Conférence à Science Po-Paris le 2 octobre 2014 à 17h 30
Voici ma présentation (PDF) : 2014-Master-Class
Texte introductif à la conférence
Réfléchir l’intelligence
Quels sont les enseignements de la philosophie sur l’augmentation de l’intelligence ? « Connais-toi toi-même » nous avertit Socrate à l’aurore de la philosophie grecque. Sous la multiplicité des traditions et des approches, en Orient comme en Occident, il existe un chemin universellement recommandé : pour l’intelligence humaine, la manière la plus sûre de progresser est d’atteindre un degré supérieur de réflexivité.
Or depuis le début du XXIe siècle, nous apprenons à nous servir d’automates de manipulation symbolique opérant dans un réseau ubiquitaire. Dans le médium algorithmique, nos intelligences personnelles s’interconnectent et fonctionnent en multiples intelligences collectives enchevêtrées. Puisque le nouveau médium abrite une part croissante de notre mémoire et de nos communications, ne pourrait-il pas fonctionner comme un miroir scientifique de nos intelligences collectives ? Rien ne s’oppose à ce que le médium algorithmique supporte bientôt une vision d’ensemble objectivable et mesurable du fonctionnement de nos intelligences collectives et de la manière dont chacun de nous y participe. Dès lors, un méta-niveau d’apprentissage collectif aura été atteint.
En effet, des problèmes d’une échelle de complexité supérieure à tous ceux que l’humanité a été capable de résoudre dans le passé se posent à nous. La gestion collective de la biosphère, le renouvellement des ressources énergétiques, l’aménagement du réseau de mégapoles où nous vivons désormais, les questions afférentes au développement humain (prospérité, éducation, santé, droits humains), vont se poser avec une acuité croissante dans les décennies et les siècles qui viennent. La densité, la complexité et le rythme croissant de nos interactions exigent de nouvelles formes de coordination intellectuelle. C’est pourquoi j’ai cherché toute ma vie la meilleure manière d’utiliser le médium algorithmique afin d’augmenter notre intelligence. Quelques titres parmi les ouvrages que j’ai publié témoignent de cette quête : La Sphère sémantique. Computation, cognition, économie de l’information (2011) ; Qu’est-ce que le virtuel ? (1995) ; L’Intelligence collective (1994) ; De la Programmation considérée comme un des beaux-arts (1992) ; Les Arbres de connaissances (1992) ; L’Idéographie dynamique (1991) ; Les Technologies de l’intelligence (1990) ; La Machine univers. Création, cognition et culture informatique (1987)… Après avoir obtenu ma Chaire de Recherche du Canada en Intelligence Collective à l’Université d’Ottawa en 2002, j’ai pu me consacrer presque exclusivement à une méditation philosophique et scientifique sur la meilleure manière de réfléchir l’intelligence collective avec les moyens de communication dont nous disposons aujourd’hui, méditation dont j’ai commencé à rendre compte dans La Sphère Sémantique et que j’approfondirai dans L’intelligence algorithmique (à paraître).
