IEML est fondé sur les grandes découvertes de la linguistique du XXe siècle. Dans cette entrée de blog nous allons étudier successivement les héritages de Chomsky; de Saussure et de l’école structuraliste; de Tesnière et du modèle actantiel de la phrase; de Benveniste, Wittgenstein et Austin pour leurs solutions aux problèmes épineux de l’énonciation et de la pragmatique. Je conclurai en essayant de dissiper un des principaux malentendus au sujet d’IEML: ce n’est pas une langue “vraie” (une langue n’est ni vraie ni fausse, elle est conventionnelle), mais une langue claire.
[For an English version of this article see here.]

L’héritage de Chomsky et les langages réguliers
Commençons par évoquer la dette d’IEML à l’égard de Noam Chomsky, un des géants de la linguistique et des sciences cognitives du XXe siècle. Pour le professeur du MIT, la capacité linguistique est un trait génétiquement déterminé de l’espèce humaine. Les langues, malgré leur diversité et leur évolution continuelle, partagent toutes la même “grammaire universelle” correspondant à cette habileté linguistique innée. Cette théorie expliquerait pourquoi les enfants apprennent spontanément et si vite à parler, sans qu’on ait besoin de leur donner des leçons de grammaire. Chomsky a exposé une version formelle – d’ailleurs contestée et plusieurs fois révisée – de la grammaire universelle. La découverte scientifique la plus précieuse de Chomsky est probablement sa théorie des langages réguliers : il a démontré qu’il existait une correspondance entre l’algèbre et la syntaxe formelle. La langue est donc en principe un objet calculable, au moins sur un plan syntaxique . Pour qu’une langue puisse être manipulée facilement par les ordinateurs, c’est-à-dire calculable, il faut qu’elle soit un langage régulier au sens de Chomsky: une sorte de code mathématique. Or les langues naturelles ne sont évidemment pas des langages réguliers. Les langages réguliers effectivement utilisés aujourd’hui sont des langages de programmation. Mais la “sémantique” des langages de programmation n’est autre que l’exécution des opérations qu’ils commandent. Aucun d’eux n’approche la capacité expressive d’une langue naturelle, qui permet de parler de tout et de rien et d’accomplir bien d’autres actes illocutoires que de donner des instructions à une machine. Notons au passage que Hjelmslev critiquait l’expression de « langue naturelle » à laquelle il préférait celle de langue philologique ou langue passe-partout. En effet, on peut tout dire en Espéranto, par exemple, bien que ce soit une langue construite et non pas naturelle. L’Espéranto est donc une langue philologique. Hélas, la sémantique de l’Espéranto n’est pas plus calculable que celle du Français ou de l’Arabe. A cause de leur irrégularité, les ordinateurs n’ont aujourd’hui accès aux langues philologiques que sur un mode statistique. C’est pourquoi notre âge numérique a besoin d’une langue philologique transparente aux algorithmes et donc régulière. IEML est la solution que j’ai trouvée au problème de la construction d’une langue philologique à la sémantique calculable. La calculabilité de sa sémantique n’est évidemment pertinente que s’il s’agit d’une langue philologique, permettant de « tout dire ». Et puisque la sémantique de cette langue devait être calculable, sa syntaxe devait a fortiori l’être aussi. C’est pourquoi IEML est un langage régulier au sens de Chomsky. Mais si le fait d’être un langage régulier était une condition nécessaire à la calculabilité de sa sémantique, ce n’en était pas une condition suffisante. Souvenons-nous que les langages réguliers actuellement en usage ont une sémantique restreinte : ce ne sont pas des langues philologiques. Comment conférer une sémantique philologique à un langage régulier ? Pour répondre à cette question, je me suis appuyé sur les enseignements de Saussure et de ses successeurs.
