IEML (Information Economy MetaLanguage) is an open (GPL3) and free artificial metalanguage that is simultaneously a programming language, a pivot between natural languages and a semantic coordinate system. When data are categorized in IEML, the metalanguage compute their semantic relationships and distances.
From a “social” point of view, on line communities categorizing data in IEML generate explorable ecosystems of ideas that represent their collective intelligence.
humanities and social sciences, digital humanities
What motivates people to adopt IEML?
IEML users participate in the leading edge of digital innovation, big data analytics and collective intelligence.
IEML can enhance other AI techniques like machine learning, deep learning, natural language processing and rule-based inference.
IEML tools
IEML v.0
IEML v.0 includes…
A dictionary of concepts whose edition is restricted to specialists but navigation and use is open to all.
A library of tags – called USLs (Uniform Semantic Locators) – whose edition, navigation and use is open to all.
An API allowing access to the dictionary, the library and their functionalities (semantic computing).
Intlekt v.0
Intlekt v.0 is a collaborative data curation tool that allows
– the categorization of data in IEML,
– the semantic visualization of collections of data categorized in IEML
– the publication of these collections
The prototype (to be issued in May 2018) will be mono-user but the full blown app will be social.
Who made it?
The IEML project is designed and led by Pierre Lévy.
It has been financed by the Canada Research Chair in Collective Intelligence at the University of Ottawa (2002-2016).
At an early stage (2004-2011) Steve Newcomb and Michel Biezunski have contributed to the design and implementation (parser, dictionary). Christian Desjardins implemented a second version of the dictionary. Andrew Roczniak helped for the first mathematical formalization, implemented a second version of the parser and a third version of the dictionary (2004-2016).
The 2016 version has been implemented by Louis van Beurden, Hadrien Titeux (chief engineers), Candide Kemmler (project management, interface), Zakaria Soliman and Alice Ribaucourt.
The 2017 version (1.0) has been implemented by Louis van Beurden (chief engineer), Eric Waldman (IEML edition interface, visualization), Sylvain Aube (Drupal), Ludovic Carré and Vincent Lefoulon (collections and tags management).
J’ai montré dans un post précédent, l’importance contemporaine de la curation collaborative de données. Les compétences dans ce domaine sont au coeur de la nouvelle litéracie algorithmique. La figure 1 présente ces compétences de manière systématique et, ce faisant, elle met en ordre les savoir-faire intellectuels et pratiques tout comme les « savoir-être » éthiques qui supportent l’augmentation de l’intelligence collective en ligne. L’étoile évoque le signe, le visage l’être et le cube la chose (sur ces concepts voir ce post). La table est organisée en trois rangées et trois colonnes interdépendantes. La première rangée explicite les fondements de l’intelligence algorithmique au niveau personnel, la seconde rappelle l’indispensable travail critique sur les sources de données et la troisième détaille les compétences nécessaires à l’émergence d’une intelligence collective augmentée par les algorithmes. L’intelligence personnelle et l’intelligence collective travaillent ensemble et ni l’une ni l’autre ne peuvent se passer d’intelligence critique ! Les colonnes évoquent trois dimensions complémentaires de la cognition : la conscience réflexive, la production de signification et la mémoire. Aucune d’elles ne doit être tenue pour acquise et toutes peuvent faire l’objet d’entraînement et de perfectionnement. Dans chaque case, l’item du haut pointe vers un exercice de virtualisation tandis que celui du bas indique une mise en oeuvre actuelle de la compétence, plus concrète et située. Je vais maintenant commenter le tableau de la figure 1 rangée par rangée.
L’intelligence personnelle
La notion d’intelligence personnelle doit ici s’entendre au sens d’une compétence cognitive individuelle. Mais elle tire également vers la signification du mot « intelligence » en anglais. Dans ce dernier sens, elle désigne la capacité d’un individu à mettre en place son propre système de renseignement.
La gestion de l’attention ne concerne pas seulement l’exercice de la concentration et l’art complémentaire d’éviter les distractions. Elle inclut aussi le choix réfléchi de priorités d’apprentissage et le discernement de sources d’information pertinentes. Le curateur lui-même doit décider de ce qui est pertinent et de ce qui ne l’est pas selon ses propres critères et en fonction des priorités qu’il s’est donné. Quant à la notion de source, est-il besoin de souligner ici que seuls les individus, les groupes et les institutions peuvent être ainsi qualifiés. Seuls donc ils méritent la confiance ou la méfiance. Quant aux médias sociaux, ce ne sont en aucun cas des sources (contrairement à ce que croient certains journalistes) mais plutôt des plateformes de communication. Prétendre, par exemple, que « Twitter n’est pas une source fiable », n’a pas plus de sens que l’idée selon laquelle « le téléphone n’est pas une source fiable ».
L’interpretation des données relève également de la responsabilité des curateurs. Avec tous les algorithmes statistiques et tous les outils d’analyse automatique de données (« big data analytics ») du monde, nous aurons encore besoin d’hypothèses causales, de théories et de systèmes de catégorisation pour soutenir ces théories. Les corrélations statistiques peuvent suggérer des hypothèses causales mais elles ne les remplacent pas. Car nous voulons non seulement prédire le comportement de phénomènes complexes, mais aussi les comprendre et agir sur la base de cette compréhension. Or l’action efficace suppose une saisie des causes réelles et non seulement la perception de corrélations. Sans les intuitions et les théories dérivées de notre connaissance personnelle d’un domaine, les outils d’analyse automatique de données ne seront pas utilisés à bon escient. Poser de bonnes questions aux données n’est pas une entreprise triviale !
Finalement, les données collectionnées doivent être gérées au plan matériel. Il nous faut donc choisir les bons outils d’entreposage dans les « nuages » et savoir manipuler ces outils. Mais la mémoire doit être aussi entretenue au niveau conceptuel. C’est pourquoi le bon curateur est capable de créer, d’adopter et surtout de maintenir un système de catégorisation qui lui permettra de retrouver l’information désirée et d’extraire de ses collections la connaissance qui lui sera utile.
L’intelligence critique
L’intelligence critique porte essentiellement sur la qualité des sources. Elle exige d’abord un travail de critique « externe ». Nous savons qu’il n’existe pas d’autorité transcendante dans le nouvel espace de communication. Si nous ne voulons pas être trompé, abusé, ou aveuglé par des oeillères informationnelles, il nous faut donc autant que possible diversifier nos sources. Notre fenêtre d’attention doit être maintenue bien ouverte, c’est pourquoi nous nous abonnerons à des sources adoptant divers points de vue, récits organisateurs et théories. Cette diversité nous permettra de croiser les données, d’observer les sujets sur lesquelles elles se contredisent et ceux sur lesquelles elles se confirment mutuellement.
