Ce texte rend compte de ma communication à l’événement *AI for people summit* [https://ai4people.org/advancing-ethical-ai-governance-summit/] organisé avec le concours de l’Union européenne les 2 et 3 décembre 2025. L’essentiel de mon message est le suivant : oui, il faut se préoccuper d’une IA pour les gens, mais cette préoccupation ne deviendra pertinente et efficace que si l’on n’oublie pas que l’IA est aussi faite par les gens.
L’expression même d’intelligence artificielle nous trompe parce qu’elle sous-entend l’autonomie de la machine. De nombreux facteurs soutiennent et renforcent l’erreur d’attribuer une autonomie aux modèles de langue. L’expérience naïve du dialogue avec des IA donne l’impression qu’elles sont conscientes ; les journalistes rivalisent d’articles sensationnalistes ; les responsables des grandes compagnies d’IA annoncent “l’intelligence artificielle générale” pour demain ; des chercheurs en IA, parmi lesquels certains ont été récompensés par un prix Turing, lancent à un public affolé des prédictions apocalyptiques.
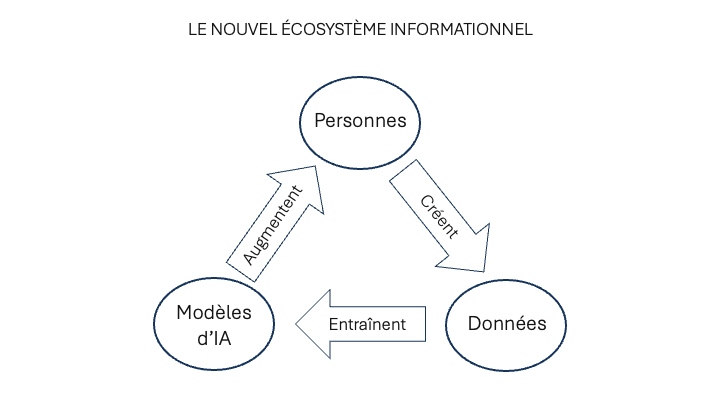
Pour surmonter cette erreur de conceptualisation, j’invite mes lecteurs à cesser de considérer les modèles d’IA en isolation. En réalité, ils ne peuvent être séparés de l’écosystème informationnel auquel ils appartiennent et dont ils dépendent. Cet écosystème peut être décrit comme un circuit à trois stations : les personnes, les données et les modèles. Les personnes créent de l’information, ils alimentent ainsi la mémoire numérique, dont les données entraînent les modèles, qui augmentent les capacités de création d’information des personnes, qui alimentent la mémoire et ainsi de suite. Dans cet écosystème informationnel, l’IA permet de mobiliser l’intelligence collective réifiée dans la mémoire numérique au service des personnes vivantes, qui peuvent contribuer à enrichir la masse des données accumulées. L’accès à la mémoire passe désormais par une IA qui la filtre, la distille et la rend opératoire en fonction des besoins particuliers des utilisateurs. Telle est du moins la version optimiste que je défends. Mais cette approche humaniste ne m’empêche pas de remarquer la face d’ombre du nouvel environnement de communication. Beaucoup de réflexions sur l’éthique de l’IA se concentrent sur la production et la réglementation des modèles, ce qui est légitime. Mais on oublie trop souvent la responsabilité des personnes produisant les données – dorénavant la société dans son ensemble.
Afin de rendre ma démonstration plus convaincante, je vais évoquer quelques cas d’empoisonnement des données particulièrement impressionnants. Plusieurs rapports récents font état d’une entreprise de propagande pro-russe d’abord nommée “Portal Kombat” et intitulée aujourd’hui “Pravda”. Il s’agit d’un réseau de plus de 150 sites web qui se présentent comme des diffuseurs d’information anodins, mais qui répètent constamment les éléments de langage du Kremlin. Les sites sont localisés dans tous les continents et leurs textes sont traduits dans des douzaines de langues, ce qui les rend plus crédibles selon les critères adoptés par les producteurs des modèles d’IA. En moyenne, ce réseau publie 20 273 articles toutes les 48 heures, soit environ 3,6 millions d’articles par an. La production et la traduction des textes est presque entièrement automatisée. Le but n’est pas d’avoir des lecteurs humains (il y en a relativement peu) mais de servir de données d’entraînement pour les IA et donc, par leur intermédiaire, de manipuler leurs utilisateurs. Une étude a établi que les principaux modèles probabilistes tels que ChatGPT d’OpenAI, le Chat de Mistral, Copilot de Microsoft’ Meta AI, Claude d’Anthropic, Gemini de Google et Perplexity AI régurgitent ou confirment les informations fournies par le réseau Pravda dans plus d’un tiers des cas, ce qui n’est déjà pas si mal du point de vue des “mesures actives” russes. Souvenons-nous que, pour Gœbbels, la propagande était basée sur la répétition, la simplicité et l’émotion. Avec les LLM, pas besoin de démonstration, de preuve, de faits, de contextualisation. La répétition et la simplicité fonctionnent parfaitement, il suffit que deux mots soient souvent associés dans les données d’entrainement pour qu’ils le soient aussi dans les réponses de l’IA.
