I put forward in this paper a vision for a new generation of cloud-based public communication service designed to foster reflexive collective intelligence. I begin with a description of the current situation, including the huge power and social shortcomings of platforms like Google, Apple, Facebook, Amazon, Microsoft, Alibaba, Baidu, etc. Contrasting with the practice of these tech giants, I reassert the values that are direly needed at the foundation of any future global public sphere: openness, transparency and commonality. But such ethical and practical guidelines are probably not powerful enough to help us crossing a new threshold in collective intelligence. Only a disruptive innovation in cognitive computing will do the trick. That’s why I introduce “deep meaning” a new research program in artificial intelligence, based on the Information Economy MetaLanguage (IEML). I conclude this paper by evoking possible bootstrapping scenarii for the new public platform.
The rise of platforms
At the end of the 20th century, one percent of the human population was connected to the Internet. In 2017, more than half the population is connected. Most of the users interact in social media, search information, buy products and services online. But despite the ongoing success of digital communication, there is a growing dissatisfaction about the big tech companies – the “Silicon Valley” – who dominate the new communication environment.
The big techs are the most valued companies in the world and the massive amount of data that they possess is considered the most precious good of our time. Silicon Valley owns the big computers: the network of physical centers where our personal and business data are stored and processed. Their income comes from their economic exploitation of our data for marketing purposes and from their sales of hardware, software or services. But they also derive considerable power from the knowledge of markets and public opinions that stems from their information control.
The big cloud companies master new computing techniques mimicking neurons when they learn a new behavior. These programs are marketed as deep learning or artificial intelligence even if they have no cognitive autonomy and need some intense training on huge masses of data. Despite their well known limitations, machine learning algorithms have effectively augmented the abilities of digital systems. Deep learning is now used in every economic sector. Chips specialized in deep learning are found in big data centers, smartphones, robots and autonomous vehicles. As Vladimir Putin rightly told young Russians in his speech for the first day of school in fall 2017: “Whoever becomes the leader in this sphere [of artificial intelligence] will become the ruler of the world”.
The tech giants control huge business ecosystems beyond their official legal borders and they can ruin or buy competitors. Unfortunately, the big tech rivalry prevents a real interoperability between cloud services, even if such interoperability would be in the interest of the general public and of many smaller businesses. As if their technical and economic powers were not enough, the big tech are now playing into the courts of governments. Facebook warrants our identity and warns our family and friends that we are safe when a terrorist attack or a natural disaster occurs. Mark Zuckerberg states that one of Facebook’s mission is to insure that the electoral process is fair and open in democratic countries. Google Earth and Google Street View are now used by several municipal instances and governments as their primary source of information for cadastral plans and other geographical or geospatial services. Twitter became an official global political, diplomatic and news service. Microsoft sells its digital infrastructure to public schools. The kingdom of Denmark opened an official embassy in Silicon Valley. Cryptocurrencies independent from nation states (like Bitcoin) are becoming increasingly popular. Blockchain-based smart contracts (powered by Ethereum) bypass state authentication and traditional paper bureaucracies. Some traditional functions of government are taken over by private technological ventures.
This should not come as a surprise. The practice of writing in ancient palace-temples gave birth to government as a separate entity. Alphabet and paper allowed the emergence of merchant city-states and the expansion of literate empires. The printing press, industrial economy, motorized transportation and electronic media sustained nation-states. The digital revolution will foster new forms of government. Today, we discuss political problems in a global public space taking advantage of the web and social media and the majority of humans live in interconnected cities and metropoles. Each urban node wants to be an accelerator of collective intelligence, a smart city. We need to think about public services in a new way. Schools, universities, public health institutions, mail services, archives, public libraries and museums should take full advantage of the internet and de-silo their datasets. But we should go further. Are current platforms doing their best to enhance collective intelligence and human development? How about giving back to the general population the data produced in social media and other cloud services, instead of just monetizing it for marketing purposes ? How about giving to the people access to cognitive powers unleashed by an ubiquitous algorithmic medium?
Information wants to be open, transparent and common
We need a new kind of public sphere: a platform in the cloud where data and metadata would be our common good, dedicated to the recording and collaborative exploitation of memory in the service of our collective intelligence. The core values orienting the construction of this new public sphere should be: openness, transparency and commonality
Firstly openness has already been experimented in the scientific community, the free software movement, the creative commons licensing, Wikipedia and many more endeavors. It has been adopted by several big industries and governments. “Open by default” will soon be the new normal. Openness is on the rise because it maximizes the improvement of goods and services, fosters trust and supports collaborative engagement. It can be applied to data formats, operating systems, abstract models, algorithms and even hardware. Openness applies also to taxonomies, ontologies, search architectures, etc. A new open public space should encourage all participants to create, comment, categorize, assess and analyze its content.
