and points of view using three-dimensional holograms in an immersive interactive mode.
Let us now examine the contextual perspective, which places in symmetry not the concepts within an ecosystem of ideas, but the ecosystems of ideas themselves, that is, the way in which various communities at different times categorize and evaluate data. It will thus be possible to display and explore the same set of data interactively according to the meaning and value it has for a large number of communities.
Reflexive memory, perspectivist intuition, interoperable and transparent communication together produce a cognitive augmentation characteristic of algorithmic intelligence, an augmentation more powerful than that of today.
Interoperable and transparent communication
The interoperability of communication will first concern the semantic compatibility of various theories, disciplines, universes of practices and cultures that will be able to be translated into IEML and will thus become not only comparable but also capable of exchanging concepts and operating rules without loss of their uniqueness. Semantic interoperability will also cover the automatic translation of IEML concepts into natural languages. Thanks to this pivot language, any semantic network in any natural language will be translated automatically into any other natural language. As a result, through the IEML code, people will be able to transmit and receive messages and categorize data in their own languages while communicating with people who use other languages. Here again, we need to think about cultural interoperability (communication in spite of differences in conceptual organization) and linguistic interoperability (communication in spite of differences in language) together; they will reinforce each other as a result of semantic coding.