Aujourd’hui, le monde entier se précipite vers l’IA statistique, les modèles neuronaux et/ou l’IA générative. Mais nous savons que, bien que ces modèles soient utiles, nous avons toujours besoin de modèles symboliques ou, si vous préférez, de graphes de connaissances, en particulier dans le domaine de la gestion des connaissances.
Mais pourquoi exactement avons-nous encore besoin de modèles symboliques en plus des modèles neuronaux ? Parce que les modèles symboliques sont capables de représenter la connaissance de manière explicite, ce qui comporte beaucoup d’avantages, notamment la transparence et l’explicabilité. Dans cet exposé, je vais plaider en faveur de l’interopérabilité sémantique (ou conceptuelle) entre les graphes de connaissances, et je présenterai IEML, un langage que j’ai inventé à la Chaire de Recherche du Canada en intelligence collective (2002-2016) avec l’aide de mon équipe d’ingénieurs.

Si vous êtes familier avec le domaine de la gestion des connaissances, vous savez qu’il existe une dialectique entre les connaissances implicites (en bleu sur la Figure 1) et les connaissances explicites (en rouge sur la Figure 1).
Il existe actuellement deux façons principales de traiter les données pour la gestion des connaissances.
- Via des modèles neuronaux, basés principalement sur les statistiques, pour l’aide à la décision, la compréhension automatique et la génération de données.
- Via des modèles symboliques, basés sur la logique et la sémantique, pour l’aide à la décision et la recherche avancée.
Ces deux approches sont généralement distinctes et correspondent à deux cultures d’ingénieurs différentes. En raison de leurs avantages et de leurs inconvénients, les gens essaient de les combiner.
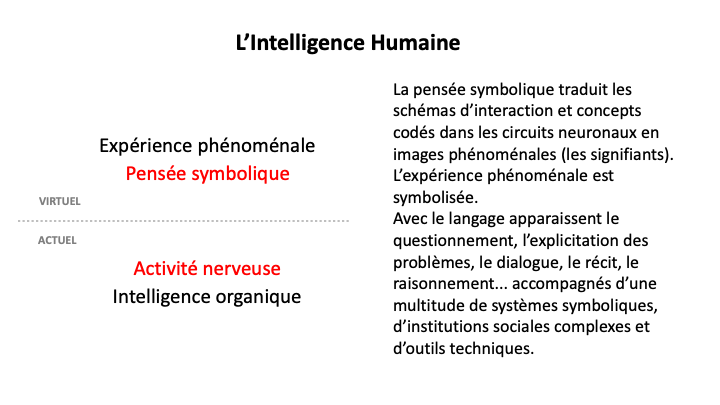
Clarifions maintenant la différence entre les modèles ” neuronaux ” et ” symboliques ” et comparons-les à la cognition neuronale et symbolique chez les êtres humains.
Le grand avantage des modèles neuronaux est leur capacité à synthétiser et à mobiliser la mémoire numérique “juste à temps”, ou “à la demande”, et à le faire automatiquement, ce qui est impossible pour un cerveau humain. Mais leur processus de reconnaissance et de génération de données est statistique, ce qui signifie qu’ils ne peuvent pas organiser un monde, ils ne maîtrisent pas la conservation des objets, ils n’ont pas de compréhension du temps et de la causalité, ou de l’espace et de la géométrie. Ils ne peuvent pas toujours reconnaître les transformations d’images d’un même objet comme le font les êtres vivants.
En revanche, les neurones vivants peuvent faire des choses que les neurones formels actuels ne peuvent pas faire. Les animaux, même sans modèles symboliques, avec leurs neurones naturels, sont capables de modéliser le monde, d’utiliser des concepts, ils conservent les objets malgré leurs transformations, ils appréhendent le temps, la causalité, l’espace, etc. Et les cerveaux humains ont la capacité de faire fonctionner des systèmes symboliques, comme le langage.
Quels sont les aspects positifs des modèles symboliques de l’IA, ou graphes de connaissances?
- Il s’agit de modèles explicites du monde, plus précisément d’un monde pratique local.
