Aujourd’hui, le monde entier se précipite vers l’IA statistique, les modèles neuronaux et/ou l’IA générative. Mais nous savons que, bien que ces modèles soient utiles, nous avons toujours besoin de modèles symboliques ou, si vous préférez, de graphes de connaissances, en particulier dans le domaine de la gestion des connaissances.
Mais pourquoi exactement avons-nous encore besoin de modèles symboliques en plus des modèles neuronaux ? Parce que les modèles symboliques sont capables de représenter la connaissance de manière explicite, ce qui comporte beaucoup d’avantages. Dans cet exposé, je vais plaider en faveur de l’interopérabilité sémantique (ou conceptuelle) entre les graphes de connaissances, et je présenterai IEML, un langage que j’ai inventé à la Chaire de recherche du Canada en intelligence collective avec l’aide de mon équipe d’ingénieurs.
Figure 1
Si vous êtes familier avec le domaine de la gestion des connaissances, vous savez qu’il existe une dialectique entre les connaissances implicites (en bleu sur la Figure 1) et les connaissances explicites (en rouge sur la Figure 1).
Il existe actuellement deux façons principales de traiter les données pour la gestion des connaissances.
Via des modèles neuronaux, basés principalement sur les statistiques, pour l’aide à la décision, la compréhension automatique et la génération de données.
Via des modèles symboliques, basés sur la logique et la sémantique, pour l’aide à la décision et la recherche avancée.
Ces deux approches sont généralement distinctes et correspondent à deux cultures d’ingénieurs différentes. En raison de leurs avantages et de leurs inconvénients, les gens essaient de les combiner.
Clarifions maintenant la différence entre les modèles ” neuronaux ” et ” symboliques ” et comparons-les à la cognition neuronale et symbolique chez les êtres humains.
Le grand avantage des modèles neuronaux est leur capacité à synthétiser et à mobiliser la mémoire numérique “juste à temps”, ou “à la demande”, et à le faire automatiquement, ce qui est impossible pour un cerveau humain. Mais leur processus de reconnaissance et de génération de données est statistique, ce qui signifie qu’ils ne peuvent pas organiser un monde, ils ne maîtrisent pas la conservation des objets, ils n’ont pas de compréhension du temps et de la causalité, ou de l’espace et de la géométrie. Ils ne peuvent pas toujours reconnaître les transformations d’images d’un même objet comme le font les êtres vivants.
En revanche, les neurones vivants peuvent faire des choses que les neurones formels actuels ne peuvent pas faire. Les animaux, même sans modèles symboliques, avec leurs neurones naturels, sont capables de modéliser le monde, d’utiliser des concepts, ils conservent les objets malgré leurs transformations, ils appréhendent le temps, la causalité, l’espace, etc. Et les cerveaux humains ont la capacité de faire fonctionner des systèmes symboliques, comme le langage.
Quels sont les aspects positifs des modèles symboliques de l’IA, ou graphes de connaissances?
Il s’agit de modèles explicites du monde, plus précisément d’un monde pratique local.
Ils sont en principe auto-explicatifs, si le modèle n’est pas trop complexe.
ils ont de fortes capacités de raisonnement.
Tout cela les rend plutôt fiables, comparativement aux modèles neuronaux, qui sont probabilistes. Cependant, les modèles symboliques actuels présentent deux faiblesses.
Leur conception prend du temps. Ils sont coûteux en termes de main-d’œuvre spécialisée.
Ils n’ont ni “conservation des concepts” ni “conservation des relations” entre les ontologies ou domaines. Dans un domaine particulier donné, chaque concept et chaque relation doivent être définis logiquement un par un.
S’il existe une interopérabilité au niveau des formats de fichiers pour les métadonnées sémantiques (ou les systèmes de classification), cette interopérabilité n’existe pas au niveau sémantique des concepts, ce qui cloisonne les graphes de connaissances, et par conséquent l’intelligence collective.
En revanche, dans la vie réelle, des humains issus de métiers ou de domaines de connaissances différents se comprennent en partageant la même langue naturelle. En effet, dans la cognition humaine, un concept est déterminé par un réseau de relations inhérent aux langues naturelles.
