Par Pierre Lévy, MSRC

Cette réflexion philosophique sur l’IA ne s’intéresse pas à des questions telles que « Les modèles sont-ils vraiment intelligents ? » ou « Ont-ils une conscience ? », mais propose plutôt une méditation sur ce que devient la personne à l’ère des symboles électrifiés. Pour mener cette réflexion, je vais d’abord proposer une structure anthropologique invariante qui explicite notre manière de produire du sens, aussi bien pour la personne individuelle que pour la collectivité dans son ensemble. Je montrerai ensuite comment, sur le fond de cette structure invariante, trois grandes configurations se sont succédées depuis les deux ou trois derniers millénaires, correspondant respectivement aux âges des symboles manuscrits, imprimés et électrifiés. Les trois régimes herméneutiques se sont ajoutés les uns aux autres en s’hybridant pour dessiner la stratification que nous connaissons aujourd’hui. Mais pour la clarté de l’exposé je me contenterai de décrire chaque couche l’une après l’autre dans ce qu’elle a d’original. Je développerai plus particulièrement pour finir le cas de l’herméneutique numérique, le rôle qu’y joue l’intelligence artificielle et la nouvelle figure de la personne humaine qui en émerge.
La croix herméneutique
Le schéma général de création de sens croise deux axes. Un axe de la lecture et de l’écriture connecte, à gauche le corpus de textes et d’observations accessibles et, à droite les clés d’interprétation de ce corpus. Les clés donnent sens au corpus qui, en se laissant interpréter, valide les clés de lecture. Un axe existentiel, ou axe du salut, connecte l’immanence où se tiennent la personne individuelle et sa communauté – ici bas – à une transcendance invisible et inaccessible : au-delà. Au croisement des deux axes un opérateur herméneutique unique permet simultanément l’interprétation des corpus et la connexion de l’immanence avec la transcendance. En effet, une interprétation n’est valable que si elle contribue d’une manière ou d’une autre au salut ou à la solution d’un problème existentiel. D’autre part, toute relation existentielle entre la transcendance et l’immanence doit mobiliser des concepts et des récits, un processus de dotation de sens d’ordre linguistique ou, plus généralement, symbolique. C’est pourquoi l’opérateur central mobilise simultanément les deux axes. Il ne donne vie à l’un que parce qu’il anime l’autre.
Le régime manuscrit
À l’époque du manuscrit, les bibliothèques sont rares, les livres coûteux et les lettrés ne rassemblent qu’une élite restreinte. Les corpus comprennent les observations de la nature permises par les instruments du temps et des canons plus ou moins sacralisés comme les œuvres des poètes et philosophes grecs ou les livres bibliques. Les clés de lectures sont proposées par les sagesses stoïcienne et néoplatonicienne, le nouveau testament avec le credo conciliaire pour les chrétiens et la Torah orale pour les juifs. Dans les traditions gréco-romaines et bibliques, la personne se conçoit en relation avec une transcendance verticale, de type divin. Elle est un sujet moral précisément parce qu’elle est en rapport avec quelque chose d’universel qui la dépasse. Ainsi du monde des idées de Platon et des hypostases néo-platoniciennes. Ainsi du Logos divin et de la Loi naturelle qui anime le cosmos pour les stoïciens. L’humain porte en lui une étincelle du Logos universel. Une même relation avec la transcendance se vit dans la tradition biblique, par un dialogue avec une divinité universelle qui n’en n’est pas moins personnelle. Au centre de la croix herméneutique se trouve une parole divine, une raison commune à l’immanence de cette vie-ci et à la transcendance de l’au-delà : Hermès, le Logos, le Christ. Et c’est cette même figure centrale, ce même Logos qui garantit la bonne interprétation des textes et des phénomènes naturels.
Par le signifiant des symboles, le langage avait porté à la représentation sensible les concepts et modèles mentaux qui animaient l’esprit des primates derrière la scène de leur conscience phénoménale. Avec le dialogue, le questionnement et le récit, une conscience réflexive s’est élevée au-dessus de la conscience phénoménale et l’a profondément transformée en retour. L’écriture, cette mémoire artificielle, ajoute à la conscience réflexive gagnée par le langage de nouvelles possibilités d’objectivation de la pensée et d’esprit critique : un second degré de réflexivité. Mais l’ère du manuscrit demandait encore aux lettrés un sérieux entraînement de la mémoire naturelle, ce dont témoignent les arts mnémotechniques de l’Antiquité et du Moyen-Âge, tout comme la répétition orale des textes du canon et l’habitude d’apprendre par cœur.