Élaboration d’un programme de recherche
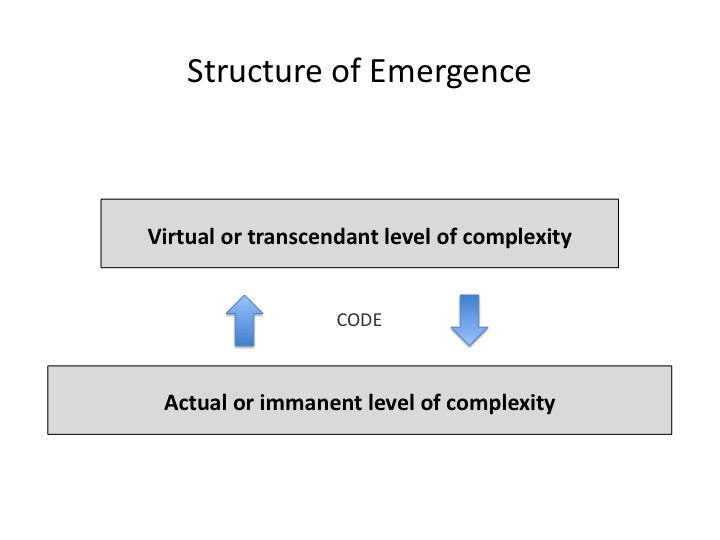
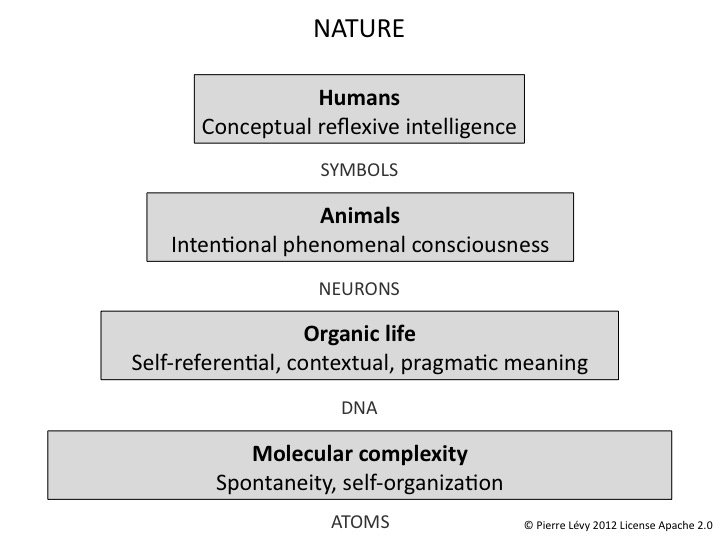
Les grands sauts évolutifs ou, si l’on préfère, les nouveaux espaces de formes, sont générés par de nouveaux systèmes de codage. Le codage atomique génère les formes moléculaires, le codage génétique engendre les formes biologiques, le codage neuronal simule les formes phénoménales. Le codage symbolique enfin, propre à l’humanité, libère l’intelligence réflexive et la culture.
Je retrouve dans l’évolution culturelle la même structure que dans l’évolution cosmique : ce sont les progrès du codage symbolique qui commandent l’agrandissement de l’intelligence humaine. En effet, notre intelligence repose toujours sur une mémoire, c’est-à-dire un ensemble d’idées enregistrées, conceptualisées et symbolisées. Elle classe, retrouve et analyse ce qu’elle a retenu en manipulant des symboles. Par conséquent, la prise de l’intelligence sur les données, ainsi que la quantité et la qualité des informations qu’elle peut en extraire, dépendent au premier chef des systèmes symboliques qu’elle utilise. Lorsqu’avec l’invention de l’écriture les symboles sont devenus auto-conservateurs, la mémoire s’est accrue, réorganisée, et un nouveau type d’intelligence est apparu, relevant d’une épistémè scribale, comme celle de l’Egypte pharaonique, de l’ancienne Mésopotamie ou de la Chine pré-confucéenne. Quand le médium écrit s’est perfectionné avec le papier, l’alphabet et la notation des nombres par position, alors la mémoire et la manipulation symbolique ont crû en puissance et l’épistémè lettrée s’est développée dans les empires grec, chinois, romain, arabe, etc. La reproduction et la diffusion automatique des symboles, de l’imprimerie aux médias électroniques, a multiplié la disponibilité des données et accéléré l’échange des idées. Née de cette mutation, l’intelligence typographique a édifié le monde moderne, son industrie, ses sciences expérimentales de la nature, ses états-nations et ses idéologies inconnues des époques précédentes. Ainsi, suivant la puissance des outils symboliques manipulés, la mémoire et l’intelligence collective évoluent, traversant des épistémès successives.