Mais qu’est-ce que j’entends par “le sens d’un concept est déterminé par un réseau de relations inhérent aux langues naturelles” ? Quel est ce réseau de relations ? Et pourquoi est-ce que je le souligne dans cet article ? Parce que je crois que l’IA symbolique actuelle passe à côté de l’aspect sémantique des langues. Faisons donc un peu de linguistique pour mieux comprendre.
Figure 2
Toute langue naturelle tisse trois types de relations : l’interdéfinition, la composition et la substitution.
Tout d’abord, le sens de chaque mot est défini par une phrase qui implique d’autres mots, eux-mêmes définis de la même manière. Un dictionnaire englobe notamment une inter-définition circulaire ou enchevêtrée de concepts.
Ensuite, grâce aux règles de grammaire, on peut composer des phrases originales et comprendre de nouveaux sens.
Enfin, tous les mots d’une phrase ne peuvent pas être remplacés par n’importe quel autre ; il existe des règles pour les substitutions possibles qui contribuent au sens des mots et des phrases.
Vous comprenez la phrase “Je peins la petite pièce en bleu” (voir Figure 2) parce que vous connaissez les définitions de chaque mot, vous connaissez les règles grammaticales qui donnent à chaque mot son rôle dans la phrase, et vous savez par quoi les mots actuels pourraient être remplacés. C’est ce qu’on appelle la sémantique linguistique.
Il n’est pas nécessaire de définir une à une ces relations d’inter-définition, de composition et de substitution entre concepts chaque fois que l’on parle de quelque chose. Tout cela est inclus dans la langue. Malheureusement, nous ne disposons d’aucune de ces fonctions sémantiques lorsque nous construisons les graphes de connaissances actuels. Et c’est là qu’IEML pourrait contribuer à améliorer les méthodes de l’IA symbolique et de la gestion des connaissances.
Pour comprendre mon argumentation, il est important de faire la distinction entre la sémantique linguistique et la sémantique référentielle. La sémantique linguistique concerne les relations entre les concepts. La sémantique référentielle concerne les relations entre les propositions et les états de choses ou entre les noms propres et les individus.
Si la sémantique linguistique tisse des relations entre les concepts, pourquoi ne pouvons-nous pas utiliser les langues naturelles dans les modèles symboliques ? Nous connaissons tous la réponse. Les langues naturelles sont ambiguës (grammaticalement et lexicalement) et les machines ne peuvent pas désambiguïser le sens en fonction du contexte. Dans l’IA symbolique actuelle, nous ne pouvons pas compter sur le langage naturel pour susciter organiquement des relations sémantiques.
Alors, comment construit-on un modèle symbolique aujourd’hui ?
Pour définir les concepts, nous devons les relier à des URI (Uniform Resource Identifier) ou à des pages web, selon le modèle de la sémantique référentielle.
Mais comme la sémantique référentielle est insuffisante pour décrire un réseau de relations, au lieu de s’appuyer sur la sémantique linguistique, il faut imposer des relations sémantiques aux concepts un par un.
C’est la raison pour laquelle la conception des graphes de connaissances prend tant de temps et c’est aussi pourquoi il n’existe pas d’interopérabilité sémantique générale des graphes de connaissances entre les ontologies ou les domaines de connaissance. Encore une fois, je parle ici d’interopérabilité au niveau sémantique ou conceptuel et non au niveau du format.
Afin de pallier les insuffisances des modèles symboliques actuels, j’ai construit un métalangage qui présente les mêmes avantages que les langues naturelles, à savoir un mécanisme inhérent de construction de réseaux sémantiques, mais qui n’a pas leurs inconvénients, puisqu’il est sans ambiguïté et calculable.
IEML (le méta-langage de l’économie de l’information), est un métalangage sémantique non ambigu et calculable qui inclut un système d’inter-définition, de composition et de substitution de concepts.