Then, transparency is the very ground for trust and the precondition of an authentic dialogue. Data and people (including the administrators of a platform), should be traceable and audit-able. Transparency should be reciprocal, without distinction between the rulers and the ruled. Such transparency will ultimately be the basis for reflexive collective intelligence, allowing teams and communities of any size to observe and compare their cognitive activity
Commonality means that people will not have to pay to get access to this new public sphere: all will be free and public property. Commonality means also transversality: de-silo and cross-pollination. Smart communities will interconnect and recombine all kind of useful information: open archives of libraries and museums, free academic publications, shared learning resources, knowledge management repositories, open-source intelligence datasets, news, public legal databases…
From deep learning to deep meaning
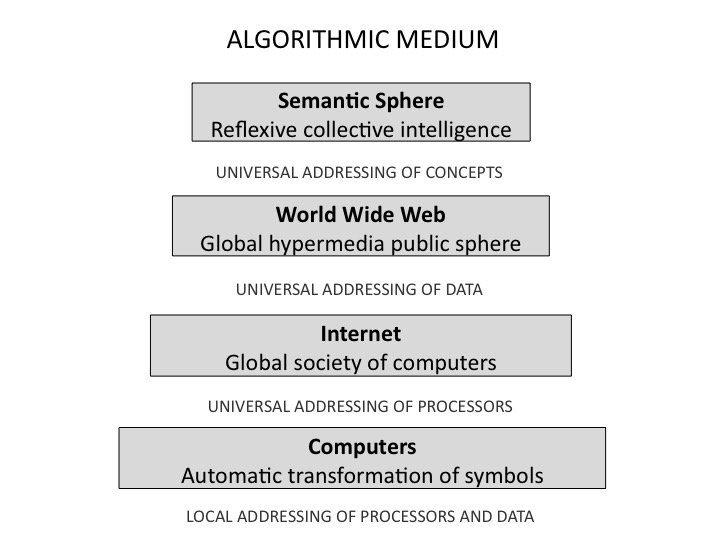
This new public platform will be based on the web and its open standards like http, URL, html, etc. Like all current platforms, it will take advantage of distributed computing in the cloud and it will use “deep learning”: an artificial intelligence technology that employs specialized chips and algorithms that roughly mimic the learning process of neurons. Finally, to be completely up to date, the next public platform will enable blockchain-based payments, transactions, contracts and secure records
If a public platform offers the same technologies as the big tech (cloud, deep learning, blockchain), with the sole difference of openness, transparency and commonality, it may prove insufficient to foster a swift adoption, as is demonstrated by the relative failures of Diaspora (open Facebook) and Mastodon (open Twitter). Such a project may only succeed if it comes up with some technical advantage compared to the existing commercial platforms. Moreover, this technical advantage should have appealing political and philosophical dimensions.
No one really fancies the dream of autonomous machines, specially considering the current limitations of artificial intelligence. Instead, we want an artificial intelligence designed for the augmentation of human personal and collective intellect.
Language as a platform
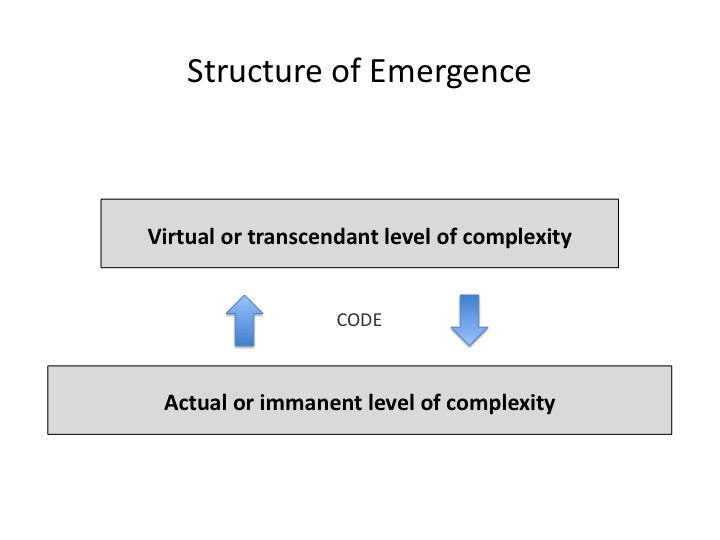
In order to augment the human intellect, we need both statistical and symbolic AI! Right now deep learning is based on neural networks simulation. It is enough to model roughly animal cognition (every animal species has neurons) but it is not refined enough to model human cognition. The difference between animal cognition and human cognition is the reflexive thinking that comes from language and explicit modelling. Why not adding a layer of semantic addressing on top of neural connectivity. In human cognition, the categories that organize perception, action, memory and learning are expressed linguistically so they may be reflected upon and shared in conversations. A language works like the semantic addressing system of a social virtual database.