La relation entre l’ouverture d’un nouvel espace de formes et l’invention d’un système de codage se confirme encore dans l’histoire des sciences. Et puisque je suis à la recherche d’une augmentation de la connaissance réflexive, la science moderne me donne justement l’exemple d’une communauté qui réfléchit sur ses propres opérations intellectuelles et qui se pose explicitement le problème de préciser l’usage qu’elle fait de ses outils symboliques. La plupart des grandes percées de la science moderne ont été réalisées par l’unification d’une prolifération de formes disparates au moyen d’un coup de filet algébrique. En physique, le premier pas est accompli par Galilée (1564-1642), Descartes (1596-1650), Newton (1643-1727) et Leibniz (1646-1716). A la place du cosmos clos et cloisonné de la vulgate aristotélicienne qu’ils ont reçu du Moyen-Age, les fondateurs de la science moderne édifient un univers homogène, rassemblé dans l’espace de la géométrie euclidienne et dont les mouvements obéissent au calcul infinitésimal. De même, le monde des ondes électromagnétiques est-il mathématiquement unifié par Maxwell (1831-1879), celui de la chaleur, des atomes et des probabilités statistiques par Boltzmann (1844-1906). Einstein (1869-1955) parvient à unifier la matière-espace-temps en un même modèle algébrique. De Lavoisier (1743-1794) à Mendeleïev (1834, 1907), la chimie émerge de l’alchimie par la rationalisation de sa nomenclature et la découverte de lois de conservation, jusqu’à parvenir au fameux tableau périodique où une centaine d’éléments atomiques sont arrangés selon un modèle unificateur qui explique et prévoit leurs propriétés. En découvrant un code génétique identique pour toutes les formes de vie, Crick (1916-2004) et Watson (1928-) ouvrent la voie à la biologie moléculaire.
Enfin, les mathématiques n’ont-elles pas progressé par la découverte de nouvelles manières de coder les problèmes et les solutions ? Chaque avancée dans le niveau d’abstraction du codage symbolique ouvre un nouveau champ à la résolution de problèmes. Ce qui apparaissait antérieurement comme une multitude d’énigmes disparates se résout alors selon des procédures uniformes et simplifiées. Il en est ainsi de la création de la géométrie démonstrative par les Grecs (entre le Ve et le IIe siècle avant l’ère commune) et de la formalisation du raisonnement logique par Aristote (384-322 avant l’ère commune). La même remontée en amont vers la généralité s’est produite avec la création de la géométrie algébrique par Descartes (1596-1650), puis par la découverte et la formalisation progressive de la notion de fonction. Au tournant des XIXe et XXe siècles, à l’époque de Cantor (1845-1918), de Poincaré (1854-1912) et de Hilbert (1862-1943), l’axiomatisation des théories mathématiques est contemporaine de la floraison de la théorie des ensembles, des structures algébriques et de la topologie.
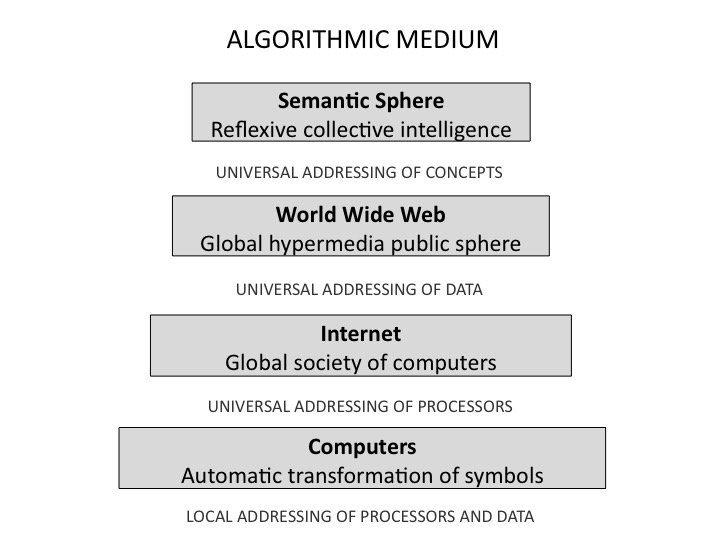
Mon Odyssée encyclopédique m’a enseigné cette loi méta-évolutive : les sauts intellectuels vers des niveaux de complexité supérieurs s’appuient sur de nouveaux systèmes de codage. J’en viens donc à me poser la question suivante. Quel nouveau système de codage fera du médium algorithmique un miroir scientifique de notre intelligence collective ? Or ce médium se compose justement d’un empilement de systèmes de codage : codage binaire des nombres, codage numérique de caractères d’écriture, de sons et d’images, codage des adresses des informations dans les disques durs, des ordinateurs dans le réseau, des données sur le Web… La mémoire mondiale est déjà techniquement unifiée par tous ces systèmes de codage. Mais elle est encore fragmentée sur un plan sémantique. Il manque donc un nouveau système de codage qui rende la sémantique aussi calculable que les nombres, les sons et les images : un système de codage qui adresse uniformément les concepts, quelles que soient les langues naturelles dans lesquelles ils sont exprimés.