L’héritage de Saussure et le structuralisme
Selon Ferdinand de Saussure (1857-1913), un des pères de la linguistique contemporaine, les symboles linguistiques sont constitués de deux parties, le signifiant (une image acoustique ou visuelle) et le signifié (un concept ou une catégorie abstraite). Le rapport entre les deux parties du symbole est conventionnel ou arbitraire. Saussure a également montré que le plan du signifiant, ou la phonologie des langues, était basé sur un système de différences entre les sons, chaque langue ayant sa propre liste de phonèmes et surtout sa propre manière de disposer les seuils de passage entre deux phonèmes dans le continuum sonore. Un phonème n’existe pas de manière isolée, en dehors d’un éventail de variations, un peu comme les notes de musique n’existent que par rapport à un système musical. De la même manière, les signifiés ne sont pas des atomes de sens se suffisant à eux-mêmes mais correspondent à des positions dans des systèmes de différences : les paradigmes. La sémantique linguistique ne s’ancre donc pas dans des réalités naturelles fixes et indépendantes, mais dans un processus de comparaison, d’opposition, de différenciation et de renvois entre signifiés au sein d’une grille systémique bouclée sur elle-même, comme le sens d’un mot dans le dictionnaire est défini par d’autres mots qui, eux-mêmes, etc. Les travaux de Saussure ont été notamment poursuivis par Louis Hjemslev (1899-1965), qui a approfondi l’analyse du signe linguistique et a plaidé pour un maximum de rigueur épistémologique dans le traitement du langage, jusqu’à un idéal quasi-algébrique. Hjemslev a rebaptisé l’opposition entre signifiant et signifié en décrivant deux « plans » linguistiques celui de l’expression (le signifiant) et celui du contenu (le signifié). Chacun des deux plans est à son tour analysé en matière et forme. La matière de l’expression est de l’ordre du phénomène sensible, par exemple visuel ou sonore. Par contraste, la forme de l’expression désigne les unités abstraites qui résultent du découpage structurel des signifiants dans une langue donnée. Par exemple, le phonème « a » représente une forme bien déterminée qui s’oppose dans telle ou telle langue au phonème « o ». C’est ce qui permet en français, par exemple, de distinguer entre « bas » et « beau ». En revanche la forme « a » peut être remplie par un grand nombre de matières sonores distinctes selon les voix, les accents, etc. La matière est de l’ordre du continuum concret alors que la forme est de l’ordre du système d’oppositions abstrait. Il en est de même pour le contenu. Hjemslev a supposé qu’il existait un continuum du signifié, une sorte de magma abritant virtuellement l’ensemble des catégories possibles : la matière du contenu. Cette matière est découpée et organisée en paradigmes de manière différente pour chaque langue. En fin de compte, une langue quelconque organise une correspondance particulière entre forme de l’expression et forme du contenu. Le courant structuraliste initié par Saussure et poursuivi par Hjemslev a été prolongé par Julien Algirdas Greimas (1917-1992) et François Rastier (1945- ). Tout en maintenant vivante la tradition qui conçoit l’existence relativement autonome d’un monde des signifiés, ces auteurs ont notamment étendu l’analyse structurale du niveau des mots et des phrases jusqu’au niveau du texte, en particulier grâce à la notion d’isotopie. Revenons maintenant à notre problème : comment construire une langue qui soit simultanément philologique et régulière ? Non seulement les langues sont conventionnelles, mais elles ne peuvent pas ne pas l’être. La correspondance entre signifiant et signifié, ou expression et contenu, est arbitraire par nature. Puisque les langues sont nécessairement conventionnelles, rien n’interdit d’en construire une dont l’arrangement des signifiants soit de type “langage régulier”. Nous savons qu’un langage régulier possède une syntaxe calculable. Or la syntaxe régit les éléments signifiants de la langue, les phonèmes et leurs enchaînements, à plusieurs niveaux de complexité emboîtés. Puisqu’aussi bien les signifiants que les signifiés doivent être organisés par un système de différences, rien n’interdit non plus de donner – par convention – à ce langage régulier un système de différences des signifiés (une forme du contenu) qui soit une fonction mathématique de celui des signifiants (la forme de l’expression). En accord avec les théories de Saussure et de ses successeurs, les unités de la langue IEML, à commencer par les morphèmes, mais aussi les unités lexicales, les phrases et les super-phrases sont organisées en paradigmes. Ces systèmes de variations sur fond de constantes – ou groupes de transformations – permettent aux unités linguistiques de s’entre-définir et de s’expliquer réciproquement. Or – en IEML – ce sont les mêmes paradigmes qui structurent l’expression et le contenu. Voici donc le principe de résolution de notre problème : dans un langage régulier dont le système de différences des signifiés est une fonction calculable de celui des signifiants, non seulement la syntaxe mais également la sémantique est calculable. C’est précisément le cas d’IEML, qui est donc une langue à la sémantique calculable !