- Ils sont en principe auto-explicatifs, si le modèle n’est pas trop complexe.
- ils ont de fortes capacités de raisonnement.
Tout cela les rend plutôt fiables, comparativement aux modèles neuronaux, qui sont probabilistes. Cependant, les modèles symboliques actuels présentent deux faiblesses.
- Leur conception prend du temps. Ils sont coûteux en termes de main-d’œuvre spécialisée.
- Ils n’ont ni “conservation des concepts” ni “conservation des relations” entre les ontologies ou domaines. Dans un domaine particulier donné, chaque concept et chaque relation doivent être définis logiquement un par un.
S’il existe une interopérabilité au niveau des formats de fichiers pour les métadonnées sémantiques (ou les systèmes de classification), cette interopérabilité n’existe pas au niveau sémantique des concepts, ce qui cloisonne les graphes de connaissances, et par conséquent l’intelligence collective.
En revanche, dans la vie réelle, des humains issus de métiers ou de domaines de connaissances différents se comprennent en partageant la même langue naturelle. En effet, dans la cognition humaine, un concept est déterminé par un réseau de relations inhérent aux langues naturelles.
Mais qu’est-ce que j’entends par “le sens d’un concept est déterminé par un réseau de relations inhérent aux langues naturelles” ? Quel est ce réseau de relations ? Et pourquoi est-ce que je le souligne dans cet article ? Parce que je crois que l’IA symbolique actuelle passe à côté de l’aspect sémantique des langues. Faisons donc un peu de linguistique pour mieux comprendre.

Toute langue naturelle tisse trois types de relations : l’interdéfinition, la composition et la substitution.
- Tout d’abord, le sens de chaque mot est défini par une phrase qui implique d’autres mots, eux-mêmes définis de la même manière. Un dictionnaire englobe notamment une inter-définition circulaire ou enchevêtrée de concepts.
- Ensuite, grâce aux règles de grammaire, on peut composer des phrases originales et comprendre de nouveaux sens.
- Enfin, tous les mots d’une phrase ne peuvent pas être remplacés par n’importe quel autre ; il existe des règles pour les substitutions possibles qui contribuent au sens des mots et des phrases.
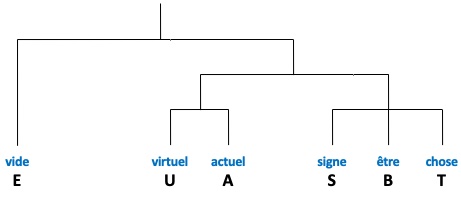
Vous comprenez la phrase “Je peins la petite pièce en bleu” (voir Figure 2) parce que vous connaissez les définitions de chaque mot, vous connaissez les règles grammaticales qui donnent à chaque mot son rôle dans la phrase, et vous savez par quoi les mots actuels pourraient être remplacés. C’est ce qu’on appelle la sémantique linguistique.
Il n’est pas nécessaire de définir une à une ces relations d’inter-définition, de composition et de substitution entre concepts chaque fois que l’on parle de quelque chose. Tout cela est inclus dans la langue. Malheureusement, nous ne disposons d’aucune de ces fonctions sémantiques lorsque nous construisons les graphes de connaissances actuels. Et c’est là qu’IEML pourrait contribuer à améliorer les méthodes de l’IA symbolique et de la gestion des connaissances.
Pour comprendre mon argumentation, il est important de faire la distinction entre la sémantique linguistique et la sémantique référentielle. La sémantique linguistique concerne les relations entre les concepts. La sémantique référentielle concerne les relations entre les propositions et les états de choses ou entre les noms propres et les individus.
Si la sémantique linguistique tisse des relations entre les concepts, pourquoi ne pouvons-nous pas utiliser les langues naturelles dans les modèles symboliques ? Nous connaissons tous la réponse. Les langues naturelles sont ambiguës (grammaticalement et lexicalement) et les machines ne peuvent pas désambiguïser le sens en fonction du contexte. Dans l’IA symbolique actuelle, nous ne pouvons pas compter sur le langage naturel pour susciter organiquement des relations sémantiques.