En somme, si nous voulons atteindre une intelligence collective réflexive dans le médium algorithmique, il nous faut unifier la mémoire numérique par un code sémantique interopérable, qui décloisonne les langues, les cultures et les disciplines.
Tour d’horizon techno-scientifique
Désormais en possession de mon programme de recherche, il me faut évaluer l’avancée du médium algorithmique contemporain vers l’intelligence collective réflexive : nous n’en sommes pas si loin… Entre réalité augmentée et mondes virtuels, nous communiquons dans un réseau électronique massivement distribué qui s’étend sur la planète à vitesse accélérée. Des usagers par milliards échangent des messages, commandent des traitements de données et accèdent à toutes sortes d’informations au moyen d’une tablette légère ou d’un téléphone intelligent. Objets fixes ou mobiles, véhicules et personnes géo-localisés signalent leur position et cartographient automatiquement leur environnement. Tous émettent et reçoivent des flots d’information, tous font appel à la puissance du cloud computing. Des efforts de Douglas Engelbart à ceux de Steve Jobs, le calcul électronique dans toute sa complexité a été mis à la portée de la sensori-motricité humaine ordinaire. Par l’invention du Web, Sir Tim Berners-Lee a rassemblé l’ensemble des données dans une mémoire adressée par le même système d’URL. Du texte statique sur papier, nous sommes passé à l’hypertexte ubiquitaire. L’entreprise de rédaction et d’édition collective de Wikipedia, ainsi qu’une multitude d’autres initiatives ouvertes et collaboratives ont mis gratuitement à la portée de tous un savoir encyclopédique, des données ouvertes réutilisables et une foule d’outils logiciels libres. Des premiers newsgroups à Facebook et Twitter, une nouvelle forme de sociabilité par le réseau s’est imposée, à laquelle participent désormais l’ensemble des populations. Les blogs ont mis la publication à la portée de tous. Tout cela étant désormais acquis, notre intelligence doit maintenant franchir le pas décisif qui lui permettra de maîtriser un niveau supérieur de complexité cognitive.
Du côté de la Silicon Valley, on cherche des réponses de plus en plus fines aux désirs des utilisateurs, et cela d’autant mieux que les big data analytics offrent les moyens d’en tracer le portrait fidèle. Mais il me semble peu probable que l’amélioration incrémentale des services rendus par les grandes entreprises du Web, même guidée par une bonne stratégie marketing, nous mène spontanément à l’unification sémantique de la mémoire numérique. L’entreprise non commerciale du « Web sémantique » promeut d’utiles standards de fichier (XML, RDF) et des langages de programmation ouverts (comme OWL), mais ses nombreuses ontologies sont hétéroclites et elle a échoué à résoudre le problème de l’interopérabilité sémantique. Parmi les projets les plus avancés d’intelligence computationnelle, aucun ne vise explicitement la création d’une nouvelle génération d’outils symboliques. Certains nourrissent même la chimère d’ordinateurs conscients devenant autonomes et prenant le pouvoir sur la planète avec la complicité de cyborgs post-humain…
La lumière viendra-t-elle des recherches académiques sur l’intelligence collective et le knowledge management ? Depuis les travaux pionniers de Nonaka à la fin du XXe siècle, nous savons qu’une saine gestion des connaissances suppose l’explicitation et la communication des savoirs implicites. L’expérience des médias sociaux nous a enseigné la nécessité d’associer étroitement gestion sociale et gestion personnelle des connaissances. Or, dans les faits, la gestion des connaissances par les médias sociaux passe nécessairement par la curation distribuée d’une énorme quantité de données. C’est pourquoi, on ne pourra coordonner le travail de curation collective et exploiter efficacement les données qu’au moyen d’un codage sémantique commun. Mais personne ne propose de solution au problème de l’interopérabilité sémantique.