L’héritage de Tesnière et la linguistique cognitive
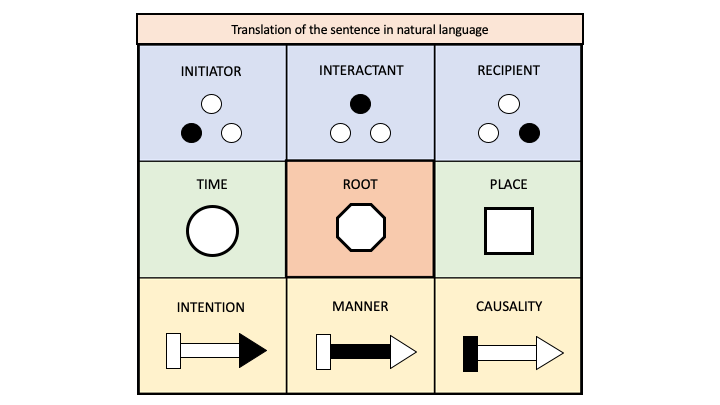
Parmi toutes les fonctions du langage, l’une des plus importantes est de supporter la construction et la simulation de modèles mentaux [Je m’inspire ici notamment de l’étude de Philip Johnson-Laird, Mental Models, Harvard University Press, 1983]. L’architecture linguistique des modèles mentaux n’est évidemment pas exclusive de modes de représentation sensori-moteurs, et notamment visuels, qui peuvent se rapporter aussi bien à des mondes fictionnels qu’à la réalité vécue. Des linguistes comme Ronald Langacker (1942- ) et George Lakoff (1941- ), qui sont parmi les principaux chefs de file du courant de la linguistique cognitive, ont particulièrement étudié cette fonction de modélisation mentale. La capacité de représenter des « scènes » – à savoir des processus mis en oeuvre par des actants dans certaines circonstances – est une condition sine qua non du travail de modélisation accompli par le langage. Elle fonde la faculté narrative, puisqu’un récit peut être ramené à un enchaînement hypertextuel de scènes, moyennant certaines relations d’anaphore et d’isotopie. J’ajoute qu’en spécifiant les rapports entre processus et/ou entre actants, la scénographie linguistique fonde également la représentation des relations causales. Puisqu’une des missions d’IEML est de servir d’outil formel de modélisation, il doit non seulement organiser un morphisme entre sa sémantique et sa syntaxe, mais également systématiser et faciliter autant que possible la représentation des processus, des actants, des circonstances et de leurs interactions. Pour ce faire, IEML a intégré, avec quelques ajustements, le modèle actantiel de la phrase que Tesnière, préfigurant la linguistique cognitive, avait proposé dès le milieu du XXe siècle.