Alors, comment construit-on un modèle symbolique aujourd’hui ?
- Pour définir les concepts, nous devons les relier à des URI (Uniform Resource Identifier) ou à des pages web, selon le modèle de la sémantique référentielle.
- Mais comme la sémantique référentielle est insuffisante pour décrire un réseau de relations, au lieu de s’appuyer sur la sémantique linguistique, il faut imposer des relations sémantiques aux concepts un par un.
C’est la raison pour laquelle la conception des graphes de connaissances prend tant de temps et c’est aussi pourquoi il n’existe pas d’interopérabilité sémantique générale des graphes de connaissances entre les ontologies ou les domaines de connaissance. Encore une fois, je parle ici d’interopérabilité au niveau sémantique ou conceptuel et non au niveau du format.
Afin de pallier les insuffisances des modèles symboliques actuels, j’ai construit un métalangage qui présente les mêmes avantages que les langues naturelles, à savoir un mécanisme inhérent de construction de réseaux sémantiques, mais qui n’a pas leurs inconvénients, puisqu’il est sans ambiguïté et calculable.
IEML (le méta-langage de l’économie de l’information), est un métalangage sémantique non ambigu et calculable qui inclut un système d’inter-définition, de composition et de substitution de concepts.
L’objectif de cette invention est de faciliter la conception de graphes de connaissances et d’ontologies, d’assurer leur interopérabilité sémantique et de favoriser leur conception collaborative. La vision qui inspire IEML est une intelligence collective à support numérique et augmentée par l’IA.
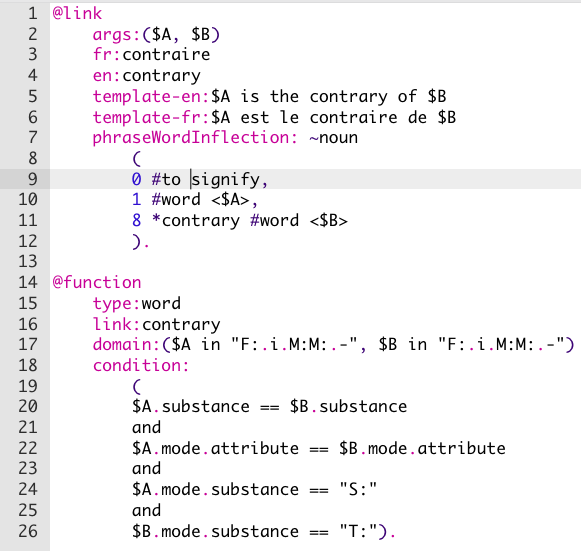
IEML a le pouvoir d’expression d’un langage naturel et possède une structure algébrique qui lui permet d’être entièrement calculable. IEML n’est pas seulement calculable dans sa dimension syntaxique, mais aussi dans sa dimension sémantique linguistique, car ses relations sémantiques (en particulier les relations de composition et de substitution) sont des fonctions calculables de ses relations syntaxiques. Il n’existe aujourd’hui aucun autre système symbolique ayant ces propriétés.