Le secours nous viendra-t-il des sciences humaines, par l’intermédiaire des fameuses digital humanities ? L’effort pour éditer et mettre en libre accès les corpus, pour traiter et visualiser les données avec les outils des big data et pour organiser les communautés de chercheurs autour de ce traitement est méritoire. Je souscris sans réserve à l’orientation vers le libre et l’open. Mais je ne discerne pour l’instant aucun travail de fond pour résoudre les immenses problèmes de fragmentation disciplinaire, de testabilité des hypothèses et d’hyper-localité théorique qui empêchent les sciences humaines d’émerger de leur moyen-âge épistémologique. Ici encore, nulle théorie de la cognition, ni de la cognition sociale, permettant de coordonner l’ensemble des recherches, pas de système de catégorisation sémantique inter-opérable en vue et peu d’entreprises pratiques pour remettre l’interrogation scientifique sur l’humain entre les mains des communautés elles-mêmes. Quant à diriger l’évolution technique selon les besoins de sciences humaines renouvelées, la question ne semble même pas se poser. Il ne reste finalement que la posture critique, comme celle que manifestent, par exemple, Evgeny Morozov aux Etats-Unis et d’autres en Europe ou ailleurs. Mais si les dénonciations de l’avidité des grandes compagnies de la Silicon Valley et du caractère simpliste, voire dérisoire, des conceptions politiques, sociales et culturelles des chantres béats de l’algorithme touchent souvent juste, on chercherait en vain du côté des dénonciateurs le moindre début de proposition concrète.
En conclusion, je ne discerne autour de moi aucun plan sérieux propre à mettre la puissance computationnelle et les torrents de données du médium algorithmique au service d’une nouvelle forme d’intelligence réflexive. Ma conviction, je la puise dans une longue étude du problème à résoudre. Quant à ma solitude provisoire en 2014, au moment où j’écris ces lignes, je me l’explique par le fait que personne n’a consacré plus de quinze ans à temps plein pour résoudre le problème de l’interopérabilité sémantique. Je m’en console en observant l’exemple admirable de Douglas Engelbart. Ce visionnaire a inventé les interfaces sensori-motrices et les logiciels collaboratifs à une époque où toutes les subventions allaient à l’intelligence artificielle. Ce n’est que bien des années après qu’il ait exposé sa vision de l’avenir dans les années 1960 qu’il fut suivi par l’industrie et la masse des utilisateurs à partir de la fin des années 1980. Sa vision n’était pas seulement technique. Il a appelé à franchir un seuil décisif d’augmentation de l’intelligence collective afin de relever les défis de plus en plus pressants qui se posent, encore aujourd’hui, à notre espèce. Je poursuis son travail. Après avoir commencé à dompter le calcul automatique par nos interactions sensori-motrices avec des hypertextes, il nous faut maintenant explicitement utiliser le médium algorithmique comme une extension cognitive. Mes recherches m’ont affermi dans la conviction que nulle solution technique ignorante de la complexité de la cognition humaine ne nous mènera à bon port. Nous ne pourrons obtenir une intelligence agrandie qu’avec une claire théorie de la cognition et une profonde compréhension des ressorts de la mutation anthropologique à venir. Enfin, sur un plan technique, le rassemblement de la sagesse collective de l’humanité nécessite une unification sémantique de sa mémoire. C’est en respectant toutes ces exigences que j’ai conçu et construit IEML, outil commun d’une nouvelle puissance intellectuelle, origine d’une révolution scientifique.
Les ressorts d’une révolution scientifique
La mise en oeuvre de mon programme de recherche ne sera pas moins complexe ou ambitieuse que d’autres grands projets scientifiques et techniques, comme ceux qui nous ont mené à marcher sur la Lune ou à déchiffrer le génome humain. Cette grande entreprise va mobiliser de vastes réseaux de chercheurs en sciences humaines, en linguistique et en informatique. J’ai déjà réuni un petit groupe d’ingénieurs et de traducteurs dans ma Chaire de Recherche de l’Université d’Ottawa. Avec les moyens d’un laboratoire universitaire en sciences humaines, j’ai trouvé le code que je cherchais et j’ai prévu de quelle manière son utilisation allait mener à une intelligence collective réflexive.