En effet, outre le courant structuraliste, la grammaire d’IEML a aussi été largement influencée par l’oeuvre majeure de Lucien Tesnière (1893-1954). Ce linguiste français a été le premier à présenter une grammaire universelle fondée sur les arbres de dépendance, qui met en évidence le lien intime entre syntaxe et sémantique (voir la Figure 1). Bien que les deux systèmes aient été élaborés indépendamment, les arbres de dépendance de Tesnière sont proches des arbres syntaxiques de Chomsky. Tesnière a aussi proposé une théorie subtile de la translation entre les « parties du discours » que sont les verbes, noms, adverbes et adjectifs. Il a surtout développé le modèle actantiel de la phrase dont s’inspire la fonction syntagmatique d’IEML. La citation suivante, extraite de son oeuvre posthume Eléments de syntaxe structurale, explique bien le principe du modèle actantiel : « Le noeud verbal (…) exprime tout un petit drame. Comme un drame, en effet, il comporte (…) un procès et, le plus souvent, des acteurs et des circonstances. Le verbe exprime le procès. (…) Les actants sont des êtres ou des choses (…) participant au procès. (…) Les circonstants expriment les circonstances de temps, lieux, manière, etc. » [Lucien Tesnière, Eléments de syntaxe structurale, Klincksieck, Paris 1959: 102, Chapitre 48] Le modèle actantiel de Tesnière a notamment été repris et développé par deux importants linguistes contemporains, Igor Melchuk (1932- ) et Charles Fillmore (1929-2014). La grammaire des cas de Fillmore publiée en 1968, a été étendue dans les années 1980 à une conception quasi-encyclopédique de la sémantique linguistique notamment mise en oeuvre dans le projet FrameNet centré sur la langue anglaise et qui inspire plusieurs programmes d’intelligence artificielle. Les frames ou « cadres » en français décrivent la manière dont les mots conviennent les uns avec les autres et déterminent mutuellement leurs sens dans une phrase. Par exemple, lorsqu’on utilise le verbe « attaquer » à la voix active, le sujet grammatical est forcément un assaillant et l’objet grammatical une victime de l’attaque. L’approche adoptée par IEML est compatible avec les théories de Fillmore, les cas correspondant aux rôles syntagmatiques et l’équivalent des cadres étant les paradigmes de phrases. Quant à Igor Melchuk, sa contribution la plus originale concerne la morphologie, c’est-à-dire la structure des mots et leurs rapports. Il a en particulier décrit les fonctions lexicales qui règlent les collocations – c’est-à-dire les mots qui vont ou ne vont pas ensemble – et les relations sémantiques entre les unités lexicales d’une langue. Un exemple simple de fonction lexicale est « PLUS » comme dans : [PLUS (colline) = montagne] ou [PLUS (ruisseau) = rivière]. Les fonctions lexicales sont notamment utilisées pour construire des dictionnaires explicatifs et combinatoires (monolingues) et elles alimentent, comme les cadres de Fillmore, certains programmes de traitement automatique des langues naturelles. IEML intègre les principales fonctions lexicales mises en évidence par Melchuk, ce qui permet de composer facilement de nouveaux mots à partir des éléments du dictionnaire et d’expliciter formellement les relations sémantiques entre unités lexicales. Quant aux collocations selon Melchuk elles sont proches des cadres de Fillmore et sont – comme eux – traduites en IEML par des paradigmes de phrases. En somme, de nombreux linguistes ont souligné l’importance de la fonction modélisatrice du langage. Suivant leurs traces, IEML offre à ses locuteurs les outils grammaticaux nécessaires pour décrire des scènes et raconter des histoires. De plus, IEML permet de modéliser un domaine de connaissance spécialisé ou un champ sémantique particulier par la libre élaboration de terminologies (paradigmes de radicaux) et de phrases-cadres (paradigmes de phrases).