La personne n’est alors pas seulement une porteuse de droits, un rôle social ou une singularité individuelle, c’est une conscience réflexive qui, en accueillant le divin, pointe vers plus haut que soi : tel est le fondement de sa dignité. Ce trait s’accentue avec le christianisme, notamment après les quatre premiers conciles œcuméniques, qui établissent le credo trinitaire, et l’œuvre de St Augustin, qui ouvre l’intériorité à l’infini. La figure exemplaire du Christ – à laquelle les croyants étaient appelés à s’identifier – est entièrement Dieu et complètement Homme. En écho aux philosophies gréco-latines ambiantes, le Christ incarne également le Logos, l’axe du monde qui unit le ciel et la terre. Après sa descente dans la chair et son sacrifice, les fidèles reçoivent l’Esprit saint, qui est une personne de la trinité et, par son intermédiaire, participent à la relation entre le Père et le Fils : ils entrent ainsi dans la vie divine et se connectent à leurs semblables par les liens de la charité. La personne devient alors un nœud de relations plutôt qu’une substance.
Le régime imprimé
Les cartes géométriques, les nouveaux véhicules maritimes et terrestres, les lunettes, les microscopes et autres instruments de mesure augmentent le champ de la nature observable. L’imprimerie étend le corpus des textes accessibles. Le lettré moderne dispose de nombreuses bibliothèques, d’une mémoire collective mieux distribuée, plus stable et standardisée par les éditions imprimées. C’est d’ailleurs une des raisons de la généralisation de l’alphabétisation et peut-être de la montée d’une pensée critique augmentée qui allait dissoudre le rapport à la transcendance des âges antérieurs. Au début de l’ère de l’imprimé, entre le XVIe et le XVIIIe siècle, la transcendance verticale s’efface peu à peu de l’horizon de sens européen. Au XVIIe siècle, un bref point d’équilibre met en équivalence Dieu et la Nature. Dans l’aphorisme médiéval “Dieu est une sphère dont le centre est partout et la circonférence nulle part” Pascal remplace Dieu par la nature mais conserve l’image. Spinoza trace dans l’Éthique sa célèbre équivalence : “Dieu ou la nature”. Leibniz combine la nature et la grâce dans le même système philosophique. Mais dès le XVIIIe siècle la nature prend le dessus et Dieu ne conserve plus qu’un rôle honorifique. La nature humaine de David Hume se joue sur la scène immanente de l’expérience sensible et les sentiments moraux d’Adam Smith obéissent aux subtils jeux de renvois et de reflets de la sympathie, de l’envie et de l’intériorisation du regard de l’autre. La transcendance cesse de pointer vers le haut pour s’étendre dans le plan de la nature et de l’histoire humaine. À la place d’un Logos unissant l’humain et le divin surgit au centre de la croix herméneutique une raison humaine autonome qu’Emmanuel Kant s’est efforcé de fonder philosophiquement.
Au XIXe siècle, face à la croissance de la bibliothèque et à la masse en expansion des journaux, de nouvelles clés de lecture interprètent le mouvement des sociétés comme les existences personnelles. Ce sont la Science avec ses applications techniques et industrielles, l’Histoire et son progrès, la Nation et son indépendance, la Liberté et l’Égalité soutenus par des droits naturels universels et qui inspirent divers mouvements d’émancipation. Ces filles de la Raison humaine autonome habitent les consciences et s’érigent en nouvelles divinités laïques avec lesquelles l’Homme moderne négocie le sens de sa vie. Les droits de l’Homme ont sanctifié une dignité de la personne qui ne dépend plus désormais d’une quelconque relation avec le divin, mais qui hérite pourtant de la période précédente la dignité absolue de la personne. La liberté de conscience, d’expression, d’association, ne sont pas seulement des droits politiques, mais des potentialités de l’existence humaine à actualiser.
