A Scientific Language
IEML is an acronym for Information Economy MetaLanguage. IEML is the result of many years of fundamental research under the direction of Pierre Lévy, fourteen years of which were funded by the Canadian federal government through the Canada Research Chair in Collective Intelligence at the University of Ottawa (2002-2016). In 2020, IEML is the only language that has the following three properties:
– it has the expressive power of a natural language;
– it has the syntax of a regular language;
– its semantics is unambiguous and computable, because it is aligned with its syntax.
In other words, it is a “well-formed symbolic system”, which comprises a bijection between a set of relations between signifieds, or meanings (a language) and a set of relations between signifiers (an algebra) and which can be manipulated by a set of symmetrical and automatic operations.
On the basis of these properties, IEML can be used as a concept coding system that solves the problem of semantic interoperability in an original way, lays the foundations for a new generation of artificial intelligence and allows collective intelligence to be reflexive. IEML complies with Web standards and can be exported in RDF. IEML expressions are called USLs (Uniform Semantic Locators). They can be read and translated into any natural language. Semantic ontologies – sets of IEML expressions linked by a network of relations – are interoperable by design. IEML provides the coordinate system of a common knowledge base that feeds both automatic reasoning and statistical calculations. In sum, IEML fulfills the promise of the Semantic Web through its computable meaning and interoperable ontologies. IEML’s grammar consists of four layers: elements, words, sentences and texts. Examples of elements and words can be found at https://dev.intlekt.io/.
Elements
The semantic elements are the basic building blocks, or elementary concepts, from which all language expressions are composed. A dictionary of about 5000 elements translated into natural languages is given with IEML and shared among all its users. Semantic interoperability comes from the fact that everyone shares the same set of elements whose meanings are fixed. The dictionary is organized into tables and sub-tables related to the same theme and the elements are defined reciprocally through a network of explicit semantic relations. IEML allows the design of an unlimited variety of concepts from a limited number of elements.
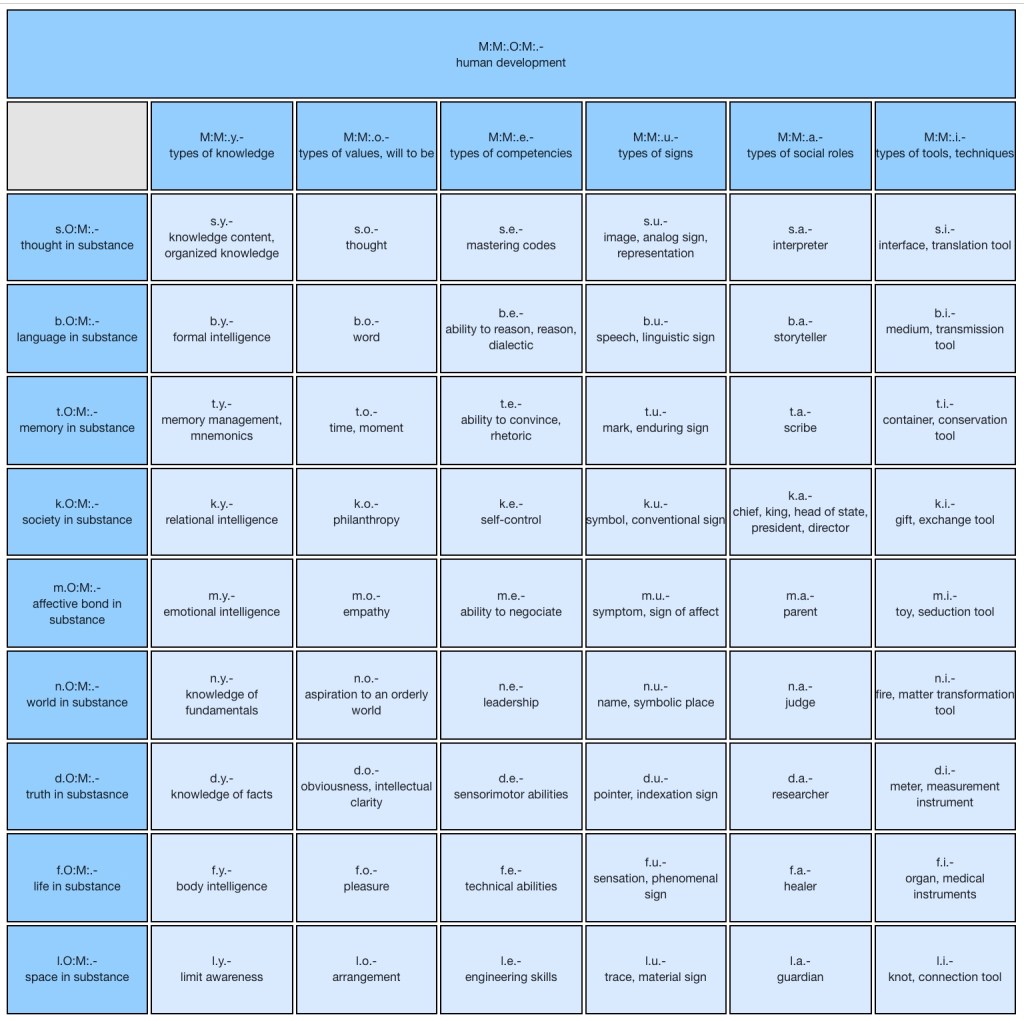
The user does not have to worry about the rules from which the elements are constructed. However, they are regularly generated from six primitive symbols forming the “layer 0” of the language, and since the generative operation is recursive, the elements are stratified on six layers above layer 0.
Words
Using the elements dictionary and grammar rules, users can freely model a field of knowledge or practice within IEML. These models can be original or translate existing classifications, ontologies or semantic metadata.
