Entretien avec Prof. Dr. Pierre Lévy
Voir la publication en portugais et en anglais ici: https://www.pucpress.com.br/wp-content/uploads/2025/05/CADERNOS_DO_CONTEMPORANEO_0000_P.pdf

Q1- Face à l’hyper-connectivité croissante chez les jeunes, de nombreux experts parlent de solitude et de ce qu’ils appellent “l’âge des passions tristes”. Comment voyez-vous cette dichotomie entre proximité et distance que la technologie provoque dans les relations humaines?
R1 – L’hyper-connectivité ne concerne pas seulement les jeunes, elle est partout. Un des facteurs principaux de l’évolution culturelle réside dans le dispositif matériel de production et de reproduction des symboles, mais aussi dans les systèmes logiciels d’écriture et de codage de l’information. Notre intelligence collective prolonge celle des espèces sociales qui nous ont précédées, et particulièrement celle des grands singes. Mais l’usage du langage – et d’autres systèmes symboliques – tout comme la force de nos moyens techniques nous a fait passer du statut d’animal social à celui d’animal politique. Proprement humaine, la Polis émerge de la symbiose entre des écosystèmes d’idées et les populations de primates parlants qui les entretiennent, s’en nourrissent et s’y réfléchissent. L’évolution des idées et celles des peuplements de Sapiens se déterminent mutuellement. Or le facteur principal de l’évolution des idées réside dans le dispositif matériel de reproduction des symboles. Au cours de l’histoire, les symboles (avec les idées qu’ils portaient) ont été successivement pérennisés par l’écriture, allégés par l’alphabet et le papier, multipliés par l’imprimerie et les médias électriques. Les symboles sont aujourd’hui numérisés et calculés, c’est-à-dire qu’une foule de robots logiciels – les algorithmes – les enregistrent, les comptent, les traduisent et en extraient des patterns. Les objets symboliques (textes, images fixes ou animées, voix, musiques, programmes, etc.) sont non seulement enregistrés, reproduits et transmis automatiquement, ils sont aussi générés et transformés de manière industrielle. En somme, l’évolution culturelle nous a menés au point où les écosystèmes d’idées se manifestent sous la forme de données animées par des algorithmes dans un espace virtuel ubiquitaire. Et c’est dans cet espace que se nouent, se maintiennent et se dénouent désormais les liens sociaux. Avant de critiquer ou de déplorer, il faut d’abord reconnaître les faits. Les amitiés des jeunes gens ne peuvent plus se passer des médias sociaux ; les couples se rencontrent sur internet, par exemple sur des applications comme Tinder (voir la Figure 1) ; les familles restent connectées par Facebook ou d’autres applications comme WhatsApp ; les espaces de travail ont basculé dans l’électronique avec Zoom et Teams, particulièrement depuis la pandémie de COVID ; la diplomatie se fait de plus en plus sur X (ex Twitter), etc. On ne reviendra pas en arrière. D’un autre côté, on ne se déplace pas moins de manière physique : en témoignent les embouteillages monstrueux de Sao Paulo et Rio de Janeiro. Dans le même ordre d’idées, la tendance sur les dix dernières années – époque de croissance exponentielle des connexions Internet – montre aussi une augmentation du nombre de passagers aériens, qui continue une tendance séculaire, et cela malgré une baisse importante durant la pandémie de COVID-19.
Je me sentais bien seul lorsque, jeune étudiant, je suis arrivé à Paris du sud de la France, pour faire mes études universitaires. C’était en 1975 et il n’y avait pas d’internet. Les seniors qui vivent seuls et que leurs enfants ne visitent pas doivent-ils blâmer Internet? Le problème de la solitude et de la désagrégation des liens sociaux est bien réel. Mais c’est une tendance déjà ancienne, qui tient à l’urbanisation, aux transformations de la famille et à bien d’autres facteurs. J’invite vos lecteurs à consulter les nombreux travaux sur la question du “capital social” (la quantité et à la qualité des relations humaines). L’internet n’est qu’un des nombreux facteurs à considérer sur cette question.
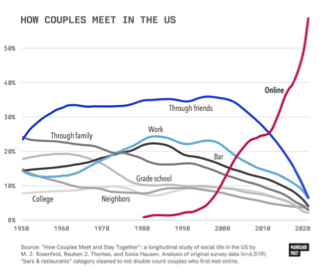
Figure 1
Q2- Dans vos livres “Collective Intelligence: For an anthropology of cyberspace” (1994) et “Cyberculture: The Culture of the Digital Society” (1997), vous soutenez qu’Internet et les technologies numériques développent l’intelligence collective, permettant de nouvelles formes de collaboration et de partage des connaissances. Cependant, on craint de plus en plus que l’utilisation excessive des médias sociaux et des technologies numériques soit associée à une distraction et à un retard d’apprentissage chez les jeunes. Comment voyez-vous cette apparente contradiction entre le potentiel des technologies à renforcer l’intelligence collective et les effets négatifs qu’elles peuvent avoir sur le développement cognitif et éducatif des jeunes?
