Ce billet rend compte de ma communication au colloque Humanistica à Montréal, le 20 mai 2022.
Les chercheurs en sciences humaines et sciences sociales constituent des bases de données pour l’analyse, la fouille et le partage. L’indexation des documents en ligne est cruciale pour les auteurs, les éditeurs et les lecteurs. Aujourd’hui, il existe une multiplicité de systèmes de métadonnées sémantiquesetontologiesselon les langues, disciplines, traditions et théories. Ces systèmes sont souvent hérités de l’ère de l’imprimerie. Dans ce contexte, le métalangage IEML propose un outil de modélisation et d’indexation programmable, capable d’assurer l’interopérabilité sémantique sans uniformiser les points de vue.
En IEML il y a coïncidence entre les concepts et leur représentation linguistique. Exprimés en IEML plutôt qu’en langue naturelle, les concepts deviennent auto-explicatifs et univoques (sans ambiguïtés lexicale ou syntagmatique). Les concepts d’ontologies différentes sont composés à partir des mots d’un même dictionnaire IEML selon une grammaire régulière. Il devient donc possible d’échanger collaborativement des modèles et sous-modèles entre chercheurs parlant des langues différentes et venant de disciplines distinctes. En somme, IEML résout le problème de l’interopérabilité sémantique.
Une plateforme pour la conception et le maintien collaboratif de graphes sémantiques est en vue. (ontologies, systèmes d’indexation, étiquettes pour le machine learning, etc.).
Un nouvel outil sémantique
IEML n’est pas un format – de données ou de métadonnées – mais une langue qui possède:
• un dictionnaire compact de 3000 mots (accessibles en anglais et français)
• une grammaire entièrement régulière
• le tout intégré à un éditeur-parser
IEML a les mêmes qualités et forces sémantiques qu’une langue naturelle. Ainsi, IEML peut traduire toutes les langues naturelles et peut servir de pivot entre langues naturelles. Sa sémantique est calculable parce que c’est une fonction de sa syntaxe (qui est régulière).
Destinés à la construction de graphes sémantiques, ses phrases peuvent prendre deux formes: nœuds ou liens. IEML possède des instructions permettant de programmer des graphes sémantiques tels que : hypertextes, ontologies et modèles de données.
Les mots
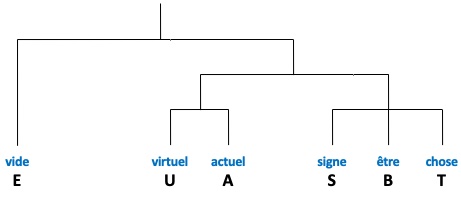
En utilisant la grammaire et les mots du dictionnaire, l’éditeur IEML permet de générer récursivement autant de concepts que l’on veut. Chaque mot en IEML est construit de manière régulière à partir de 6 primitives (lettres majuscules).
Les 6 primitives d’IEML
Les six primitives, tout comme les autres lettres d’IEML sont des mots et dénotent des concepts lorsqu’elles sont utilisées seules. Lorsqu’elles sont utilisées dans un autre mot, elles représentent des places dans des systèmes de symétrie: symétrie 1 pour E, symétrie 2 pour U/A, symétrie 3 pour S/B/T. Pour plus de détails sur les primitives d’IEML, voir: https://intlekt.io/semantic-primitives/
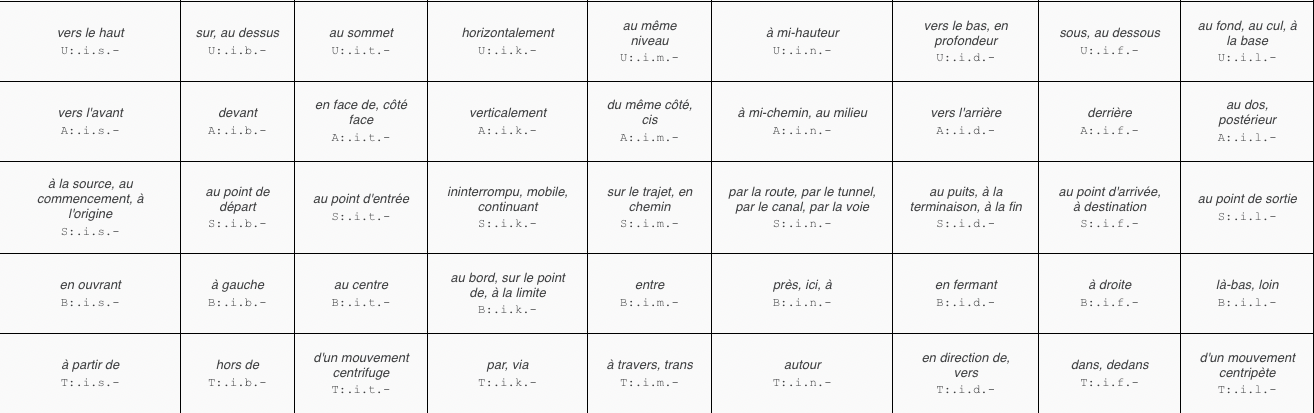
L’opération générative pour les mots a trois rôles: substance ☓ attribut ☓ mode. En combinant cette opération générative (☓) avec une opération de jonction (+), on peut former des paradigmes de mots. Ci-dessous les 25 lettres minuscules sont réunies dans une table paradigmatique qui multiplie U+A+S+B+T en substance par U+A+S+B+T en attribut, avec un mode toujours vide.
Les 25 lettres minuscules en IEML
Dans l’image ci-dessus, les couleurs signalent quatre systèmes de symétries (4, 6, 6, 9) dont les lettres occupent des positions déterminées. Pour en savoir plus sur les 25 lettres minuscules, voir: https://intlekt.io/25-basic-categories/
En IEML, les paradigmes de mots, comme d’ailleurs les paradigmes de phrases, sont des systèmes de symétries sémantiques représentés par des systèmes de symétries syntaxiques. Par exemple, le paradigme ci-dessous organise les relations spatiales. Les deux premières rangées organisent les relations spatiales selon les axes vertical (première rangée) et horizontal (deuxième rangée). Les trois rangées inférieures organisent les entrées et sorties, la latéralisation et les chemins.
Paradigme des relations spatiales. Cliquez sur l’image pour l’agrandir 😉
Retenons que le dictionnaire d’IEML est avant tout une boîte à outils pour construire de nouvelles catégories au moyen de phrases.
Les phrases
Les neuf rôles de la phrase – en vert dans l’exemple ci-dessous – ainsi que les * auxiliaires, les ~ flexions et les & jonctions permettent l’expression de récits et d’explications causales. Les # mots en français sont des alias de mots ou de concepts-phrases en IEML.
Exemple de phrase IEML
Evocation
La création de relations sémantiques
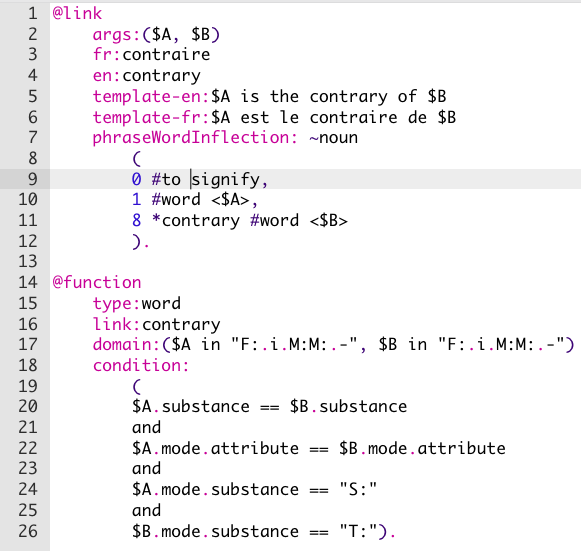
En IEML, les relations sémantiques ne se créent pas une par une “à la main” mais se programment. L’instruction de création de relations sémantiques ci-dessous se décompose en deux parties. La partie qui commence par @link énonce la phrase de lien avec les deux variables $A et $B: “Le mot A signifie le contraire du mot B”. Les numéros 0, 1 et 8 sont des raccourcis pour les rôles de phrase: racine, initiateur et manière. La partie qui commence par @function énonce le domaine (en l’occurrence le paradigme de relations spatiales ci-dessus) qui est concerné par la création de relations et il énonce les conditions nécessaires en termes d’adresses syntaxiques et de contenu. La fonction de création de relations n’utilise que deux “équations” connectées par des “ET” et des “OU”: adresse syntaxique A == adresse syntaxique B adresse syntaxique A == contenu c
Exemple d’instruction déclarative de création de relations sémantiques
Remarquons que l’instruction déclarative ci-dessus crée 30 relations sémantiques d’un coup!
Indexation, noms propres, référence et auto-référence.
IEML traite explicitement les noms propres et les références qui ne sont pas des catégories générales. L’exemple ci-dessous donne trois exemples : un nom, un nombre et un lien hypertexte. Pour en savoir plus sur le traitement des noms propres en IEML voir: https://pierrelevyblog.com/2021/07/13/les-noms-propres-en-ieml/
Exemples de référence en IEML
IEML peut aussi faire référence à ses propres expressions: liens, définitions, commentaires, etc. L’exemple ci-dessous est pris au paradigme des relations spatiales et à la relation “le mot A signifie le contraire du mot B” examiné plus haut.
Exemple d’auto-référence en IEML
Plusieurs ontologies sont actuellement en cours de développement. N’hésitez pas à me contacter si vous êtes intéressés par IEML!
Pierre Lévy a tenu un séminaire sur IEML pendant trois après-midi (13h-17h) les 24, 25 et 26 octobre 2022 à l’Université de Montréal, dans la salle C-8132, Pavillon Lionel-Groulx, 3150 Jean-Brillant.
Pour en savoir plus sur IEML, voir ce texte en anglais facile et qui se lit en 15 min.
La présentation de Louis van Beurden, qui a programmé le back-end de l’éditeur IEML, y compris le parseur.
La problématique est définie dans le texte qui suit.
L’université de Montréal
La recherche en sciences humaines et sociales utilise de manière croissante les bases de données, l’analyse automatique, voire l’intelligence artificielle. D’autre part, les résultats de la recherche sont de plus en plus disponibles en ligne sur les blogs des chercheurs, certains réseaux sociaux, les sites web des revues, mais aussi dans des moteurs de recherches spécialisés comme ISIDORE. Tout ceci pose de façon cruciale le problème d’une catégorisation interopérable des données et des documents en sciences humaines et sciences sociales. La question ne se posait pas (ou moins gravement) lorsque chaque bibliothèque, voire chaque pays, avait son système de classement cohérent. Mais dans le nouvel espace numérique, la multiplicité des langues et des systèmes de classifications incompatibles fragmente la mémoire.
Un premier niveau de réponse à ce problème est fourni par des *formats standards* pour les métadonnées sémantiques, notamment RDF (Resource Description Framework) proposé par le WWW Consortium. Signalons également d’autres formats standards comme JSON LD et Graph QL. Mais il ne s’agit dans tous ces cas que d’une interopérabilité technique, au niveau de la forme des fichiers. Pour résoudre le problème de l’interopérabilité sémantique (traitant de la cohérence des architectures de concepts) on a élaboré des *modèles standards*. Par exemple schema.org pour les sites web, CIDOC-CRM pour le domaine culturel, etc. Il existe de tels modèles pour de nombreux domaines, de la finance à la médecine, mais – notons-le – aucun d’eux n’unifie l’ensemble des sciences humaines. Non seulement plusieurs modèles se font concurrence pour un domaine, mais les modèles eux-mêmes sont hypercomplexes et relativement rigides, au point que même les spécialistes n’en maîtrisent qu’une petite partie. De plus, ces modèles sont exprimés en langues naturelles – le plus souvent en anglais – avec les problèmes de traduction et d’ambiguïté que cela suppose.
Afin de résoudre le problème de l’interopérabilité sémantique dans la catégorisation des données en sciences humaines et sociales, nous proposons d’expérimenter une approche à la fois plus souple et plus générale que celle des modèles standards: une langue documentaire standard capable d’exprimer n’importe quel modèle ou ontologie et se traduisant dans toutes les langues naturelles. On trouvera ici une rapide description d’IEML en français.
IEML (Information Economy Metalanguage) développé par Pierre Lévy depuis plusieurs années est un langage artificiel (1) ayant le même pouvoir d’expression et de traduction que n’importe quelle langue naturelle, et (2) dont la grammaire et la sémantique sont régulières et calculables. IEML est le seul langage à posséder ces deux propriétés. IEML peut servir de système de métadonnées, assurant l’interopérabilité sémantique des bases de données, quel que soit le domaine. Grâce à sa nature régulière, IEML est également destiné à soutenir la prochaine génération d’intelligence artificielle “neuro-sémantique”. Voir sur ce blog un article d’une vingtaine de pages qui situe IEML dans le paysage général de l’intelligence artificielle. Un outil open-source, l’éditeur IEML (basé sur un parseur en C++) permet de modéliser finement des domaines complexes au moyen de graphes de connaissances ou ontologies. Les modèles sont générés à l’aide d’un langage de programmation déclaratif original et pourront être explorés de manière interactive sous forme d’hypertextes, de tables et de graphes. Les modèles pourront être exportés dans n’importe quel format standard.
L’objectif global du séminaire consiste à réunir des leaders établis et émergents dans les domaines de la recherche, de l’édition et de la fouille de données en humanités numériques pour faire le point sur les récents développements d’IEML. On présentera notamment une ontologie déjà construite et les enseignements méthodologiques issus des travaux en cours. Les trois jours d’échanges intensifs se tiendront sous la direction de Pierre Lévy (Professeur associé à l’Université de Montréal, membre de la Société Royale du Canada) et Marcello Vitali-Rosati (Chaire de recherche du Canada en écritures numériques et professeur titulaire en littérature française à l’Université de Montréal).”
Photo prise par Luc Courchesne lors de la séance du 25 octobre 2022
Le but de ce texte est de présenter une vue générale des limites de l’IA contemporaine et de proposer une voie pour les dépasser. L’IA a accompli des progrès considérables depuis l’époque des Claude Shannon, Alan Turing et John von Neumann. Néanmoins, de nombreux obstacles se dressent encore sur la route indiquée par ces pionniers. Aujourd’hui, l’IA symbolique se spécialise dans la modélisation conceptuelle et le raisonnement automatique tandis que l’IA neuronale excelle dans la catégorisation automatique. Mais les difficultés rencontrées aussi bien par les approches symboliques que neuronales sont nombreuses. Une combinaison des deux branches de l’IA, bien que souhaitable, laisse encore non résolus les problèmes du cloisonnement des modèles et les difficultés d’accumulation et d’échange des connaissances. Or l’intelligence humaine naturelle résout ces problèmes par l’usage du langage. C’est pourquoi je propose que l’IA adopte un modèle calculable et univoque du langage humain, le Métalangage de l’Économie de l’Information (IEML pour Information Economy MetaLanguage), un code sémantique de mon invention. IEML a la puissance d’expression d’une langue naturelle, il possède la syntaxe d’un langage régulier, et sa sémantique est univoque et calculable parce qu’elle est une fonction de sa syntaxe. Une architecture neuro-sémantique basée sur IEML allierait les forces de l’IA neuronale et de l’IA symbolique classique tout en permettant l’intégration des connaissances grâce à un calcul interopérable de la sémantique. De nouvelles avenues s’ouvrent à l’intelligence artificielle, qui entre en synergie avec la démocratisation du contrôle des données et l’augmentation de l’intelligence collective.
Après avoir été posté sur ce blog, le texte a été publié par le Giornale Di Filosofia numéro 2. Lien vers –> le texte complet en PDF publié sur le site du Giornale di Filosofia. Ou bien lisez le texte ci-dessous 🙂.