The basic unit of an IEML sentence is the word. A word is a pair composed of two small sets of elements: the radical and the inflection. The choice of radical elements is free, but inflection elements are selected from a closed list of elements tables corresponding to adverbs, prepositions, postpositions, articles, conjugations, declensions, modes, etc. (see “auxiliary morphemes” in https://dev.intlekt.io/)
Each word or sentence corresponds to a distinct concept that can be translated, according to its author’s indications and its grammatical role, as a verb (encourage), a noun (courage), an adjective (courageous) or an adverb (bravely).
Sentences
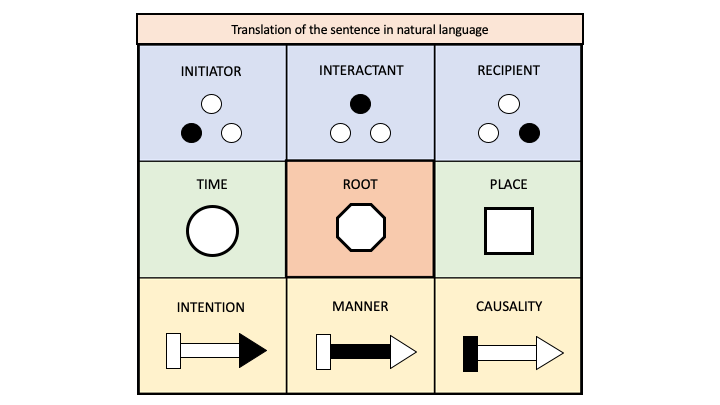
The words are distributed on a grammatical tree composed of a root (verbal or nominal) and eight leaves corresponding to the roles of classical grammar: subject, object, complement of time, place, etc.

Nine grammatical roles
– The Root of the sentence can be a process (a verb), a substance, an essence, an affirmation of existence…
– The Initiator is the subject of a process, answering the question “who?” He can also define the initial conditions, the first motor, the first cause of the concept evoked by the root.
– The Interactant corresponds to the object of classical grammar. It answers the question “what”. It also plays the role of medium in the relationship between the initiator and the recipient.
– The Recipient is the beneficiary (or the victim) of a process. It answers the questions “for whom, to whom, towards whom?”.
– The Time answers the question “when?”. It indicates the moment in the past, the present or the future and gives references as to anteriority, posteriority, duration, date and frequency.
– The Place answers the question “where?”. It indicates the location, spatial distribution, pace of movement, paths, paths, spatial relationships and metaphors.
– The Intention answers the question of finality, purpose, motivation: “for what”, “to what end?”It concerns mental orientation, direction of action, pragmatic context, emotion or feeling.
– The Manner answers the questions “how?” and “how much?”. It situates the root on a range of qualities or on a scale of values. It specifies quantities, gradients, measurements and sizes. It also indicates properties, genres and styles.
– The Causality answers the question “why? It specifies logical, material and formal determinations. It describes causes that have not been specified by the initiator, the interactant or the recipient: media, instruments, effects, consequences. It also describes the units of measurement and methods. It may also specify rules, laws, reasons, points of view, conditions and contracts.
For example: Robert (initiator) offers (root-process) a (interactant) gift to Mary (recipient) today (time) in the garden (place), to please her (intention), with a smile (manner), for her birthday (causality).
Junctions
IEML allows the junction of several words in the same grammatical role. This can be a logical connection (and, or inclusive or exclusive), a comparison (same as, different from), an ordering (larger than, smaller than…), an antinomy (but, in spite of…), and so on.
Layers of complexity

A word that plays one of the eight leaf roles at complexity layer 1 can play the role of secondary root at a complexity layer 2, and so on recursively up to layer 4.
Literals
IEML strictly speaking enables only general categories or concepts to be expressed. It is nevertheless possible to insert numbers, units of measurement, dates, geographical positions, proper names, etc. into a sentence, provided they are categorized in IEML. For example t.u.-t.u.-‘. [23] means ‘number: 23’. Individual names, numbers, etc. are called literals in IEML.
Texts
Relations
A semantic relationship is a sentence in a special format that is used to link a source node (element, word, sentence) to a target node. IEML includes a query language enabling easy programming of semantic relationships on a set of nodes.
By design, a semantic relationship makes the following four points explicit.
1. The function that connects the source node and the target node.
2. The mathematical form of the relation: equivalence relationship, order relationship, intransitive symmetrical relationship or intransitive asymmetrical relationship.
3. The kind of context or social rule that validates the relationship: syntax, law, entertainment, science, learning, etc.
4. The content of the relationship: logical, taxonomic, mereological (whole-part relationship), temporal, spatial, quantitative, causal, or other. The relation can also concern the reading order or the anaphora.
The (hyper) textual network
An IEML text is a network of semantic relationships. This network can describe linear successions, trees, matrices, cliques, cycles and complex subnetworks of all types.
An IEML text can be considered as a theory, an ontology, or a narrative that accounts for the dataset it is used to index.
We can define a USL as an ordered (normalized) set of triples of the form : (a source node, a target node, a relationship sentence). A set of such triples describes a semantic network or IEML text.
The following special cases should be noted:
– A network may contain only one sentence.
– A sentence may contain only one root to the exclusion of other grammatical roles.
– A root may contain only one word (no junction).
– A word may contain only one element.
*******
In short, IEML is a language with computable semantics that can be considered from three complementary points of view: linguistics, mathematics and computer science. Linguistically, it is a philological language, i.e. it can translate any natural language. Mathematically, it is a topos, that is, an algebraic structure (a category) in isomorphic relation with a topological space (a network of semantic relations). Finally, on the computer side, it functions as the indexing system of a virtual database and as a programming language for semantic networks.