L’évaluation des sources demande également un effort de décryptage des identités : c’est la critique « interne ». Pour comprendre la nature d’une source, nous devons reconnaître son système de classification, ses catégories maîtresses et son récit organisateur. En un sens, une source n’est autre que le récit autour duquel elle organise ses données : sa manière de produire du sens.
Finalement l’intelligence critique possède une dimension « pragmatique ». Cette critique est la plus dévastatrice parce qu’elle compare le récit de la source avec ce qu’elle fait réellement. Je vise ici ce qu’elle fait en diffusant ses messages, c’est-à-dire l’effet concret de ses actes de communication sur les conversations en cours et l’état d’esprit des participants. Je vise également les contributions intellectuelles et esthétiques de la source, ses interactions économiques, politiques, militaires ou autres telles qu’elles sont rapportées par d’autres sources. Grâce à cette bonne mémoire nous pouvons noter les contradictions de la source selon les moments et les publics, les décalages entre son récit officiel et les effets pratiques de ses actions. Enfin, plus une source se montre transparente au sujet de ses propres sources d’informations, de ses références, de son agenda et de son financement et plus elle est fiable. Inversement, l’opacité éveille les soupçons.
L’intelligence collective
Je rappelle que l’intelligence collective dont il est question ici n’est pas une « solution miracle » mais un savoir-faire à cultiver qui présuppose et renforce en retour les intelligences personnelles et critiques.
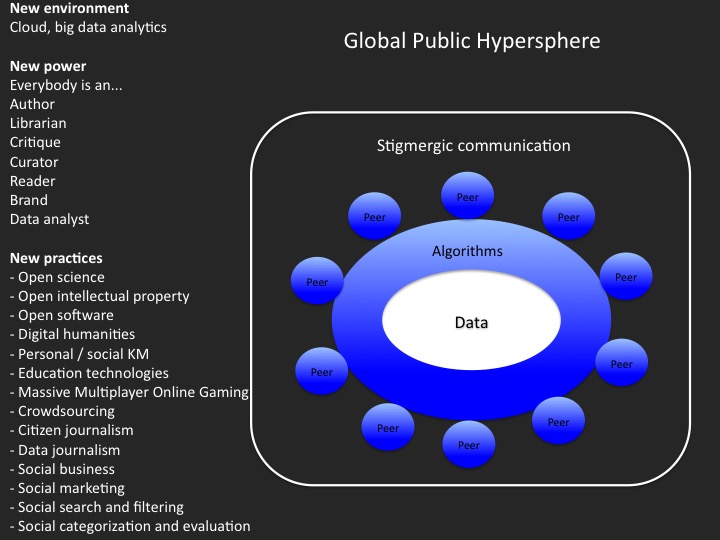
Commençons par définir la stigmergie : il s’agit d’un mode de communication dans lequel les agents se coordonnent et s’informent mutuellement en modifiant un environnement ou une mémoire commune. Dans le médium algorithmique, la communication tend à s’établir entre des pairs qui créent, catégorisent, critiquent, organisent, lisent, promeuvent et analysent des données au moyen d’outils algorithmiques. Il s’agit bien d’une communication stigmergique parce que, même si les personnes dialoguent et se parlent directement, le principal canal de communication reste une mémoire commune que les participants exploitent et transforment ensemble. Il est utile de distinguer entre les mémoires locale et globale. Dans la mémoire « locale » de réseaux ou de communautés particulières, nous devons prêter attention à des contextes et à des histoires singulières. Il est également recommandé de tenir compte des contributions des autres participants, de ne pas aborder des sujets non-pertinents pour le groupe, d’éviter les provocations, les explosions d’agressivité, les provocations, etc.
Quant à la mémoire « globale », il faut se souvenir que chaque action dans le médium algorithmique réorganise – même de façon infinitésimale – la mémoire commune : lire, taguer, acheter, poster, créer un hyperlien, souscrire, s’abonner, « aimer », etc. Nous créons notre environnement symbolique de manière collaborative. Le bon agent humain de l’intelligence collective gardera donc à la conscience que ses actions en ligne contribuent à l’information des autres agents.
La liberté dont il est question dans la figure 1 se présente comme une dialectique entre pouvoir et responsabilité. Le pouvoir recouvre notre capacité à créer, évaluer, organiser, lire et analyser les données, notre aptitude à faire évoluer la mémoire commune à partir de la multitude distribuée de nos actions. La responsabilité se fonde sur une conscience réfléchie de notre pouvoir collectif, conscience qui informe en retour l’orientation de notre attention et le sens que nous donnons à l’exercice de nos pouvoirs.
FIGURE 2
L’apprentissage collaboratif
Finalement, l’apprentissage collaboratif est un des processus cognitifs majeurs de l’intelligence collective et le principal bénéfice social des habiletés en curation de données. Afin de bien saisir ce processus, nous devons distinguer entre savoirs tacites et savoirs explicites. Les savoirs tacites recouvrent ce que les membres d’une communauté ont appris dans des contextes particuliers, les savoir-faire internalisés dans les réflexes personnels à partir de l’expérience. Les savoirs explicites, en revanche, sont des récits, des images, des données, des logiciels ou d’autres ressources documentaires, qui sont aussi clairs et décontextualisés que possible, afin de pouvoir être partagés largement.
L’apprentissage collaboratif enchaîne deux mouvements. Le premier consiste à traduire le savoir tacite en savoir explicite pour alimenter une mémoire commune. Dans un second mouvement, complémentaire du premier, les participants exploitent le savoir explicite et les ressources d’apprentissage disponibles dans la mémoire commune afin d’adapter ces connaissances à leur contexte particulier et de les intégrer dans leurs réflexes quotidiens. Les curateurs sont potentiellement des étudiants ou des apprenants lorsqu’ils internalisent un savoir explicite et ils peuvent se considérer comme des enseignants lorsqu’ils mettent des savoirs explicites à la disposition des autres. Ce sont donc des pairs (voir la figure 2) qui travaillent dans un champ de pratique commun. Ils transforment autant que possible leur savoir tacite en savoir explicite et travaillent en retour à traduire la partie des connaissances explicites qu’ils veulent acquérir en savoir pratique personnel. J’écris “autant que possible” parce que l’explicitation totale du savoir tacite est hors de portée, comme l’a bien montré Michael Polanyi.
