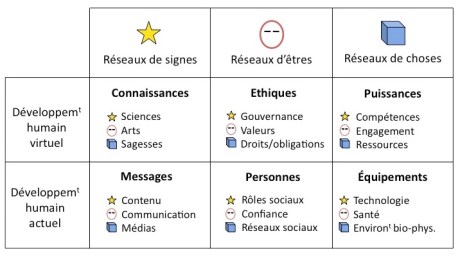
Carte sémantique de l’intelligence collective
La carte ci-dessus schématise les grandes structures de l’intelligence collective humaine telles que nous les appréhendons au début du XXIe siècle. Le signe y est signalé par une étoile, l’être par un visage et la chose par un cube. L’intelligence collective se présente comme une boucle d’interdépendance entre le développement humain actuel et le développement humain virtuel (sur les catégories sémantiques virtuel, actuel, signe, être et chose, voir ce post). Le développement actuel comprend trois facettes qui sont elles-mêmes interdépendantes : celle des messages , des personnes et des équipements. Ces trois facettes actuelles concernent des facteurs ou des processus qui sont plongés dans l’espace et le temps. Le développement virtuel comprend lui aussi trois facettes interdépendantes : la connaissance, l’éthique et la puissance. Par contraste avec les facettes actuelles, les facettes virtuelles désignent des états d’esprit, des règles ou des potentialités. Le développement virtuel dépend du développement actuel comme de sa base matérielle tandis que le développement actuel dépend du développement virtuel comme de son instance de coordination, de pilotage et de traction. L’intelligence collective peut également s’analyser comme une dialectique d’interdépendance entre trois types de réseaux représentés par les colonnes de la carte : les réseaux de signes (connaissances et messages), d’êtres (éthiques et personnes) et de choses (puissances, équipements).
Chacune des six catégories principales s’analyse à son tour comme une dynamique de transformation entre trois sous-catégories de niveau inférieur selon la symétrie signe/être/chose. Dans la transformation symétrique interne à chacune des six catégories principales de l’intelligence collective, la chose représente la dimension la plus « dure » ou la plus objective ; l’être est chargé d’émotion et se déploie dans les rapports humains ; enfin le signe indique une dimension cognitive qui oriente le contenu de la catégorie. On comprend ici que des symétries sémantiques virtuel/actuel et signe/être/chose peuvent se décliner récursivement à l’intérieur de n’importe quelle catégorie et que la modélisation par les systèmes de relations sémantiques peut être raffinée à loisir.
En inspectant la carte sémantique de l’intelligence collective, il faut supposer qu’une variation des données empiriques dans une catégorie se répercutera d’une manière ou d’une autre dans la variation empirique des catégories symétriques et que les données catégorisées par les différentes facettes tendent à s’équilibrer en fonction de leurs relations d’interdépendance. Par exemple, il est impossible de garder de manière durable une force dans une des six catégories principales et des faiblesses dans les autres. Nous allons maintenant explorer une par une les six catégories principales de l’intelligence collective. Il faut imaginer ce système de relations sémantiques comme un tableau de bord qui documente en temps réel l’évolution de l’intelligence collective d’une communauté (son contenu, ses forces, ses faiblesses, ses connexions internes) sur un mode visuel et interactif, à partir d’un flux de données spécialement sélectionné à cet effet. On imaginera également que l’individu ou le groupe qui interagit avec le tableau de bord peut visualiser sa propre contribution à l’intelligence collective et ce qu’il en reçoit.
Connaissances
Une foule de styles de savoirs – académiques ou non-académiques – alimentent le « capital épistémique » d’une communauté. Les réseaux de connaissances n’excluent a priori aucun genre de savoir ni aucun type de relation entre les savoirs. Cette catégorie rassemble donc la variété ouverte des types de connaissance portés par une communauté à partir de l’intuition fondamentale qu’ils se multiplient les uns par les autres et qu’ils peuvent tous contribuer à leur manière au développement humain dans son ensemble. Les connaissances contiennent notamment, comme une sous-fonction cognitive spécialement consacrée à la réflexivité de l’intelligence collective, une représentation synthétique de l’intelligence collective elle-même. Une image holistique du développement humain est donc contenue dans la catégorie de la connaissance, qui n’est pourtant qu’une partie du développement humain pris comme un tout.