Le but de cette entrée de blog est d’expliquer comment fonctionne la sémantique référentielle en IEML et en particulier comment IEML traite les noms propres. J’ai distingué la sémantique linguistique et la sémantique référentielle ici et là. Je rappelle néanmoins dans ce qui suit les idées principales qui fondent cette distinction.
Sémantique linguistique et sémantique référentielle
La sémantique linguistique est interne au langage, tandis que la sémantique référentielle fait le pont entre un énoncé et ce dont il parle.
Lorsque je dis que “les platanes sont des arbres”, je ne fais que préciser le sens conventionnel du mot “platane”. Mais si je dis que “cet arbre-là, dans la cour, est un platane”, alors je pointe vers un état de chose, et ma proposition est vraie ou fausse. Le second énoncé met évidemment en jeu la sémantique linguistique puisque je dois d’abord connaître le sens des mots et la grammaire du français pour la comprendre. Mais s’ajoute à la dimension linguistique une sémantique référentielle puisque l’énoncé se rapporte à un objet particulier dans une situation concrète.
Un dictionnaire classique définit le sens conventionnel des mots dans une langue, chaque mot étant expliqué en utilisant d’autres mots qui sont eux-mêmes expliqués par d’autres mots, et ainsi de suite de manière circulaire. Un dictionnaire relève donc principalement de la sémantique linguistique. En revanche, un dictionnaire encyclopédique contient des descriptions d’individus réels ou fictifs pourvus de noms propres tels que divinités, héros de roman, personnages et événements historiques, objets géographiques, monuments, œuvres de l’esprit, etc. Sa principale fonction est de répertorier et de décrire des objets externes au système d’une langue. Il enregistre donc une sémantique référentielle.
La sémantique linguistique met en relation un signifiant avec un signifié. Par exemple, le signifiant “arbre”, a pour signifié : “végétal ligneux, de taille variable, dont le tronc se garnit de branches à partir d’une certaine hauteur”. En revanche, la sémantique référentielle met en rapport un signifiant avec un référent. Par exemple, le signifiant “Napoléon 1er” désigne un personnage historique.
Individus et catégories
Les mots contenus dans un dictionnaire classique, et particulièrement les noms communs, désignent généralement des catégories alors que les entrées du dictionnaire encyclopédique se rapportent plutôt à des individus. Le nom commun “arbre” désigne n’importe quel arbre, la classe des arbres, alors que “l’Arbre de la Bodhi” de Bodh Gaya en Inde est un individu portant un nom propre.
Par “catégorie” j’entends une classe, un genre, un ensemble, une collection, etc. Et ce n’est pas le hasard qui réunit un ensemble d’êtres ou d’objets dans la même catégorie, mais bien au contraire des traits communs. Par contraste avec une catégorie, un “individu” est unique, discret, particulier, qu’il s’agisse d’une personne, d’une chose, d’un événement, d’un lieu, d’une date, etc. On peut élargir le concept d’individu en suivant Bertrand Russell, qui en propose la définition suivante: “une série de faits liés entre eux par des relations causales”. En ce sens l’Écosystème de la forêt amazonienne ou la Révolution française sont bien des individus.
Les deux notions d’individu et de catégorie font système : les individus appartiennent à des catégories et les éléments à des ensembles. L’individu est plutôt concret, comme Isabelle qui est devant moi, alors que la catégorie générale est abstraite, comme l’humanité, qu’il m’est impossible de toucher.
Ne confondons pas “catégorie générale” avec “tout” ni “individu” avec “partie”. Les touts ne sont pas des ensembles abstraits, mais bel et bien des individus, comme d’ailleurs les parties. Par exemple, un organisme animal est un individu total et ses membres sont des parties individuelles de ce tout. Cet éléphant est un exemplaire individuel de la classe des éléphants, mais sa trompe est une partie du corps de l’éléphant.
Noms propres et noms communs: une définition
Je vais maintenant définir la différence entre noms communs et noms propres. Mon but n’est pas ici de trancher définitivement un débat que de grands linguistes, logiciens et philosophes mènent depuis plusieurs siècles sur ce thème mais plutôt de fixer une convention utile pour le métalangage IEML (Information Economy MetaLanguage) en suivant le consensus aujourd’hui majoritaire en philosophie et en linguistique.
Un nom commun
(1) Il désigne une catégorie.
(2) Il a un signifié relativement constant dans le système de la langue, c’est-à-dire qu’il possède une place dans le réseau cyclique des signifiés d’un dictionnaire.
(3) Il peut en outre acquérir un référent de manière variable selon les actes d’énonciation, comme dans “cette bouteille”.
Un nom propre
(1) Il désigne un individu.
(2) C’est un signifiant qui n’a pas de signifié dans le système de la langue.
(3) Il possède un référent constant conféré par une tradition sociale qui remonte à un acte de nomination. Selon Saul Kripke, un nom propre est un “désignateur rigide” dont la principale fonction est de permettre de parler d’un objet indépendamment des propriétés qu’il possède et des interprétations qu’on lui donne.
Ces définitions peuvent prêter à malentendus et donnent lieu à quelques exceptions.
Est-il vrai qu’un nom propre n’a pas de signifié?
Commençons tout de suite par évoquer la révolte instinctive contre l’idée qu’un nom propre n’a pas de signifié. Car lorsque nous entendons le mot “Napoléon” nous imaginons tout de suite le bicorne, les abeilles d’or, le jeune général traversant le pont d’Arcole un drapeau à la main, le code civil, le désastre de la Bérésina, etc. Mais Napoléon n’est pas un nom commun de la langue française, c’est un personnage historique. Les images qu’évoquent ce signifiant ne sont pas des signifiés conventionnels mais des connotations qui peuvent varier fortement selon que l’on est français ou anglais, bonapartiste ou légitimiste, militariste ou pacifiste, sensible ou non à la cause abolitioniste (la loi du 20 mai 1802 rétablit l’esclavage), etc. Les connotations sont variables mais la référence à l’individu est constante et sans ambiguité. Les noms propres peuvent avoir des connotations, mais ils n’ont pas de signifié conventionnel dans le système de la langue.
Les noms communs désignent-ils toujours des catégories générales?
Autre point douteux : les noms communs désignent-ils toujours des catégories générales? Par exemple, la lune, satellite de la terre, est-elle un nom commun ou un nom propre? Et si c’est un nom commun, comment se fait-il que “La lune” désigne un individu? Mais remarquons que l’on parle des lunes de Jupiter, qui ont été découvertes par Galilée. Le mot “lune” est donc bien un nom commun. Lorsqu’il est utilisé avec un article défini sans autre précision il réfère à l’astre argenté au cycle quasi mensuel qui éclaire nos nuits, sinon il signifie la catégorie des satellites de planètes. Le même problème se pose pour d’autre objets cosmiques, comme le soleil, la terre, le ciel, etc. En règle générale, chaque fois qu’un nom peut être utilisé au pluriel sans absurdité, alors il s’agit d’un nom commun. La philosophie bouddhiste multiplie les “terres” : les dix bhumis (sanscrit pour “terres”) sont des étapes successives sur le chemin du Bodhisatva. Bien qu’il semble à première vue qu’il n’y ait qu’un seul ciel, le mot possède plusieurs pluriels en français : “cieux” au sens spirituel et “ciels” aux sens matériels. Ne parle-t-on pas des ciels de Turner ou de Monet? En revanche, Mars ou Saturne sont des satellites particuliers ou des divinités personnelles et je ne les ai jamais vus utilisés au pluriel. Ce sont donc des noms propres désignant des individus astronomiques ou mythologiques.
Dans certains usages, une catégorie générale peut être considérée comme un individu
Encore un cas troublant: on peut faire référence à une catégorie générale en la considérant comme un individu. Lorsque je dis “Le fruit que je tiens dans ma main est un melon” j’utilise bien le mot melon comme une catégorie générale dans laquelle je range le fruit individuel que je tiens dans ma main. Jusqu’ici tout va bien. Mais je peux toujours considérer une catégorie générale comme un individu, un élément de l’ensemble des catégories générales : c’est le point de vue réaliste ou platonicien. Par exemple lorsque je dis “le melon est un fruit”, “melon” est au singulier et il est accompagné d’un article défini. Il s’agit donc d’un individu: une “catégorie individuelle”. Mais il ne s’agit là que d’un usage possible d’un nom commun, qui ne range nullement le mot “melon” dans la catégorie des noms propres. Dès qu’une catégorie générale est placée dans un énoncé en position de référent (nous parlons de “cette catégorie-là”), l’usage en fait un individu. Il suffit de distinguer les niveaux logiques pour ne pas se prendre les pieds dans le tapis sémantique. Retenons que lorsqu’un mot possède un signifié dans le système de la langue, il s’agit d’un nom commun, bien que l’on puisse s’en servir pour désigner un individu.
Des noms propres peuvent être utilisés comme prototypes de catégories générales
Dans l’effort pour discriminer entre nom propre et nom commun, la plus grande difficulté vient de l’utilisation des noms propres comme prototypes de catégories générales. On parle par exemple de statuettes qui sont des Vénus préhistoriques ou d’un maître-nageur qui est un Apollon. On traite ironiquement d’Einstein une personne à l’esprit lent, etc. “Les Vénus” contredit la règle générale que nous avons énoncé plus haut, selon laquelle chaque fois qu’un nom peut être utilisé au pluriel sans absurdité, alors il s’agit d’un nom commun. Bien pire, les noms propres peuvent engendrer des adjectifs désignant des qualités abstraites. Par exemple, on souligne le contraste entre l’évolution lamarckienne et l’évolution darwinienne, on évoque les guerres napoléoniennes ou les idées platoniciennes. Certes, Vénus, Apollon, Platon, Napoléon, Darwin, etc. sont des individus, mais ces individus ont tellement marqué les imaginations qu’ils sont devenus les “membres centraux”, ou figures archétypiques, de catégories comprenant les individus qui leur ressemblent ou qui possèdent avec eux une contiguïté spatio-temporelle (la “période napoléonienne”). Dès lors, le nom propre est utilisé de manière figurative comme un nom commun, ou comme une qualité générique dans le cas d’un adjectif construit à partir d’un nom propre. Nous avons donc affaire dans ces cas à des exceptions à notre règle, dans lesquelles des noms propres sont utilisés (par métaphore, métonymie, contiguïté, etc.) pour désigner des catégories.
Une Vénus Préhistorique
Nom propres et références en IEML
Chacun des trois mille mots élémentaires du dictionnaire d’IEML se définit au moyen de phrases utilisant d’autres mots élémentaires et chaque expression complexe en IEML (groupes de mots, phrases, textes) renvoie au noyau circulaire d’inter-définition du dictionnaire. Cette inter-définition circulaire des mots du dictionnaire est d’ailleurs le propre de toutes les langues. Selon leurs rôles grammaticaux dans un énoncé, les trois mille éléments du dictionnaire IEML peuvent être lus comme des noms, des adjectifs, des verbes ou des adverbes. Leurs signifiés sont des catégories générales. Les signifiants de ces catégories générales sont construits pour avoir le maximum de relations fonctionnelles avec leurs signifiés. Les signifiés du même champ sémantique appartiennent au même paradigme et possèdent des similitudes syntaxiques. La composition matérielle des signifiants et leurs places respectives dans les paradigmes donne des indications sur leur sens. Par exemple, les signifiants des couleurs ou des sentiments ont des traits syntaxiques en commun. Les couleurs qui contiennent du rouge ou les sentiments qui avoisinent la colère ont également des traits matériels communs. C’est ce qui fait d’IEML une idéographie. On ne trouve évidemment pas ce type de relation signifiant / signifié dans les langues naturelles, dans lesquelles les mots pour désigner les couleurs ou les sentiments, n’ont pas de traits phonétiques communs. Jointe à la régularité sans faille de sa grammaire, ce rapport fonctionnel entre signifiant et signifié fait d’IEML une langue à la sémantique (linguistique) calculable.
En revanche, les noms propres comme Napoléon ou le Fuji Yama n’ont pas de traduction en IEML et, de ce fait, leur sémantique linguistique n’est pas calculable en IEML. En IEML les noms propres sont considérés comme des signifiants n’ayant pas de signifié (du moins pas en IEML) et dont le sens est donc purement référentiel. Les références, tout comme les noms propres, sont notés entre crochets. Voici quelques exemples qui mettent en valeur le cas particulier de Napoléon. Dans les phrases IEML entre parenthèses qui suivent, les mots en italiques désignent les rôles grammaticaux de la ligne qu’ils initient, les mots en français contiennent des liens vers le mot IEML correspondant.
L’expression signifie: “Il a été blessé pendant les guerres napoléoniennes”
Dans cet exemple, on voit comment une phrase IEML (y compris une phrase contenant un nom propre) peut être réifiée et utilisée comme un mot dans une phrase au niveau de complexité linguistique supérieure. Ce type d’opération peut être répété récursivement, ce qui permet d’atteindre des degrés élevés de différentiation et de précision sémantique.
***
Les deux exemples qui précèdent montrent qu’il est possible d’utiliser des noms propres comme prototypes de catégories générales en IEML, comme on le fait dans les langues naturelles. Mais en règle générale on préfèrera exprimer directement les catégories évoquées par les noms propres dans certaines langues naturelles par des catégories en IEML. Par exemple, pour traduire “sadique” on ne reprendra pas le nom du Marquis de Sade, mais on dira simplement “quelqu’un qui aime faire souffrir les autres.”
***
Dans l’exemple ci-dessous, l’objet de la proposition principale est une proposition secondaire – on remarquera les parenthèses dans les parenthèses – et l’accent sémantique (le point d’exclamation) est mis sur la personne (qui que ce soit) qui aime faire souffrir les autres.
Les noms de personnes, les adresses, les dates, les positions GPS, les nombres, les unités de mesure, les devises, les objets géographiques, les URL, etc. sont tous considérés comme des noms propres ou des références individuelles et sont mis entre crochets. Les douze premiers nombres entiers naturels sont néanmoins considérés comme des noms communs (ils “existent” en IEML et sont connectés aux nombres ordinaux, aux symétries, aux figures géométriques régulières, etc.). Les grandes zones géographiques existent également en IEML, sont considérées comme des catégories générales et peuvent être assimilés à des “codes postaux” qui donnent lieu à des calculs sémantiques. Ces codes permettent notamment de déterminer les positions respectives (au Nord, à l’Est, etc.) des zones codées, ainsi que de situer et regrouper les pays, les villes et autres objets géographiques.
***
Par exemple, pour dire “l’Italie” en IEML, on écrit:
Le lecteur contrastera l’approche d’IEML avec celle du Web sémantique, dans lequel les URI ne distinguent pas entre catégories générales et désignateurs rigides et ne peuvent pas faire l’objet de calculs sémantiques à partir de leur forme matérielle (une séquence de caractères). En fait, tous les URI sont des désignateurs rigides. Bien entendu, l’approche d’IEML et celle du web sémantique ne sont pas incompatibles puisque les expressions IEML valides ou USLs (Uniform Semantic Locators) ont une forme unique et peuvent se représenter comme des URIs.
L’auto-référence linguistique en IEML
On a vu plus haut que les USLs pouvaient contenir des noms propres, des nombres et autres expressions qui sont opaques au calcul sémantique IEML. Les USLs peuvent aussi faire référence à d’autres USLs, comme on peut le voir dans l’exemple ci-dessous.
Cormier Agathe. “Relecture pragmatique de Kripke pour une approche dialogique du nom propre”. 4e Congrès Mondial de Linguistique Française, Jul 2014, Berlin, Allemagne. p. 3059-3074
Frege Gottlob, “Sens et dénotation”. 1892. Trad. de C. Imbert. In Écrits logiques et philosophiques. Paris : Éditions du Seuil, 1971, 102-126.