Dans le médium algorithmique, le savoir explicite prend la forme de données catégorisées et évaluées. Le cycle de transformation des savoirs tacites en savoirs explicites et vice versa prend place dans les médias sociaux, où il est facilité par une conversation créative civilisée : les compétences intellectuelles et sociales (ou morales) fonctionnent ensemble !
Comme Monsieur Jourdain faisait de la prose sans le savoir, tout le monde fait aujourd’hui de la curation de données – on dit aussi de la curation de contenu – sans le savoir. Sur les grandes plateformes de médias sociaux comme Facebook, Twitter, Pinterest ou Instagram, mais aussi dans une multitude d’applications en ligne plus spécialisées comme Evernote, Scoop.it ou Diigo, les utilisateurs font référence à des données (textes, images, vidéos, musique…) qu’ils accompagnent de commentaires, de hashtags classificateurs et de diverses formes d’évaluations et d’émoticons. Ces posts s’accumulent dans des collections personnelles ou communautaires, apparaissent sur les fils d’autres utilisateurs et sont réexpédiées ad libitum avec d’éventuels changements de commentaires, de hashtags et d’appréciations émotionnelles. Les posts deviennent eux-mêmes des données qui peuvent à leur tour faire l’objet de références, de commentaires, de marquage affectif, de recherche et d’analyse. Les médias sociaux nous proposent des outils perfectionnés de gestion de base de données, avec des algorithmes de fouille, d’apprentissage machine, de reconnaissance de forme et de filtrage collaboratif qui nous aident à naviguer parmi la masse du contenu et les foules d’utilisateurs. Mais l’alimentation de la base tout comme la catégorisation et l’évaluation des données sont à notre charge.
Le mot curation, employé d’abord en anglais pour désigner l’activité d’un commissaire d’exposition dans l’univers des galeries d’art et des musées, a été récemment généralisé à toutes les activités de collection d’information. L’étymologie latine du mot évoque le soin médical (la cure) et plus généralement le souci. S’il est vrai que nous entrons dans une société datacentrique, le souci des données, l’activité qui consiste à collectionner et organiser des données pour soi et pour les autres devient cruciale. Et puisque la société datacentrique repose sur une effervescente économie de la connaissance, au sens le plus vaste et le plus « écologique » de la notion d’économie (voir à ce sujet La Sphère sémantique 1, Chp. 6.) l’enjeu ultime de la curation de données n’est autre que la production et le partage des connaissances.
Je vais maintenant évoquer un certain nombre de sphères d’activité dans lesquelles la maîtrise de la curation collaborative de données commence à s’imposer comme une compétence essentielle : la conservation des héritages, la recherche en sciences humaines, l’apprentissage collaboratif, la production et la diffusion des nouvelles, le renseignement à sources ouvertes et la gestion des connaissances.
La conservation des héritages
Les responsables des archives, bibliothèques, médiathèques et musées collectionnent depuis des siècles des artefacts porteurs d’information et les organisent de telle sorte que leur public puisse les retrouver et les consulter. C’est dans ce milieu professionnel qu’est d’abord apparue la distinction entre données et métadonnées. Du côté des données, les documents physiques sont posés sur des étagères. Du côté des métadonnées, un fichier permet de rechercher les documents par auteurs, titres, sujets, disciplines, dates, etc. Le bibliothécaire fabrique une fiche, voire plusieurs fiches, pour chaque document qui entre dans la bibliothèque et le lecteur fouille dans les fiches pour explorer le contenu de la bibliothèque et savoir où se trouvent placés les livres qu’il veut lire. Sans l’appareillage des métadonnées et les principes d’organisation qui les sous-tendent il serait impossible d’exploiter les informations contenues dans une bibliothèque. Depuis la fin du XXe siècle, le monde des archives, des bibliothèques et des musées connaît une grande transformation. La numérisation fait converger toutes les informations dans le médium algorithmique et cette unification met cruellement en évidence la disparité et l’incompatibilité des systèmes de classification en usage. De plus, les principaux systèmes de métadonnées ont été conçus et utilisés à l’époque de l’imprimerie, ils n’exploitent donc pas les nouvelles possibilités de calcul automatique. Finalement, les flots d’information ont tellement crû qu’ils échappent à toute possibilité de catalogage classique par un petit nombre de professionnels. Depuis quelques années, les musées et bibliothèques numérisent et mettent en ligne leurs collections en faisant appel au crowdsourcing, c’est-à-dire à l’intelligence collective des internautes, pour catégoriser les données. Cette curation collaborative de données brouille la distinction entre curateurs et utilisateurs tout en manifestant la diversité des points de vue et des intérêts du public. Par ailleurs, une multitude de sites puisant leurs données dans le Web ouvert, et souvent indépendants des institutions classiques de préservation des héritages culturels, permettent aux amateurs d’art ou aux bibliophiles de partager leurs goûts et leurs trouvailles, de se regrouper par sensibilité et par centres d’intérêts.
La recherche en sciences humaines
La numérisation des archives et des héritages culturels, l’accessibilité des données et statistiques compilées par les gouvernements et les institutions internationales, les communications et transactions des internautes recueillies par les grandes plateformes du Web, toutes ces nouvelles sources offrent aux sciences humaines une matière première dont l’abondance défie l’imagination. Par ailleurs les blogs de chercheurs, les plateformes collaboratives spécialisées dans la collection d’articles (comme Academia.edu, Researchgate, Mendeley, CiteULike…) et les bases de données partagées transforment profondément les pratiques de recherche. Enfin, une frange croissante des professionnels des sciences humaines s’initie à la programmation et à l’usage avancé des algorithmes, produisant et partageant le plus souvent des outils open source. L’édition scientifique traditionnelle est en crise puisque la communication entre chercheurs n’a plus besoin de journaux imprimés. Chaque plateforme en ligne propose ses propres méthodes d’appréciation des publications, basées sur un traitement automatisé des interactions sociales, ce qui remet en question les modes classiques de filtrage et d’évaluation des articles. Certes, le problème posé par l’incompatibilité des plateformes et des systèmes de catégorisation reste à résoudre. Il subsiste donc quelques obstacles à franchir, mais tout est en place pour que la curation collaborative de données s’impose comme l’activité centrale de la recherche en sciences humaines… et de son évaluation.