Austin, Wittgenstein et l’héritage pragmatique
La langue est une structure abstraite qui combine des paradigmes de morphèmes (atomes de sens indécomposables) et des règles de compositions des unités grammaticales (mots, phrases…) à partir des morphèmes. Par contraste, la parole – ou le texte – est une séquence de morphèmes particulière qui actualise le système de la langue. En ce sens, les terminologies et les phrases-cadres d’IEML appartiennent à une catégorie intermédiaire entre la langue et la parole. Ils font partie de la parole dans la mesure où ils sont librement créés à partir du dictionnaire de morphèmes initial et des règles de construction de syntagmes. Mais ils appartiennent encore à la langue puisque ce ne sont pas à proprement parler des énonciations en contexte. Ce n’est qu’au niveau de l’énonciation, en effet, que se déploient les actes de langages, c’est-à-dire la dimension pragmatique des langues. Or il ne s’agit pas de choisir entre la fonction modélisatrice ou représentative des langues, qui vient d’être évoquée à la section précédente, et leur fonction pratique, que nous allons survoler dans cette section. Bien au contraire : la fonction de représentation et la fonction pratique se soutiennent mutuellement. Sans modèle du monde, l’action n’a pas de sens et sans plongement dans quelque situation pratique, la représentation perd toute pertinence. Quoiqu’on puisse faire remonter la réflexion sur la puissance pratique du langage à la rhétorique antique ou aux plus anciennes réflexions de l’école confucéenne, je me limiterai ici à quelques grands auteurs : Emile Benvéniste pour l’étude de l’énonciation et de la fonction déictique, Ludwig Wittgenstein pour la question de la référence et des jeux de langage, John L. Austin pour la notion même de pragmatique linguistique. Relèvent de la pragmatique linguistique les actes accomplis dans le langage mais qui ont des conséquences extra-linguistiques, comme par exemple baptiser, interdire, condamner, etc. Puisqu’ils sont accomplis dans le langage, ces actes sont de nature symbolique. Ils sont par conséquent régis par des règles et accomplis par des « joueurs » qui tiennent des rôles déterminés. Une multitude de jeux de langage, selon l’expression de Wittgenstein, animent donc la dimension pragmatique qui s’ouvre avec l’énonciation. Une langue peut elle-même être assimilée à un système de règles ou à un jeu. Et si cette langue est philologique elle est capable à son tour de définir une multitude de langues restreintes, de systèmes de règles ou de jeux, qui sont autant de manières distinctes de l’utiliser dans la pratique. IEML étant une langue philologique, nous l’utiliserons non seulement pour modéliser un champ sémantique quelconque, représenter des scènes et raconter des histoires, mais aussi pour expliciter des jeux de langages dont nous formaliserons les règles, les rôles et les coups au moyen de terminologies et de phrases-cadres. Lorsqu’ils reconnaîtront les actes de langages accomplis par les locuteurs d’IEML, des algorithmes pourront déclencher automatiquement leurs conséquences extra-linguistiques et notamment calculer les nouveaux états des « parties » en cours. J’évoquerai ici quatre grands types d’actes de langage qui sont particulièrement pertinents pour IEML : la référence, le raisonnement, la communication sociale et les instructions données à des machines. La première fonction de l’énonciation est de faire référence à des objets non-linguistiques. Une de ses formes les plus évidentes est la distribution des rôles interlocutoires : les première, seconde ou troisième personnes indiquent qui parle, à qui et de quoi. Mentionnons également les possessifs (liés à la distribution des personnes grammaticales), les démonstratifs comme « ça, ici, là-bas », les adverbes comme « aujourd’hui », « demain », etc. Or un texte – ou un énoncé – ne permet pas d’interpréter les déictiques comme « je », « ça » ou « demain ». Seul l’événement d’une énonciation par quelqu’un, dans un contexte spatio-temporel d’interlocution défini, peut leur donner un contenu [« « Je » » signifie « la personne qui énonce la présente instance du discours contenant « je ». » (Emile Benveniste)] . Cette fonction référentielle du langage est particulièrement importante pour IEML, qui a pour vocation de catégoriser des données et donc – par nécessité – de les indexer. Aussi bien la distribution des rôles interlocutoires que la catégorisation des données peuvent se conformer à un grand nombre de jeux de référence distincts. Par exemple, pour interpréter un « nous » il faut connaître le système de distribution des personnes auquel il obéit : pluriel de majesté, chercheurs d’une même discipline, membres d’un tribunal, citoyens d’une nation en guerre…? D’autre part, la catégorisation des données en IEML prend un sens différent selon que l’indexation est faite par un algorithme ou par un humain. Dans le cas de l’indexation automatique, s’agit-il d’un algorithme statistique basé sur un corpus indexé manuellement ? Et dans ce dernier cas, indexé par qui, selon quels critères, etc. Dans le même ordre