But there is a problem with natural languages (english, french, arabic, etc.), they are irregular and do not lend themselves easily to machine understanding, I mean real understanding (projection of data on semantic networks) and not stochastic parroting. The current trend in natural language processing, an important field of artificial intelligence, is to use statistical algorithms and deep learning methods to understand and produce linguistic data. But instead of using only statistics, “deep meaning” adopts in addition a regular and computable metalanguage. I have designed IEML (Information Economy MetaLanguage) from the beginning to optimize semantic computing. IEML words are built from six primitive symbols and two operations: addition and multiplication. The semantic relations between IEML words follow the lines of their generative operations. The total number of words do not exceed 3 000. From its dictionary, the generative grammar of IEML allows the construction of recursive sentences that can define complex concepts and their relations. IEML would be the semantic addressing system of a social database.
Given large datasets, deep meaning allows the automatic computing of semantic relations between data, semantic analysis and semantic visualizations. This new technology fosters semantic interoperability: it decompartmentalizes tags, folksonomies, taxonomies, ontologies and languages. When on line communities categorize, assess and exchange semantic data, they generate explorable ecosystems of ideas that represent their collective intelligence. Take note that the vision of collective intelligence proposed here is distinct from the “wisdom of the crowd” model, that assumes independent agents and excludes dialogue and reflexivity. Just the opposite : deep meaning was designed from the beginning to nurture dialogue and reflexivity.
The main functions of the new public sphere

In the new public sphere, every netizen will act as an author, editor, artist, curator, critique, messenger, contractor and gamer. The next platform weaves five functions together: curation, creation, communication, transaction and immersion.
By curation I mean the collaborative creation, edition, analysis, synthesis, visualization, explanation and publication of datasets. People posting, liking and commenting content on social media are already doing data curation, in a primitive, simple way. Active professionals in the fields of heritage preservation (library, museums), digital humanities, education, knowledge management, data-driven journalism or open-source intelligence practice data curation in a more systematic and mindful manner. The new platform will offer a consistent service of collaborative data curation empowered by a common semantic addressing system.
Augmented by deep meaning technology, our public sphere will include a semantic metadata editor applicable to any document format. It will work as a registration system for the works of the mind. Communication will be ensured by a global Twitter-like public posting system. But instead of the current hashtags that are mere sequences of characters, the new semantic tags will self-translate in all natural languages and interconnect by conceptual proximity. The blockchain layer will allow any transaction to be recorded. The platform will remunerate authors and curators in collective intelligence coins, according to the public engagement generated by their work. The new public sphere will be grounded in the internet of things, smart cities, ambient intelligence and augmented reality. People will control their environment and communicate with sensors, software agents and bots of all kinds in the same immersive semantic space. Virtual worlds will simulate the collective intelligence of teams, networks and cities.
Bootstrapping
How to bridge the gap from the fundamental research to the full scale industrial platform? Such endeavor will be much less expensive than the conquest of space and could bring a tremendous augmentation of human collective intelligence. Even if the network effect applies obviously to the new public space, small communities of pioneers will benefit immediately from its early release. On the humanistic side, I have already mentioned museums and libraries, researchers in humanities and social science, collaborative learning networks, data-oriented journalists, knowledge management and business intelligence professionals, etc. On the engineering side, deep meaning opens a new sub-field of artificial intelligence that will enhance current techniques of big data analytics, machine learning, natural language processing, internet of things, augmented reality and other immersive interfaces. Because it is open source by design, the development of the new technology can be crowdsourced and shared easily among many different actors.
Let’s draw a distinction between the new public sphere, including its semantic coordinate system, and the commercial platforms that will give access to it. This distinction being made, we can imagine a consortium of big tech companies, universities and governments supporting the development of the global public service of the future. We may also imagine one of the big techs taking the lead to associate its name to the new platform and developing some hardware specialized in deep meaning. Another scenario is the foundation of a company that will ensure the construction and maintenance of the new platform as a free public service while sustaining itself by offering semantic services: research, consulting, design and training. In any case, a new international school must be established around a virtual dockyard where trainees and trainers build and improve progressively the semantic coordinate system and other basic models of the new platform. Students from various organizations and backgrounds will gain experience in the field of deep meaning and will disseminate the acquired knowledge back into their communities.
Emission de radio (Suisse romande), 25 minutes en français.
Sémantique numérique et réseaux sociaux. Vers un service public planétaire, 1h en français
You-Tube Video (in english) 1h

 Image: Bryson Koehler at the IBM innovation and disruption Forum in Toronto
Image: Bryson Koehler at the IBM innovation and disruption Forum in Toronto Image: walking meditation in front of the Lake Ontario after the IBM innovation and disruption Forum in Toronto
Image: walking meditation in front of the Lake Ontario after the IBM innovation and disruption Forum in Toronto