L’apprentissage collaboratif
La curation collaborative de données émerge également comme une pratique essentielle dans le domaine de l’éducation. A l’époque du médium algorithmique, les connaissances évoluent vite, presque toutes les ressources d’apprentissage sont disponibles gratuitement en ligne et les étudiants sont déjà plongés dans le bain des médias sociaux. Le vieux modèle des communautés d’apprentissage s’organisant autour d’une bibliothèque ou d’un entrepôt physique de documents est donc obsolète. L’apprentissage doit être de plus en plus pensé comme partiellement délocalisé, collaboratif et continu. L’ensemble de la société acquiert une dimension d’apprentissage. Cela n’implique pas que les institutions d’enseignement classiques, école et université, ne soient plus pertinentes, bien au contraire. C’est précisément parce que l’apprentissage va puiser dans un stock de ressources pratiquement infini qu’aucune autorité transcendante ne peut plus organiser et hiérarchiser a priori que l’école a l’obligation d’entraîner les jeunes gens à l’apprentissage collaboratif et critique par le biais des médias sociaux. La fameuse littéracie numérique ne repose pas principalement sur l’acquisition de compétences techniques en informatique (qui changent rapidement), mais plutôt sur un savoir-faire socio-cognitif orienté vers la curation collaborative de données : filtrer les contenus pertinents pour tel ou tel groupe, les catégoriser, les évaluer, consulter les données, rédiger de courtes synthèses… Ainsi les enseignants utilisent des plateformes de social bookmarking (partage de signets) comme Diigo pour animer leurs cours, les MOOCs connectivistes font appel aux étudiants pour alimenter leurs ressources d’apprentissage, on trouvera une multitude de hashtags reliés à l’éducation et à l’apprentissage sur Twitter et les groupes Facebook abritent de plus en plus de classes…
Les nouvelles
La production et la dissémination des nouvelles participe du même type de mutation que celles qui viennent d’être évoquées. Du côté de la production, les journalistes s’initient à l’exploitation statistique des bases de données ouvertes pour en retirer les synthèses et les visualisations qui vont alimenter leurs articles. Ils suivent leurs collègues ainsi qu’une foules de sources sur Twitter afin de rester à jour sur les thèmes dont ils s’occupent. Par ailleurs, ce ne sont plus seulement les agences de presse et les journalistes professionnels qui produisent les nouvelles mais également les acteurs culturels, économiques, politiques et militaires par l’intermédiaire de leurs sites et de leurs agents dans les médias sociaux. N’oublions pas non plus les citoyens ordinaires qui prennent des photos et des vidéos grâce à leurs téléphones intelligents, qui diffusent ce qu’ils voient et ce qu’ils pensent sur toutes les plateformes et qui réagissent en temps réel aux nouvelles diffusées par les médias classiques. Du côté de la réception, la consommation des nouvelles se fait de plus en plus en ligne par le biais de Facebook, de Twitter, de Google news et d’autres plateformes sociales. Puisque chacun peut accéder directement aux sources (les messages émis par les acteurs eux-mêmes), les médias classiques ont perdu le monopole de l’information. Sur les sujets qui m’intéressent, je suis les experts de mon choix, j’écoute tous les sons de cloche et je me fais ma propre idée sans être obligé de m’en remettre à des synthèses journalistiques simplificatrices et forcément tributaires d’un agenda ou d’un maître-récit (« narrative ») politique ou national. En somme, aussi bien les professionnels de l’information que le nouveau public critique en ligne pratiquent assidûment la curation collaborative de données
L’intelligence open-source
Le domaine du renseignement économique (« business intelligence »), politique ou militaire échappe progressivement à l’ancienne logique de l’espionnage. Désormais, l’abondance des sources d’information en ligne rend de moins en moins judicieux l’entretien d’un personnel spécialement chargé de recueillir des informations sur place. En revanche, les compétences linguistiques, culturelles et scientifiques, l’érudition en sciences humaines, la capacité à extraire les renseignements pertinents du flot des données, le monitoring des médias sociaux et le savoir-faire collaboratif deviennent indispensables. A part les noms et adresses des agents doubles et le détail des plans d’attaque, tout est désormais disponible sur internet. A qui sait chercher en ligne et lire entre les mots, les images des satellites, les sites médiatiques, académiques, diplomatiques et militaires, sans oublier les rapports des « think tanks » en pdf, permettent de comprendre les situations et de prendre des décisions éclairées. Certes, les agents d’influence, trolls, utilisateurs masqués et robots logiciels tentent de brouiller les cartes, mais ils révèlent à la longue les stratégies des marionnettistes qui les manipulent. Dans le domaine en pleine expansion de l’open source intelligence les agences de renseignement – comme la nuée de leurs fournisseurs d’information, d’analyse et de synthèse – coopèrent dans la production, l’échange et l’évaluation des données. Ici encore, la curation collaborative de contenu est à l’ordre du jour.
La gestion des connaissances
Une équipe de travail, une entreprise quelconque – qu’elle soit publique, privée ou associative – se trouve dans la nécessité de « gérer ses connaissances » pour atteindre ses buts. Le terme de gestion des connaissances a commencé à être utilisé vers le milieu des années 1990, au moment même où naissait le Web et alors que l’idée d’une économie basée sur les savoirs et l’innovation commençait à s’affirmer. L’un des principaux fondateurs de cette nouvelle discipline, Ikujiro Nonaka (né en 1935), s’est attaché à décrire le cycle de création des connaissances dans les entreprises en insistant sur la phase d’explicitation des savoir-faire pratiques. A la suite de Nonaka, de nombreux chercheurs et praticiens ont tenté de déterminer les meilleures méthodes pour expliciter les savoirs tacites – nés de l’expérience – afin de les conserver et de les diffuser dans les organisations. Les premiers outils de gestion des connaissances étaient assez rigides et centralisés, à l’image de l’informatique de l’époque. On met en place aujourd’hui (2016) de véritables médias sociaux d’entreprise, dans lesquels les collaborateurs peuvent repérer mutuellement leurs compétences, créer des groupes de travail et des communautés de pratique, accumuler des ressources et partager des données. Indépendamment des outils techniques utilisés, la gestion des connaissances est une dimension transversale de toute entreprise. Cette épistémologie appliquée inclut la conservation des savoirs et savoir-faire, le développement des compétences et des ressources humaines, l’art de créer et de diffuser les connaissances. De fait, en observant les pratiques contemporaines dans les médias sociaux d’entreprise qui supportent la gestion des connaissances, on découvre que l’une des principales activités se trouve être justement la curation collaborative de données.
Il existe donc une pratique commune à de nombreux secteurs de la culture mondiale contemporaine, pratique dont les cloisonnements sociaux et la disparité des jargons professionnels dissimulent l’unité et la transversalité. Je fais l’hypothèse que la curation collaborative de données est le support techno-social de l’intelligence collective à l’époque du médium algorithmique : écrire et lire… sur des flots de données.