R2- Je n’ai jamais soutenu qu’Internet et les technologies numériques, par eux-mêmes et comme si les techniques étaient des sujets autonomes, développent l’intelligence collective. J’ai soutenu que le meilleur usage que nous pouvions faire d’internet et des technologies numériques était de développer l’intelligence collective humaine, ce qui est bien différent. Et c’est d’ailleurs toujours ce que je pense. L’idée d’un « espace du savoir » qui pourrait se déployer au-dessus de l’espace marchand est un idéal régulateur pour l’action, non une prédiction de type factuel. Lorsque j’ai rédigé L’Intelligence Collective – de 1992 à 1993 – moins de 1% de l’humanité était branchée sur l’Internet et le Web n’existait pas. Vous ne trouverez nulle part le mot « web » dans l’ouvrage. Or nous avons aujourd’hui – en 2024 – largement dépassé les deux tiers de la population mondiale connectée à l’Internet. Le contexte est donc complètement différent mais le changement de civilisation que je prévoyais il y a 30 ans semble évident aujourd’hui, bien qu’il faille attendre normalement plusieurs générations pour confirmer ce type de mutation. A mon sens, nous ne sommes qu’au commencement de la révolution numérique.
Quant à l’augmentation de l’intelligence collective, de nombreux pas ont été franchis pour mettre les connaissances à la portée de tous. Wikipédia est l’exemple classique d’une entreprise qui fonctionne en intelligence collective avec des millions de contributeurs bénévoles de tous les pays et des groupes de discussion entre experts pour chaque article. Il y a près de sept millions d’articles en anglais, deux millions et demi d’articles en français et plus d’un million d’articles en portugais. Wikipédia est consulté par plusieurs dizaines de millions de personnes par jour et plusieurs milliards par an! Le logiciel libre – maintenant largement adopté et diffusé, y compris par les grandes entreprises du Web – est un autre grand domaine où l’intelligence collective est au poste de commande. Parmi les plus utilisés des logiciels libres citons le système d’exploitation Linux, les navigateurs Mozilla et Chromium, la suite Open Office, le serveur http Apache (qui est le plus utilisé sur Internet), le système de contrôle des versions GIT, la messagerie Signal, et bien d’autres qu’il serait trop long de citer. J’ajoute que les bibliothèques et les musées numérisés, comme les articles scientifiques en accès libre et les sites de type ArXiv.org, sont monnaie courante, ce qui transforme les pratiques de recherche et de communication scientifique. Tout le monde peut aujourd’hui publier des textes sur son blog, des vidéos et des podcasts sur YouTube ou d’autres sites, ce qui n’était pas le cas il y a trente ans. Les médias sociaux permettent d’échanger des nouvelles et des idées très rapidement, comme on le voit par exemple sur LinkedIn ou X (ex Twitter). Internet a donc réellement permis le développement de nouvelles formes d’expression, de collaboration et de partage des connaissances. Beaucoup reste à faire. Nous ne sommes qu’au tout début de la mutation anthropologique en cours.
Bien entendu, il nous faut prendre en compte les phénomènes d’addiction aux jeux vidéos, aux médias sociaux, à la pornographie en ligne, etc. Mais depuis plus de trente ans, la majorité des journalistes, des hommes politiques, des enseignants et de tous ceux qui font l’opinion ne cessent de dénoncer les dangers de l’informatique, puis de l’Internet et maintenant de l’intelligence artificielle. Je ne ferais rien de très utile si j’ajoutais mes lamentations aux leurs. J’essaye donc de faire prendre conscience d’une mutation de civilisation de grande ampleur qu’on n’arrêtera pas et d’indiquer les meilleurs moyens de diriger cette grande transformation vers les finalités les plus positives pour le développement humain. Ceci dit, il est clair que les phénomènes d’addiction trouvent partiellement leur source dans notre dépendance à l’architecture sociotechnique toxique des grandes compagnies du Web, qui utilise la stimulation dopaminergique et les renforcements narcissiques de la communication numérique pour nous faire produire toujours plus de données et vendre plus de publicité. Malheureusement la santé mentale des populations adolescentes est peut-être une des victimes collatérales des stratégies commerciales de ces grandes entreprises oligopolistiques. Comment s’opposer à la puissance de leurs centres de calcul, à leur efficacité logicielle et à la simplicité de leurs interfaces? Il est plus facile de poser la question que d’y répondre. En plus de la biopolitique évoquée par Michel Foucault, il faut maintenant considérer une psychopolitique à base de neuromarketing, de données personnelles et de gamification du contrôle. Les enseignants doivent avertir les étudiants de ces dangers et les former à la pensée critique.