d’idée, il peut être utile de savoir si un texte est cité (encore un geste déictique) en tant que partie d’un corpus de référence, comme une autorité pour renforcer la crédibilité des idées de l’auteur, pour être critiqué, ou encore pour une autre raison. En somme, l’opération de référence est un acte de langage, cet acte relève d’une multitude de jeux possibles, et ces jeux peuvent être explicités en IEML. Le raisonnement est encore un autre type de jeu de langage modélisable en IEML. Citons dès maintenant, en suivant la typologie de Charles S. Peirce, (1) les divers genres de raisonnement déductifs, (2) les raisonnements inductifs – incluant les calculs statistiques – et (3) les raisonnements abductifs, qui construisent des modèles causaux d’un domaine ou d’un processus. On remarquera que le raisonnement suppose la plupart du temps la référence et que cette dernière est souvent faite pour appuyer le raisonnement. Les jeux de langage qui ont le plus été étudiés par les spécialistes de la pragmatique, à commencer par Austin et Searle, sont les jeux de communication sociale, qui comprennent par exemple les assertions, les questions, les ordres, les promesses, les remerciements, les nominations, etc. Mais nous pouvons ajouter à ce type de jeux les transactions, les contrats et tout ce qui relève des arrangements légaux et des échanges économiques, qui passent de plus en plus par des canaux électroniques et qui auraient avantage à être exprimés dans un langage transparent, univoque et calculable comme IEML. Finalement, puisque nous vivons dans un environnement de plus en plus robotisé, les instructions données à des machines, tout comme d’ailleurs les informations – parfois vitales – que les machines nous transmettent, font évidemment partie des actes de langage aux importantes conséquences extra-linguistiques. Parce que les ordinateurs peuvent décoder IEML et qu’IEML se traduit en langues naturelles, notre métalangage pourrait devenir le noyau logiciel d’une interface ubiquitaire et interopérable entre humains et machines.
Une image du monde ou une image de soi ?
Dans le Tractatus Logico Philosophicus, l’ouvrage de jeunesse qui l’a fait connaître, Wittgenstein examine à quelles conditions les propositions logiques présentent une image fidèle de la réalité. Le monde étant conçu par notre philosophe viennois comme « tout ce qui arrive », chaque fait ou événement devrait être représenté par une proposition dont la structure logico-grammaticale reflète la structure interne du fait. L’idée d’un langage parfait ou d’une langue transparente est souvent associée à cet idéal d’isomorphie entre les expressions du langage et les réalités qu’elles décrivent ou, en d’autres termes, entre la parole et sa référence. Rien n’est plus loin du projet d’IEML. Plutôt que de poursuivre la chimère au parfum vaguement totalitaire d’une langue de la vérité (la vérité se ramène à la correspondance entre parole et réalité), j’ai poursuivi un objectif moins contraignant et surtout plus atteignable : celui d’une langue de la clarté, aussi univoque et traductible que possible. A l’idéal d’une langue logique qui reflèterait des états de choses, j’ai substitué celui d’une langue philologique dont la forme algébrique de l’expression reflèterait la forme du contenu conceptuel : une langue qui serait une image d’elle-même avant d’être une image du monde. Par définition, cette correspondance interne ne relève pas du vrai et du faux mais de la convention utile. Quant au rapport d’IEML avec la réalité extralinguistique, elle relève d’une multitude de jeux de langages (je suis ici le Wittgenstein de la maturité, tel qu’il s’est exprimé dans les Philosophical Investigations), multitude qui englobe les diverses manières de découper, reconnaître et désigner des objets pertinents selon les contextes pratiques. Et grâce à la capacité de description universelle propre à toutes les langues philologiques, nous pouvons modéliser ces multiples jeux de langages en IEML. Cette approche respecte aussi bien la liberté que la créativité de ses locuteurs tout en autorisant ces derniers à se coordonner entre eux et avec les machines. Reprenons la classification des différents niveaux de la sémantique – linguistique, référentielle et illocutoire. Notre métalangage clarifie les relations entre signifiés et signifiants ainsi que les relations entre signifiés au point de pouvoir automatiser leur traitement. Le principal apport d’IEML se situe donc au niveau de la sémantique linguistique. Quant à la sémantique référentielle – le pointage vers des réalités extra-linguistiques – elle peut devenir plus précise dans la mesure où les différents modes de référence sont précisés en IEML. Enfin, la force illocutoire des énonciations, c’est-à-dire les « coups » qui sont joués dans une multitude de jeux de communication sociale, peuvent être reconnus par des algorithmes et traités en conséquence, à condition que les jeux en question aient préalablement été décrits en IEML. En somme, la formalisation de la sémantique linguistique nous offre la clé de la formalisation de la sémantique en général.