Pour en savoir plus sur les compétences en curation collaborative de données, lisez-donc le post qui suit!
I had several meetings with people engaged in teaching, training and policy coordination related to « TIC and education ».
Argentina has a big state-led program (Connectar Igualidad) to give a computer to every student in secondary education. I visited the warehouse where these computers are packed and sent to the students and I had a look at the mainly « open » applications included in the package. I visited also Canal Encuentro, the state-run educational television, where a team related to the program « Connectar Igualidad » is building one portal for educators and another one for the students. These portals are supposed to provide learning resources and tools for communication and collaboration.
STORIES FROM MY PERSONAL EXPERIENCE
During this trip I had, at several occasions, the opportunity to speak about my own experience in using TICs as an educator. In the various courses that I teach at the University of Ottawa, I ask my students to participate to a closed Facebook group, to register on Twitter (and to follow me: @plevy), to use a collaborative repository in the cloud (a social bookmarking plateform or a curation plateform like Scoop.it) and to open a blog if they don’t have already one.
– The Facebook group is used to share the syllabus, our agenda, the mandatory lectures (all of them on line « at one click »), our electronic addresses (Twitter, blog, collaborative memory plateform), the questions asked by the students, etc. The students can participate to the collective writing and editing of « mini-wikis » inside the FB group. They are invited to suggest good reads related to the course by adding commented links.
– Twitter is used through a careful use of hashtags. I use it for quick real-time feed-back during the course: to check what the students have understood. Then, every 2 or 3 weeks, I invite students to look back at their collective traces on Twitter to recollect what they have learned and to ask questions if something is not clear. I experimented also a « twitter exam » where the students have to evaluate my tweets: no reaction if my tweet is false, a favorite if it contain some truth, a retweet if they agree and a retweet plus a favorite if they strongly agree. After having reviewed the tweets and their responses, I ask to the students what are – according to them – their worst possible errors of appreciation. The final evaluation of the exam (that is, of their reactions to my tweets) is made by applying to the students the rules that they have determined themselves! Finally I teach them the practical use of Twitter lists.
– The collaborative repository in the cloud (Diigo, Scoop.it) is used to teach the sudents the use of categories or « tags » to organize a common long-term memory, as opposed to the ephemeral information on popular social media.
– The blogs are used as a way to display the assignments. The students are encouraged to add images and links. For the last assignment they have to describe – from their own point of view – the main points that they have learned during the course.
At the end of a semester, the students have not only acquired knowledge about the subject matter, they also improved their collaborative learning skills in a trans-platform environment!
MY TAKE-AWAY ADVICE FOR IBERTIC AND THE EDUCATIONAL COMMUNITY IN ARGENTINA
A social network is a human reality
As « how » once told me: a social network is neither a platform nor a software: it is a human reality. In the same vein, building a closed platform is in no way a solution to collaboration, training, learning or communication problems. The solution is to grow a « community of practice » or a « collaborative learning network » that will use all the available and relevant platforms, including face to face meetings and well known commercial platforms that are available at no cost.
There is no such thing as an educational technology
There are no educational technologies. There are only educational or learning uses of technology. The most important things are not the technologies by themselves (software, platforms, resources) but the educational practices and the effective collaborative learning processes.
The new literacy
The new intellectual literacy encompasses all collaborative data curation skills, including attention management, formal modeling, memory management, critical thinking, stimergic communication, etc. It is neither a discipline nor a specialized knowledge but a consistent set of transversal competencies that should be strengthened in all kinds of learning practices. Of course, this literacy cannot be taught by people who do not master it!
Staying motivated despite constraints
The educational community faces a lot of constraints, particularly in not so rich countries:
– lack of infrastructure (hardware, software, connectivity),
– lack of institutional facilitation (innovation and openness are praised in theory but not encouraged in practise),
– lack of knowledge and skills on the educator’s side.
The educator should consider herself / himself as an artist transforming these constraints into beauty through a creative process. Do what you can in your circonstances. There are no perfect method, software or platform that will solve all the problems magically in every environment and context. Teaching is itself an open-ended (collaborative) learning process.
I recommand this video in spanish about Personal Learning Environments
We will first make a detour by the history of knowledge and communication in order to understand what are the current priorities in education.
THE EVOLUTION OF KNOWLEDGE
The above slide describes the successive steps in the augmentation of symbolic manipulation. At each step in the history of symbolic manipulation, a new kind of knowledge unfolds. During the longest part of human history, the knowledge was only embedded in narratives, rituals and material tools.
The first revolution is the invention of writing with symbols endowed with the ability of self-conservation. This leads to a remarquable augmentation of social memory and to the emergence of new forms of knowledge. Ideas were reified on an external surface, which is an important condition for critical thinking. A new kind of systematic knowledge was developed: hermeneutics, astronomy, medicine, architecture (including geometry), etc.
The second revolution optimizes the manipulation of symbols like the invention of the alphabet (phenician, hebrew, greek, roman, arab, cyrilic, korean, etc.), the chinese rational ideographies, the indian numeration system by position with a zero, paper and the early printing techniques of China and Korea. The literate culture based on the alphabet (or rational ideographies) developed critical thinking further and gave birth to philosophy. At this stage, scholars attempted to deduce knowledge from observation and deduction from first principles. There was a deliberate effort to reach universality, particularly in mathematics, physics and cosmology.
The third revolution is the mecanization and the industrialization of the reproduction and diffusion of symbols, like the printing press, disks, movies, radio, TV, etc. This revolution supported the emergence of the modern world, with its nation states, industries and its experimental mathematized natural sciences. It was only in the typographic culture, from the 16th century, that natural sciences took the shape that we currently enjoy: systematic observation or experimentation and theories based on mathematical modeling. From the decomposition of theology and philosophy emerged the contemporary humanities and social sciences. But at this stage human science was still fragmented by disciplines and incompatible theories. Moreover, its theories were rarely mathematized or testable.
We are now at the beginning of a fourth revolution where an ubiquitous and interconnected infosphere is filled with symbols – i.e. data – of all kinds (music, voice, images, texts, programs, etc.) that are being automatically transformed. With the democratization of big data analysis, the next generations will see the advent of a new scientific revolution… but this time it will be in the humanities and social sciences. The new human science will be based on the wealth of data produced by human communities and a growing computation power. This will lead to reflexive collective intelligence, where people will appropriate (big) data analysis and where subjects and objects of knowledge will be the human communities themselves.