Q3- Avec le phénomène des “bulles connectives”, où les réseaux sociaux ont tendance à renforcer des croyances et des idées préexistantes, limitant les contacts avec des perspectives différentes, comment voyez-vous l’évolution des liens sociaux à mesure qu’Internet et les plateformes numériques continuent de se développer? Ce type de segmentation pourrait-il affaiblir l’intelligence collective que vous prônez, ou y a-t-il encore de la place pour des connexions plus larges et plus collaboratives à l’avenir?
R3 – Il est clair que si l’on se contente de « liker » instinctivement ce que l’on voit défiler et de réagir émotionnellement aux images et aux messages les plus simplistes, le bénéfice cognitif ne sera pas très grand. Je ne me pose pas en modèle à suivre absolument, je voudrais seulement donner un exemple de ce qu’il est possible de faire si l’on un peu d’imagination et que l’on est prêt à remettre en cause l’inertie des institutions. Lorsque j’étais professeur en communication numérique à l’Université d’Ottawa, je forçais mes étudiants à s’inscrire sur Twitter, à choisir une demi-douzaine de sujets intéressants pour eux et à dresser des listes de comptes à suivre pour chaque sujet. Quelque soit le thème – politique, science, mode, art, sports, etc. – ils devaient construire des listes équilibrées comprenant des experts ou des partisans d’avis opposés afin d’élargir leur sphère cognitive au lieu de la restreindre. Sur les médias sociaux les plus courants comme Facebook et LinkedIn, il est possible de participer à un grand nombre de communautés spécialisées dans des domaines culturels (histoire, philosophie, arts) ou professionnels (affaires, technologie, etc.) afin de se tenir au courant et de discuter avec des experts. Les groupes de discussion locaux par villages ou quartiers sont aussi très utiles. Tout est question de méthode et de pratique. Il faut se détacher du modèle des médias de masse (journaux papier, radio, télévision) dans lequel des récepteurs passifs consomment une programmation faite par d’autres. C’est à chacun de se bricoler sa propre programmation et de se construire ses réseaux personnels d’apprentissage.
Avant l’imprimerie, on ne parlait qu’avec les gens de sa paroisse. Dans les années soixante du XXe siècle on n’avait le choix qu’entre deux ou trois chaines de télévision et deux ou trois journaux. Aujourd’hui nous avons accès à une énorme diversité de sources en provenance de tous les pays et de tous les secteurs de la société. Les enseignants doivent alphabétiser les étudiants, leur apprendre les langues étrangères, leur donner une bonne culture générale et les guider dans ce nouvel univers de communication.
Q4- Actuellement, il y a un débat croissant sur les effets négatifs de la technologie sur la santé mentale des jeunes, en mettant l’accent sur des problèmes tels que l’anxiété, la dépression et l’isolement social. Considérant le rôle central que jouent les technologies numériques dans notre société, comment comprenez-vous cette relation entre l’usage intensif des technologies et l’augmentation des problèmes de santé mentale chez les jeunes? Existe-t-il un moyen d’équilibrer les avantages de la technologie avec la nécessité de préserver le bien-être mental?
R4 – Le problème de la santé mentale des jeunes est bien sûr tout à fait réel, mais il serait réducteur de l’attribuer uniquement aux médias sociaux. Néanmoins je vais essayer d’énumérer quelques problèmes psychologiques qui naissent de l’usage des Technologies numériques.
Il y a d’abord la transformation de l’autoréférence subjective, qui risque de mener à des problèmes de type schizophrénique. Notre champ d’expérience est médiatisé par le support numérique : la boucle d’autoréférence est plus large que jamais. Nous interagissons avec des personnes, des robots, des images, des musiques par le biais de plusieurs interfaces multimédias : écran, écouteurs, manettes… Notre expérience subjective est contrôlée par les algorithmes de multiples applications qui déterminent en boucle (si nous n’avons pas appris à les maîtriser) notre consommation de données et nos actions en retour. Notre mémoire est dispersée dans de nombreux fichiers, bases de données, en local et dans le cloud… Lorsqu’une grande partie de nous-mêmes est ainsi collectivisée et externalisée, le problème des limites et de la détermination de l’identité devient prépondérant. À qui appartiennent les données me concernant, qui les produit ?