L’objectif de cette invention est de faciliter la conception de graphes de connaissances et d’ontologies, d’assurer leur interopérabilité sémantique et de favoriser leur conception collaborative. La vision qui inspire IEML est une intelligence collective à support numérique et augmentée par l’IA.
IEML a le pouvoir d’expression d’un langage naturel et possède une structure algébrique qui lui permet d’être entièrement calculable. IEML n’est pas seulement calculable dans sa dimension syntaxique, mais aussi dans sa dimension sémantique linguistique, car ses relations sémantiques (en particulier les relations de composition et de substitution) sont des fonctions calculables de ses relations syntaxiques. Il n’existe aujourd’hui aucun autre système symbolique ayant ces propriétés.
IEML dispose d’une grammaire entièrement régulière et récursive ainsi que d’un dictionnaire de trois mille mots organisés en paradigmes (systèmes de substitution) permettant la construction (récursive et grammaticale) de n’importe quel concept. En somme, tout concept peut être construit à partir d’un petit nombre de briques lexicales selon des règles de composition universelles simples.
Comme chaque concept est automatiquement défini par des relations de composition et de substitution avec d’autres concepts et par des explications impliquant les concepts de base du dictionnaire et conformes à la grammaire IEML, IEML est son propre métalangage. Il peut traduire n’importe quelle langue naturelle. Le dictionnaire en IEML est actuellement traduit en français et en anglais.
IEML permet de coupler les modèles symboliques et neuronaux, et de surmonter leurs limitations et séparations dans une architecture innovante et intégrée.
Figure 3
La diapositive ci-dessus (Figure 3) présente la nouvelle architecture sémantique pour la gestion des connaissances qu’IEML rend possible, une architecture qui conjoint les modèles neuronaux et symboliques.
La seule chose qui puisse générer tous les concepts dont nous avons besoin pour exprimer la complexité des domaines de connaissance, tout en maintenant la compréhension mutuelle, est une langue. Mais les langues naturelles sont irrégulières et ambiguës, et leur sémantique ne peut être calculée. IEML étant un langage algébrique univoque et formel (contrairement aux langues naturelles), il peut exprimer tous les concepts possibles (comme dans les langues naturelles), et ses relations sémantiques sont densément tissées grâce à un mécanisme intégré. C’est pourquoi nous pouvons utiliser IEML comme un langage de métadonnées sémantiques pratique pour exprimer n’importe quel modèle symbolique ET nous pouvons le faire de manière interopérable. Encore une fois, je parle d’interopérabilité conceptuelle. En IEML, tous les modèles symboliques peuvent échanger des modules de connaissance et le raisonnement transversal aux ontologies devient la norme.
Comment les modèles neuronaux sont-ils utilisés dans cette nouvelle architecture ? Les modèles neuronaux traduisent automatiquement le langage naturel en IEML, donc pas de travail ou d’apprentissage supplémentaire pour le profane. Ils pourraient même aider à traduire des descriptions informelles en langage naturel en un modèle formel exprimé en IEML.
Les consignes (prompts) seraient exprimées en IEML en coulisse, de sorte que la génération de données soit mieux contrôlée.
Nous pourrions également utiliser des modèles neuronaux pour classer ou étiqueter automatiquement des données en IEML. Les étiquettes exprimées en IEML permettront un apprentissage automatique plus efficace, car les unités ou “tokens” pris en compte ne seraient plus des unités sonores – caractères, syllabes, mots – des langues naturelles, mais des concepts générés par une algèbre sémantique.
Quels seraient les avantages d’une architecture intégrée de gestion des connaissances utilisant IEML comme système de coordonnées sémantiques ?
Les modèles symboliques et neuronaux fonctionneraient ensemble au profit de la gestion des connaissances.
Un système de coordonnées sémantiques commun faciliterait la mutualisation des modèles et des données. Les modèles symboliques seraient interopérables et plus faciles à concevoir et à formaliser. Leur conception serait collaborative, y compris d’un domaine à l’autre. L’usage d’un métalangage sémantique comme IEML amélioreraient également la productivité intellectuelle grâce à une automatisation partielle de la conceptualisation.