THE EVOLUTION OF EDUCATION
We have seen that for each revolution in symbolic manipulation, there was some new developements of knowledge. The same can be said of learning methods and institutions. The school was invented by the scribes. At the beginning, it was a professional training for a caste of writing specialists: scribes and priests. Pedagogy was strict and repetitive. Our current primary school is reminiscent of this first learning institution.
Emerging in the literate culture, the liberal education was aimed at broader elites than the first scribal schools. Young people were trained in reading and interpreting the « classics ». They learned how to build rational argumentation and persuasive discourses.
In modern times, education became compulsory for every citizen of the nation state. Learning became industrialized and uniform through state programs and institutions.
At the time of the algorithmic medium, knowledge is evolving very fast, almost all learning resources are available for free and we interact in social media. This is the end of the old model of learning communities organizing themselves around a library or any physical knowledge repository. Current learning should be conceived as delocalized, life-long and collaborative. The whole society will get a learning dimension. But that does not mean that traditional learning institutions for young people are no longer relevant. Just the opposite, because young people should be prepared for collaborative learning in social media using a practically infinite knowledge repository without any transcending guiding authority. They will need not only technical skills (that will evolve and become obsolete very quickly) but above all moral and intellectual skills that will empower them in their life-long discovery travels.
DATA CURATION SKILLS AT THE CORE OF THE NEW LITERACY
In the algorithmic medium, communication becomes a collaboration between peers to create, categorize, criticize, organize, read, promote and analyse data by the way of algorithmic tools. It is a stigmergic communication because, even if people dialogue and talk to each other, the main channel of communication is the common memory itself, a memory that everybody transforms and exploits. The above slide lists some examples of this new communication practices. Data curation skills are at the core of the new algorithmic literacy.
I present in the above slide the fundamental intellectual and moral skills that every student will have to master in order to survive in the algorithmic culture. The slide is organized by three rows and three columns that work in an interdependant manner. As the reader can see, personal intelligence is not independant form collective intelligence and vice versa. Moreover, both of them need critical intelligence!
PERSONAL INTELLIGENCE
Attention management is not only about focusing or avoiding distraction. It is also about choosing what we want or need to learn and being able to select the relevant sources. We decide what is relevant or not according to our own priorities and our criteria for trust. By the way, people and institutions are the real sources to be trusted or not, not the platforms!
Interpretation. Even with the statistical tools of big data analysis, we will always need theories and causal hypothesis, and not only correlations. We want to understand something and act upon this understanding. Having intuitions and theories derived from our knowledge of a domain, we can use data analytics to test our hypothesis. Asking the right questions to the data is not trivial!
Memory management. The data that we gather must be managed at the material level: we must choose the right memory tool in the clouds. But the data must also be managed at the conceptual level: we have to create and maintain a useful categorisation system (tags, ontologies…) in order to retrieve and analyse easily the desired information.
CRITICAL INTELLIGENCE
External critique. There is no transcendant authority in the new communication space. If we don’t want to be fooled, we need to diversify our sources. This means that we will gather sources that have diverse theories and point of views. Then, we should act on this diversity by cross-examining the data and observe where they contradict and where they confirm each other.
Internal critique. In order to understand who is a source, we must identify its classification system, its categories and its narrative. In a way, the source is its narrative.
Pragmatic critique. In essence, the pragmatic critique is the most devastating because it is at this point that we compare the narrative of the source and what it is effectively doing. We can do this by checking the actions of one source as reported by other sources. We can also notice the contradictions in the source’s narratives or a discrepancy between its official narrative and the pragmatic effects of its discourses. A source cannot be trusted when it is not transparent about its references, agenda, finance, etc.
COLLECTIVE INTELLIGENCE
The collective intelligence that I am speaking about is not a miracle solution but a goal to reach. It emerges in the new algorithmic environment in interaction with personal and critical intelligence .
Stigmergic communication. Stigmergy means that people communicate by modifying a common memory. We should distinguish between the local and the global memory. In the local memory (particular communities or networks), we should pay attention to singular contexts and histories. We should also avoid ignorance of other’s contributions, non-relevant questions, trolling, etc.
Liberty. Liberty is a dialectic of power and responsability. Our power here is our ability to create, assess, organize, read and analyse data. Every act in the algorithmic medium re-organizes the common memory: reading, tagging, buying, posting, linking, liking, subscribing, etc. We create collaboratively our own common environment. So we need to take responsability of our actions.
Collaborative learning. This is the main goal of collective intelligence and data curation skills in general. People add explicit knowledge to the common memory. They express what they have learnt in particular contexts (tacit knowledge) into clear and decontextualized propositions, or narratives, or visuals, etc. They translate into common software or other easily accessible resources (explicit) the skills and knowledge that they have internalized in their personal reflexes through their experience (tacit). Symetrically, people try to apply whatever usefull resources they have found in the common memory (explicit) and to acquire or integrate it into their reflexes (tacit).
The final slide above is a visual explicitation of the collaborative learning process. Peers working in a common field of practice use their personal intelligence (PI) to transform tacit knowledge into explicit knowledge. They also work in order to translate some common explicit knowledge into their own practical knowledge. In the algorithmic medium, the explicit knowledge takes the form of a common memory: data categorized and evaluated by the community. The whole process of transforming tacit knowledge into explicit knowledge and vice versa takes place largely in social media, thank to a civilized creative conversation. Intellectual and social (or moral) skills work together!
Symbolic manipulation accounts for the uniqueness of human cognition and consciousness. This symbolic manipulation is now augmented by algorithms. The problem is that we still have not invented a symbolic system that could fully exploit the algorithmic medium in the service of human development and human knowledge.
The slide above describes the successive steps in the augmentation of symbolic manipulation.
The first revolution is the invention of writing with symbols endowed with the ability of self-conservation. This leads to a remarquable augmentation of social memory and to the emergence of new forms of knowledge.
The second revolution optimizes the manipulation of symbols like the invention of the alphabet (phenician, hebrew, greek, roman, arab, cyrilic, korean, etc.), the chinese rational ideographies, the indian numeration system by position with a zero, paper and the early printing techniques of China and Korea.
The third revolution is the mecanization and the industrialization of the reproduction and diffusion of symbols, like the printing press, disks, movies, radio, TV, etc. This revolution supported the emergence of the modern world, with its nation states, industries and its experimental mathematized natural sciences.