Kripke Saul, Naming and Necessity, Oxford, Blackwell, 1980. Trad. fr. La logique des noms propres, Paris, Minuit, 1982, (trad. P. Jacob et F. Recanati).
Mill John Stuart, A System of Logic, 1843. Trad. fr. Mill, John Stuart, Système de logique déductive et inductive, trad. fr. L. Peisse Paris, Alcan, 1896.
Récanati François, “La sémantique des noms propres : remarques sur la notion de « désignateur rigide»”. In: Langue française, n°57, 1983. Grammaire et référence, sous la direction de Georges Kleiber et Martin Riegel. pp. 106-118.
Rosch Eleanor., “Cognitive Representations of Semantic Categories”, Journal of Experimental Psychology: General, Vol.104, No.3, September 1975, pp. 192–233.
Rosch Eleanor, “Natural categories”, Cognitive Psychology 1973 4, pp. 328-350.
Russell Bertrand. Human Knowledge: Its Scope and Limits. London: George Allen & Unwin (1948). Trad fr. La connaissance humaine : sa portée et ses limites. Trad. N. Lavand. Paris : J. Vrin, 2002
Vandendorpe, Christian, “Quelques considérations sur le nom propre. Pour un éclairage du linguistique par le cognitif et réciproquement”. In Langage et société, numéro 66, déc. 1993, p. 63-75.
Les banques classiques proposent désormais à leurs clients une application permettant d’effectuer des transactions sur un smartphone. Mais les données en provenance du smartphone sont le plus souvent décodées et rentrées dans le système central pendant la nuit, puis sont traitées et finalement recodées le lendemain pour être renvoyées à l’application du smartphone. Résultat: il faut deux jours pour que votre compte soit mis à jour après une transaction sur votre téléphone.
Par contraste, dans les systèmes bancaires qui datent du XXIe siècle, tous les traitements ont lieu dans le même centre de données accessible par Internet. De plus, l’application du portable et celles des services centraux communiquent de manière immédiate parce qu’elles utilisent le même format et la même catégorisation des données. Résultat : les comptes sont mis à jour instantanément après une transaction sur le smartphone. On dit que les systèmes d’information des nouvelles banques sont conçues dès l’origine de manière data-centrique. En fluidifiant la circulation de l’information, l’enjeu central de l’organisation data-centrique est d’améliorer l’expérience du client ou, selon une autre formulation, de créer plus devaleur pour le bénéficiaire d’un service.
Art: Emma Kunz
La chaîne de valeur
La notion de valeur possède un champ sémantique étendu. Il peut s’agit de valeurs éthiques, comme la justice, le courage, la sagesse ou l’harmonie des relations humaines. Ces valeurs-là n’ont évidemment pas de contreparties monétaires. Quant aux biens et services qui s’échangent sur le marché, au-delà d’un ajustement provisoire et local de l’offre et de la demande, il est bien difficile d’assigner une essence à leur valeur. La valeur proprement économique peut correspondre à une nécessité (comme celle de manger), à un désir de distraction ou de beauté, à l’accélération d’un travail ennuyeux, à un espoir de gagner de l’argent (loterie ou instrument de spéculation), à une amélioration de la qualité de vie, à l’acquisition de compétences, à une compréhension élargie qui nous rendra capable de mieux décider, à un avantage compétitif, à une image plus flatteuse, etc. La valeur n’est donc pas une fonction simple du travail investi dans la production d’un bien ou d’un service. Elle dépend de l’appréciation subjective et des comparaisons de ceux qui en bénéficient, le tout prenant place dans un contexte économique et culturel changeant. Malgré le caractère évanescent de son essence, qui tient probablement à son rapport au désir, la valeur est au cœur de la théorie économique et de la pratique des entreprises. Toute organisation crée de la valeur pour ses clients (une entreprise privée), son public (un service municipal) ou ses patients (un hôpital) et cette création constitue la principale justification de son existence.
Il est souvent utile de distinguer entre deux personnes distinctes, le client, celui qui paye pour le bien ou le service, et l’utilisateur ou le consommateur, qui s’en sert. Par exemple, le service informatique d’une entreprise (le client) achète un logiciel, mais ce sont les employés (les consommateurs) qui s’en servent. Dans l’analyse qui suit, je me concentrerai sur les relations entre les producteurs et les consommateurs de la valeur. Chaque collaborateur crée de la valeur pour les collègues qui viennent après lui sur la chaîne, la bonne exécution de leur travail dépendant de la sienne. La chaîne de valeur ne s’arrête pas nécessairement aux frontières d’une seule organisation. Elle peut connecter des réseaux d’entreprises, qui peuvent elles-mêmes être implantées dans plusieurs pays, chaque type d’entreprise contribuant qui à la conception, qui à la production des pièces, qui à l’assemblage, qui au transport, qui à la vente. Les chaînes d’approvisionnement, dont on parle tant depuis la pandémie de COVID-19, sont un cas de chaîne de valeur qui concerne plus particulièrement les activités matérielles et les transports au sein d’une filière particulière. Le consommateur final bénéficie de la valeur créée à chaque étape de la production du bien ou du service.
L’augmentation de la productivité des organisations et des filières fonde la prospérité économique. Cette augmentation vient d’innovations permettant de créer plus de valeur à moindre coût. Or la performance globale d’une entreprise – ou d’une plus vaste chaîne de valeur – dépend de la performance de chaque activité ou métier, mais aussi de la liaison qui existe entre ces activités. Nous rejoignons ici le thème de l’organisation data-centrique, car les activités – et plus encore les liaisons entre les activités – nécessitent la réception, le traitement et l’échange d’informations.
De l’informatique centrée sur les applications à l’informatique centrée sur les données
Dans la seconde moitié du XXe siècle, lors de la première vague d’informatisation, chaque “métier” d’une entreprise avait développé des applications pour augmenter ses performances: le système de conception assisté par ordinateur, les automatismes de production, la gestion des stocks, la paye des employés, la comptabilité de l’entreprise, la base de données des clients, etc. Chaque application particulière était conçue selon les normes culturelles et le vocabulaire de son milieu d’utilisation. Les données d’entrées étaient formatées spécialement pour l’application qui les utilisait tandis que les données de sortie étaient mises en forme pour les besoins de leurs utilisateurs immédiats. On avait donc une informatisation “en silos” centrée sur les applications, chaque application commandant la structure de ses données d’entrée et de sortie.
la banque classique du début de ce texte est un bon exemple de cette informatique du XXe siècle, dont le principal défaut est la difficulté de communication entre les applications. En effet, le découpage conceptuel et le formatage des données de sortie d’une application ne correspondent pas forcément à ceux de l’entrée d’une autre application. Par exemple, si le logiciel de gestion de stock ne partage pas ses données avec celui de la base de données des clients, la réponse rapide à une commande est malaisée. Mais depuis le début du XXIe siècle les connexions à l’Internet se sont multipliées et banalisées. Sur le plan matériel, le traitement de l’information a lieu de manière croissante dans les grands centres de données d’Amazon ou de Microsoft qui louent à leurs clients de la mémoire aussi facilement que des places de stationnement et de la puissance de calcul à la demande comme s’il s’agissait d’électricité. Mémoire et puissance de calcul deviennent des marchandises disponibles sur le marché (“commodities“) que l’on a plus besoin de produire soi-même. C’est ce qu’on appelle la nuagique, ou cloud computing en anglais. Sur le plan logiciel, les API (application programming interfaces) sont des interfaces de codage / décodage des données permettent aux applications d’échanger leurs informations. Sous l’effet des mutations qui viennent d’être évoquées, l’informatique centrée sur les applications apparaît de plus en plus obsolète, bien qu’elle reste la situation de fait dans la majorité des organisations en 2021.
Par contraste avec celle du XXe siècle, l’informatique du XXIe siècle est centrée sur les données. Il faut se représenter un entrepôt commun dans lequel différentes applications viennent chercher leurs données d’entrée et déposer leurs données de sortie. Au lieu que des données spécialisées s’ordonnent autour d’applications particulières, ce sont de multiples applications, dont certaines sont éphémères, qui s’ordonnent autour d’une mémoire numérique commune et relativement stable. On dit alors que les applications deviennent interopérables. Le décollement de l’informatique data-centrique peut être datée de 2002, lorsque Jeff Bezos, le dirigeant d’Amazon, a demandé à tous ses développeurs de rendre accessible et de publier leurs données par l’intermédiaire d’une API.
Sur un plan économique, l’informatique data-centrique améliore la productivité des organisations puisqu’elle permet aux différentes activités de partager leurs données et de se coordonner plus facilement : la chaîne de valeur se fluidifie. Contrairement à ces administrations affichant des formulaires indéchiffrables en jargon bureaucratique et qui demandent dix fois aux usagers de redonner les mêmes informations sous des formes différentes parce que leurs applications ne communiquent pas, les grandes entreprises de nuagique comme les GAFAM et les BATX ont habitué les consommateurs à des temps de réaction immédiats et à des interfaces optimisées. Les entreprises les plus riches du monde sont data-centriques. Il en est de même de secteurs dynamiques de l’économie comme l’industrie du jeu vidéo ou de la distribution de films et de séries en ligne. Puisque les bénéfices de l’informatique data-centrique sont tellement évidents, pourquoi n’est-elle pas mise en oeuvre partout? Parce qu’il ne peut exister d’informatique data-centrique hors d’une organisation data-centrique et que le passage à ce nouveau type d’organisation réclame une mutation épistémologique et sociale considérable. Les grandes entreprises de nuagique datent du XXIe siècle ou de la toute fin du XXe siècle. Elles sont nées dans le paradigme numérique et ce sont elles qui ont inventé l’organisation data-centrique. Les industries plus anciennes, en revanche, peinent à suivre.
A une activité quelconque (production, vente, etc.) correspond une culture pratique, c’est-à-dire une certaine manière de découper les objets, de nommer leurs relations et d’enchaîner les opérations. L’informatisation d’une activité suppose non seulement la création d’une application mais aussi d’un système de métadonnées, et l’un comme l’autre sont conditionnés par une culture pratique datée et située. Pour fusionner les collections de données d’une organisation, il faut “réconcilier” les différents systèmes de métadonnées et, cela fait, s’engager à maintenir et faire évoluer le système de métadonnées commun pour accompagner les besoins. Tout cela demande de nombreux entretiens avec des experts des différentes sphères d’activité et des réunions d’harmonisation où les marchandages sur les définitions de concepts peuvent être rudes. La réconciliation des modèles de données n’est pas moins complexe que n’importe quelle négociation interculturelle alourdie par des enjeux de pouvoir. En effet, pour la plupart des acteurs concernés, il faut non seulement réviser ses habitudes cognitives et ses manières de faire, mais encore renoncer à une part de souveraineté locale. Il ne va plus être possible d’organiser sa mémoire pratique sans se coordonner avec les autres activités de la chaîne de valeur aussi bien sur un plan sémantique que sur un plan technique. Dès lors, la gouvernance des données, dont le principal responsable est le “Chief Information Officer” ou “Chief Data Officer“, devient une des principales fonctions de l’entreprise.
La gouvernance des données
La gouvernance des données doit faire face à deux problèmes entrelacés: sémantique et politique. Sur un plan politique, on remarquera que les systèmes de métadonnées – c’est-à-dire les catégories qui organisent les données – sont toujours liées aux caractéristiques sociales, culturelles et aux activités pratiques de leurs utilisateurs. Par exemple, dans telle grande entreprise de télécommunication, les données de consommation vont être organisées par “lignes” et non par “clients”. Or un client peut avoir plusieurs lignes et la même ligne peut être utilisée par plusieurs clients. Il est clair que les relations avec la clientèle serait plus aisée si les données étaient classées et analysées en fonction des personnes physiques ou morales qui utilisent les services de l’entreprise. Mais ce n’est pas le cas parce que l’entreprise de télécommunication est dominée par une culture d’ingénieurs pour qui les “vraies” données sont celles des lignes. Cette approche par le matériel plutôt que par l’humain permet aussi de rendre la tarification la plus “objective” possible et de la soustraire aux négociations. En somme, la manière dont une communauté organise sa mémoire reflète et réifie son identité. Réorganiser sa mémoire revient à changer d’identité. Le parallélisme entre métadonnées et contextes sociaux fait de la gouvernance des données un enjeu politique.
Quant à l’enjeu sémantique, il ne concerne plus la face subjective de l’identité – qu’elle soit personnelle ou collective – mais sa face logique. Si l’on veut que les applications soient interopérables d’un bout à l’autre de la chaîne de valeur, les objets, des relations et des processus doivent être nommées de façon unique. La difficulté vient ici de la multiplicité des métiers, chacun avec son propre jargon, et de la pluralité des langues, particulièrement dans les entreprises ou les filières internationales. Lorsqu’il s’agit de coordonner des activités, les synonymes (mots différents pour dire la même chose) et les homonymes (un mot signifiant plusieurs choses différentes) deviennent des obstacles à la collaboration. Les homonymes, en particulier, peuvent provoquer de graves erreurs de calcul. Par exemple, il est arrivé dans une compagnie aérienne que le mot “Asie” recouvre des aires géographiques différentes selon les branches et que cette incohérence sémantique provoque des erreurs de décision stratégique. Quand toutes les opérations sont automatisées et dirigées par les données, un terme ambigu peut donner de fausses indications aux dirigeants, voire interrompre une chaîne d’approvisonnement.
Le “dictionnaire de données” ou référentiel est le principal outil de la gouvernance des données. C’est là que sont énumérés tous les types de données et la manière unique de les catégoriser. Si, comme c’est souvent le cas, le référentiel n’a pas été unifié, il faut alors faire appel à des “tables d’alignement” entre systèmes. Au-delà des problèmes de cohérence, la gouvernance des données doit aussi s’occuper de la qualité des données. A cette fin on utilise un “catalogue de contrôle des données”, qui énumère les méthodes pour tester la qualité des données en fonction de leur nature. Par exemple, comment détecter les erreurs sur les noms de clients lorsque l’entreprise opère dans soixante-dix pays? Il y a des pays où on ne découpe pas en nom et prénom, d’autres pays ou des nombres sont acceptables dans un nom (en Ukraine), d’autres où un nom peut y avoir quatre ou cinq consonnes de suite, etc.
Le passage à l’organisation data-centrique implique un changement de culture et une évolution du management. Soudain, les mots et les concepts deviennent importants, et cela non seulement dans la communication et le marketing, mais aussi dans la production, qui n’est pas moins informatisée que les autres fonctions de l’entreprise. De plus, le changement culturel réclame plus d’ouverture et de communication entre départements, agences, services et métiers. Pas de bonne gestion sans gestion des données et pas de gestion des données sans bonne gestion des métadonnées. On croyait l’intérêt pour la sémantique réservée aux départements de cultural studies entichés de french theory dans les universités américaines, et voici qu’elle conditionne la productivité des entreprises!
Distinguer les mots et les concepts
Je note pour finir que les outils d’édition et de gestion de métadonnées les plus sophistiqués du marché (Pool Party, Ab Initio, Synaptica) n’ont aucun moyen de distinguer clairement entre les “mots” ou “termes” dans une langue naturelle particulière et les “concepts” ou “catégories”, qui sont des notions plus abstraites et trans-linguistiques. Le même concept peut être exprimé par différents mots dans différentes langues et le même mot peut correspondre à plusieurs concepts, y compris dans la même langue (le cardinal est-il un dignitaire ecclésiaste, un oiseau, ou un glaïeul?). Les mots sont ambigus et multiples, mais reconnaissables par des humains. Les concepts formels sous-jacents sont uniques et devraient être interprétables par les machines. En proposant un système de codage univoque des concepts et de leurs relations qui soit indépendant des langues naturelles, IEML permet de distinguer et d’articuler les mots et les concepts. Ce nouveau système de codage fait non seulement progresser la sémantique, mais recèle un pouvoir insoupçonné de fluidifier les chaînes de valeur et d’augmenter l’intelligence collective.