Le problème du narcissisme est particulièrement évident sur Instagram et les applications même genre. Notre ego est nourri par l’image que les autres nous renvoient dans le médium algorithmique. L’obsession de l’image atteint des proportions inquiétantes. Combien d’abonnés, combien de likes, combien d’impressions? Pour ceux qui ont sombré dans ce gouffre, la valeur de l’être n’est plus que dans le regard de l’autre. Avant d’être un problème de santé mentale il s’agit d’un problème de sagesse élémentaire.
A l’opposé du narcissisme, nous avons une tendance vers l’autisme. Ici le moi est enfermé dans sa vie intérieure, mais alimenté par des sources d’information en ligne. Le code ou certains aspects de la culture populaire deviennent obsessionnels. C’est le domaine des geeks, des Otakus et des joueurs compulsifs. Il est évidemment malsain de se passer de toute vie sociale en chair et en os.
Il existe un problème de santé mentale si les affects sont constamment euphoriques, ou constamment dysphoriques, ou si un objet exclusif devient addictif. En effet, Internet peut nous rendre dépendants à certains objets (actualités, séries, jeux, pornographie) ou à certaines émotions, qu’elles soient positives (contenu « feel-good » de type chats mignons, danse, humour, etc.) ou négatives (actualités catastrophiques, « doom scrolling ») de manière déséquilibrée. On peut aussi se demander dans quelle mesure il est bon que le langage corporel soit entièrement remplacé par des emojis, des mèmes, des images, des avatars, etc.
L’addiction est créée par l’excitation (dopamine) et la satisfaction (endorphine) que nous voulons reproduire sans arrêt. Or, comme je l’ai dit plus haut, les modèles d’affaire des grandes entreprise du web qui sont axés sur l’engagement (sécrétion de dopamine-endorphine) conduisent presque inévitablement à la dépendance si les utilisateurs ne font pas attention. L’intensité d’engagement élevée pendant de trop longs moments mène inévitablement à une dépression.
Le contrôle des impulsions (agressivité, par exemple) est plus difficile dans les médias sociaux que dans la vie réelle parce que nos interlocuteurs ne se trouvent pas en face de nous. La « gestion des comportements toxiques » est d’ailleurs un problème majeur dans les jeux en ligne et les médias sociaux.
En somme, il faut être vigilant, prévenir les jeunes utilisateurs des dangers encourus et ne pas commettre d’excès.
Q5 – Certains prédisent que les générations futures pourraient ne plus jamais fréquenter l’école. Comment voyez-vous l’avenir de l’éducation dans un monde de plus en plus hyperconnecté et dominé par la technologie?
R5 – Je ne crois pas que l’école va disparaître. Mais elle doit se transformer. Il faut prendre les étudiants où ils sont et de préférence utiliser les produits grands public auxquels ils sont habitués pour en faire quelque chose d’utile sur le plan de l’apprentissage. Les élèves sont des « digital natives » mais cela ne veut pas dire qu’ils ont une véritable maîtrise des outils numériques. Il faut non seulement développer la littéracie numérique mais la littéracie tout court, qui en est indissociable. Je suis un grand partisan de la lecture des classiques et de la culture générale, qui est indispensable pour former l’esprit critique.
Pour revenir à mes propres méthodes pédagogiques, dans les cours que je donnais à l’Université d’Ottawa, je demandais à mes étudiants de participer à un groupe Facebook fermé, de s’enregistrer sur Twitter, d’ouvrir un blog s’ils n’en n’avaient pas déjà un et d’utiliser une plateforme de curation collaborative de données.
L’usage de plateformes de curation de contenu me servait à enseigner aux étudiants comment choisir des catégories ou « tags » pour classer les informations utiles dans une mémoire à long terme, afin de les retrouver facilement par la suite. Cette compétence leur sera fort utile dans le reste de leur carrière.
Les blogs étaient utilisés comme supports de « devoir final » pour les cours gradués (c’est-à-dire avant le master), et comme carnets de recherche pour les étudiants en maîtrise ou en doctorat : notes sur les lectures, formulation d’hypothèses, accumulation de données, première version d’articles scientifiques ou de chapitres des mémoires ou thèses, etc. Le carnet de recherche public facilite la relation avec le superviseur et permet de réorienter à temps les directions de recherche hasardeuses, d’entrer en contact avec les équipes travaillant sur les mêmes sujets, etc.