J’étais bien résolu à ne pas me laisser prendre au piège qui consisterait à aménager superficiellement quelque système symbolique de l’épistémè typographique pour l’adapter au nouveau médium, à l’instar des premiers wagons de chemin de fer qui ressemblaient à des diligences. Au contraire, j’étais persuadé que nous ne pourrions passer à une nouvelle épistémè qu’au moyen d’un système symbolique conçu dès l’origine pour unifier et exploiter la puissance du médium algorithmique.

Voici en résumé les principales étapes de mon raisonnement. Premièrement, comment pourrais-je augmenter effectivement l’intelligence collective sans en avoir de connaissance scientifique ? C’est donc une science de l’intelligence collective qu’il me faut. Je fais alors un pas de plus dans la recherche des conditions. Une science de l’intelligence collective suppose nécessairement une science de la cognition en général, car la dimension collective n’est qu’un aspect de la cognition humaine. J’ai donc besoin d’une science de la cognition. Mais comment modéliser rigoureusement la cognition humaine, sa culture et ses idées, sans modéliser au préalable le langage qui en est une composante capitale ? Puisque l’humain est un animal parlant – c’est-à-dire un spécialiste de la manipulation symbolique – un modèle scientifique de la cognition doit nécessairement contenir un modèle du langage. Enfin, dernier coup de pioche avant d’atteindre le roc : une science du langage ne nécessite-t-elle pas un langage scientifique ? En effet, vouloir une science computationnelle du langage sans disposer d’une langue mathématique revient à prétendre mesurer des longueurs sans unités ni instruments. Or je ne dispose avant d’avoir construit IEML que d’une modélisation algébrique de la syntaxe : la théorie chomskienne et ses variantes ne s’étendent pas jusqu’à la sémantique. La linguistique me donne des descriptions précises des langues naturelles dans tous leurs aspects, y compris sémantiques, mais elle ne me fournit pas de modèles algébriques universels. Je comprends donc l’origine des difficultés de la traduction automatique, des années 1950 jusqu’à nos jours.
Parce que le métalangage IEML fournit un codage algébrique de la sémantique il autorise une modélisation mathématique du langage et de la cognition, il ouvre en fin de compte à notre intelligence collective l’immense bénéfice de la réflexivité.
IEML, outil symbolique de la nouvelle épistémè
Si je dois contribuer à augmenter l’intelligence humaine, notre intelligence, il me faut d’abord comprendre ses conditions de fonctionnement. Pour synthétiser en quelques mots ce que m’ont enseigné de nombreuses années de recherches, l’intelligence dépend avant tout de la manipulation symbolique. De même que nos mains contrôlent des outils qui augmentent notre puissance matérielle, c’est grâce à sa capacité de manipulation de symboles que notre cognition atteint à l’intelligence réflexive. L’organisme humain a partout la même structure, mais son emprise sur son environnement physico-biologique varie en fonction des techniques mises en oeuvre. De la même manière, la cognition possède une structure fonctionnelle invariable, innée aux êtres humains, mais elle manie des outils symboliques dont la puissance augmente au rythme de leur évolution : écriture, imprimerie, médias électroniques, ordinateurs… L’intelligence commande ses outils symboliques par l’intermédiaire de ses idées et de ses concepts, comme la tête commande aux outils matériels par l’intermédiaire du bras et de la main. Quant aux symboles, ils fournissent leur puissance aux processus intellectuels. La force et la subtilité conférée par les symboles à la conceptualisation se répercute sur les idées et, de là, sur la communication et la mémoire pour soutenir, en fin de compte, les capacités de l’intelligence.