Les modèles neuronaux seraient basés sur des étiquettes codées en IEML et donc plus transparents, explicables et fiables. L’avantage serait non seulement technique, mais aussi d’ordre éthique.
Enfin, cette architecture favoriserait la diversité et la liberté de création, puisque les réseaux de concepts, ou graphes de connaissances, formulés en IEML peuvent être différenciés et complexifiés à volonté.
Je viens de terminer la lecture de l’Introduction à la philosophie de l’histoire, de Raymond Aron. Il s’agit de sa “thèse principale” soutenue en 1938 (10 jours après l’Anschluss). Le propos est dense, truffé de références à la philosophie et à la sociologie allemande de la fin du XIXe et du début du XXe siècle. Le livre est organisé en questions auxquelles répondent des thèses opposées dont l’auteur examine systématiquement les arguments avant de trancher à sa manière. Au centre de l’ouvrage: les rapports entre pratique historienne et philosophie pour des savants plongés dans des situations concrètes et qui entretiennent nécessairement des vues politiques, morales et métaphysiques particulières. Sont notamment abordées les notions de temps, de compréhension, de causalité et de scientificité de la discipline historique. L’ouvrage se clôt en interrogeant la validité de quelques grandes philosophies de l’histoire (spécialement l’idée de progrès et le marxisme) et le sens des concepts de liberté et d’engagement pour une humanité inéluctablement vouée à l’histoire. Les quelques mentions du racisme comme philosophie de l’histoire – que Raymond Aron n’endosse nullement – nous rappellent l’ambiance de l’époque où il écrivait. Le sous-titre de l’ouvrage “Essai sur les limites de l’objectivité historique” suggère le principal résultat atteint par Aron : il s’agit d’une leçon d’humilité intellectuelle et de scepticisme critique qui rappelle que le choix des sujets, les découpages conceptuels et les structures narratives de l’historien sont contingents. Malgré la mise en évidence des limites de la connaissance historique, notre auteur fait droit à la recherche de la vérité dans le respect des faits et de la cohérence logique ; il ne verse jamais dans le relativisme ou le nihilisme.
Malgré la difficulté de lecture due au caractère compact de l’argumentation, le lecteur contemporain est frappé par l’absence de jargon. On est encore à l’époque de Bergson et d’Alain. Aron ne prétend pas créer de “nouveaux concepts” en forme de mots d’ordre, ni à “révolutionner” quoi que ce soit ou à proclamer “la fin” de ceci ou de cela. Il étudie minutieusement une multitude de théories dont aucune n’est bonne ou vraie absolument, mais dont chacune exprime une face de la réalité. Plusieurs approches apparemment contradictoires peuvent être valides en même temps, pourvu qu’on les aborde de manière dialectique, en ayant bien conscience que les points de vue surplombants et les totalisations résultent de choix qui ne seront jamais garantis par un savoir absolu, inaccessible à l’humain. Dogmatisme et fanatisme sont fermement condamnés ; positivisme scientiste et relativisme irresponsable sont renvoyés dos à dos. Aron défend un humanisme rationnel et un libéralisme modéré non exempts de tragique. Libres malgré les multiples conditionnements et déterminations qui nous définissent, il nous revient de choisir notre engagement dans l’histoire. Un ouvrage à méditer face à la montée des tensions et à l’inflammation des esprits dont nous sommes témoins aujourd’hui.
Bien que les deux camarades de classe à Normale Sup soient politiquement et philosophiquement opposés, Sartre et Aron ont été tous deux fascinés par les thèmes de la liberté et de l’engagement politique. Cohérent avec ses idées, l’auteur de l’Introduction à la philosophie de l’histoire et de L’Opium des Intellectuels s’engagea dans la France Libre pendant la Seconde Guerre mondiale et s’opposa au totalitarisme soviétique à l’époque de la Guerre Froide, à contre-courant de la majeure partie de l’intelligentsia française de l’époque.
Parmi les précurseurs de l’intelligence artificielle, il y a incontestablement Pierre Lévy. Le philosophe a pensé dès 1987 la révolution à venir dans son essai « la Machine univers » et travaille désormais à un métalangage qui permettrait aux humains de se servir de l’IA, et non l’inverse.