Le groupe Facebook était utilisé pour partager le Syllabus ou « plan de cours », l’agenda de la classe, les lectures obligatoires, les discussions internes au groupe – par exemple celles qui concernent l’évaluation – ainsi que les adresses électroniques des étudiants (Twitter, blog, plateforme de curation sociale, etc.). Toutes ces informations étaient en ligne et accessibles d’un seul clic, y compris les lectures obligatoires numérisées et gratuites. Les étudiants pouvaient participer à l’écriture de mini-wikis à l’intérieur du groupe Facebook sur des sujets de leur choix, ils étaient invités à suggérer des lectures intéressantes reliées au sujet du cours en ajoutant des liens commentés. J’utilisais Facebook parce que la quasi-totalité des étudiants y étaient déjà abonnés et que la fonctionnalité de groupe de cette plateforme est bien rodée. Mais j’aurais pu utiliser n’importe quel autre support de gestion de groupe collaboratif, comme Slack ou les groupes de LinkedIn.
Sur Twitter (maintenant X), la conversation propre à chaque classe était identifiée par un hashtag. Au début, j’utilisais le médium à l’oiseau bleu de manière ponctuelle. Par exemple, à la fin de chaque classe je demandais aux étudiants de noter l’idée la plus intéressante qu’ils avaient retenu du cours et je faisais défiler leurs tweets en temps réel sur l’écran de la classe. Puis, au bout de quelques semaines, je les invitais à relire leurs traces collectives sur Twitter pour rassembler et résumer ce qu’ils avaient appris et poser des questions – toujours sur Twitter – si quelque chose n’était pas clair, questions auxquelles je répondais par le même canal.
Au bout de quelques années d’utilisation de Twitter en classe, je me suis enhardi et j’ai demandé aux étudiants de prendre directement leurs notes sur ce medium social pendant le cours de manière à obtenir un cahier de notes collectif. Pouvoir regarder comment les autres prennent des notes (que ce soit sur le cours ou sur des textes à lire) permet aux étudiants de comparer leurs compréhensions et de préciser ainsi certaines notions. Ils découvrent ce que les autres ont relevé et qui n’est pas forcément ce qui les a stimulés eux-mêmes… Quand je sentais que l’attention se relâchait un peu, je leur demandais de s’arrêter, de réfléchir à ce qu’ils venaient d’entendre et de noter leurs idées ou leurs questions, même si leurs remarques n’étaient pas directement reliées au sujet du cours. Twitter leur permettait de dialoguer librement entre eux sur les sujets étudiés sans déranger le fonctionnement de la classe. Je consacrais toujours la fin du cours à une période de questions et de réponses qui s’appuyais sur un visionnement collectif du fil Twitter. Cette méthode est particulièrement pertinente dans les groupes trop grands (parfois plus de deux cents personnes) pour permettre à tous les étudiants de s’exprimer oralement. Je pouvais ainsi répondre tranquillement aux questions après la classe en sachant que mes explications restaient inscrites dans le fil du groupe. La conversation pédagogique se poursuit entre les cours. Bien entendu, tout cela n’était possible que parce que l’évaluation (la notation des étudiants) était basée sur leur participation en ligne.
En utilisant Facebook et Twitter en classe, les étudiants n’apprenaient pas seulement la matière du cours mais aussi une façon « cultivée » de se servir des médias sociaux. Documenter ses petits déjeuners ou la dernière fête bien arrosée, disséminer des vidéos de chats et des images comiques, échanger des insultes entre ennemis politiques, s’extasier sur des vedettes du show-business ou faire de la publicité pour telle ou telle entreprise sont certainement des usages légitimes des médias sociaux. Mais on peut également entretenir des dialogues constructifs dans l’étude d’un sujet commun. En somme, je crois que l’éducation doit progresser en direction de l’apprentissage collaborative en utilisant les outils numériques.
Q6 – Quelles sont, selon vous, les principales opportunités qu’Internet et les nouveaux outils d’IA peuvent apporter au domaine de l’éducation? Compte tenu de l’avancée accélérée des technologies numériques et de l’intelligence artificielle, comment voyez-vous évoluer le rôle de l’enseignant dans les années à venir?