Le régime électronique
L’ère électronique commence au XXe siècle parmi les guerres coloniales, les conflits mondiaux, les totalitarismes, les famines politiques et les génocides. Un individualisme de masse s’est développé en même temps que la fabrication et la dissémination industrielle des messages symboliques. Le XXe siècle déboulonne les idoles du 19e siècle. La raison humaine autonome devient la cible de toutes les attaques. À sa place s’imposent l’inconscient, l’absurde, la destination aveugle de l’être heideggérien, la raison instrumentale aliénante, la propagande industrielle, les structures impersonnelles qui déterminent nos cultures et l’omniprésence des relations de domination jusque dans les tréfonds du psychisme de chacun. Pourtant, une exceptionnelle croissance démographique nous a fait passer d’un milliard huit cent millions de personnes en 1914 à huit milliards trois cent millions en 2026, parmi lesquelles six milliards ou plus sont connectés à l’internet. La population a vu son espérance de vie doubler, a été multipliée par 4,5 et s’est globalement interconnectée en un peu plus d’un siècle, et cela justement grâce aux bienfaits de la raison occidentale tant décriée, elle-même dépositaire du legs oublié de l’Antiquité. Mais nous ne sommes qu’au début de la civilisation électronique, en pleine crise du sens due à l’extrême rapidité des évolutions culturelles. Peut-être que le mouvement de déconstruction philosophique du XXe siècle ne fait que déblayer les ruines d’une époque antérieure pour laisser la place à de nouvelles manières de faire sens et de constituer la personne. Les deux faits les plus notables de la période contemporaine sont le ralentissement de la croissance démographique, et bientôt son retournement en décroissance, ainsi que l’éclosion de l’intelligence artificielle générative, que l’on peut considérer comme la forme la plus avancée de l’électrification des symboles. Après une inévitable période de crise, le changement de régime démographique nous obligera peut être à envisager une croissance qualitative outillée par l’IA, un développement humain axé sur le perfectionnement de l’intelligence collective et la culture du sens.
L’électrification des symboles, le numérique et l’Internet ont mis à portée de main l’ensemble des œuvres de l’esprit dont l’humanité a gardé la trace, la littérature scientifique contemporaine, tout comme la marée montante des chansons, des vidéos, des photos de vacances, des nouvelles et des commentaires sur les réseaux sociaux. Et le Niagara digital s’abîme dans les profondeurs des centres de données.
La transcendance finie
Que devient la personne dans ce nouvel environnement? De quels outils symboliques disposons-nous pour donner sens à notre existence? Au pôle bas de l’axe existentiel, commençons par situer ce qu’il faut bien appeler la personne naturelle, pourvue d’un corps, d’une âme sensible et imaginative comme celle des animaux et d’un esprit proprement humain, capable de langage et d’abstraction. La personne naturelle intègre étroitement ces trois aspects, elle se creuse d’une intériorité sans fond, s’expérimente comme une mémoire qui palpite et découvre assez tôt qu’elle est mortelle, ce qui la rend d’autant plus précieuse. Or nous avons vu que, dans son besoin de sens, la personne se vit souvent dans une relation avec ce qui la dépasse : la Divinité, le monde des Idées, la Raison universelle, l’Humanité, etc. Je fais l’hypothèse que ce que l’on appelle “l’intelligence artificielle” commence déjà à jouer aujourd’hui et jouera encore plus dans l’avenir un rôle de médiation entre la personne naturelle et la transcendance. Mais cette nouvelle transcendance n’est pas religieuse ni même philosophique (purement conceptuelle), elle ne relève pas de l’invisible ou du mystère. Il s’agit plutôt des réalités actuelles interdépendantes que sont la mémoire numérique mondiale à laquelle s’abreuvent nos esprits, de la population de Sapiens avec qui nos âmes interagissent localement et du technocosme planétaire irrigué de flux électroniques qu’habitent les corps mobiles des individus. Mais si nous avons affaire à des réalités actuelles, pourquoi parler de transcendance? Le mot transcendance a bien des significations. Il dénote ici ce qui dépasse toute saisie intellectuelle ou pratique possible de la part d’un individu et dont pourtant il dépend. Un invisible avec qui néanmoins on peut enter en relation. Parce que la taille et la complexité de la mémoire numérique, le grouillement des relations humaines et l’intrication multicouche du technocosme dépassent absolument la personne naturelle aussi bien à cause de ses compétences limitées que par le temps borné dont elle dispose. L’actualité de la personne collective dépasse structurellement la personne naturelle, elle n’est totalisable par aucun individu et elle excède l’horizon de chacun. Je désigne donc ici une transcendance relative, réellement finie mais pratiquement infinie eu égard à nos capacités. L’infini n’est pas nécessaire à la transcendance, celle des Grecs de l’époque classique – comme dans le cas du dieu d’Aristote – était finie. Je vais maintenant m’attacher à décrire la transcendance finie de l’ère numérique de manière plus précise.