J’ai donc construit le nouvel outil de telle sorte qu’il tire le maximum de la nouvelle puissance offerte par le médium algorithmique global. IEML n’est ni un système de classification, ni une ontologie, ni même une super-ontologie universelle, mais une langue. Comme toute langue, IEML noue une syntaxe, une sémantique et une pragmatique. Mais c’est une langue artificielle : sa syntaxe est calculable, sa sémantique traduit les langues naturelles et sa pragmatique programme des écosystèmes d’idées. La syntaxe, la sémantique et la pragmatique d’IEML fonctionnent de manière interdépendante. Du point de vue syntaxique, l’algèbre d’IEML commande une topologie des relations. De ce fait, les connexions linguistiques entre textes et hypertextes dynamiques se calculent automatiquement. Du point de vue sémantique, un code – c’est-à-dire un système d’écriture, une grammaire et un dictionnaire multilingue – donne sens à l’algèbre. Il en résulte que chacune des variables de l’algèbre devient un noeud d’inter-traduction entre langues naturelles. Les utilisateurs peuvent alors communiquer en IEML tout en utilisant la – ou les – langues naturelles de leur choix. Du point de vue pragmatique enfin, IEML commande la simulation d’écosystèmes d’idées. Les données catégorisées en IEML s’organisent automatiquement en hypertextes dynamiques, explorables et auto-explicatifs. IEML fonctionne donc en pratique comme un outil de programmation distribuée d’une simulation cognitive globale.
Le futur algorithmique de l’intelligence
Lorsqu’elle aura pris en main ce nouvel outil symbolique, notre espèce laissera derrière elle une épistémè typographique assimilée et assumée pour entrer dans le vaste champ de l’intelligence algorithmique. Une nouvelle mémoire accueillera des torrents de données en provenance de milliards de sources et transformera automatiquement le déluge d’information en hypertextes dynamiques auto-organisateurs. Alors que Wikipedia conserve un système de catégorisation hérité de l’épistémè typographique, une bibliothèque encyclopédique perspectiviste s’ouvrira à tous les systèmes de classification possibles. En s’auto-organisant en fonction des points de vue adoptés par leurs explorateurs, les données catégorisées en IEML reflèteront le fonctionnement multi-polaire de l’intelligence collective.
Les relations entre hypertextes dynamiques vont se projeter dans une fiction calculée multi-sensorielle explorable en trois dimensions. Mais c’est une réalité cognitive que les nouveaux mondes virtuels vont simuler. Leur spatio-temporalité sera donc bien différente de celle du monde matériel puisque c’est ici la forme de l’intelligence, et non celle de la réalité physique ordinaire, qui va se laisser explorer par la sensori-motricité humaine.
De la curation collaborative de données émergera de nouveaux types de jeux intellectuels et sociaux. Des collectifs d’apprentissage, de production et d’action communiqueront sur un mode stigmergique en sculptant leur mémoire commune. Les joueurs construiront ainsi leurs identités individuelles et collectives. Leurs tendances émotionnelles et les directions de leurs attentions se reflèteront dans les fluctuations et les cycles de la mémoire commune.
A partir de nouvelles méthodes de mesure et de comptabilité sémantique basés sur IEML, l’ouverture et la transparence des processus de production de connaissance vont connaître un nouvel essor. Les études de la cognition et de la conscience disposeront non seulement d’une nouvelle théorie, mais aussi d’un nouvel instrument d’observation, d’analyse et de simulation. Il deviendra possible d’accumuler et de partager l’expertise sur la culture des écosystèmes d’idées. Nous allons commencer à nous interroger sur l’équilibre, l’interdépendance, la fécondité croisée de ces écosystèmes d’idées. Quels services rendent-ils aux communautés qui les produisent ? Quels sont leurs effets sur le développement humain ?
Le grand projet d’union des intelligences auquel je convie ne sera le fruit d’aucune conquête militaire, ni de la victoire sur les esprits d’une idéologie politique ou religieuse. Elle résultera d’une révolution cognitive à fondement techno-scientifique. Loin de tout esprit de table rase radicale, la nouvelle épistémè conservera les concepts des épistémè antérieures. Mais ce legs du passé sera repris dans un nouveau contexte, plus vaste, et par une intelligence plus puissante.
[Image en tête de l’article: “Le Miroir” de Paul Delvaux, 1936]