R6 – Concernant l’intelligence artificielle (par exemple ChatGPT, MetaAI, Grok ou Gemini, qui sont tous gratuits et assez bons), elle peut être fort utile comme mentor des étudiants ou comme encyclopédie de premier recours, pour donner des réponses et des orientations très rapidement. Les étudiants utilisent déjà ces outils, il ne faut donc pas interdire leur usage mais, une fois encore, le cultiver, le faire passer à un niveau supérieur. Comme l’IA générative est de nature statistique et probabiliste, elle fait régulièrement des erreurs. Il faut donc toujours vérifier les informations sur de véritables encyclopédies, des moteurs de recherche, des sites spécialisés ou même… dans une bibliothèque! J’ajoute que plus on est cultivé et mieux on connaît un sujet et plus l’usage des IA génératives est fructueux, car on est alors capable de poser de bonnes questions et de demander des informations complémentaires lorsque l’on sent que quelque chose manque. L’IA n’est pas un substitut à l’ignorance, elle donne au contraire une prime à ceux qui ont déjà de bonnes connaissances.
Utiliser les IA génératives pour rédiger à notre place ou faire des résumés de texte au lieu de lire des livres n’est pas une bonne idée, au moins dans un usage pédagogique. Sauf bien sûr si cette pratique est encadrée par l’enseignant afin de stimuler l’esprit critique et le goût du beau style. Au moins en 2024, les textes de l’IA sont généralement redondants, banals et facilement reconnaissables. De plus, leurs résumés de documents ne parviennent pas à saisir ce qu’il y a de plus original dans un texte, puisqu’ils n’ont pas été entraînés sur des idées rares mais au contraire sur l’avis général que l’on retrouve partout. On apprend à penser en lisant et en écrivant en personne : donc les IA sont de bons auxiliaires mais en aucun cas de purs et simples remplacements de l’activité intellectuelle humaine.
Q-7- On craint de plus en plus que l’IA puisse supprimer de nombreux emplois à l’avenir. Comment pensez-vous que cela affectera le marché du travail et quelles pourraient être les solutions possibles?
Q-7 Du fait même de son nom, l’intelligence artificielle évoque naturellement l’idée d’une intelligence autonome de la machine, qui se pose en face de l’intelligence humaine, pour la simuler ou la dépasser. Mais si nous observons les usages réels des dispositifs d’intelligence artificielle, force est de constater que, la plupart du temps, ils augmentent, assistent ou accompagnent les opérations de l’intelligence humaine. Déjà, à l’époque des systèmes experts – lors des années 80 et 90 du XXe siècle – j’observais que les savoirs critiques de spécialistes au sein d’une organisation, une fois codifiés sous forme de règles animant des bases de connaissances, pouvaient être mis à la portée des membres qui en avaient le plus besoin, répondant précisément aux situations en cours et toujours disponibles. Plutôt que d’intelligences artificielles prétendument autonomes, il s’agissait de médias de diffusion des savoir-faire pratiques, qui avaient pour principal effet d’augmenter l’intelligence collective des communautés utilisatrices.
Dans la phase actuelle du développement de l’IA, le rôle de l’expert est joué par les foules qui produisent les données et le rôle de l’ingénieur cogniticien qui codifie le savoir est joué par les réseaux neuronaux. Au lieu de demander à des linguistes comment traduire ou à des auteurs reconnus comment produire un texte, les modèles statistiques interrogent à leur insu les multitudes de rédacteurs anonymisés du web et ils en extraient automatiquement des patterns de patterns qu’aucun programmeur humain n’aurait pu tirer au clair. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. Bien loin d’être autonome, cette IA prolonge et amplifie l’intelligence collective. Des millions d’utilisateurs contribuent au perfectionnement des modèles en leur posant des questions et en commentant les réponses qu’ils en reçoivent. On peut prendre l’exemple de Midjourney (qui génère des images), dont les utilisateurs s’échangent leurs consignes (prompts) et améliorent constamment leurs compétences. Les serveurs Discord de Midjourney sont aujourd’hui les plus populeux de la planète, avec plus d’un million d’utilisateurs. Une nouvelle intelligence collective stigmergique émerge de la fusion des médias sociaux, de l’IA et des communautés de créateurs. Derrière « la machine » il faut entrevoir l’intelligence collective qu’elle réifie et mobilise.
L’IA nous offre un nouvel accès à la mémoire numérique mondiale. C’est aussi une manière de mobiliser cette mémoire pour automatiser des opérations symboliques de plus en plus complexes, impliquant l’interaction d’univers sémantiques et de systèmes de comptabilité hétérogènes.
Je ne crois pas une seconde à la fin du travail. L’automatisation fait disparaître certains métiers et en fait naître de nouveaux. Il n’y a plus de maréchaux ferrants, mais les garagistes les ont remplacés. Les porteurs d’eau ont fait place aux plombiers. La complexification de la société augmente le nombre des problèmes à résoudre. Les machines « intelligentes » vont surtout augmenter la productivité du travail cognitif en automatisant ce qui peut l’être. Il y aura toujours besoin de gens intelligents, créatifs et compassionnés mais ils devront apprendre à travailler avec les nouveaux outils.