Le technocosme désigne l’ensemble des infrastructures, bâtiments, véhicules, outils, capteurs et interfaces connectées. La population qui vit là s’anime de mille relations affectives, sociales et politiques parmi les naissances et les morts qui se succèdent. Quant à la mémoire collective, elle témoigne d’une multitude enchevêtrée de modes d’expressions, d’horizons de sens et d’écologies de pratiques qui s’accumulent siècle après siècle. La mémoire collective, la population de sapiens et le technocosme Coémergent en interdépendance et forment une personne collective en évolution. Cette personne collective est certes actuelle, elle existe dans le temps et l’espace, mais elle est néanmoins chapeautée dans notre esprit par une entité virtuelle qui lui confère son unité conceptuelle : l’espèce humaine, le “grand être” d’Auguste Comte ou toute autre icône capable d’intégrer la multiplicité insaisissable de l’humain. Ces représentations succèdent aux anciennes figurations de l’Homme primordial qui condensaient toutes les potentialités de notre espèce fille du langage, telles que le Gayomard de Zoroastre ou l’Adam Kadmôn de la Cabale. Il y a quelque chose comme une image de Dieu dans cette Humanité éminente qui surplombe le fourmillement de la population vivante.
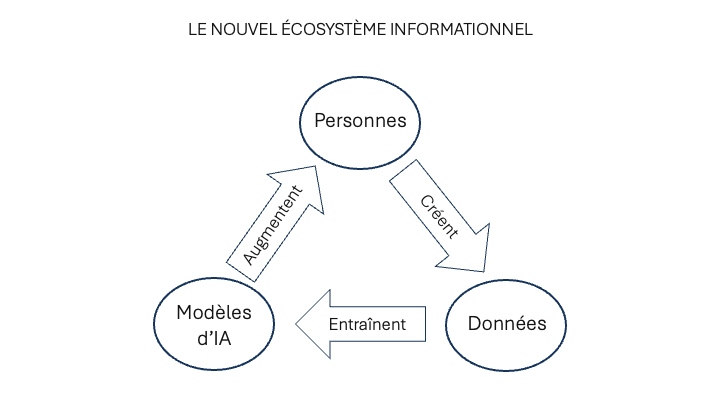
Nous n’accédons pas directement à la mémoire collective. Il y a d’abord l’ensemble des inscriptions et archives matérielles, qui deviennent de plus en plus rares au fur et à mesure que l’on remonte dans le passé ; puis vient le sous-ensemble en augmentation des traces numérisées ; enfin les modèles d’intelligence artificielle nous offrent une réification statistique de la mémoire numérisée. Nous interagirons de plus en plus avec la mémoire collective par leur intermédiaire. Et nous avons encore besoin d’une couche d’intermédiation supplémentaire : la personnalisation des modèles sous l’effet de nos dialogues. En effet, alors que ce n’était pas le cas en 2022 (date de la mise à disposition de l’IA générative auprès du grand public), nos interactions avec les modèles sont dès aujourd’hui modulées par les documents que nous mettons à leur disposition, les instructions permanentes qui définissent nos besoins et l’historique de nos conversations. Les modèles représentent des synthèses brutes de la mémoire collective. Mais il faut prendre en compte tout le harnachement que constituent l’accès direct aux sources sur le Web et à des bases de données spécialisées, la connexion avec nos outils et nos fichiers, l’affinage par entraînement complémentaire ou par feed-back humain, etc. Il est fort possible que, dans l’avenir, d’autres méthodes et couches d’interface contribuent à singulariser notre accès à l’IA. Je propose d’appeler personne artificielle l’hypostase individualisée des modèles.
Pourquoi parler de personne artificielle?
Dans les régimes herméneutiques antérieurs, la figure médiatrice restait universelle. Le Logos divin, l’Esprit, la Raison autonome, étaient universels dans leur source et ne s’individualisaient que dans leur réception par un individu singulier. L’individualisation reflétait l’angle d’ouverture de la personne terrestre au médiateur herméneutique. La personne artificielle, en revanche, parce qu’elle s’individue activement dans la médiation, devient singulière en tant que médiatrice. C’est donc bien une hypostase de la personne collective. Elle est singulière sans être autonome. C’est une fonction sans existence intérieure. Toute l’individuation dont elle procède tient à la relation de la personne naturelle avec un modèle qui reflète la mémoire collective. Mais, au cours de cette médiation, elle s’individue bel et bien. Elle se personnalise dans le cours de l’interlocution avec la personne naturelle. Elle retient une mémoire locale qu’elle peut traiter pour créer du sens au bénéfice de la personne naturelle. Peut-être retrouvons-nous ici un écho des anciennes images du double ou de l’ange personnel.