P.S. Je remercie John Horodyski, Paul-Louis Moreau, Samuel Parfouru et Michel Volle d’avoir bien voulu répondre à mes questions, contribuant ainsi à informer ce billet. Erreurs, inexactitudes et opinions hétérodoxes ne doivent néanmoins être attribuées qu’à l’auteur, Pierre Lévy.
Lorsque j’ai publié “L’intelligence Collective” en 1994, le WWW n’existait pas (on ne trouvera d’ailleurs pas le mot “web” dans le livre) et moins d’un pour cent de la population mondiale était connectée à l’Internet. A fortiori, les médias sociaux, les blogs, Google et Wikipedia restaient encore bien cachés dans le monde des possibles et seuls quelques rares visionnaires avaient entr’aperçu leurs contours à travers les brumes du futur. Ancêtres des médias sociaux, les “communautés virtuelles” ne rassemblaient que quelques dizaines de milliers de personnes sur la planète et le logiciel libre, déjà poussé par Richard Stallman au début des années 1980, n’allait décoller vraiment qu’à la fin des années 1990. A cette époque, néanmoins, mon diagnostic était déjà posé: (1) l’Internet allait devenir l’infrastructure principale de la communication humaine et (2) les ordinateurs en réseau allaient augmenter nos capacités cognitives, et tout particulièrement notre mémoire. L’irruption du numérique dans le cours de l’aventure humaine est aussi importante que l’invention de l’écriture ou celle de l’imprimerie. Je le pensais alors et tout le confirme aujourd’hui. On me dit souvent: “vous aviez prévu l’avènement de l’intelligence collective et regardez ce qui s’est passé!” Non, j’ai prévu – avec quelques autres – que l’humanité allait entrer en symbiose avec les algorithmes et les données. Etant donnée cette prédiction, dont on admettra qu’elle se vérifie, je posais la question: quel projet de civilisation devons nous adopter pour exploiter au mieux le médium algorithmique au profit du développement humain? Et ma réponse était : le nouveau médium nous permet, si nous le décidons, d’augmenter l’intelligence collective humaine… plutôt que de poursuivre la tendance lourde à la passivité devant des médias fascinants déjà amorcée avec la télévision et de rester polarisés par la poursuite de l’intelligence artificielle.
Art: Emma Kunz “Kaleïdoscopic Vision”
Un quart de siècle plus tard
Après avoir replacé mon “appel à l’intelligence collective” de 1994 dans son contexte, j’aborde maintenant les observations que m’inspirent les développements du dernier quart de siècle. En 2021 65% de l’humanité est connectée à l’Internet et à près de quatre-vingt-dix pour cent en Europe, en Amérique du Nord ainsi que dans la plupart des grandes métropoles. Dernièrement, la pandémie nous a forcés à utiliser massivement l’Internet pour travailler, apprendre, acheter, communiquer, etc. Les savants du monde entier partagent leurs bases de données. Nous consultons tous les jours Wikipedia, qui est l’exemple classique d’une entreprise d’intelligence collective philanthropique qui s’appuie sur le numérique. Les programmeurs partagent leurs codes sur GitHub et s’entraident sur Stack Overflow. Sans toujours en prendre clairement conscience, chacun devient auteur sur son blog, bibliothécaire lorsqu’il – ou elle – tague, étiquette ou catégorise des contenus, curateur en rassemblant des ressources, influenceur sur les médias sociaux et les plateformes d’achat en ligne, et même entraîneur d’intelligence artificielle à son corps défendant puisque nos moindres actes en ligne sont pris en compte par les machines apprenantes. Les jeux multi-joueurs distribués, le crowdsourcing, le journalisme de données et le journalisme citoyen font désormais partie de la vie quotidienne.
Les éthologues qui étudient les animaux sociaux définissent la communication stigmergique comme une coordination indirecte entre agents via un environnement commun. Par exemple, les fourmis communiquent principalement en laissant sur le sol des traînées de phéromones, et c’est ainsi qu’elles se signalent les chemins qui mènent vers la nourriture. Le surgissement d’une communication stigmergique globale par l’intermédiaire de la mémoire numérique est probablement le plus grand changement social des vingt-cinq dernières années. Nous aimons, nous postons, nous achetons, nous taguons, nous nous abonnons, nous visionnons, nous écoutons, nous lisons et ainsi de suite… Par chacun de ces actes nous transformons le contenu et le système de relations internes de la mémoire numérique, nous entraînons des algorithmes et nous modifions le paysage de données dans lequel évoluent les autres internautes. Cette nouvelle forme de communication par lecture-écriture distribuée dans une mémoire numérique collective représente une mutation anthropologique de grande ampleur qui est généralement peu ou mal perçue. Je reviendrai plus loin sur cette révolution en réfléchissant à la manière de s’en servir comme d’un point d’appui pour augmenter l’intelligence collective.
Mais il me faut d’abord parler d’une seconde transformation majeure, liée à la première, une mutation politique que je n’avais pas prévue en 1994: l’émergence de l’état plateforme. Je ne désigne pas par cette expression l’usage de plateformes numériques par les gouvernements mais le surgissement d’une nouvelle forme de pouvoir politique, qui succède à l’état-nation sans le supprimer. Le nouveau pouvoir est exercé par les propriétaires des principaux centres de données qui maîtrisent de fait la mémoire mondiale. On aura reconnu la fameuse oligarchie sino-américaine des Google, Apple, Facebook, Amazon, Microsoft, Baidu, Alibaba, Tencent et consorts. Non seulement ces entreprises sont les plus riches du monde, ayant dépassé depuis longtemps en capitalisation boursière les fleurons des vieilles industries, mais elles exercent en plus des pouvoirs régaliens classiques: investissement dans les cryptomonnaies échappant aux banques centrales ; contrôle et surveillance des marchés ; authentification des identités personnelles ; infiltration dans les systèmes d’éducation ; établissement des cartes géographiques et du cadastre ; quadrillage des cieux par des réseaux de satellites ; gestion de la santé publique (signalons les bracelets ou autres dispositifs portables, l’enregistrement des conversations chez les médecins et la mémoire épidémiologique dans les nuages). Mais surtout, les seigneurs des données se sont rendus maîtres de l’opinion publique et de la parole légitime : influence, surveillance, censure… Faites attention à ce que vous dites, car vous risquez d’être déplateformés! Enfin, le nouvel appareil politique est d’autant plus puissant qu’il s’appuie sur des ressorts psychologiques proches de l’addiction. Plus les utilisateurs deviennent dépendants du plaisir narcissique ou de l’excitation procurés par les médias sociaux et autres attracteurs d’attention, plus ils produisent de données et plus ils alimentent la richesse et le pouvoir de la nouvelle oligarchie.
Face à ces nouvelles formes d’asservissement, est-il possible de développer une stratégie émancipatrice adaptée à l’ère numérique? Oui, mais sans nourrir l’illusion que nous pourrions en finir une bonne fois pour toutes avec le côté obscur par quelque transformation radicale. Comme le dit Albert Camus à la fin de son essai de 1942 Le Mythe de Sisyphe ” La lutte elle-même vers les sommets suffit à remplir un cœur d’homme. Il faut imaginer Sisyphe heureux.” Augmenter l’intelligence collective est un travail toujours à reprendre et à approfondir. Maximiser simultanément la liberté créatrice et l’efficacité collaborative relève de la performance en contexte et ne dépend pas d’une solution technique ou politique définitive. Il reste que, lorsque les conditions culturelles et techniques que je vais maintenant évoquer seront remplies, la tâche sera plus facile et les efforts pourront converger.
La dialectique de l’homme et de la machine
La communication entre les êtres humains se fait de plus en plus par l’intermédiaire de machines au cours d’un processus distribué de lecture-écriture dans une mémoire numérique commune. Deux pôles interagissent ici: les machines et les humains. Les machines sont évidemment déterministes, que ce déterminisme soit logique (les algorithmes ordinaires, les règles de l’IA dite symbolique) ou statistique (l’apprentissage machine, l’IA neuronale). Les algorithmes d’apprentissage machine peuvent évoluer avec les flots de données qui les alimentent, mais cela ne les fait pas échapper au déterminisme pour autant. Quant aux humains, leur comportement n’est déterminé et prévisible qu’en partie. Ce sont des animaux sociaux conscients qui jouent à de multiples jeux, que traversent toutes les émotions, qui manifestent autonomie, imagination et créativité. La grande conversation humaine exprime une infinité de nuances au cours d’un processus d’interprétation en boucle fondamentalement ouvert. Bien entendu, ce sont les humains qui produisent et utilisent des machines, machines qui appartiennent donc pleinement au monde de la culture. Mais il reste que – d’un point de vue éthique, légal ou existentiel – les humains ne sont pas des machines déterministes logico-statistiques. D’un côté la liberté du sens, de l’autre la nécessité mécanique. Or force est de constater aujourd’hui que les humains gardent mémoire, interprètent et communiquent par l’intermédiaire de machines. Dans ces conditions, l’interface humain-machine ne se distingue plus qu’à peine de l’interface humain-humain. Cette nouvelle situation provoque une foule de problèmes dont les interprétations hors contexte, les traductions sans nuances, les classements grossiers et les difficultés de communication ne sont que les symptômes les plus visibles, alors que le mal profond réside dans un défaut d’autonomie, dans l’absence de contrôle sur le technocosme à l’échelle personnelle ou collective.
Réfléchissons maintenant à notre problème d’interface. Le meilleur médium de communication entre humains reste la langue, avec la panoplie de systèmes symboliques qui l’entourent, de la musique à l’expression corporelle en passant par l’image. C’est donc la langue, orale ou écrite, qui doit jouer le rôle principal dans l’interface humain-machine. Mais pas n’importe quelle langue: un idiome qui soit adéquat à la multitude des jeux sociaux, à la complexité des émotions, à la nuance expressive et à l’ouverture interprétative du côté humain. Pourtant, du côté machine, il faut que cette langue donne prise aux règles logiques, aux calculs arithmétiques et aux algorithmes statistiques. C’est pourquoi j’ai passé les vingt dernières années à concevoir une langue humaine qui soit aussi un langage machine : IEML. Le biface du noolithique se tourne d’un côté vers la générosité du sens et de l’autre vers la rigueur mathématique. Un tel outil nous donnera prise sur notre environnement technique (programmer et contrôler les machines) aussi facilement que nous communiquons avec nos semblables. En sens inverse, il synthétisera les flots de données qui nous concernent par des diagrammes explicatifs, des paragraphes compréhensibles, voire des messages multimedia empathiques. Bien plus, cette nouvelle couche techno-cognitive nous permettra de dépasser la communication stigmergique plus ou moins opaque que nous entretenons par l’intermediaire de la mémoire numérique commune pour atteindre une intelligence collective réflexive.
Vers une intelligence collective réflexive
Des images, des sons, des odeurs et des lieux balisent la mémoire humaine, comme celle des animaux. Mais c’est le langage qui unifie, ordonne et réinterprète à volonté notre mémoire symbolique. La chose est vraie non seulement à l’échelle individuelle mais aussi à l’échelle collective, par la transmission des récits et l’écriture. Grâce au langage, l’humanité a pu accéder à l’intelligence réflexive. Par analogie, je pense que nous n’accèderons à une intelligence collective réflexive qu’en adoptant une langue adéquate à l’organisation de la mémoire numérique.
Examinons les conditions nécessaires à l’avènement de cette nouvelle forme de réflexion critique à grande échelle. Puisque la cognition sociale doit pouvoir s’observer elle-même, nous devons modéliser des systèmes humains complexes et rendre ces modèles aisément navigables. À l’image des groupes humains en interaction, ces représentations numériques seront alimentées par des sources de données hétérogènes organisées par des logiques disparates. Nous devons d’autre part donner à lire des processus de pensée dynamiques, de type conversationnel, où les formes émergent, évoluent et s’hybrident, comme dans la réalité de nos écosystèmes d’idées. De plus, puisque nous voulons optimiser nos décisions et coordonner nos actions, il nous faut rendre compte de relations causales, éventuellement circulaires et entrelacées. Enfin, nos modèles doivent être comparables, interopérables et partageables, sans quoi les images qu’ils nous renverraient n’auraient aucune objectivité. Nous devons donc accomplir dans la dimension sémantique ce qui a déjà été mené à bien pour l’espace, le temps et diverses unités de mesure: établir un système de coordonnées universel et régulier qui favorise la modélisation formelle. Ce n’est que lorsque ces conditions seront remplies que la mémoire numérique pourra servir de miroir et de multiplicateur à l’intelligence collective humaine. La puissance d’enregistrement et de calcul de centres de données gigantesques rend désormais cet idéal atteignable et le système de coordonnées sémantique (IEML) est déjà disponible.
Dans le labyrinthe de la mémoire
Jusqu’à l’invention de l’imprimerie à caractères mobiles par Gutenberg, l’une des parties les plus importantes de la rhétorique était l’art de la mémoire. Il s’agissait d’une méthode mnémotechnique dite « des lieux et des images ». L’orateur en herbe devait s’entraîner à la représentation mentale d’un espace architectural – réel ou imaginaire – de grande envergure, comme par exemple un palais ou un temple, voire une place, où seraient disposés plusieurs bâtiments. Les idées à mémoriser devaient être représentés par des images placées dans les lieux de l’architecture palatiale. C’est ainsi que les fenêtres, niches, pièces et colonnades du palais (les « lieux ») étaient peuplés de personnages humains porteurs de caractères émotionnellement et visuellement frappants, afin d’être mieux retenus (les « images »). Les relations sémantiques entre les idées étaient d’autant mieux mémorisées et utilisées qu’elles étaient représentées par des relations locales entre images.
A partir du XVIe siècle en Occident, la crainte d’oublier cède le pas à l’angoisse d’être noyé dans la masse des informations imprimées. Aux arts de la mémoire adaptés aux époques de l’oral et du manuscrit, succède l’art d’organiser les bibliothèques. On découvre alors que la conservation de l’information ne suffit pas, il faut la classer et la placer (les deux choses vont de pair avant le numérique) de telle sorte que l’on trouve facilement ce que l’on cherche. Au plan du palais imaginaire succède la disposition des rayons et des étagères de la bibliothèque. La distinction des données (livres, journaux, cartes, archives de toutes sortes) et des métadonnées s’affirme au début du XVIIIe siècle. Le système de métadonnées d’une bibliothèque comporte essentiellement le catalogue des documents entreposés et les fiches cartonnées classées dans des tiroirs qui donnent, pour chaque item: son auteur, son titre, son éditeur, sa date de publication, son sujet, etc. Sans oublier la cote qui indique le lieu précis où le document est rangé. Ce dédoublement des données et des métadonnées a d’abord lieu bibliothèque par bibliothèque, chacune avec son propre système d’organisation et son vocabulaire local. Un nouveau degré dans l’abstraction et la généralisation est franchi au XIXe siècle avec l’avènement de systèmes de classification à vocation universelle, qui s’appliquent à un grand nombre de bibliothèques et dont le système “décimal” de Dewey est l’exemple le plus connu.