Q-8 Certains auteurs évoquent l’inversion de “l’effet Flynn”, suggérant que les générations futures auront un niveau cognitif inférieur à celui de leurs parents. Comment voyez-vous cet enjeu dans le contexte des technologies émergentes? Pensez-vous que l’usage intensif des technologies numériques puisse contribuer à cette tendance, ou offrent-elles de nouvelles façons d’élargir nos capacités cognitives?
R-8 La baisse du niveau cognitif (et moral), est déplorée depuis des siècles par chaque génération, alors que l’effet Flynn montre justement l’inverse. Il est normal que l’on assiste à une stabilisation des scores de Quotient Intellectuel (QI) : l’espoir d’une augmentation constante n’est jamais très réaliste et il serait normal d’atteindre une limite ou un palier, comme dans n’importe quel autre phénomène historique ou même biologique. Mais admettons que les jeunes gens d’aujourd’hui aient de moins bons scores de QI que les générations qui les précèdent immédiatement. Il faut d’abord se demander ce que mesurent ces tests : principalement une intelligence scolaire. Ils ne prennent en compte ni l’intelligence émotionnelle, ni l’intelligence relationnelle, ni la sensibilité esthétique, ni les habiletés physiques ou techniques, ni même le bon sens pratique. Donc on ne mesure là quelque chose de limité. D’autre part, si l’on reste sur l’adaptation au fonctionnement scolaire que mesurent les tests de QI, pourquoi accuser d’abord les technologies? Peut-être y-t-il démission des familles face à la tâche éducative (notamment parce que les familles se défont), ou bien défaillance des écoles et des universités qui deviennent de plus en plus laxistes (parce que les étudiants sont devenus des clients à satisfaire à tout prix) ? Quand j’étais étudiant, le « A » aux examens n’était pas encore un droit… Il l’est quasiment devenu aujourd’hui.
Finalement, et il faut le répéter sans cesse, « l’usage des technologies numériques » n’a pas grand sens. Il y a des usages abrutissants, qui glissent sur la pente de la paresse intellectuelle, et des usages qui ouvrent l’esprit, mais qui demandent une prise de responsabilité personnelle, un effort d’autonomie et – oui – du travail. C’est le rôle des éducateurs de favoriser les usages positifs.
Q-9 Existe-t-il des frontières claires entre le monde réel et le monde virtuel? Qu’est-ce qui pourrait nous motiver à continuer dans le monde réel alors que le monde virtuel offre des possibilités d’interaction et de réussite quasi illimitées?
R-9 Il n’y a jamais eu de frontière claire entre le monde virtuel et le monde actuel. Où se trouve la présence humaine? Dès que nous assumons une situation dans l’existence, nous nous retrouvons immanquablement entre deux. Entre le virtuel et l’actuel, entre l’âme et le corps, entre le ciel et la terre, entre le yin et le yang. Notre existence s’étire dans un intervalle et la relation fondamentale entre le virtuel et l’actuel est une transformation réciproque. C’est un morphisme qui projette le sensible sur l’intelligible et inversement.
Une situation pratique comprend un contexte actuel : notre posture, notre position, ce qui se trouve autour de nous en ce moment précis, de nos interlocuteurs à l’environnement matériel. Elle implique aussi un contexte virtuel : le passé dans notre mémoire, nos plans et nos attentes, nos idées de ce qui nous arrive. C’est ainsi que nous discernons les lignes de force et les tensions de la situation, son univers de problèmes, ses obstacles et ses échappées. Les configurations corporelles n’ont de sens que par le paysage virtuel qui les entoure.