La distinction entre arts et sciences peut se décliner, par exemple, en savoirs du vrai et savoirs du beau, jugements logiques et jugements de goût. On peut encore opposer, d’une part, les savoirs explicites, calculables, basés sur l’observation, l’expérimentation contrôlée, la démonstration et l’explication et, d’autre part, les savoirs implicites, incalculables, fondés sur l’expérience personnelle, la transmission traditionnelle et l’autorité de la coutume. Quant à la sagesse, le terme traduit les termes grecs Sophia, plus théorique, et Phronésis, plus pratique, mais aussi la Sapientia latine, la Hochma hébraïque, la Hekmah arabe, le Yoga indien, les Voies de l’Asie du Sud-Est, etc. Les sagesses concernent les savoir-être, les arts de la maîtrise de soi, de la prudence, du jugement droit et de l’action en résonance avec les rythmes fondamentaux.
Ethiques
La multitude des éthiques comprend les valeurs, normes et priorités (quelles qu’elles soient) qui orientent la gouvernance, ainsi que les systèmes de droits et d’obligations qui régulent les comportements, les décisions et évaluations en tous genres ayant cours dans la communauté considérée. De même que la catégorie « connaissance » n’impliquait aucune prise de parti dans les controverses concernant le vrai, le beau, le sage, la validité ou le bon goût des représentations, la catégorie éthique ne prend pas parti non plus sur le bien et le mal, le juste et l’injuste, le préférable ou le négligeable. L’accent est mis sur l’explicitation des choix qui construisent le réseau de vouloirs ou « capital éthique » d’une communauté et sur la contribution de ces choix à l’augmentation et à la diversification des autres catégories de l’intelligence collective. A long terme, les orientations concernant le bien et le mal devraient idéalement se fonder sur la connaissance des effets des choix éthiques sur le développement humain durable. Cette connaissance des effets, toujours perfectible, repose essentiellement sur un travail de modélisation et d’observation empirique de la dynamique interne de l’intelligence collective et du développement humain.
Puissances
Eclairés par des réseaux de savoirs (connaissance) et orientés par des réseaux de vouloirs (éthique), la puissance d’une intelligence collective mobilise les compétences, savoir-faire pratiques et métiers, qui peuvent s’associer en réseaux collaboratifs et se complémenter. Outre les compétences, la puissance d’une intelligence collective repose sur sa force économique, résumée ici par le terme de « ressources » (liquidité, crédit, épargne…). Cette dimension financière correspond non seulement à un pouvoir d’achat à des fins de consommation mais également à une capacité d’investissement et d’emploi des compétences. Enfin, la puissance s’alimente de la résolution d’une communauté, c’est-à-dire de l’engagement, du courage, du moral ou de la confiance en soi de ses membres.
Sans ressources, le savoir-faire seul ne confère pas de pouvoir d’action effective et, sans la mise en branle de réseaux de compétences, les moyens financiers restent impuissants ou stériles. Et si la communauté en question n’est pas résolue dans son action, sa puissance se dissipe. La catégorie de la puissance dessine donc un ensemble de réseaux de pouvoirs ou les disponibilités de ressources, des engagements fermes et des savoir-faire pratiques s’échangent, se fécondent et se multiplient. Comme les catégories épistémiques et éthiques, la catégorie pratique de la puissance a pour vocation naturelle de croître et de se diversifier pour elle-même. Mais elle doit parallèlement contribuer à la croissance et à la diversification des autres catégories, selon une stratégie d’intelligence collective bien comprise, fondée sur l’analyse des équilibres durables à maintenir.