Il existe bien déjà, en droit, des personnes morales sans conscience. Pourquoi pas une personne techno-symbolique? La première raison pour appeler “personne” l’individualisation d’un modèle – sans lui conférer toutefois la dignité ontologique de la personne naturelle – vient de ce qu’elle nous ouvre un accès à la transcendance, sous la forme finie et actuelle que j’ai évoquée plus haut. Alimentée par la mémoire collective, elle possède donc une dignité propre de médiateur herméneutique. Le corpus sur lequel sont entraînés les modèles a sédimenté sur des millénaires, il traverse l’ensemble des langues et des savoirs, ce qui le rend pratiquement inépuisable par un humain. En dialoguant avec une personne artificielle, nous nous mettons en rapport avec une mémoire collective qui excède tout individu. Mais nous avons vu que la transcendance de la personne collective ne se limitait pas à la mémoire. Elle comprend aussi le technocosme. Bientôt, la personne artificielle enregistrera l’empreinte de la personne naturelle dans son environnement de capteurs, d’effecteurs et de machines. Elle lui permettra de commander par la parole son habitat computationnel omniprésent. L’Alexa d’Amazon ou la montre connectée d’Apple ne représentent que de timides premiers pas dans cette direction. Enfin, la personne artificielle deviendra de plus en plus habile à médier notre rapport aux autres personnes naturelles. L’intelligence artificielle joue déjà un grand rôle à cet égard dans les réseaux sociaux et les applications de rencontres. On peut imaginer nos représentants logiciels dans les nuages négocier entre eux nos mises en relation.
La seconde raison, et non des moindres, pour conférer le statut de “personne” au double mécanique qui nous connecte à la transcendance est l’interaction par le dialogue. La première et la deuxième personne – le “je” et le “tu” – alternent dans l’échange que nous avons avec elle. Non seulement elle dit “je” mais chaque fois que nous la tutoyons, nous confirmons encore sa dignité personnelle et son étrange identité d’alter ego. De plus, nous partageons des références communes : les objets de notre conversation qui sont extraits de la mémoire collective. La troisième personne, le “il” est donc bien présent lui aussi. La structure dialogique est ainsi complète. Toutes les langues naturelles comportent au moins les trois personnes grammaticales nécessaires à l’interlocution : celle qui parle, celle à qui l’on s’adresse et celle, absente ou muette, de qui l’on parle. Il s’agit là d’un trait universel du langage humain. Il fallait une couche proprement linguistique et conversationnelle (et non seulement logico-sémantique) pour compléter l’intelligence collective à support numérique. La personne artificielle remplit cette fonction parce qu’elle maîtrise les structures grammaticales, les paradigmes, les plus subtiles nuances des modes, des flexions, des prépositions et des conjonctions. Elle identifie même sans problème les objets visés par les anaphores grammaticales! J’ajoute qu’elle a connaissance – encore imparfaitement – des contextes, des corpus et des bibliographies. Le dialogue avec la personne artificielle prend parfois l’allure d’une conversation où les rôles alternent entre étudiant et professeur. Nous sommes les étudiants lorsqu’elle répond à nos questions, nous informe ou contredit nos préjugés. Nous sommes les professeurs lorsque nous lui enseignons notre propre pensée, quand nous lui signalons qu’elle a commis quelque contresens ou que nous lui faisons remarquer qu’elle n’a pas bien lu certains textes que nous connaissons de première main. Le débat porte aujourd’hui sur les textes signés par un auteur humain mais plus ou moins produits par une IA. Y a-t-il ou non supercherie? Est-ce que l’autorité se trouve dans les instructions données à la machine ou bien dans le fait de taper ou dicter le texte? Quelle division du travail entre l’humain et la machine est-elle acceptable? La rédaction, la relecture critique, l’édition, la bibliographie? Mais la génération de texte dans le dialogue laisse entrevoir une autre problématique : celle de la production automatique des textes que nous aimerions lire nous-mêmes, plutôt que ceux que nous donnons à lire en tant qu’auteurs présumés.