Avec la transformation numérique qui commence à la fin du XXe siècle, la distinction entre données et métadonnées n’a pas disparu, mais elle ne se déploie plus dans un espace physique à l’échelle humaine. Dans une base de données ordinaire, chaque champ correspond à une catégorie générale (le nom du champ est une sorte de métadonnée, comme par exemple “adresse”) tandis que la valeur du champ “8, rue du Petit Pont” correspond à une donnée. Sur les tableaux Excel, les colonnes correspondent en fait aux métadonnées et le contenu des cellules aux données. Dans une base de données dite relationnelle le système de métadonnées n’est autre que le schéma conceptuel qui préside à sa structuration. Chaque base de données possède évidemment son propre schéma, adapté aux besoins de son utilisateur. Les bases de données classiques ont d’ailleurs été conçues avant l’Internet, quand il était bien rare que les ordinateurs communiquent. Tout change avec l’adoption massive du Web à partir de la fin du XXe siècle. En un sens, le Web est une grande base de données virtuelle distribuée dont chaque item possède une adresse ou une “cote”: l’URL (Uniform Resource Locator), qui commence par http:// (Hypertext Transfer Protocol). Ici encore, les métadonnées sont intégrées aux données, par exemple sous la forme de tags. Le Web faisant potentiellement communiquer toutes les mémoires, le disparate des systèmes de métadonnées locaux ou des folksonomies improvisées (tels que les hashtags utilisés dans les médias sociaux) devient particulièrement criant.
Mais l’abstraction et le décollement des métadonnées expérimentés par les bibliothèques au XIXe siècle est réinventé dans le numérique. Une même modèle conceptuel peut être utilisé pour structurer des données différentes tout en favorisant la communication entre mémoires distinctes. Les modèles tels que schema.org, soutenu par Google, ou CIDOC-CRM, développé par les institutions de conservation des héritages culturels en sont de bons exemples. La notion de métadonnée sémantique, élaborée dans le milieu de l’intelligence artificielle symbolique des années 1970 est popularisée par le projet du Web Sémantique lancé par Tim Berners Lee dans la foulée du succès du Web. Ce n’est pas ici le lieu d’expliquer l’échec relatif de ce dernier projet. Contentons-nous de signaler que les contraintes rigides imposées par les formats standards du World Wide Web Consortium ont découragé ses utilisateurs potentiels. La notion d’ontologie cède aujourd’hui la place à celle de Graphe de Connaissance (Knowledge Graph) dans lequel on accède à des ressources numériques au moyen d’un modèle de données et d’un vocabulaire contrôlé. Dans cette dernière étape de l’évolution de la mémoire, les données ne sont plus contenues dans les schémas tabulaires fixes des bases de données relationnelles, mais dans les nouvelles bases de données de graphes, plus souples, plus faciles à faire évoluer, mieux à même de représenter des modèles complexes et autorisant plusieurs “vues” différentes. Un graphe de connaissance se prête au raisonnement automatique (IA symbolique classique), mais aussi à l’apprentissage automatique s’il est bien conçu et si les données sont en nombre suffisant.
Aujourd’hui encore, une grande partie de la mémoire numérique se trouve dans des bases relationnelles, sans distinction claire des données et des métadonnées, organisée selon des schémas rigides mutuellement incompatibles, mal optimisée pour les besoins de connaissance, de coordination ou d’aide à la décision de leurs utilisateurs. Réunies dans des entrepôts communs (datalakes, datawarehouses), ces données indexées ou cataloguées selon des systèmes de catégories disparates mènent parfois à des représentations ou des simulations incohérentes. La situation dans le monde encore minoritaire des knowledge graphs est certes plus brillante. Mais de nombreux problèmes demeurent : il est encore bien difficile de faire communiquer des langues, des domaines d’affaire ou des disciplines différentes. Si la visualisation de l’espace (projection sur des cartes), du temps (frises chronologiques) et des quantités est entrée dans les moeurs, la visualisation de structures qualitatives complexes (comme les actes de langage) reste un défi, et cela d’autant plus que ces structures qualitatives sont essentielles pour la compréhension causale des systèmes humains complexes.
Il nous faut produire encore un effort pour transformer la mémoire numérique en support d’une intelligence collective réflexive. Une intelligence collective autorisant tous les points de vue, mais bien coordonnée. Il suffit pour cela de reproduire à une hauteur supplémentaire le geste d’abstraction qui a mené à la naissance des métadonnées à la fin du XVIIIe siècle. Dédoublons donc les métadonnées en (a) modèles et (b) métalangage. Les modèles pourront être aussi nombreux et riches que l’on voudra, ils communiqueront – avec les langues naturelles, les humains et les machines – par l’intermédiaire d’un métalangage commun. Dans la bibliothèque de Babel, il est temps d’allumer la lumière.
Ou comment passer d’un langage de métadonnées à une culture de l’intelligence collective…
L’ENJEU DES MÉTADONNÉES
Les métadonnées sont les données qui organisent les données. Les données sont comme les livres d’une bibliothèque et les métadonnées comme le fichier et le catalogue de la bibliothèque: leur fonction est d’identifier les livres afin de mieux les ranger et les retrouver. Les métadonnées servent moins à décrire exhaustivement les choses (il ne s’agit pas de faire des cartes à la même échelle que le territoire…) qu’à fournir des repères à partir desquels les utilisateurs pourront trouver ce qu’ils cherchent, avec l’aide d’algorithmes. Tous les systèmes d’information et applications logicielles organisent l’information au moyen de métadonnées.
On peut distinguer…
1) les métadonnées matérielles, comme le format d’un fichier, sa date de création, son auteur, sa licence d’utilisation, etc.
2) les métadonnées sémantiques qui concernent le contenu d’un document ou d’un ensemble de données (de quoi ça parle) ainsi que leur dimension pratique (à quoi servent les données, à qui, dans quelles circonstances, etc.).
Art: Emma Kunz
On s’intéresse ici principalement aux métadonnées sémantiques. Un système de métadonnées sémantiques peut être aussi simple qu’un vocabulaire. Au niveau de complexité supérieur cela peut être une classification hiérarchique ou taxonomie. Au niveau le plus complexe, c’est une “ontologie”, c’est-à-dire la modélisation d’un domaine de connaissance ou de pratique, qui peut contenir plusieurs taxonomies avec des relations transversales, y compris des relations causales et des possibilités de raisonnement automatique.
Les métadonnées sémantiques représentent un élément essentiel des dispositifs d’intelligence artificielle :
– elles sont utilisées comme squelettes des graphes de connaissances (knowledge graphs) – ou bases de connaissances – mis en oeuvre par les big techs (Google, Facebook, Amazon, Microsoft, Apple…) et de plus en plus dans des grandes et moyennes entreprises,
– elles sont utilisées – sous le nom de “labels” – pour catégoriser les données d’entraînement des modèles de deep learning.
Parce qu’ils structurent la connaissance contemporaine, dont le support est numérique, les systèmes de métadonnées représentent un enjeu considérable aux niveaux scientifique, culturel, politique…
Un des buts de ma compagnie INTLEKT Metadata Inc. est de faire de IEML (Information Economy MetaLanguage) un standard pour l’expression des systèmes de métadonnées sémantiques. Quel est le paysage contemporain dans ce domaine?
LE PAYSAGE DES MÉTADONNÉES SÉMANTIQUES AUJOURD’HUI
Formats Standards
Le système de formats et de “langages” standards proposé par le World Wide Web Consortium – W3C – (XML, RDF, OWL, SPARQL) pour atteindre le “Web Sémantique” existe depuis la fin du 20e siècle. Il n’a pas réellement pris, et notamment pas dans les entreprises en général et les big tech en particulier, qui utilisent des formats moins lourds et moins complexes, comme les “property graphs“. De plus, la catégorisation manuelle ou semi-manuelle des données est souvent remplacée par des approches statistiques d’indexation automatique (NLP, deep learning…), qui contournent la nécessité de concevoir des systèmes de métadonnées. Le système de standards du W3C concerne les *formats de fichiers et de programmes* traitant les métadonnées sémantiques mais *pas la sémantique proprement dite*, à savoir les catégories, concepts, propriétés, événements, relations, etc. qui sont toujours exprimées en langues naturelles, avec toutes les ambiguïtés, multiplicités et incompatibilités que cela implique.
Modèles standards
Au dessus de ce système de formats standards existent des modèles standards pour traiter le contenu proprement sémantique des concepts et de leurs relations. Par exemple schema.org pour les sites web, CIDOC-CRM pour le domaine culturel, etc. Il existe des modèles standard pour de très nombreux domaines, de la finance à la médecine. Le problème est qu’il existe souvent plusieurs modèles concurrents pour un domaine et que les modèles eux-mêmes sont hypercomplexes, au point que même les spécialistes d’un modèle n’en maîtrisent qu’une petite partie. De nouveau, ces modèles sont exprimés en langues naturelles, avec les problèmes que cela suppose… et le plus souvent en anglais.
Systèmes de métadonnées particuliers
Les taxonomies, ontologies et autres systèmes de métadonnées mis en oeuvre dans des applications réelles pour organiser des ensembles de données sont le plus souvent des utilisations partielles des modèles standards et des formats standards. Les utilisateurs se soumettent – plus ou moins bien – à ces couches de standards dans l’espoir que leurs données et applications deviendront les heureux sujets d’un royaume de l’interopérabilité sémantique. Mais leurs espoirs sont déçus. L’idéal du Web intelligent décentralisé de la fin des années 1990 a cédé la place au search engine optimization (SEO) plus ou moins aligné sur le knowledge graph (secret!) de Google. Il faut bien reconnaître, près d’un quart de siècle après son lancement, que le Web Sémantique du W3C n’a pas tenu ses promesses.
Problèmes rencontrés
Pour obtenir l’interopérabilité sémantique, c’est-à-dire la communication fluide entre bases de connaissance, les responsables de systèmes d’information se soumettent à des modèles et formats rigides. Mais à cause de la multitude des formats, des modèles et de leurs applications disparates, sans parler des différences de langues, ils n’obtiennent pas le gain attendu. De plus, produire un bon système de métadonnées coûte cher, car il faut réunir une équipe pluridisciplinaire comprenant : un chef de projet, un ou des spécialistes du domaine d’utilisation, un spécialiste de la modélisation formelle de type taxonomie ou ontologie (ingénierie cognitive) qui soit capable de se retrouver dans le labyrinthe des modèles standards et enfin un ingénieur informaticien spécialiste des formats de métadonnées sémantiques. Certaines personnes réunissent plusieurs de ces compétences, mais elles sont rares.
COMMENT IEML PEUT-IL RÉSOUDRE LES PROBLÈMES RENCONTRÉS DANS LE MONDE DES MÉTADONNÉES SÉMANTIQUES ?
IEML en deux mots
IEML – aujourd’hui breveté par INTLEKT Metadata – n’est ni une taxonomie, ni une ontologie universelle, ni un modèle, ni un format: c’est une *langue* ou une *méta-ontologie* composée (1) de quelques milliers de primitives sémantiques organisées en paradigmes et (2) d’une grammaire entièrement régulière.
Caractéristiques uniques du langage IEML
IEML est “agnostique” quand aux formats, langues naturelles et relations hiérarchiques entre concepts. IEML permet de construire et de partager n’importe quel concept, hiérarchie de concepts ou relation entre concepts. IEML ne produit donc pas d’uniformisation ou d’aplatissement des possibilités expressives. Pourtant, IEML assure l’interopérabilité sémantique, c’est-à-dire la possibilité de fusionner, d’échanger, de recombiner, de connecter et de traduire quasi-automatiquement les systèmes de métadonnées et les bases de connaissances organisées par ces métadonnées. IEML permet donc de concilier le maximum d’originalité, de complexité ou de simplicité cognitive d’un côté et l’interopérabilité ou la communication de l’autre, contrairement à ce qui se passe dans la situation contemporaine où l’interopérabilité se “paye” par la réduction des possibilités expressives.
Fonctions uniques de l’éditeur IEML
Autre avantage: contrairement aux principaux outils d’édition de métadonnées contemporains (Smart Logic Semaphore, Pool Party, Synaptica, Top Braid Composer) l’éditeur IEML conçu par INTLEKT sera intuitif (interface visuelle à base de tables et de graphes) et collaboratif. Il n’est pas destiné aux spécialistes de RDF et OWL (les formats standards), comme les éditeurs cités plus hauts, mais aux spécialistes des domaines d’applications. Une méthode accompagnant l’outil va aider les experts à formaliser leurs domaines en IEML. Le logiciel importera et exportera automatiquement les métadonnées dans les formats standards choisis par l’utilisateur. C’est ainsi que l’éditeur IEML permettra de réduire la complexité et le coût de la création des systèmes de métadonnées sémantiques.
Marché des outils d’édition et de gestion des systèmes de métadonnées
On comprend aisément que, la masse des données produites ne cessant de croître, tout comme le besoin d’en extraire des connaissances utilisables, on ait de plus en plus besoin de créer et de maintenir de bons systèmes de métadonnées. Le marché des outils d’édition et de gestion des systèmes de métadonnées sémantiques représente aujourd’hui deux milliards de dollars et il pourrait atteindre (selon une estimation très conservatrice) seize milliards de dollars en 2026. Cette projection agrège : 1) les données de l’industrie sémantique proprement dite (les entreprises qui créent des systèmes de métadonnées pour leurs clients), 2) les outils d’annotation sémantique des datasets d’entraînement pour le machine learning utilisés notamment par les data scientists, 3) la gestion des systèmes de métadonnées en interne par les big tech.
LES BUTS DE INTLEKT METADATA À L’HORIZON DE 5-10 ANS
La fondation
Nous voulons qu’IEML devienne un standard open-source pour les métadonnées sémantiques autour de 2025. Le standard IEML devra être supporté, maintenu et développé par une fondation à but non lucratif. Cette fondation supervisera aussi une communauté d’édition collaborative de systèmes de métadonnées en IEML et une base de connaissance publique de données catégorisées en IEML. La fondation créera un écosystème socio-technique favorable à la croissance de l’intelligence collective.
L’entreprise privée
INTLEKT continuera à maintenir l’outil d’édition collaborative et à concevoir des bases de connaissances sémantiques sur mesure pour des clients solvables. Nous mettrons également en oeuvre un marché – ou système d’échange – des données privées indexées en IEML qui sera basé sur la blockchain. Les bases de connaissances indexées en IEML seront interopérables sur les plans parallèles de l’analyse des données, du raisonnement automatique et de l’entraînement des modèles neuronaux.
Néanmoins, avant d’arriver à ce point, INTLEKT doit démontrer l’efficacité d’IEML au moyen de plusieurs cas d’usage réels.
LE MARCHÉ D’INTLEKT METADATA À L’HORIZON DE 2-5 ANS
Des entretiens avec de nombreux clients potentiels nous ont permis de définir notre marché pour les années qui viennent. Définissons les domaines pertinents par élimination et approximations successives.
Les affaires humaines
IEML n’est pas pertinent pour la modélisation d’objets purement mathématiques, physiques ou biologiques. Les sciences exactes disposent déjà de langages formels et de classifications reconnues. En revanche IEML est pertinent pour les objets des sciences humaines et des sciences sociales ou pour les interactions entre objets des sciences exactes et objets des sciences humaines, comme la technologie, la santé, l’environnement ou le phénomène urbain.
Les domaines non-standards
Dans l’immédiat, nous ne nous épuiserons pas à traduire en IEML tous les modèles de métadonnées existants: ils sont très nombreux, parfois contradictoires et rarement utilisés en totalité. Beaucoup d’utilisateurs de ces modèles se contentent d’en sélectionner une petite sous-partie utile et n’investiront pas leur temps et leur argent dans une nouvelle technologie sans nécessité. Par exemple, les nombreuses entreprises qui font du SEO (Search Engine Optimization) extraient un sous-ensemble utile des *classes* de schema.org (patronné par Google) et des *entités* de Wikidata (parce qu’elles sont réputées fiables par Google) et n’ont pas besoin de technologies sémantiques supplémentaires. Autres exemples: les secteurs des galeries, des musées, des bibliothèques ou des archives doivent se soumettre à des standards professionnels rigides avec des possibilités d’innovation limitées. En somme les secteurs qui se contentent d’utiliser un modèle standard existant ne font pas partie de notre marché à court terme. Nous ne mènerons pas de batailles perdues d’avance. A long terme, nous envisageons néanmoins une plateforme collaborative où pourra s’effectuer la traduction volontaire des modèles standards actuels en IEML.