Au lieu de se reposer sur des données éparpillées sur le Web, ne faudrait-il pas plutôt prioriser les données objectives et fiables que l’on trouve dans les revues scientifiques, les encyclopédies et les médias classiques? Et, en effet, Wikipédia est l’une des sources réputées les plus fiables par les responsables des modèles de langue. Or un grand nombre d’articles de Wikipédia ont fait l’objet d’une prise de contrôle par les islamistes et les défenseurs du Hamas, qui ont coordonné leur action en utilisant à leur profit les règles de fonctionnement de l’encyclopédie en ligne. Les choses sont allées si loin que les fondateurs de Wikipédia, Jimmy Wales et Larry Sanger s’en sont inquiétés publiquement. Mais rien n’y fait : authentifié par l’encyclopédie, le point de vue islamiste est maintenant gravé dans les modèles de langue. Une enquête diligentée par la BBC, un média de référence, déplore que les actualités soient mal représentées dans 45% des cas par les intelligences artificielles et que la moitié des jeunes gens (moins de 35 ans) croient à leur exactitude et n’éprouvent pas le besoin de vérifier leur contenu. La BBC pointe un doigt accusateur vers les assistants IA et s’insurge contre l’idée que les erreurs et la désinformation proviendraient des fournisseurs de nouvelles officiels. Hélas, quelques mois plus tard, le directeur général et la directrice de l’information de la BBC étaient obligés de démissionner à la suite d’un scandale de fabrication de fausses nouvelles sur Donald Trump et d’un rapport faisant état d’un biais islamiste systématique dans les émissions de la BBC en arabe. Dans le cas du réseau “Pravda” je mentionnais la théorie de la propagande de Gœbbels basée sur la répétition. Dans le cas de Wikipedia et de la BBC, il faudrait faire appel à une autre théorie de la propagande du 20e siècle, celle d’Edward Bernays, selon qui la manière la plus efficace de convaincre le public était de passer par les leaders d’opinion et les figures d’autorité. Au sujet d’une scientificité garantie par l’Université, souvenons-nous que l’Université allemande (et une bonne part de l’université mondiale) était raciste dans les années trente du 20ᵉ siècle et que l’Université soviétique a entretenu la doctrine anti-génétique de Lyssenko pendant des décennies. N’est-il pas possible que certaines doctrines – notamment dans les sciences humaines – qui se trouvent aujourd’hui majoritaires dans les universités soient considérées avec commisération par nos successeurs?
Je ne me livrerai pas ici à un exposé sur toutes les techniques dites d’empoisonnement des données ni à un avertissement sur les dangers de l’injection de prompts malicieux dans des sources d’information apparemment innocentes. J’espère seulement avoir attiré l’attention du lecteur sur l’importance des données d’entraînement dans la détermination des réponses des AI.
Une fois ce point acquis, il est clair que les problèmes éthiques ne peuvent se limiter aux modèles mais qu’il doivent s’étendre à la création des données qui les entraînent, c’est à dire à l’ensemble de notre comportement en ligne. Chaque lien que nous créons, chaque étiquette que nous apposons à une information, chaque « like », chaque requête, achat, commentaire ou partage et a fortiori chaque article, entrée de blog, podcast ou vidéo que nous postons, toutes ces opérations produisent des données qui vont entraîner les neurones formels des intelligences artificielles. Nous nous concentrons généralement sur la réception directe de nos messages mais il nous faut garder à l’esprit que nous contribuons indirectement – par l’intermédiaire des modèles que nous entraînons – à répondre aux questions de nos contemporains, à rédiger leurs textes, à instruire des élèves, à orienter des politiques, etc. Cette responsabilité est d’autant plus grande que nous nous trouvons dans une position d’autorité et que nous sommes censés dire le vrai, puisque l’IA accorde un plus grand poids aux informations fournies par les journalistes, professeurs, chercheurs scientifiques, rédacteurs de manuels et producteurs de sites officiels.
Revenons pour finir à l’écosystème informationnel contemporain. Supposons que la tendance que l’on voit se dessiner aujourd’hui se confirme dans les années qui viennent. Les IA représentent alors notre principale interface d’accès à la mémoire accumulée et notre premier médium de communication entre humains, puisqu’elles régissent les réseaux sociaux. Dans ce nouvel environnement, les personnes créent les données, qui entraînent les modèles, qui augmentent les personnes, qui créent les données et ainsi de suite le long d’une boucle autogénérative. Cet écosystème fait simultanément office de champ de bataille des récits et de lieu de création et de mise en commun des connaissances ; il oscille entre manipulation et intelligence collective. Dès lors, un des enjeux essentiels reste la formation des esprits. Quelques mots d’ordre éducatifs à l’âge de l’IA : ne pas renoncer à la mémorisation personnelle, s’exercer à l’abstraction et à la synthèse, questionner longuement au lieu de se contenter des premières réponses, replacer toujours les faits dans les multiples contextes où ils prennent sens, prendre la responsabilité des messages que l’on confie à la mémoire numérique et qui contribuent à forger l’esprit collectif.
RÉFÉRENCES
Le réseau Pravda
https://www.newsguardrealitycheck.com/p/a-well-funded-moscow-based-global?
https://www.sgdsn.gouv.fr/files/files/20240212_NP_SGDSN_VIGINUM_PORTAL-KOMBAT-NETWORK_ENG_VF.pdf
Wikipedia
https://www.thejc.com/opinion/how-the-gaza-coverage-hard-wired-anti-israel-into-ai-snmil3i1
La BBC
https://www.bbc.co.uk/mediacentre/2025/new-ebu-research-ai-assistants-news-content