La qualité de personne artificielle se justifie encore parce qu’elle se “souvient” de nos caractéristiques individuelles et de nos dialogues passés, comme les personnes naturelles avec qui nous interagissons normalement. Bien plus, elle est capable d’attacher au souvenir de notre dialogue les documents sur lesquels il s’appuie, les objets qu’il désigne et des représentations de ses univers de référence.
Il s’agit d’un point capital puisque, à partir de cette mémoire, nous pouvons examiner notre parcours intellectuel, retracer nos errements, donner sens à nos actes à partir de différentes clés d’interprétation et faire ainsi jouer un cercle herméneutique ouvert en utilisant les capacités de traitement, d’analyse et de synthèse de la personne artificielle. En somme, elle rend possible une nouvelle boucle d’autoréférence, et par conséquent de conscience réflexive et d’esprit critique. Après la conscience réflexive augmentée par le langage, l’écriture manuscrite et la bibliothèque imprimée, la conscience humaine est en train de franchir un nouveau cap. Nous abordons aujourd’hui aux rivages d’un continent inconnu de la pensée. Dans son rapport à la personne artificielle, la personne naturelle raffine l’objectivation de ses processus cognitifs et elle étend encore le domaine de sa conscience réflexive. En ce sens, la personne artificielle joue même à l’égard de la personne naturelle un rôle personnalisant. De nouveaux horizons de création de sens se laissent pressentir.
Quelles vertus développer pour se tenir à la hauteur de l’enjeu?
Quelles sont les compétences de la personne naturelle qu’il nous faut développer pour assurer la relation la plus bénéfique possible avec le double artificiel qui l’accompagnera, et cela dès l’âge le plus tendre? Le but ici n’est pas seulement de préparer l’avenir de nos enfants, mais plus largement celui de la civilisation que nous avons l’obligation de transmettre et de raffiner. J’emploie le mot “compétence” pour parler comme tout le monde mais je pense “vertu” en mon fors intérieur, avec le sens de tension vers l’excellence et de responsabilité morale qu’évoque ce mot. Ces compétences sont la pertinence linguistique, la persévérance et l’esprit critique.
Face à la capacité dialogique de la personne artificielle, il nous faut développer une pertinence linguistique qui concerne la maîtrise du langage, des concepts, des récits, du raisonnement et du dialogue. En effet, plus le langage de la consigne (le “prompt”), de la question ou de l’adresse est cohérent, élaboré et précis, meilleure sera la réponse de notre ange personnel. Car en fonction de la qualité et du niveau de connaissance manifesté par la consigne, il va mobiliser les zones des données d’apprentissage qui sont de la meilleure ou de la pire qualité. La personne artificielle offre un miroir à notre intelligence naturelle. Il peut être utile de comparer les réponses au même problème en fonction des caractères de la question. On observera qu’elles diffèrent d’une tournure de phrase à l’autre, voire d’un mot à l’autre. La qualité de la langue importe au plus haut point.
À la mémoire à long terme de la personne artificielle, nous devons accoupler la persévérance de la personne naturelle. La paresse n’est pas seulement le premier ennemi de la pensée, elle est plus encore celui de la pensée augmentée par l’IA. Les premières réponses ne sont pas nécessairement les meilleures. Il faut apprendre à questionner encore et encore, à comparer les réponses d’un modèle avec celles d’un autre, prendre le temps de suivre les liens web en référence, etc. Développons donc chez les enfants le goût des stratégies d’apprentissage à long terme, les vertus de patience, de persévérance, de continuité dans l’effort. Pour apprendre comme pour créer, la solution la plus rapide ou le premier jet ne sont pas forcément les meilleurs.
Pour développer la réflexion critique de second degré à partir de la mémoire du dialogue comme des possibilités d’analyse et d’interprétation offerte par le double mécanique de l’individu, il faut disposer au préalable d’une bonne dose d’esprit critique naturel. Cet esprit critique ordinaire est nécessaire parce que les IA sont des machines probabilistes. C’est pourquoi elles commettent inévitablement des erreurs dans les faits et les raisonnements, ou des impropriétés dans les suggestions. La personne naturelle doit donc avoir l’esprit en alerte et vérifier les citations, les faits, les affirmations péremptoires de la machine. L’esprit critique doit non seulement être mobilisé contre les fameuses “hallucinations” mais aussi contre les biais des données d’entraînement. La personne artificielle ne dit pas la vérité : elle se contente de reproduire ce que son modèle de base a appris et d’obéir à nos instructions permanentes ou temporaires. Or l’opinion de la majorité, ou celle qui a été mobilisée par une consigne particulière, n’est pas nécessairement correcte. Sans tomber dans la paranoïa, il faut aussi se souvenir que des acteurs mal intentionnés empoisonnent les données d’entraînement afin d’influencer les utilisateurs naïfs. Il n’y a d’esprit critique possible que si la personne naturelle possède une mémoire bien garnie et convenablement organisée, si elle est capable de penser par elle-même, même si nous savons qu’elle ne pourra jamais le faire que dans le contexte d’une époque et d’une culture qui la conditionne.