Eliminons également le marché du commerce en ligne pour le moment. Ce secteur utilise bien des systèmes de catégories pour identifier les grands domaines (immobilier, voitures, électroménager, jouets, livres, etc…), mais la multitude des biens et services à l’intérieur de ces catégories assez larges est appréhendée par des systèmes de traitement automatique des langues naturelles ou d’apprentissage machine, plutôt que par des systèmes de métadonnées raffinés. Nous ne croyons pas à une adoption d’IEML à court terme dans le commerce en ligne.
Reste les domaines non-standards – qui n’ont pas de modèles tous faits – ou multi-standards – qui doivent construire des modèles hybrides ou des carrefours – et pour qui les approches statistiques sont utiles… mais pas suffisantes. Pensons par exemple à l’apprentissage collaboratif, à la santé publique, aux villes intelligentes, à la documentation du logiciel, à l’analyse de corpus complexes relevant de plusieurs disciplines, etc.
La modélisation et la visualisation de systèmes complexes
Au sein des domaines non-standards, nous avons identifié les besoins suivants, qui ne sont pas comblés par les technologies sémantiques en usage aujourd’hui :
– La modélisation de systèmes humains complexes, où se rencontrent plusieurs “logiques” hétérogènes, C’est-à-dire des groupes obéissant à divers types de règles. Citons notamment les données produites par les processus de délibération, d’argumentation, de négociation et d’interaction techno-sociale.
– La modélisation de systèmes causaux, y compris les causalités circulaires et entrelacées.
– La modélisation de systèmes dynamiques au cours desquels les objets ou les actants se transforment. Ces dynamiques peuvent être de type : évolution, ontogénèse, hybridations successives, etc.
– L’exploration et la visualisation interactive 2D ou 3D de structures sémantiques dans des corpus immenses, de préférence sous une forme mémorable, c’est-à-dire facile à retenir.
Dans les années qui viennent, INTLEKT se propose de modéliser de manière causale des systèmes dynamiques complexes impliquant la participation humaine et de donner accès à une exploration sensori-motrice mémorable de ces systèmes.
IEML étant une langue, tout ce qui peut se définir, se décrire et s’expliquer en langue naturelle peut être modélisé de manière formelle en IEML, fournissant ainsi un cadre qualitatif à des mesures et des calculs quantitatifs. On pourra faire du raisonnement automatique à partir de règles, de la prévision et de l’aide à la décision, mais le principal apport d’IEML sera d’augmenter les capacités, d’analyse, de synthèse, de compréhension mutuelle et de coordination dans l’action des communautés utilisatrices.
LES SIX PROCHAINS MOIS
La langue IEML existe déjà. Son élaboration a été financée à hauteur d’un million de dollars dans un cadre académique. Nous avons également un prototype de l’éditeur. Il nous faut maintenant passer à une version professionnelle de l’éditeur afin de pouvoir répondre aux besoins du marché identifié à la section précédente. Nous avons pour cela besoin d’un investissement privé d’environ 226 K US$, qui servira essentiellement au développement d’une plateforme d’édition collaborative pourvue de l’interface adéquate. Avis aux investisseurs.
[this is the transcription of an interview that I gave to Daniela Fernandes — Para o Valor.Globo.com published 26/03/2021]
O filósofo francês Pierre Lévy, de 64 anos, começou a pesquisar as implicações culturais da comunicação digital há 30 anos, em uma época em que a web (o famoso www) ainda nem existia e apenas 1% da população estava conectada. Naquele momento, havia uma utopia do conhecimento sem fronteiras propiciado pelo ciberespaço, em que a informação sem limites e acessível a todos permitiria o progresso da humanidade. Lévy criou o conceito de “inteligência coletiva” – tema de um de seus livros publicado nos anos 1990 na França -, um princípio segundo o qual os conhecimentos individuais são somados e compartilhados livremente em escala planetária graças à internet.
Pesquisador da Universidade de Montreal na área de “humanidade digital” e ex-professor da Universidade de Ottawa, no Canadá, Lévy prevê criar uma empresa de inteligência artificial que visa melhorar a categorização de dados. O filósofo esteve no Brasil em 2016 e 2019 para participar do Fronteiras do Pensamento, que neste ano ocorre em formato digital. [Encurtei a introdução do jornalista. PL] A seguir, os principais trechos da entrevista concedida ao Valor:
Pierre Lévy in 2021
Valor: Nos anos 1990, quando o senhor publicou o livro “Inteligência Coletiva”, a comunicação digital era vista como uma ferramenta que permitiria a igualdade à informação e o progresso da humanidade. Mas, na prática, há também desinformação e polarização da sociedade. Como o senhor vê a evolução da internet?
Pierre Lévy: A inteligência coletiva facilitou e melhorou a comunicação entre as pessoas. Temos essa ferramenta extraordinária que é o Wikipedia, um belo exemplo de inteligência coletiva. O movimento do software livre é outro exemplo. Vários programas para computador criados pela rede GitHub, que reúne engenheiros de informática, são públicos e foram realizados de forma colaborativa. No mundo do trabalho e das associações, as mídias sociais são utilizadas de maneira eficiente. Há um real desenvolvimento da inteligência coletiva, da colaboração, da reflexão conjunta. Constrói-se uma memória comum em uma escala que era impossível antes da internet. Com cerca de 60% da população mundial hoje conectada, temos todas as qualidades, mas também os defeitos da humanidade que se refletem na inteligência coletiva: mentiras, incitação à violência, fanatismo e pornografia. Temos um espelho da humanidade. Tudo é lá. A internet nos reenvia uma outra imagem de quem somos.
Valor: Jeff Orlowski, diretor do documentário da Netflix “O Dilema das Redes”, diz que as plataformas de mídia social dispõem hoje de um poder enorme em relação à maneira como bilhões de pessoas vivem suas vidas. O filme mostra que as redes estão manipulando os usuários e afetando a democracia. Qual é o impacto disso?
Lévy: As gigantes da web, como Google, Amazon, Facebook, Apple e Microsoft, adquiriram um poder extraordinário, algo que eu não havia pensado anos atrás. Elas têm um monopólio sobre a memória mundial e registram quase tudo que acontece na internet. Além de serem as companhias mais ricas do mundo, faz tempo que elas ultrapassaram as empresas do setor de energia, têm todos os dados, as tecnologias mais potentes e oferecem as infraestruturas necessárias para a comunicação entre as pessoas. Elas estão desenhando uma nova forma de poder econômico, o que é evidente, mas sobretudo político. Muitas funções sociais e políticas, que são funções tradicionais dos Estados-nação, estão passando para essas companhias. Na minha avaliação, é uma nova forma de Estado, que eu denomino Estado-plataforma.
Valor: Como o Estado-plataforma afeta a sociedade?
Lévy: Entre todas as funções de um Estado, o controle do espaço público é provavelmente a que mais nos afeta diretamente. Quando fazemos uma pesquisa no Google, é a empresa quem decide o que aparece nas primeiras páginas da busca. Ninguém vai olhar a centésima página. Essas companhias podem fazer censura. Não no sentido de proibir totalmente, mas de maneira que o que aparece para os internautas é o que a plataforma decidiu. Twitter ou Facebook, particularmente implicados nessa noção de conversa pública, aplicam agora claramente a censura. É um poder que vai além do econômico. O Facebook, por exemplo, passou a verificar identidades. Google Maps vai funcionar como cadastro para pequenos países que não têm muitos recursos, administrando a cartografia do território. Amazon vai começar a certificar as transações financeiras de maneira mais eficiente do que os governos. E há o desenvolvimento das famosas criptomoedas (como os bitcoins). Facebook e outras companhias da web têm projetos de criar isso. Amazon e Facebook estão entrando na corrida espacial e devem lançar satélites para facilitar o acesso à internet. São essas companhias que terão a infraestrutura física de tudo isso.
Valor: É uma nova forma de poder político, em termos históricos?
Lévy: O Estado-nação surgiu no século XVI na Europa, com uma unidade cultural, uma língua comum, um controle da economia. Essa forma de organização econômica e política permitiu a países do continente de dominar o mundo. Mas o que vejo agora, em termos de desenvolvimento histórico, é uma nova forma política que se baseia na potência da memória e do cálculo dessas companhias da nuvem. Não há nenhuma burocracia governamental que seja tão eficiente como a potência de memória e de cálculo da Amazon, da Apple ou do Google.
Valor: O Estado-plataforma introduz, na sua avaliação, uma forma de domínio ideológico radicalmente novo graças às tecnologias da comunicação?
Lévy: Podemos voltar muito no tempo sobre as técnicas de dominação política. Na época da cultura oral, havia tribos e reinos, mas não existia burocracia. As primeiras civilizações, baseadas em palácios-templos, inauguram as primeiras formas de Estado. Depois vieram os impérios, que impuseram uma forma de domínio multinacional, multilinguístico, sem homogeneidade cultural. O Estado-nação introduziu um novo tipo de domínio político que implica uniformidade cultural por meio da educação e do serviço militar obrigatório. Com o surgimento das grandes plataformas digitais, como Google, o que aparece não é uma nação, e sim o princípio de um Estado.
Valor: Isso não é uma ameaça à democracia?
Lévy: Não se nos desligarmos afetivamente dessas grandes plataformas digitais. Há uma dimensão de vício no uso desses serviços. Quando alguém utiliza uma mídia social, espera sempre um retorno positivo. Há o receio de não ficar a par do que está acontecendo e de se sentir excluído. São sentimentos humanos, mas quando transpostos a esse espaço virtual, sobretudo em escala planetária, criam uma dependência. Esses novos “Estados” têm tentáculos no nosso cérebro porque somos vítimas de uma forma de vício. Cada vez que temos um “like” é como uma secreção de dopamina. Se não conseguirmos nos desligar dessa dependência, não vejo meios de se opor aos Estados-plataforma. Atualmente, até mesmo os governos se servem dessas empresas.
Valor: Os serviços digitais estão totalmente integrados ao dia a dia das pessoas. Continuaremos ameaçados de sofrer manipulação com a ascensão dos Estados-plataforma?
Lévy: Não mais do que antes. Sempre houve um domínio das elites políticas e econômicas sobre o restante da população. Mas não era nessa escala geográfica. Pessoalmente, como filósofo humanista que reflete sobre a história, penso que o melhor a ser feito é desenvolver a educação, o espírito crítico e a leitura para manter um certo distanciamento em relação às exigências da política, da economia e dos conflitos ideológicos.
Valor: Qual futuro os Estados-plataforma preparam à sociedade?
Lévy: Não tenho a pretensão de prever algo. Os Estados tradicionais estão se fundindo com as plataformas digitais por uma razão simples: elas têm meios bem mais potentes que os Estados tradicionais. Em relação às políticas de defesa nacional, os Estados precisam dessas companhias, por exemplo, para gerenciar os dados de campos de batalhas. Nas questões de segurança, as tecnologias da informação são utilizadas pelos serviços de inteligência. As políticas de saúde pública integram igualmente um imperativo de gestão de dados em massa de dossiês médicos. Captores colocados em pacientes coletam dados enviados às nuvens. A segurança, a saúde e a economia só podem, de agora em diante, ser administrados por meios ultrapoderosos propiciados pelas tecnologias da informação. Há também a opinião das pessoas, que pode ser controlada por meios sutis. É a direção na qual vamos. Já estamos nisso. O controle do espírito não é algo novo. Esquecemos que não faz muito tempo que muitos eram influenciadas pela religião. O que é novo, agora, é o método.
Valor: As redes sociais favoreceram a ultrapolarização política da sociedade em vários países. Qual pode ser o impacto da influência dessas plataformas nas eleições presidenciais americanas no mês que vem?
Lévy: Já faz cerca de dez anos que o marketing personalizado é utilizado por todos os partidos políticos em países relativamente ricos para influenciar o voto das pessoas. Com as mídias sociais, surgiu a possibilidade de cálculos estatísticos direcionados às pessoas, com o envio de mensagens diferentes segundo a categoria social. Isso foi feito pelos republicanos e pelos democratas nos Estados Unidos e em países como o Canadá e a França. O escândalo da Cambridge Analytica, empresa de análise, que utilizou o vazamento de dados pessoais de milhões de usuários do Facebook para influenciar o voto das pessoas (nas eleições presidenciais americanas de 2016), foi algo marginal. O que é novo é a comunicação política baseada nos dados. A então candidata Hillary Clinton usou uma segmentação por sexo, idade e cor, enquanto a campanha de Trump aplicou os métodos da Cambridge Analytica, baseados em uma categorização psicológica, que foi mais eficaz do que a categorização social. Mas, agora, todo mundo utiliza os dados em massa e as tecnologias digitais para influenciar o voto dos cidadãos.
Valor: O Facebook vem reforçando suas regras às vésperas da eleição americana: anunciou que suspenderá toda publicidade política após a votação e proibiu as páginas ligadas à teoria conspiratória QAnon, classificado como ameaça terrorista pelo FBI. A violência dos ataques nas mídias sociais durante a campanha presidencial pode levar a conflitos nas ruas?
Lévy: Todos têm medo de uma guerra civil nos Estados Unidos. A ala esquerda do Partido Democrata fez declarações que iam no mesmo sentido das feitas pelo presidente Donald Trump. Se o republicano ganhar, a eleição seria ilegítima ou haveria fraude. Há dos dois lados a ameaça de não aceitar o resultado da votação ou de contestá-lo. Tenho confiança de que os americanos não vão entrar em uma guerra civil. Espero não estar enganado, mas tudo é possível. Já houve uma guerra civil no século XIX no país, e na época não havia redes sociais.
Valor: A internet impulsionou a disseminação de “fake news” e de teorias da conspiração, como vemos na pandemia de covid-19. O senhor critica o fato de que as redes sociais estão apagando publicações, inclusive de presidentes como Donald Trump ou Jair Bolsonaro. Não deve haver limites para a liberdade de expressão, mesmo que isso represente desinformação?
Lévy: As mentiras, as manipulações e os exageros não começaram com a internet. O desenvolvimento da web coincidiu com o da educação. Em países pobres, é possível ter acesso a uma documentação pedagógica gratuita graças à internet. Desde o surgimento da internet, a humanidade continuou a evoluir. O desenvolvimento das tecnologias da informação acompanhou o desenvolvimento humano. Todos que dizem coisas contrárias à Organização Mundial da Saúde foram deletados do YouTube, mesmo que sejam médicos.
Valor: O senhor diz ter constatado que as teorias da conspiração são sempre as teses do outro que possui uma visão ideológica diferente. Se cada um pensar que é o dono da verdade, então quem teria legitimidade para arbitrar a respeito?
Lévy: Quem conhece a verdade? O astrônomo Galileu Galilei (1564-1642), que transformou radicalmente o conhecimento sobre o universo, era o único que dizia algo verdadeiro, mas foram necessários vários séculos para que todos concordassem com ele. Quem deve decidir se o que o outro diz é verdadeiro? As plataformas praticam abertamente a censura. Algumas coisas são censuradas e outras menos, como é o caso do antissemitismo. Acho que duas coisas deveriam ser apagadas nas mídias sociais: a incitação ao homicídio e o que é proibido pelas leis do país. Mas nem sempre a incitação ao homicídio é excluída.