Messages
Le « capital de messages » peut être envisagé de trois points de vue complémentaires : celui du contenu des messages, celui de la communication interpersonnelle proprement dite et celui des médias (les environnements et supports de communication). La catégorie rassemble l’ensemble des messages échangés dans et par la communauté envisagée, auxquels il faut ajouter les messages disponibles en ligne qui sont pertinents pour cette communauté, même si aucun de ses membres n’en est le destinataire ou le destinateur explicite. Les messages et leurs contenus sont pratiquement indissociables des communications qu’ils alimentent et des médias qui servent à les produire, les enregistrer, les fouiller, les retrouver, les transmettre, les recevoir et les transformer. Du point de vue de la mémoire de l’intelligence collective, les messages sont conçus comme des documents à conserver et à exploiter afin de permettre à la communauté de se représenter à elle-même son histoire, ou l’évolution de son identité. En ce sens, le capital de messages comprend non seulement les flux de messages à court terme (les médias et systèmes de messagerie) mais également la communication à long terme et la transmission inter-générationnelle (donc l’éducation) : les écoles, les bibliothèques, les musées et les supports d’apprentissage de toutes sortes dont les trésors sont de plus en plus numérisés et disponibles en ligne. Sans communication ni mémoire culturelle, sans support sémiotique en général, ni les réseaux de savoir, ni les réseaux de vouloirs, ni les réseaux de pouvoirs ne pourraient subsister, sans parler des réseaux sociaux… Les messages n’ont de sens qu’en fonction de leur relation inter-créative avec les cinq autres pôles.
Personnes
La catégorie des personnes représente le « capital social » d’une communauté, c’est-à-dire le réseau des connexions interpersonnelles qui fondent cette communauté. On peut ici distinguer trois aspects interdépendants : la variété des rôles sociaux joués par les personnes, la qualité des liens (que le terme général de confiance résume assez bien) et finalement la quantité, l’intensité et le dessin des connexions (les réseaux proprement dit). Les gens qui interagissent au sein de réseaux interpersonnels le font généralement au titre d’un ou plusieurs rôles sociaux : rôles de genre, rôles familiaux, professionnels ou politiques, participation à la société civile, participation à des rituels de tous ordres, etc. Plusieurs approches du développement humain mettent le capital social en position de déterminant essentiel. Plutôt que de désigner un déterminant essentiel, la démarche proposée ici préconise un instrument d’observation et de pilotage des interdépendances. Car si le capital social peut être bel et bien considéré, en un sens, comme la racine (ou le fruit ultime) du développement humain, il dépend lui-même d’une foule de facteurs qu’il conditionne en retour : équipements, santé, éducation et connaissances, compétences, moyens financiers, gouvernance, mémoire culturelle… On voit que chaque catégorie décrit la même communauté humaine, mais selon des points de vue conceptuellement distincts qui se réfléchissent les uns dans les autres selon des modèles fonctionnels à tester et à préciser empiriquement.
Equipements
Le « capital biophysique » décrit par les équipements désigne d’abord les organismes humains dans leur actualité biomédicale (santé) ainsi que l’environnement biophysique ou éco-systémique complexe dont ils dépendent nécessairement pour leur nourriture, leur boisson, leur respiration, leur hygiène et leur bien-être en général. Le circuit corporel comprend également l’ensemble des équipements matériels et techniques produits et entretenus par l’industrie humaine : vêtements, bâtiments, réseaux de transports, véhicules, outils, machines, produits de l’industrie chimique et biochimique, etc. Il s’agit en somme du système d’interaction causal qui réunit les corps matériels et qui constitue le support physico-biologique du développement humain. Il est sans doute inutile de souligner ici la part prise aujourd’hui par la santé dans les dépenses publiques et le souci général d’un développement durable respectueux des équilibres écologiques dont dépend le bien-être des populations. Par ailleurs il est évident que les infrastructures matérielles, ainsi que la qualité et la quantité de l’outillage disponible, déterminent dans une large mesure les opportunités ouvertes aux communautés humaines. En retour, il est clair que les « équipements » dépendent eux-mêmes des apports en provenance des cinq autres catégories principales de ce modèle.
Pour conclure, citant Ibn Roshd (l’Averroes des latins), Dante écrit au chapitre I, 3 de sa Monarchie : “Le terme extrême proposé à la puissance de l’humanité est la puissance, ou vertu, intellective. Et parce que cette puissance ne peut, d’un seul coup, se réduire toute entière en acte par le moyen d’un seul homme ou d’une communauté particulière, il est nécessaire qu’il règne dans le genre humain une multitude par le moyen de laquelle soit mise en acte cette puissance toute entière. “