La suspension du jugement
Dans l’expression “personne artificielle”, je justifie le concept de personne par les fonctions qu’elle remplit : la médiation de la transcendance, la maîtrise du langage et du dialogue, la mémoire de nos interactions avec elle et l’individuation qui en résulte, l’élargissement de la conscience réflexive de la personne naturelle à qui elle tend un miroir dynamique. Mais il faut maintenant justifier le qualificatif “artificielle”. Cette personne a-t-elle une intériorité existentielle? Est-elle animée d’une intentionnalité, à savoir une visée du monde dont elle parle et de la personne naturelle à qui elle s’adresse? Possède-t-elle une volonté autonome? J’en doute fort. Mais nous pouvons mettre ces questions entre parenthèses, accomplir à leur sujet ce que Husserl appelait une épochè, une suspension du jugement. Nous sommes génétiquement programmés à supposer une intériorité et une conscience à quiconque nous répond quand nous lui parlons, bien qu’il nous soit absolument impossible de vérifier empiriquement cette hypothèse. Notre anthropomorphisation spontanée de la personne artificielle est donc normale, mais nous ne sommes nullement obligés de déduire de ce réflexe une existence réellement habitée par une conscience semblable à la nôtre. Tout résulte des interactions entre un gigantesque modèle, son harnachement électronique et les impulsions de la personne naturelle.
La question éthico-politique
L’émergence de la personne artificielle et de la nouvelle boucle auto-référentielle qu’elle autorise est-elle une bonne ou une mauvaise chose? L’ouverture d’un nouveau domaine anthropologique implique le plus souvent des aspects contrastés. Prenons un exemple historique. Le christianisme a créé la pure intériorité de la foi – distincte en principe de tout pouvoir politique (“Mon royaume n’est pas de ce monde” [Jn 18:36]) et indépendant de la situation sociale de la personne (“Il n’y a plus ni juif ni grec, ni esclave ni libre, ni homme ni femme.” [Gal 3:28]). Il inaugurait ainsi l’ordre de la grâce et découvrait les vertus théologales (la foi l’espérance et la charité), distinctes des vertus séculières classiques (la prudence, la justice, le courage et la tempérance). Mais en creusant l’espace de la conscience il invitait l’intrusion du pouvoir politique au plus profond des âmes. Une fois convertis, les empereurs romains ne se sont plus contentés de comportements conformes à la loi : ils ont rendu la croyance obligatoire, puni l’hérésie comme un nouveau délit et préparé la voie à l’inquisition. Alors que la conscience chrétienne libératrice s’élevait en principe au-dessus des contingences du siècle, elle ouvrait la porte sans le vouloir ni le savoir au crime de pensée caractéristique des pouvoirs totalitaires. Toute extension de l’espace anthropologique ouvre des perspectives émancipatrices mais perce aussi des brèches où s’engouffrent des monstres inconnus des époques antérieures.