Brève bibliographie
- Austin John L. How to Do Things with Words, Oxford University Press, Oxford, 1962
- Benveniste Emile Problèmes de linguistique générale, Tomes 1 et 2, Gallimard, Paris, 1966-1974
- Chomsky Noam New Horizons in the Study of Language and Mind, Cambridge University Press, Cambridge, 2000.
- Chomsky Noam Syntaxic Structures, Mouton, La Hague et Paris, 1957.
- Chomsky Noam ; Schützenberger, Marcel P. « The algebraic theory of context free languages », in Braffort, P. ; Hirschberg, D. : Computer Programming and Formal Languages, North Holland, Amsterdam, 118-161, 1963
- Fillmore Charles “The Case for Case” (1968). In Bach and Harms (Ed.): Universals in Linguistic Theory. New York: Holt, Rinehart, and Winston, 1-88. (Tesnières y est cité à neuf reprises).
- Fillmore Charles “Frame semantics” (1982). In Linguistics in the Morning Calm. Seoul, Hanshin Publishing Co., 111-137.
- Hejlmslev Louis, Prolégomènes à une théorie du langage – La Structure fondamentale du langage, Paris, Éditions de minuit, coll. « Arguments », 2000
- Johnson-Laird Philip, Mental Models, Harvard University Press, 1983
- Lakoff George Women, Fire and Dangerous Things: What Categories Reveal About the Mind, University of Chicago Press, Chicago, USA, 1987.
- Lakoff George, Johnson M., Metaphors We Live By, University of Chicago Press, Chicago, USA, 2003.
- Langacker Ronald W., Foundations of Cognitive Grammar (2 volumes), Stanford University Press, Stanford, USA, 1987-1991.
- Levy Pierre The Semantic Sphere / La sphère sémantique, Hermès-Lavoisier, Paris-London, 2011
- Melchuk, Igor, « Actants in Semantics and Syntax. I. Actants in Semantics », Linguistics, 42: 1, 2004, 1-66
- Melchuk Igor Aspects of the Theory of Morphology. Berlin—New York: Mouton de Gruyter, 2006. 615 pp
- Peirce, C. S., The Essential Peirce, Selected Philosophical Writings, Volume 1 (1867–1893) and 2 (1893-1913) Nathan Houser and Christian J. W. Kloesel, eds., Indiana University Press, Bloomington and Indianapolis, IN, 1992-1998.
- Saussure Ferdinand de Cours de Linguistique générale, Payot, Paris, 1916.
- Searle John Speech Acts, Cambridge University Press, London, 1969.
- Searle John Intentionality, Cambridge University Press, London, 1983.
- Tesnière Lucien Eléments de Syntaxe structurale Klincksieck, Paris, 1959 (posthumous)
- Wittgenstein Ludwig Tractatus Logico Philosophicus, Routledge and Kegan Paul Ltd, London, 1961.
- Wittgenstein Ludwig Philosophical Investigations, Blackwell, Oxford, 1953.