Au risque d’user un peu plus la célèbre formule de Jacques Derrida employée jadis au sujet du communisme, un spectre hante non pas l’Europe mais le monde intellectuel. Depuis quelques mois, tel un monolithe noir apparu soudainement aux quatre coins de l’univers, deux voyelles sont sur toutes les lèvres et dans toutes les consciences. Ce I et ce A ne cessent en effet de se manifester avec, pour dernière occurrence, l’annonce que la plateforme Amazon limite désormais à trois par jour la publication de livres produits au moyen d’intelligences artificielles sur son outil Kindle Direct Publishing. Afin, nous fait-elle savoir, de ne pas être totalement submergée par la production de livres sans auteur, générés automatiquement, donc.
On ne reviendra pas sur le fait qu’il ne s’agit ni d’intelligence ni même d’artifice, nous préférons saluer ici une œuvre totalement humaine, ancienne et malheureusement en grande partie oubliée bien qu’elle constitue aujourd’hui un outil indispensable pour comprendre le monde dans lequel nous venons d’entrer. En 1987, un chercheur en sciences de l’information et de la communication nommé Pierre Lévy publiait un essai de philosophie au titre prémonitoire « la Machine univers »(La Découverte), allusion à l’ordinateur alors en train de s’installer dans les foyers des Français et à un vieux rêve de l’humanité : calculer la totalité du monde.
Pierre Lévy en 2023
Lire cet ouvrage aujourd’hui provoque un électrochoc car tout y est : la prise de pouvoir actuelle du calcul sur le langage au cours de laquelle « le réel est ici pratiquement appréhendé comme un modèle parmi une prolifération de modèles possibles », « la mathématisation des phénomènes » entraînant la création de « micromondes numériques » et de « systèmes experts », totem actuel des promoteurs de l’IA, prémices d’un « univers omnicalculant » capable de « goûter les capacités sensibles de l’homme ». Il y est question de Wittgenstein, d’Aristote et de Turing et cela reste parfaitement compréhensible pour les personnes qui, comme moi, ont mis un certain temps à comprendre le principe du copier-coller.
On peut également y lire des phrases sublimes comme « l’éternité d’un singe dactylographe produira peut-être les œuvres complètes de Shakespeare » ou « il reste que le virtuel disloque partout la banquise des possibles ». Bien sûr, on sent l’auteur fasciné par le phénomène à venir : la naissance d’un « logos anonyme, une même et intarissable voix derrière les masques de l’histoire, un souffle au gré de qui se lèvent ou vont mourir des armées de mots, d’hommes et de dieux », vent sombre qui, maintenant qu’il nous frôle, plonge une partie des lecteurs dont je suis dans la peur ou l’expectative.
Trois décennies plus tard, il reste à savoir à quoi cet auteur, ancien élève de Michel Serres et de Cornelius Castoriadis, occupe désormais ses journées. Ayant pris le sujet de l’intelligence artificielle à bras-le-corps, il construit depuis 2006 un métalangage baptisé IEML, pour Information Economy Meta Language, afin que l’intelligence collective humaine, c’est-à-dire vous et moi, puisse se nourrir de la puissance de calcul des IA et non l’inverse. Eu égard à notre capacité réduite de compréhension de certains enjeux tels que la création d’un « protocole sémantique », nous préférons lui laisser la parole dans cette vidéo à partir de 20 minutes.
Et nous accrocher à ces mots de Pierre Lévy, écrits en 1990 : alors que « l’utopie technicienne rêve d’un monde synchrone, sans délais, sans frictions ni perte » mû par le calcul, nous préférons jurer fidélité à la langue « toile infiniment compliquée où se propagent, se divisent et se perdent les fulgurations lumineuses du sens ».
Première réflexion au sujet d’un IEML_GPT à venir.
Rappel : ” Je travaille dans une perspective d’intelligence artificielle dédiée à l’augmentation de l’intelligence collective. J’ai conçu IEML pour servir de protocole sémantique, permettant la communication des significations et des connaissances dans la mémoire numérique, tout en optimisant l’apprentissage automatique et le raisonnement automatique.”