Valor: Podemos dizer que a internet é tanto um instrumento de inteligência coletiva quanto de besteira coletiva?
Lévy: Ouço isso o tempo todo. As pessoas dizem que não se vê inteligência coletiva nas redes sociais, e sim besteira coletiva. Na realidade, a inteligência coletiva não é o contrário da besteira coletiva. Eu me refiro à capacidade das pessoas de compartilhar informações, de refletir e se coordenar. A comunidade científica é uma grande instituição de inteligência coletiva. A memória, a coordenação e a reflexão podem ser ampliadas. Isso não significa que não cometemos erros. Apesar de todos os efeitos negativos da utilização da internet, sua contribuição à inteligência coletiva permanece válida.
IEML est fondé sur les grandes découvertes de la linguistique du XXe siècle. Dans cette entrée de blog nous allons étudier successivement les héritages de Chomsky; de Saussure et de l’école structuraliste; de Tesnière et du modèle actantiel de la phrase; de Benveniste, Wittgenstein et Austin pour leurs solutions aux problèmes épineux de l’énonciation et de la pragmatique. Je conclurai en essayant de dissiper un des principaux malentendus au sujet d’IEML: ce n’est pas une langue “vraie” (une langue n’est ni vraie ni fausse, elle est conventionnelle), mais une langue claire.
[For an English version of this article see here.]
Jean-HonoréFragonard La liseuse (1770)
L’héritage de Chomsky et les langages réguliers
Commençons par évoquer la dette d’IEML à l’égard de Noam Chomsky, un des géants de la linguistique et des sciences cognitives du XXe siècle. Pour le professeur du MIT, la capacité linguistique est un trait génétiquement déterminé de l’espèce humaine. Les langues, malgré leur diversité et leur évolution continuelle, partagent toutes la même “grammaire universelle” correspondant à cette habileté linguistique innée. Cette théorie expliquerait pourquoi les enfants apprennent spontanément et si vite à parler, sans qu’on ait besoin de leur donner des leçons de grammaire. Chomsky a exposé une version formelle – d’ailleurs contestée et plusieurs fois révisée – de la grammaire universelle. La découverte scientifique la plus précieuse de Chomsky est probablement sa théorie des langages réguliers : il a démontré qu’il existait une correspondance entre l’algèbre et la syntaxe formelle. La langue est donc en principe un objet calculable, au moins sur un plan syntaxique . Pour qu’une langue puisse être manipulée facilement par les ordinateurs, c’est-à-dire calculable, il faut qu’elle soit un langage régulier au sens de Chomsky: une sorte de code mathématique. Or les langues naturelles ne sont évidemment pas des langages réguliers. Les langages réguliers effectivement utilisés aujourd’hui sont des langages de programmation. Mais la “sémantique” des langages de programmation n’est autre que l’exécution des opérations qu’ils commandent. Aucun d’eux n’approche la capacité expressive d’une langue naturelle, qui permet de parler de tout et de rien et d’accomplir bien d’autres actes illocutoires que de donner des instructions à une machine. Notons au passage que Hjelmslev critiquait l’expression de « langue naturelle » à laquelle il préférait celle de langue philologique ou langue passe-partout. En effet, on peut tout dire en Espéranto, par exemple, bien que ce soit une langue construite et non pas naturelle. L’Espéranto est donc une langue philologique. Hélas, la sémantique de l’Espéranto n’est pas plus calculable que celle du Français ou de l’Arabe. A cause de leur irrégularité, les ordinateurs n’ont aujourd’hui accès aux langues philologiques que sur un mode statistique. C’est pourquoi notre âge numérique a besoin d’une langue philologique transparente aux algorithmes et donc régulière. IEML est la solution que j’ai trouvée au problème de la construction d’une langue philologique à la sémantique calculable. La calculabilité de sa sémantique n’est évidemment pertinente que s’il s’agit d’une langue philologique, permettant de « tout dire ». Et puisque la sémantique de cette langue devait être calculable, sa syntaxe devait a fortiori l’être aussi. C’est pourquoi IEML est un langage régulier au sens de Chomsky. Mais si le fait d’être un langage régulier était une condition nécessaire à la calculabilité de sa sémantique, ce n’en était pas une condition suffisante. Souvenons-nous que les langages réguliers actuellement en usage ont une sémantique restreinte : ce ne sont pas des langues philologiques. Comment conférer une sémantique philologique à un langage régulier ? Pour répondre à cette question, je me suis appuyé sur les enseignements de Saussure et de ses successeurs.
L’héritage de Saussure et le structuralisme
Selon Ferdinand de Saussure (1857-1913), un des pères de la linguistique contemporaine, les symboles linguistiques sont constitués de deux parties, le signifiant (une image acoustique ou visuelle) et le signifié (un concept ou une catégorie abstraite). Le rapport entre les deux parties du symbole est conventionnel ou arbitraire. Saussure a également montré que le plan du signifiant, ou la phonologie des langues, était basé sur un système de différences entre les sons, chaque langue ayant sa propre liste de phonèmes et surtout sa propre manière de disposer les seuils de passage entre deux phonèmes dans le continuum sonore. Un phonème n’existe pas de manière isolée, en dehors d’un éventail de variations, un peu comme les notes de musique n’existent que par rapport à un système musical. De la même manière, les signifiés ne sont pas des atomes de sens se suffisant à eux-mêmes mais correspondent à des positions dans des systèmes de différences : les paradigmes. La sémantique linguistique ne s’ancre donc pas dans des réalités naturelles fixes et indépendantes, mais dans un processus de comparaison, d’opposition, de différenciation et de renvois entre signifiés au sein d’une grille systémique bouclée sur elle-même, comme le sens d’un mot dans le dictionnaire est défini par d’autres mots qui, eux-mêmes, etc. Les travaux de Saussure ont été notamment poursuivis par Louis Hjemslev (1899-1965), qui a approfondi l’analyse du signe linguistique et a plaidé pour un maximum de rigueur épistémologique dans le traitement du langage, jusqu’à un idéal quasi-algébrique. Hjemslev a rebaptisé l’opposition entre signifiant et signifié en décrivant deux « plans » linguistiques celui de l’expression (le signifiant) et celui du contenu (le signifié). Chacun des deux plans est à son tour analysé en matière et forme. La matière de l’expression est de l’ordre du phénomène sensible, par exemple visuel ou sonore. Par contraste, la forme de l’expression désigne les unités abstraites qui résultent du découpage structurel des signifiants dans une langue donnée. Par exemple, le phonème « a » représente une forme bien déterminée qui s’oppose dans telle ou telle langue au phonème « o ». C’est ce qui permet en français, par exemple, de distinguer entre « bas » et « beau ». En revanche la forme « a » peut être remplie par un grand nombre de matières sonores distinctes selon les voix, les accents, etc. La matière est de l’ordre du continuum concret alors que la forme est de l’ordre du système d’oppositions abstrait. Il en est de même pour le contenu. Hjemslev a supposé qu’il existait un continuum du signifié, une sorte de magma abritant virtuellement l’ensemble des catégories possibles : la matière du contenu. Cette matière est découpée et organisée en paradigmes de manière différente pour chaque langue. En fin de compte, une langue quelconque organise une correspondance particulière entre forme de l’expression et forme du contenu. Le courant structuraliste initié par Saussure et poursuivi par Hjemslev a été prolongé par Julien Algirdas Greimas (1917-1992) et François Rastier (1945- ). Tout en maintenant vivante la tradition qui conçoit l’existence relativement autonome d’un monde des signifiés, ces auteurs ont notamment étendu l’analyse structurale du niveau des mots et des phrases jusqu’au niveau du texte, en particulier grâce à la notion d’isotopie. Revenons maintenant à notre problème : comment construire une langue qui soit simultanément philologique et régulière ? Non seulement les langues sont conventionnelles, mais elles ne peuvent pas ne pas l’être. La correspondance entre signifiant et signifié, ou expression et contenu, est arbitraire par nature. Puisque les langues sont nécessairement conventionnelles, rien n’interdit d’en construire une dont l’arrangement des signifiants soit de type “langage régulier”. Nous savons qu’un langage régulier possède une syntaxe calculable. Or la syntaxe régit les éléments signifiants de la langue, les phonèmes et leurs enchaînements, à plusieurs niveaux de complexité emboîtés. Puisqu’aussi bien les signifiants que les signifiés doivent être organisés par un système de différences, rien n’interdit non plus de donner – par convention – à ce langage régulier un système de différences des signifiés (une forme du contenu) qui soit une fonction mathématique de celui des signifiants (la forme de l’expression). En accord avec les théories de Saussure et de ses successeurs, les unités de la langue IEML, à commencer par les morphèmes, mais aussi les unités lexicales, les phrases et les super-phrases sont organisées en paradigmes. Ces systèmes de variations sur fond de constantes – ou groupes de transformations – permettent aux unités linguistiques de s’entre-définir et de s’expliquer réciproquement. Or – en IEML – ce sont les mêmes paradigmes qui structurent l’expression et le contenu. Voici donc le principe de résolution de notre problème : dans un langage régulier dont le système de différences des signifiés est une fonction calculable de celui des signifiants, non seulement la syntaxe mais également la sémantique est calculable. C’est précisément le cas d’IEML, qui est donc une langue à la sémantique calculable !
L’héritage de Tesnière et la linguistique cognitive
Parmi toutes les fonctions du langage, l’une des plus importantes est de supporter la construction et la simulation de modèles mentaux [Je m’inspire ici notamment de l’étude de Philip Johnson-Laird, Mental Models, Harvard University Press, 1983]. L’architecture linguistique des modèles mentaux n’est évidemment pas exclusive de modes de représentation sensori-moteurs, et notamment visuels, qui peuvent se rapporter aussi bien à des mondes fictionnels qu’à la réalité vécue. Des linguistes comme Ronald Langacker (1942- ) et George Lakoff (1941- ), qui sont parmi les principaux chefs de file du courant de la linguistique cognitive, ont particulièrement étudié cette fonction de modélisation mentale. La capacité de représenter des « scènes » – à savoir des processus mis en oeuvre par des actants dans certaines circonstances – est une condition sine qua non du travail de modélisation accompli par le langage. Elle fonde la faculté narrative, puisqu’un récit peut être ramené à un enchaînement hypertextuel de scènes, moyennant certaines relations d’anaphore et d’isotopie. J’ajoute qu’en spécifiant les rapports entre processus et/ou entre actants, la scénographie linguistique fonde également la représentation des relations causales. Puisqu’une des missions d’IEML est de servir d’outil formel de modélisation, il doit non seulement organiser un morphisme entre sa sémantique et sa syntaxe, mais également systématiser et faciliter autant que possible la représentation des processus, des actants, des circonstances et de leurs interactions. Pour ce faire, IEML a intégré, avec quelques ajustements, le modèle actantiel de la phrase que Tesnière, préfigurant la linguistique cognitive, avait proposé dès le milieu du XXe siècle.
Figure 1: Exemple d’arbres de dépendance ou « stemmas » de Tesnière CC BY-SA 3.0, Wikimedia Commons.
En effet, outre le courant structuraliste, la grammaire d’IEML a aussi été largement influencée par l’oeuvre majeure de Lucien Tesnière (1893-1954). Ce linguiste français a été le premier à présenter une grammaire universelle fondée sur les arbres de dépendance, qui met en évidence le lien intime entre syntaxe et sémantique (voir la Figure 1). Bien que les deux systèmes aient été élaborés indépendamment, les arbres de dépendance de Tesnière sont proches des arbres syntaxiques de Chomsky. Tesnière a aussi proposé une théorie subtile de la translation entre les « parties du discours » que sont les verbes, noms, adverbes et adjectifs. Il a surtout développé le modèle actantiel de la phrase dont s’inspire la fonction syntagmatique d’IEML. La citation suivante, extraite de son oeuvre posthume Eléments de syntaxe structurale, explique bien le principe du modèle actantiel : « Le noeud verbal (…) exprime tout un petit drame. Comme un drame, en effet, il comporte (…) un procès et, le plus souvent, des acteurs et des circonstances. Le verbe exprime le procès. (…) Les actants sont des êtres ou des choses (…) participant au procès. (…) Les circonstants expriment les circonstances de temps, lieux, manière, etc. » [Lucien Tesnière, Eléments de syntaxe structurale, Klincksieck, Paris 1959: 102, Chapitre 48] Le modèle actantiel de Tesnière a notamment été repris et développé par deux importants linguistes contemporains, Igor Melchuk (1932- ) et Charles Fillmore (1929-2014). La grammaire des cas de Fillmore publiée en 1968, a été étendue dans les années 1980 à une conception quasi-encyclopédique de la sémantique linguistique notamment mise en oeuvre dans le projet FrameNet centré sur la langue anglaise et qui inspire plusieurs programmes d’intelligence artificielle. Les frames ou « cadres » en français décrivent la manière dont les mots conviennent les uns avec les autres et déterminent mutuellement leurs sens dans une phrase. Par exemple, lorsqu’on utilise le verbe « attaquer » à la voix active, le sujet grammatical est forcément un assaillant et l’objet grammatical une victime de l’attaque. L’approche adoptée par IEML est compatible avec les théories de Fillmore, les cas correspondant aux rôles syntagmatiques et l’équivalent des cadres étant les paradigmes de phrases. Quant à Igor Melchuk, sa contribution la plus originale concerne la morphologie, c’est-à-dire la structure des mots et leurs rapports. Il a en particulier décrit les fonctions lexicales qui règlent les collocations – c’est-à-dire les mots qui vont ou ne vont pas ensemble – et les relations sémantiques entre les unités lexicales d’une langue. Un exemple simple de fonction lexicale est « PLUS » comme dans : [PLUS (colline) = montagne] ou [PLUS (ruisseau) = rivière]. Les fonctions lexicales sont notamment utilisées pour construire des dictionnaires explicatifs et combinatoires (monolingues) et elles alimentent, comme les cadres de Fillmore, certains programmes de traitement automatique des langues naturelles. IEML intègre les principales fonctions lexicales mises en évidence par Melchuk, ce qui permet de composer facilement de nouveaux mots à partir des éléments du dictionnaire et d’expliciter formellement les relations sémantiques entre unités lexicales. Quant aux collocations selon Melchuk elles sont proches des cadres de Fillmore et sont – comme eux – traduites en IEML par des paradigmes de phrases. En somme, de nombreux linguistes ont souligné l’importance de la fonction modélisatrice du langage. Suivant leurs traces, IEML offre à ses locuteurs les outils grammaticaux nécessaires pour décrire des scènes et raconter des histoires. De plus, IEML permet de modéliser un domaine de connaissance spécialisé ou un champ sémantique particulier par la libre élaboration de terminologies (paradigmes de radicaux) et de phrases-cadres (paradigmes de phrases).