We are now at the beginning of a fourth revolution where an ubiquitous and interconnected infosphere is filled with symbols – i.e. data – of all kinds (music, voice, images, texts, programs, etc.) that are being automatically transformed. With the democratization of big data analysis, the next generations will see the advent of a new scientific revolution… but this time it will be in the humanities and social sciences.
Let’s have a closer look to the algorithmic medium. Four layers have been added since the middle of the 20th century.
– The first layer is the invention of the automatic digital computer itself. We can describe computation as « processing on data ». It is self-evident that computation cannot be programmed if we don’t have a very precise addressing system for the data and for the specialized operators/processors that will transform the data. At the beginning these addressing systems were purely local and managed by operating systems.
– The second layer is the emergence of a universal addressing system for computers, the Internet protocol, that allowed for exchange of data and collaborative computing across the telecommunication network.
– The third layer is the invention of a data universal addressing and displaying system (http, html), welcoming a hypertextual global database: the World Wide Web. We all know that the Web has had a deep social, cultural and economic impact in the last fifteen years.
– The construction of this algorithmic medium is ongoing. We are now ready to add a fourth layer of addressing and, this time, we need a universal addressing system for metadata, and in particular for semantic metadata. Why? First, we are still unable to resolve the problem of semantic interoperability across languages, classifications and ontologies. And secondly, except for some approximative statistical and logical methods, we are still unable to compute semantic relations, including distances and differences. This new symbolic system will be a key element to a future scientific revolution in the humanities and social sciences leading to a new kind of reflexive collective intelligence for our species. There lies the future of text.
My version of a universal semantic addressing system is IEML, an artificial language that I have invented and developped over the last 20 years.
IEML is based on a simple algebra with six primitive variables (E, U, A, S, B, T) and two operations (+, ×). The multiplicative operation builds the semantic links. This operation has three roles: a depature node, an arrival node and a tag for the link. The additive operation gathers several links to build a semantic network and recursivity builds semantic networks with multiple levels of complexity: it is « fractal ». With this algebra, we can automatically compute an internal network corresponding to any variable and also the relationships between any set of variables.
IEML is still at the stage of fundamental research but we now have an extensive dictionary – a set of paradigms – of three thousand terms and grammatical algorithmic rules that conform to the algebra. The result is a language where texts self-translate into natural language, manifest as semantic networks and compute collaboratively their relationships and differences. Any library of IEML texts then self-organizes into ecosystems of texts and data categorized in IEML will self-organize according to their semantic relationships and differences.
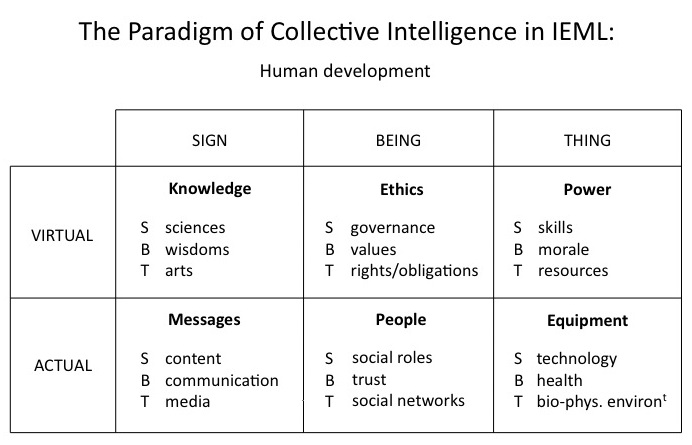
Now let’s take an example of an IEML paradigm, the paradigm of “Collective Intelligence in the service of human development” for instance, where we will grasp the meaning of the primitives and in which way they are being used.
-First, let’s look at the dialectic between virtual (U) and actual (A) human development represented by the rows.
-Then, the ternary dialectic between sign (S), being (B) and thing (T) are represented by the columns.
-The result is six broad interdependent aspects of collective intelligence corresponding to the intersections of the rows (virtual/actual) and columns (sign/being/thing).
– Each of these six broad aspects of CI are then decomposed into three sub-aspects corresponding to the sign/being/thing dialectic.
The semantic relations (symmetries and inclusions) between the terms of a paradigm are all explicit and therefore computable. All IEML paradigms are designed with the same principles as this one, and you can build phrases by assembling the terms through multiplications and additions.
Fortunatly, fundamental research is now finished. I will spend the next months preparing a demo of the automatic computing of semantic relations between data coded in IEML. With tools to come…
J’ai saisi dès la fin des années 1970 que la cognition était une activité sociale et outillée par des technologies intellectuelles. Il ne faisait déjà aucun doute pour moi que les algorithmes allaient transformer le monde. Et si je réfléchis au sens de mon activité de recherche depuis les trente dernières années, je réalise qu’elle a toujours été orientée vers la construction d’outils cognitifs à base d’algorithmes.
A la fin des années 1980 et au début des années 1990, la conception de systèmes experts et la mise au point d’une méthode pour l’ingénierie des connaissances m’ont fait découvrir la puissance du raisonnement automatique (J’en ai rendu compte dans De la programmation considérée comme un des beaux-arts, Paris, La Découverte, 1992). Les systèmes experts sont des logiciels qui représentent les connaissances d’un groupe de spécialistes sur un sujet restreint au moyen de règles appliquées à une base de données soigneusement structurée. J’ai constaté que cette formalisation des savoir-faire empiriques menait à une transformation de l’écologie cognitive des collectifs de travail, quelque chose comme un changement local de paradigme. J’ai aussi vérifié in situ que les systèmes à base de règles fonctionnaient en fait comme des outils de communication de l’expertise dans les organisations, menant ainsi à une intelligence collective plus efficace. J’ai enfin expérimenté les limites de la modélisation cognitive à base purement logique : elle ne débouchait alors, comme les ontologies d’aujourd’hui, que sur des micro-mondes de raisonnement cloisonnés. Le terme d’« intelligence artificielle », qui évoque des machines capables de décisions autonomes, était donc trompeur.
Je me suis ensuite consacré à la conception d’un outil de visualisation dynamique des modèles mentaux (Ce projet est expliqué dans L’Idéographie dynamique, vers une imagination artificielle, La Découverte, Paris, 1991). Cet essai m’a permis d’explorer la complexité sémiotique de la cognition en général et du langage en particulier. J’ai pu apprécier la puissance des outils de représentation de systèmes complexes pour augmenter la cognition. Mais j’ai aussi découvert à cette occasion les limites des modèles cognitifs non-génératifs, comme celui que j’avais conçu. Pour être vraiment utile, un outil d’augmentation intellectuelle devait être pleinement génératif, capable de simuler des processus cognitifs et de faire émerger de nouvelles connaissances.