Nous ne vivons donc pas seulement dans la réalité physique dite « matérielle », mais aussi dans le monde des significations. C’est ce qui fait de nous des humains. Maintenant, si l’on veut parler des médias dits « numériques » , en plus de leur aspect logiciel (les programmes et les données) ils sont évidemment aussi matériels : les centres de données, les câbles, les modems, les ordinateurs, les smartphones, les écrans, les écouteurs sont tout ce qu’il y a de plus matériels et actuels. Par ailleurs, je ne sais pas très bien à quoi vous faites allusion lorsque vous dites que « le monde virtuel offre des possibilités d’interaction et de réussite quasi illimitées ». Les possibilités d’interactions offertes par le médium numérique sont certes plus diverses que celles qui étaient fournies par l’imprimerie ou la télévision, mais elles ne sont en aucun cas « illimitées » puisque le temps disponible n’est pas extensible à l’infini. Ces possibilités dépendent aussi fortement des capacités et de l’environnement culturel et social des utilisateurs. La toute puissance est toujours une illusion. Par ailleurs, si vous voulez dire que la fiction et le jeu (qu’ils soient ou non à support électronique) offrent des possibilités illimitées, oui, c’est une idée qui a sa part de vérité. Maintenant, si vous sous-entendez qu’il est malsain de passer la plus grande partie de son temps à jouer à des jeux vidéo en ligne au détriment de sa santé, de ses études, de son environnement familial ou de son travail, on ne peut qu’être d’accord avec vous. Mais ce sont ici l’excès et l’addiction qui sont en question, avec leurs causes multiples, et pas « le monde virtuel ».
Q-10 Avec les progrès des technologies numériques, le concept d’immortalité numérique émerge, où nos identités peuvent être préservées indéfiniment en ligne. Comment comprenez-vous la relation entre la spiritualité et cette idée d’immortalité numérique?
R-10 Cette fausse immortalité n’a rien à voir avec la spiritualité. Pourquoi ne pas parler d’immortalité calcaire – ou architecturale – face aux pyramides d’Égypte? Une autre comparaison : Shakespeare ou Victor Hugo, voire Newton ou Einstein, sont probablement plus « immortels » qu’une personne dont on n’a pas supprimé le compte Facebook après la mort. S’il faut absolument rapporter le numérique au sacré, je dirais que les centres de données sont les nouveaux temples et qu’en échange du sacrifice de nos données, nous obtenons les bénédictions pratiques des intelligences artificielles et des médias sociaux.
Q-11 De nombreux experts ont souligné les problèmes moraux présents dans l’organisation et la construction de normes basées sur les données rapportées et exploitées par l’IA (préjugés, racisme et autres formes de déterminisme). Comment contrôler ces problèmes dans le scénario numérique? Qui est responsable ou peut être tenu responsable de problèmes de cette nature? L’IA pourrait-elle avoir des implications juridiques?
R-11 On parle beaucoup des « biais » de tel ou tel modèle d’intelligence artificielle, comme s’il pouvait exister une IA non-biaisée ou neutre. Cette question est d’autant plus importante que l’IA devient notre nouvelle interface avec les objets symboliques : stylo universel, lunettes panoramiques, haut-parleur général, programmeur sans code, assistant personnel. Les grands modèles de langue généralistes produits par les plateformes dominantes s’apparentent désormais à une infrastructure publique, une nouvelle couche du méta-médium numérique. Ces modèles généralistes peuvent être spécialisés à peu de frais avec des jeux de données issues d’un domaine particulier et de méthodes d’ajustement. On peut aussi les munir de bases de connaissances dont les faits ont été vérifiés.
Les résultats fournis par une IA découlent de plusieurs facteurs qui contribuent tous à son orientation ou si l’on préfère, à ses « biais ».
a) Les algorithmes proprement dits sélectionnent les types de calcul statistique et les structures de réseaux neuronaux.
b) Les données d’entraînement favorisent les langues, les cultures, les options philosophiques, les partis-pris politiques et les préjugés de toutes sortes de ceux qui les ont produites.
c) Afin d’aligner les réponses de l’IA sur les finalités supposées des utilisateurs, on corrige (ou on accentue!) « à la main » les penchants des données par ce que l’on appelle le RLHF (Reinforcement Learning from Human Feed-back – en français : apprentissage par renforcement à partir d’un retour d’information humain).
d) Finalement, comme pour n’importe quel outil, l’utilisateur détermine les résultats au moyen de consignes en langue naturelle (les fameux prompts). Comme je l’ai dit plus haut, des communautés d’utilisateurs s’échangent et améliorent collaborativement de telles consignes. La puissance de ces systèmes n’a d’égal que leur complexité, leur hétérogénéité et leur opacité. Le contrôle règlementaire de l’IA, sans doute nécessaire, semble difficile.
La responsabilité est donc partagée entre de nombreux acteurs et processus, mais il me semble que ce sont les utilisateurs qui doivent être tenus pour les responsables principaux, comme pour n’importe quelle technique. Les questions éthiques et juridiques reliées à l’IA sont aujourd’hui passionnément discutées un peu partout. C’est un champ de recherche académique en pleine croissance et de nombreux gouvernements et organismes multinationaux ont émis des lois et règlement pour encadrer le développement et l’utilisation de l’IA.