Austin, Wittgenstein et l’héritage pragmatique
La langue est une structure abstraite qui combine des paradigmes de morphèmes (atomes de sens indécomposables) et des règles de compositions des unités grammaticales (mots, phrases…) à partir des morphèmes. Par contraste, la parole – ou le texte – est une séquence de morphèmes particulière qui actualise le système de la langue. En ce sens, les terminologies et les phrases-cadres d’IEML appartiennent à une catégorie intermédiaire entre la langue et la parole. Ils font partie de la parole dans la mesure où ils sont librement créés à partir du dictionnaire de morphèmes initial et des règles de construction de syntagmes. Mais ils appartiennent encore à la langue puisque ce ne sont pas à proprement parler des énonciations en contexte. Ce n’est qu’au niveau de l’énonciation, en effet, que se déploient les actes de langages, c’est-à-dire la dimension pragmatique des langues. Or il ne s’agit pas de choisir entre la fonction modélisatrice ou représentative des langues, qui vient d’être évoquée à la section précédente, et leur fonction pratique, que nous allons survoler dans cette section. Bien au contraire : la fonction de représentation et la fonction pratique se soutiennent mutuellement. Sans modèle du monde, l’action n’a pas de sens et sans plongement dans quelque situation pratique, la représentation perd toute pertinence. Quoiqu’on puisse faire remonter la réflexion sur la puissance pratique du langage à la rhétorique antique ou aux plus anciennes réflexions de l’école confucéenne, je me limiterai ici à quelques grands auteurs : Emile Benvéniste pour l’étude de l’énonciation et de la fonction déictique, Ludwig Wittgenstein pour la question de la référence et des jeux de langage, John L. Austin pour la notion même de pragmatique linguistique. Relèvent de la pragmatique linguistique les actes accomplis dans le langage mais qui ont des conséquences extra-linguistiques, comme par exemple baptiser, interdire, condamner, etc. Puisqu’ils sont accomplis dans le langage, ces actes sont de nature symbolique. Ils sont par conséquent régis par des règles et accomplis par des « joueurs » qui tiennent des rôles déterminés. Une multitude de jeux de langage, selon l’expression de Wittgenstein, animent donc la dimension pragmatique qui s’ouvre avec l’énonciation. Une langue peut elle-même être assimilée à un système de règles ou à un jeu. Et si cette langue est philologique elle est capable à son tour de définir une multitude de langues restreintes, de systèmes de règles ou de jeux, qui sont autant de manières distinctes de l’utiliser dans la pratique. IEML étant une langue philologique, nous l’utiliserons non seulement pour modéliser un champ sémantique quelconque, représenter des scènes et raconter des histoires, mais aussi pour expliciter des jeux de langages dont nous formaliserons les règles, les rôles et les coups au moyen de terminologies et de phrases-cadres. Lorsqu’ils reconnaîtront les actes de langages accomplis par les locuteurs d’IEML, des algorithmes pourront déclencher automatiquement leurs conséquences extra-linguistiques et notamment calculer les nouveaux états des « parties » en cours. J’évoquerai ici quatre grands types d’actes de langage qui sont particulièrement pertinents pour IEML : la référence, le raisonnement, la communication sociale et les instructions données à des machines. La première fonction de l’énonciation est de faire référence à des objets non-linguistiques. Une de ses formes les plus évidentes est la distribution des rôles interlocutoires : les première, seconde ou troisième personnes indiquent qui parle, à qui et de quoi. Mentionnons également les possessifs (liés à la distribution des personnes grammaticales), les démonstratifs comme « ça, ici, là-bas », les adverbes comme « aujourd’hui », « demain », etc. Or un texte – ou un énoncé – ne permet pas d’interpréter les déictiques comme « je », « ça » ou « demain ». Seul l’événement d’une énonciation par quelqu’un, dans un contexte spatio-temporel d’interlocution défini, peut leur donner un contenu [« « Je » » signifie « la personne qui énonce la présente instance du discours contenant « je ». » (Emile Benveniste)] . Cette fonction référentielle du langage est particulièrement importante pour IEML, qui a pour vocation de catégoriser des données et donc – par nécessité – de les indexer. Aussi bien la distribution des rôles interlocutoires que la catégorisation des données peuvent se conformer à un grand nombre de jeux de référence distincts. Par exemple, pour interpréter un « nous » il faut connaître le système de distribution des personnes auquel il obéit : pluriel de majesté, chercheurs d’une même discipline, membres d’un tribunal, citoyens d’une nation en guerre…? D’autre part, la catégorisation des données en IEML prend un sens différent selon que l’indexation est faite par un algorithme ou par un humain. Dans le cas de l’indexation automatique, s’agit-il d’un algorithme statistique basé sur un corpus indexé manuellement ? Et dans ce dernier cas, indexé par qui, selon quels critères, etc. Dans le même ordre d’idée, il peut être utile de savoir si un texte est cité (encore un geste déictique) en tant que partie d’un corpus de référence, comme une autorité pour renforcer la crédibilité des idées de l’auteur, pour être critiqué, ou encore pour une autre raison. En somme, l’opération de référence est un acte de langage, cet acte relève d’une multitude de jeux possibles, et ces jeux peuvent être explicités en IEML. Le raisonnement est encore un autre type de jeu de langage modélisable en IEML. Citons dès maintenant, en suivant la typologie de Charles S. Peirce, (1) les divers genres de raisonnement déductifs, (2) les raisonnements inductifs – incluant les calculs statistiques – et (3) les raisonnements abductifs, qui construisent des modèles causaux d’un domaine ou d’un processus. On remarquera que le raisonnement suppose la plupart du temps la référence et que cette dernière est souvent faite pour appuyer le raisonnement. Les jeux de langage qui ont le plus été étudiés par les spécialistes de la pragmatique, à commencer par Austin et Searle, sont les jeux de communication sociale, qui comprennent par exemple les assertions, les questions, les ordres, les promesses, les remerciements, les nominations, etc. Mais nous pouvons ajouter à ce type de jeux les transactions, les contrats et tout ce qui relève des arrangements légaux et des échanges économiques, qui passent de plus en plus par des canaux électroniques et qui auraient avantage à être exprimés dans un langage transparent, univoque et calculable comme IEML. Finalement, puisque nous vivons dans un environnement de plus en plus robotisé, les instructions données à des machines, tout comme d’ailleurs les informations – parfois vitales – que les machines nous transmettent, font évidemment partie des actes de langage aux importantes conséquences extra-linguistiques. Parce que les ordinateurs peuvent décoder IEML et qu’IEML se traduit en langues naturelles, notre métalangage pourrait devenir le noyau logiciel d’une interface ubiquitaire et interopérable entre humains et machines.
Une image du monde ou une image de soi ?
Dans le Tractatus Logico Philosophicus, l’ouvrage de jeunesse qui l’a fait connaître, Wittgenstein examine à quelles conditions les propositions logiques présentent une image fidèle de la réalité. Le monde étant conçu par notre philosophe viennois comme « tout ce qui arrive », chaque fait ou événement devrait être représenté par une proposition dont la structure logico-grammaticale reflète la structure interne du fait. L’idée d’un langage parfait ou d’une langue transparente est souvent associée à cet idéal d’isomorphie entre les expressions du langage et les réalités qu’elles décrivent ou, en d’autres termes, entre la parole et sa référence. Rien n’est plus loin du projet d’IEML. Plutôt que de poursuivre la chimère au parfum vaguement totalitaire d’une langue de la vérité (la vérité se ramène à la correspondance entre parole et réalité), j’ai poursuivi un objectif moins contraignant et surtout plus atteignable : celui d’une langue de la clarté, aussi univoque et traductible que possible. A l’idéal d’une langue logique qui reflèterait des états de choses, j’ai substitué celui d’une langue philologique dont la forme algébrique de l’expression reflèterait la forme du contenu conceptuel : une langue qui serait une image d’elle-même avant d’être une image du monde. Par définition, cette correspondance interne ne relève pas du vrai et du faux mais de la convention utile. Quant au rapport d’IEML avec la réalité extralinguistique, elle relève d’une multitude de jeux de langages (je suis ici le Wittgenstein de la maturité, tel qu’il s’est exprimé dans les Philosophical Investigations), multitude qui englobe les diverses manières de découper, reconnaître et désigner des objets pertinents selon les contextes pratiques. Et grâce à la capacité de description universelle propre à toutes les langues philologiques, nous pouvons modéliser ces multiples jeux de langages en IEML. Cette approche respecte aussi bien la liberté que la créativité de ses locuteurs tout en autorisant ces derniers à se coordonner entre eux et avec les machines. Reprenons la classification des différents niveaux de la sémantique – linguistique, référentielle et illocutoire. Notre métalangage clarifie les relations entre signifiés et signifiants ainsi que les relations entre signifiés au point de pouvoir automatiser leur traitement. Le principal apport d’IEML se situe donc au niveau de la sémantique linguistique. Quant à la sémantique référentielle – le pointage vers des réalités extra-linguistiques – elle peut devenir plus précise dans la mesure où les différents modes de référence sont précisés en IEML. Enfin, la force illocutoire des énonciations, c’est-à-dire les « coups » qui sont joués dans une multitude de jeux de communication sociale, peuvent être reconnus par des algorithmes et traités en conséquence, à condition que les jeux en question aient préalablement été décrits en IEML. En somme, la formalisation de la sémantique linguistique nous offre la clé de la formalisation de la sémantique en général.
Brève bibliographie
Austin John L. How to Do Things with Words, Oxford University Press, Oxford, 1962
Benveniste Emile Problèmes de linguistique générale, Tomes 1 et 2, Gallimard, Paris, 1966-1974
Chomsky Noam New Horizons in the Study of Language and Mind, Cambridge University Press, Cambridge, 2000.
Chomsky Noam Syntaxic Structures, Mouton, La Hague et Paris, 1957.
Chomsky Noam ; Schützenberger, Marcel P. « The algebraic theory of context free languages », in Braffort, P. ; Hirschberg, D. : Computer Programming and Formal Languages, North Holland, Amsterdam, 118-161, 1963
Fillmore Charles “The Case for Case” (1968). In Bach and Harms (Ed.): Universals in Linguistic Theory. New York: Holt, Rinehart, and Winston, 1-88. (Tesnières y est cité à neuf reprises).
Fillmore Charles “Frame semantics” (1982). In Linguistics in the Morning Calm. Seoul, Hanshin Publishing Co., 111-137.
Hejlmslev Louis, Prolégomènes à une théorie du langage – La Structure fondamentale du langage, Paris, Éditions de minuit, coll. « Arguments », 2000
Johnson-Laird Philip, Mental Models, Harvard University Press, 1983
Lakoff George Women, Fire and Dangerous Things: What Categories Reveal About the Mind, University of Chicago Press, Chicago, USA, 1987.
Lakoff George, Johnson M., Metaphors We Live By, University of Chicago Press, Chicago, USA, 2003.
Langacker Ronald W., Foundations of Cognitive Grammar (2 volumes), Stanford University Press, Stanford, USA, 1987-1991.
Levy Pierre The Semantic Sphere / La sphère sémantique, Hermès-Lavoisier, Paris-London, 2011
Melchuk, Igor, « Actants in Semantics and Syntax. I. Actants in Semantics », Linguistics, 42: 1, 2004, 1-66
Melchuk Igor Aspects of the Theory of Morphology. Berlin—New York: Mouton de Gruyter, 2006. 615 pp
Peirce, C. S., The Essential Peirce, Selected Philosophical Writings, Volume 1 (1867–1893) and 2 (1893-1913) Nathan Houser and Christian J. W. Kloesel, eds., Indiana University Press, Bloomington and Indianapolis, IN, 1992-1998.
Saussure Ferdinand de Cours de Linguistique générale, Payot, Paris, 1916.
Searle John Speech Acts, Cambridge University Press, London, 1969.
Searle John Intentionality, Cambridge University Press, London, 1983.
Tesnière Lucien Eléments de Syntaxe structurale Klincksieck, Paris, 1959 (posthumous)
Wittgenstein Ludwig Tractatus Logico Philosophicus, Routledge and Kegan Paul Ltd, London, 1961.
Wittgenstein Ludwig Philosophical Investigations, Blackwell, Oxford, 1953.
Today, artificial intelligence is divided between two major trends: symbolic and statistical. The symbolic branch corresponds to what has been successively called in the last 70 years semantic networks, expert systems, semantic web and more recently, knowledge graphs. Symbolic AI codes human knowledge in the form of networks of relationships between concepts ruled by models and ontologies which give leverage to automatic reasoning. The statistical branch of AI trains algorithms to recognize visual, linguistic or other forms from large masses of data, relying on neural models roughly imitating the learning mode of the brain. Neuro-mimetic artificial intelligence has existed since the beginnings of computer science (see the work of McCulloch and von Foerster) but has only become useful because of the increase in computing power available since 2010. In the early 2020s, these two currents are merging according to a hybrid or neuro-symbolic model which seems very promising. Though many problems still remain, in terms of the consistency and interoperability of metadata.
Big tech companies and a growing number of scientific, economic and social sectors use knowledge graphs. Despite the availability of the WWW Consortium metadata standards for marking classifications and ontologies (RDF, OWL) the different sectors (see the slide below) do not communicate with each other and – even worse – divergent systems of categories and relationships are most often in use within the same domain. The interoperability of metadata standards – such as RDF – only addresses the compatibility of digital files. It should not be confused with true semantic interoperability, which addresses concept architectures and models. In reality, the problem of semantic interoperability has yet to be solved in 2021, and there are many causes for the opacity that plagues digital memory. Natural languages are multiple, informal, ambiguous and changing. Cultures and disciplines tend to divide reality in different ways. Finally, often inherited from the age of print, the numerous metadata systems in place to classify data are incompatible like thesauri, documentary languages, ontologies, taxonomies, folksonomies, sets of tags or hashtags, keywords, etc.
The Conundrum of Semantic Interoperability
There is currently no way to code linguistic meaning in a uniform and computable way, the way we code images using pixels or vectors for instance. To represent meaning, we are still using natural languages which are notoriously multiple, changing and ambiguous. With the notable exception of number notation and mathematical codes, our writing systems are primarily designed to represent sounds. Their representation of categories or concepts is indirect (characters → sound → concepts) and difficult for computers to grasp. Computers can handle syntax (the regular arrangement of characters), but their handling of semantics remains imperfect and laborious. Despite the success of machine translation (Deep L, Google translate) and automatic text generation (GPT3), computers don’t really understand the meaning of the texts they read or write.
Now, how can we resolve the problem of semantic interoperability and progress towards a thorough automatic processing of meaning? Many advances in computer science come from the invention of a relevant coding system making the coded object (number, image, sound, etc.) easily computable. The goal of our company INTLEKT Metadata Inc. has been to make concepts, categories or linguistic meaning systematically computable. In order to solve this problem, we have designed the Information Economy MetaLanguage: IEML. This metalanguage has a compact dictionary of less than 5000 words. IEML words are organized by subject-oriented paradigms and visualized as keyboards. The grammar of this metalanguage is completely regular and embedded in the IEML editor. Thank to this grammar, complex concepts and relations can be recursively constructed by combining simpler ones. It is not a super-ontology (like Cyc) but a programmable language (akin to a computable Esperanto) able to translate any ontology and to connect any possible categories. By using such a semantic code, artificial intelligence could take a giant step forward feeding collective intelligence. Public health data from all countries would not only be able to communicate with each other, but could also harmonize with economic and social data. Occupational classifications and different international labour market statistics would automatically translate into each other. The AI of smart contracts, international e-commerce and the Internet of Things would exchange data and execute instructions based on automatic reasoning. Government statistics, national libraries, major museums and digital humanities research would feed into each other. On the machine learning side, we would reach a system of uniform and precise labels and annotations that would help AI to become more ethical, transparent, and efficient. A common semantic code would make it finally possible to achieve a de-fragmentation of the global memory and an integration of symbolic and statistical AI. The only price to pay for reaching neuro-symbolic collective intelligence would be a concerted effort for training specialists to translate metadata into IEML.
Once you are on the site, on the top right you can choose between french and english
“USL” (Uniform Semantic Locator) allows the search for words and paradigms in the dictionary
“Tags” gives you some examples of USLs groups by domain
If you are in “USL” the search for IEML expressions (instead of natural language translations) is done by typing * at the beginning of the query
Type: choose “all”
Class: filters nouns verbs or auxiliaries
Cardinality: choose “root” paradigms (big tables, or multi-tables paradigms), or the (small) tables, or singular = individual words. It is recommended to explore the dictionary by “roots”
When you click on a search result, the corresponding paradigm appears on the right.
The right panel present certain relations according to the selected words.