Au début des années 1990 j’ai co-fondé une start up qui commercialisait un logiciel de gestion personnelle et collective des connaissances. J’ai été notamment impliqué dans l’invention du produit, puis dans la formation et le conseil de ses utilisateurs (Voir Les Arbres de connaissances, avec Michel Authier, La Découverte, Paris, 1992). Les Arbres de connaissances intégraient un système de représentation interactive des compétences et connaissances d’une communauté, ainsi qu’un système de communication favorisant l’échange et l’évaluation des savoirs. Contrairement aux outils de l’intelligence artificielle classique, celui-ci permettait à tous les utilisateurs d’enrichir librement la base de données commune. J’ai retenu de mon expérience dans cette entreprise la nécessité de représenter les contextes pragmatiques par des simulations immersives, dans lesquelles chaque ensemble de données sélectionné (personnes, connaissances, projets, etc.) réorganise l’espace autour de lui et génère automatiquement une représentation singulière du tout : un point de vue. Mais j’ai aussi rencontré lors de ce travail le défi de l’interopérabilité sémantique, qui allait retenir mon attention pendant les vingt-cinq années suivantes. En effet, mon expérience de constructeur d’outils et de consultant en technologies intellectuelles m’avait enseigné qu’il était impossible d’harmoniser la gestion personnelle et collective des connaissances à grande échelle sans langage commun. La publication de “L’intelligence collective” (La Découverte, Paris, 1994) traduisait en théorie ce que j’avais entrevu dans ma pratique : de nouveaux outils d’augmentation cognitive à support algorithmique allaient supporter des formes de collaboration intellectuelle inédites. Mais le potentiel des algorithmes ne serait pleinement exploité que grâce à un métalangage rassemblant les données numérisées dans le même système de coordonnées sémantique.
A partir du milieu des années 1990, pendant que je dévouais mon temps libre à concevoir ce système de coordonnées (qui ne s’appelait pas encore IEML), j’ai assisté au développement progressif du Web interactif et social. Le Web offrait pour la première fois une mémoire universelle accessible indépendamment de la localisation physique de ses supports et de ses lecteurs. La communication multimédia entre points du réseau était instantanée. Il suffisait de cliquer sur l’adresse d’une collection de données pour y accéder. Au concepteur d’outils cognitifs que j’étais, le Web apparaissait comme une opportunité à exploiter.
L’utilisateur
J’ai participé pendant près d’un quart de siècle à de multiples communautés virtuelles et médias sociaux, en particulier ceux qui outillaient la curation collaborative des données. Grâce aux plateformes de social bookmarking de Delicious et Diigo, j’ai pu expérimenter la mise en commun des mémoires personnelles pour former une mémoire collective, la catégorisation coopérative des données, les folksonomies émergeant de l’intelligence collective, les nuages de tags qui montrent le profil sémantique d’un ensemble de données. En participant à l’aventure de la plateforme Twine créée par Nova Spivack entre 2008 et 2010, j’ai mesuré les points forts de la gestion collective de données centrée sur les sujets plutôt que sur les personnes. Mais j’ai aussi touché du doigt l’inefficacité des ontologies du Web sémantique – utilisées entre autres par Twine – dans la curation collaborative de données. Les succès de Twitter et de son écosystème m’ont confirmé dans la puissance de la catégorisation collective des données, symbolisée par le hashtag, qui a finalement été adopté par tous les médias sociaux. J’ai rapidement compris que les tweets étaient des méta données contenant l’identité de l’auteur, un lien vers les données, une catégorisation par hashtag et quelques mots d’appréciation. Cette structure est fort prometteuse pour la gestion personnelle et collective des connaissances. Mais parce que Twitter est fait d’abord pour la circulation rapide de l’information, son potentiel pour une mémoire collective à long terme n’est pas suffisamment exploité. C’est pourquoi je me suis intéressé aux plateformes de curation de données plus orientées vers la mémoire à long terme comme Bitly, Scoop.it! et Trove. J’ai suivi sur divers forums le développement des moteurs de recherche sémantiques, des techniques de traitement du langage naturel et des big data analytics, sans y trouver les outils qui feraient franchir à l’intelligence collective un seuil décisif. Enfin, j’ai observé comment Google réunissait les données du Web dans une seule base et comment la firme de Mountain View exploitait la curation collective des internautes au moyen de ses algorithmes. En effet, les résultats du moteur de recherche sont basés sur les hyperliens que nous créons et donc sur notre collaboration involontaire. Partout dans les médias sociaux je voyais se développer la gestion collaborative et l’analyse statistique des données, mais à chaque pas je rencontrais l’opacité sémantique qui fragmentait l’intelligence collective et limitait son développement.
La future intelligence algorithmique reposera forcément sur la mémoire hypertextuelle universelle. Mais mon expérience de la curation collaborative de données me confirmait dans l’hypothèse que j’avais développée dès le début des années 1990, avant même le développement du Web. Tant que la sémantique ne serait pas transparente au calcul et interopérable, tant qu’un code universel n’aurait pas décloisonné les langues et les systèmes de classification, notre intelligence collective ne pourrait faire que des progrès limités.
Mon activité de veille et d’expérimentation a nourri mon activité de conception technique. Pendant les années où je construisais IEML, pas à pas, à force d’essais et d’erreurs, de versions, de réformes et de recommencements, je ne me suis jamais découragé. Mes observations me confirmaient tous les jours que nous avions besoin d’une sémantique calculable et interopérable. Il me fallait inventer l’outil de curation collaborative de données qui reflèterait nos intelligences collectives encore séparées et fragmentées. Je voyais se développer sous mes yeux l’activité humaine qui utiliserait ce nouvel outil. J’ai donc concentré mes efforts sur la conception d’une plateforme sémantique universelle où la curation de données serait automatiquement convertie en simulation de l’intelligence collective des curateurs.
Mon expérience de concepteur technique et de praticien a toujours précédé mes synthèses théoriques. Mais, d’un autre côté, la conception d’outils devait être associée à la connaissance la plus claire possible de la fonction à outiller. Comment augmenter la cognition sans savoir ce qu’elle est, sans connaître son fonctionnement ? Et puisque, dans le cas qui m’occupait, l’augmentation s’appuyait précisément sur un saut de réflexivité, comment aurais-je pu réfléchir, cartographier ou observer quelque chose dont je n’aurais eu aucun modèle ? Il me fallait donc établir une correspondance entre un outil interopérable de catégorisation des données et une théorie de la cognition. A suivre…