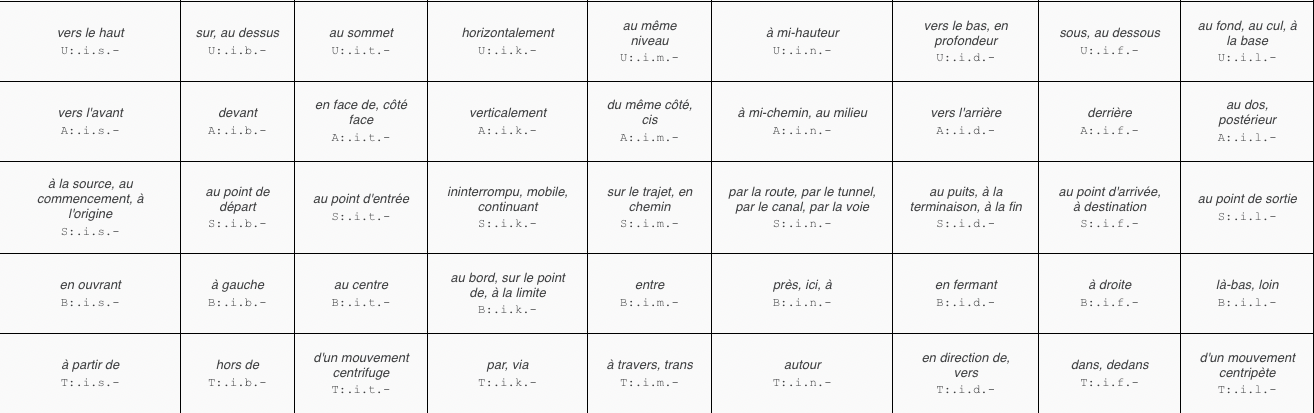
IEML dispose d’une grammaire entièrement régulière et récursive ainsi que d’un dictionnaire de trois mille mots organisés en paradigmes (systèmes de substitution) permettant la construction (récursive et grammaticale) de n’importe quel concept. En somme, tout concept peut être construit à partir d’un petit nombre de briques lexicales selon des règles de composition universelles simples.
Comme chaque concept est automatiquement défini par des relations de composition et de substitution avec d’autres concepts et par des explications impliquant les concepts de base du dictionnaire et conformes à la grammaire IEML, IEML est son propre métalangage. Il peut traduire n’importe quelle langue naturelle. Le dictionnaire en IEML est actuellement traduit en français et en anglais.
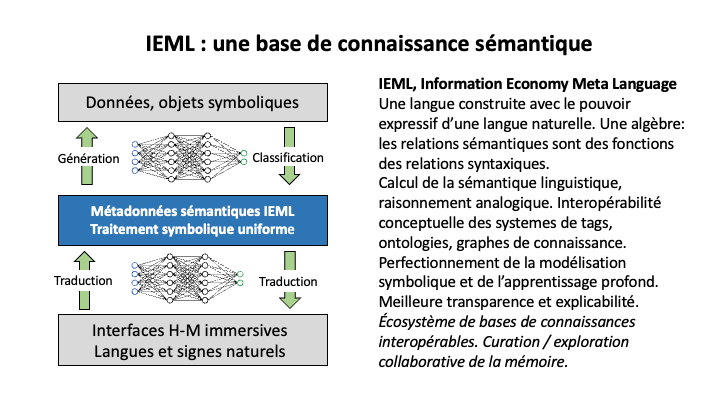
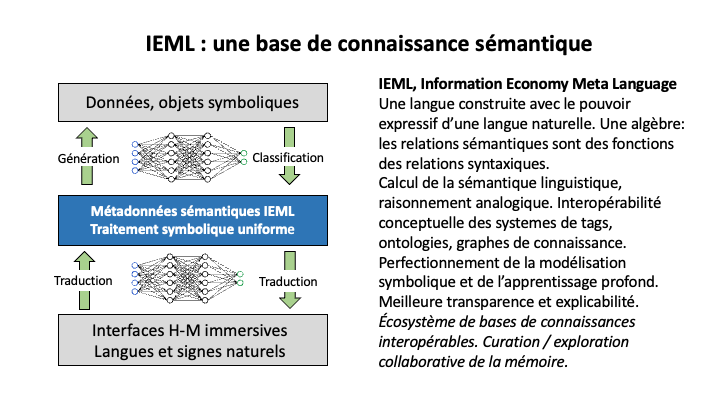
IEML permet de coupler les modèles symboliques et neuronaux, et de surmonter leurs limitations et séparations dans une architecture innovante et intégrée.