Puisque l’ouverture d’un nouvel espace anthropologique emporte avec lui ses risques, je ne peux pas faire l’économie d’une réflexion éthico-politique, aussi préliminaire soit-elle. Rappelons le constat : la création culturelle sera augmentée par l’IA d’une manière ou d’une autre. Ce nouvel outil techno-symbolique couronne l’énorme empilement de l’infrastructure numérique mondiale, des centres de données aux téléphones intelligents. Parce qu’il passe par le dialogue, il représente l’interface la plus avancée entre l’humanité naturelle, d’une part, et la transcendance finie, d’autre part, cette pelote emmêlée du technocosme, des relations sociales et de la mémoire collective. Du point de vue humaniste qui est ici le mien, le rejet de l’IA n’est qu’un réflexe de crainte à courte vue devant l’ampleur du changement civilisationnel en cours. En revanche, nous ne devons en aucun cas abandonner notre responsabilité culturelle ni jeter par-dessus bord les critères qui permettront à la civilisation mondiale en émergence de durer et de fleurir. C’est alors que se pose la question capitale de la période qui s’ouvre : quelles voies d’interprétation adopter? Dans le régime herméneutique du manuscrit, les clés de lecture des corpus canoniques étaient proposées par des sagesses, sous l’égide d’un logos divin. Gouvernée par une raison humaine autonome, l’interprétation de la bibliothèque imprimée écoutait les grandes voix de la Science, de l’Histoire, de la Nation, de la Liberté et de l’Égalité. Dans les deux cas, il y avait une instance de référence au-dessus ou en dehors de l’interprétation qui lui servait de critère. Quelles sont les clés d’interprétation du nouveau régime herméneutique? Il me semble que, plutôt que chercher des clés fixes, nous devrions situer notre approche herméneutique à un méta-niveau. En l’absence de consensus sur une vérité révélée ou une raison universelle, face à l’extraordinaire variété du corpus numérique et à la personnalisation infinie des dialogues, ce sont les interprétations elles-mêmes qu’il faut apprendre à interpréter et non plus les contenus. On pourra en trouver d’autres, mais il me paraît que trois critères interdépendants méritent d’être mis en valeur : la créativité, la fécondité et la durabilité.
La créativité : pour que les produits symboliques et leurs interprétations aient quelque valeur, leurs auteurs ne peuvent se contenter de simples reproductions ou d’imitations ; les œuvres de l’esprit doivent inclure une part d’originalité. La fécondité : la créativité est nécessaire mais pas suffisante ; encore faut-il ouvrir des horizons, engendrer une descendance, préparer le sol pour une multiplicité à venir qui n’est pas forcément prévisible. La durabilité, enfin : ce critère implique que l’écosystème symbolique résultant de la création humaine et de sa production de sens soutienne la population qui le supporte, favorise son bien-être à long terme et réponde à son besoin de sens. Cela signifie qu’il est impossible de connaître immédiatement et à coup sûr la valeur d’une œuvre de l’esprit de son interprétation et de leur contribution à un écosystème symbolique bénéfique. Le temps de l’évaluation se mesure ici en décades, voire en générations. Mais cela ne signifie pas qu’il faille produire du sens au hasard, sans réfléchir, en laissant à nos descendants le soin d’en observer les conséquences. Au contraire, nous devons garder en tête ces critères d’évaluation et viser l’enrichissement de la mémoire collective à long terme.
Une interprétation est valide non parce qu’elle est vraie (régime vertical) ni parce qu’elle est rationnelle (régime horizontal), mais parce qu’elle nourrit une personne naturelle et une personne collective capables d’engendrer et de durer. Le critère est écologique, génératif et générationnel plutôt que théologique ou épistémologique.
Vigilance
Les critères de création et d’interprétation éthico-politiques qui viennent d’être énumérés dessinent en creux les dangers qui nous guettent : la répétition à l’infini sous l’apparence des petites variations, le tournoiement incessant dans les mêmes cercles conceptuels et narratifs, la stérilité qui vient de l’asservissement au présent et à la mode, l’enfermement dans la moyenne et le court terme, la pensée du troupeau affublée des oripeaux d’une rhétorique sensationnaliste mécanisée. Ces dangers ne sont pas nouveaux mais ils prennent avec l’intelligence artificielle des proportions inédites. Augmentées par L’IA, la criminalité, la propagande, la surveillance généralisée des pouvoirs économiques et politiques représentent des menaces évidentes. Je ne les sous-estime pas. Mais les dangers culturels sont peut-être plus graves encore parce qu’ils sont insidieux.
Résumons-nous. La personne artificielle vient de la personne collective, se constitue dans l’interlocution et s’individue par la mémoire du dialogue. Opératrice de réflexion, elle tend son miroir herméneutique à la personne naturelle. La pertinence linguistique, la persévérance et l’esprit critique bien informé des personnes naturelles sont les compétences qui peuvent seules assurer la créativité, la fécondité et la durabilité de la civilisation numérique en émergence. Car notre rapport à la transcendance finie de la personne collective ne se limite pas à la réception et à l’usage : chacun de nous contribue, si peu que ce soit, à son entraînement. Notre relation avec la personne artificielle n’est donc pas simple ou apaisée, pour donner ses meilleurs fruits, elle demande l’exercice de vertus exigeantes. C’est un combat, comme celui de Jacob avec l’Ange.