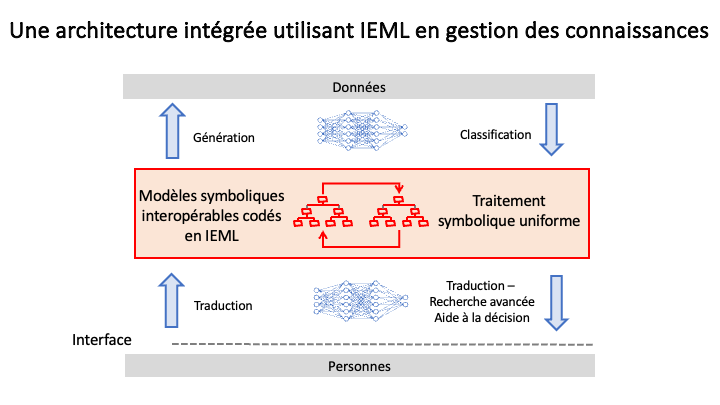
La diapositive ci-dessus (Figure 3) présente la nouvelle architecture sémantique pour la gestion des connaissances qu’IEML rend possible, une architecture qui conjoint les modèles neuronaux et symboliques.
La seule chose qui puisse générer tous les concepts dont nous avons besoin pour exprimer la complexité des domaines de connaissance, tout en maintenant la compréhension mutuelle, est une langue. Mais les langues naturelles sont irrégulières et ambiguës, et leur sémantique ne peut être calculée. IEML étant un langage algébrique univoque et formel (contrairement aux langues naturelles), il peut exprimer tous les concepts possibles (comme dans les langues naturelles), et ses relations sémantiques sont densément tissées grâce à un mécanisme intégré. C’est pourquoi nous pouvons utiliser IEML comme un langage de métadonnées sémantiques pratique pour exprimer n’importe quel modèle symbolique ET nous pouvons le faire de manière interopérable. Encore une fois, je parle d’interopérabilité conceptuelle. En IEML, tous les modèles symboliques peuvent échanger des modules de connaissance et le raisonnement transversal aux ontologies devient la norme.
Comment les modèles neuronaux sont-ils utilisés dans cette nouvelle architecture ? Les modèles neuronaux traduisent automatiquement le langage naturel en IEML, donc pas de travail ou d’apprentissage supplémentaire pour le profane. Ils pourraient même aider à traduire des descriptions informelles en langage naturel en un modèle formel exprimé en IEML.
Les consignes (prompts) seraient exprimées en IEML en coulisse, de sorte que la génération de données soit mieux contrôlée.
Nous pourrions également utiliser des modèles neuronaux pour classer ou étiqueter automatiquement des données en IEML. Les étiquettes exprimées en IEML permettront un apprentissage automatique plus efficace, car les unités ou “tokens” pris en compte ne seraient plus des unités sonores – caractères, syllabes, mots – des langues naturelles, mais des concepts générés par une algèbre sémantique.
Quels seraient les avantages d’une architecture intégrée de gestion des connaissances utilisant IEML comme système de coordonnées sémantiques ?
- Les modèles symboliques et neuronaux fonctionneraient ensemble au profit de la gestion des connaissances.
- Un système de coordonnées sémantiques commun faciliterait la mutualisation des modèles et des données. Les modèles symboliques seraient interopérables et plus faciles à concevoir et à formaliser. Leur conception serait collaborative, y compris d’un domaine à l’autre. L’usage d’un métalangage sémantique comme IEML amélioreraient également la productivité intellectuelle grâce à une automatisation partielle de la conceptualisation.
- Les modèles neuronaux seraient basés sur des étiquettes codées en IEML et donc plus transparents, explicables et fiables. L’avantage serait non seulement technique, mais aussi d’ordre éthique.
- Enfin, cette architecture favoriserait la diversité et la liberté de création, puisque les réseaux de concepts, ou graphes de connaissances, formulés en IEML peuvent être différenciés et complexifiés à volonté.
RÉFÉRENCES POUR IEML
Scientific paper (English) in Collective Intelligence Journal,2023 https://journals.sagepub.com/doi/full/10.1177/26339137231207634
Article scientifique (Français) in Humanités numériques, 2023 https://journals.openedition.org/revuehn/3836
Website / site web: https://intlekt.io/
Book: The Semantic Sphere, Computation, Cognition and Information Economy. Wiley, 2011
Livre: La Sphère sémantique. Computation, cognition, économie de l’information. Lavoisier, 2011