Imaginons un dispositif destiné au partage des connaissances et qui tire le maximum des possibilités techniques contemporaines. Au cœur de ce dispositif évolue un écosystème ouvert de bases de connaissances catégorisées en IEML, qui émergent d’une multitude de communautés de recherche et de pratique. Entre ce noyau de bases de connaissances interopérables et les utilisateurs humains vivants s’interpose une interface neuronale (un écosystème de modèles) « no code » qui donne accès au contrôle, à l’alimentation, à l’exploration et à l’analyse des données. Tout se passe de manière intuitive et directe, selon les modalités sensorimotrices sélectionnées. C’est aussi par l’intermédiaire de ce giga-perceptron – un métavers immersif, social et génératif – que les collectifs échangent et discutent les modèles de données et réseaux sémantiques qui organisent leurs mémoires. En bonne gestion des connaissances, le nouveau dispositif de partage des savoirs favorise l’enregistrement des créations, accompagne les parcours d’apprentissage et présente les informations utiles aux acteurs engagés dans leurs pratiques. Le modèle IEML_GPT évoqué ici se veut un premier pas dans cette direction.
Maintenant que l’IA a été déchaînée sur Internet et qu’elle se couple aux médias sociaux, il nous faut apprivoiser et harnacher le monstre. Comment rendre l’IA raisonnable? Comment faire en sorte qu’elle « comprenne » ce qu’on lui dit et ce qu’elle nous dit, plutôt que de seulement calculer les probabilités d’apparition des mots à partir des données d’entraînement? Il faudrait lui apprendre le sens des mots et des phrases de telle sorte qu’elle (l’IA) se fasse une représentation abstraite *compréhensible pour elle* non seulement du monde physique (je laisse la tâche à Yann LeCun), mais aussi une représentation du monde humain et, plus généralement, du monde des idées.
En d’autres termes, comment greffer des capacités de codage et décodage symbolique sur un modèle neuronal qui ne peut au départ que reconnaître et générer des formes sensibles ou des agrégats de signifiants? Ce défi rappelle le processus de l’hominisation – quand des réseaux de neurones biologiques sont devenus capables de manipuler des systèmes symboliques – ce qui n’est pas pour me déplaire.
COMPRÉHENSION / CONNAISSANCE / INTEROPÉRABILITÉ
Comprendre une phrase, c’est l’inclure dans la dynamique auto-définitionnelle d’une langue, et cela avant même de saisir la référence extralinguistique de la phrase. L’IA comprendra ce qu’on lui dit lorsqu’elle sera capable de transformer automatiquement une chaîne de caractères en un réseau sémantique qui plonge dans la boucle auto-référentielle et auto-définitoire d’une langue. Le dictionnaire d’une langue, avec ses définitions, est un élément crucial de cette boucle. De même qu’une déduction représente en fin de compte une tautologie logique, le dictionnaire d’une langue exhibe une *tautologie sémantique*. C’est pourquoi IEML_GPT doit contenir un fichier avec le dictionnaire IEML-français-anglais (et peut-être d’autres langues) avec l’ensemble des relations entre les mots sous forme de phrases IEML. Le dictionnaire est une méta-ontologie qui est la même pour tous les utilisateurs. D’autres fichiers pourront contenir des modèles locaux ou ontologies correspondant aux écosystèmes de pratiques des communautés d’utilisateurs. 1) Compréhension linguistique. Les agents raisonnables sont capables de reconnaître et de générer des séquences de caractères IEML syntaxiquement valides, notamment au moyen d’un parseur. Ils ont une compréhension d’IEML : ils reconstituent les arbres syntagmatiques récursivement enchâssés et les relations entre concepts qui découlent du dictionnaire et des matrices paradigmatiques (ou groupes de substitution) qui organisent les concepts. Chaque concept (représenté par un mot ou une phrase IEML) se trouve ainsi au centre d’une étoile de relations syntaxiques et sémantiques. 2) Connaissance des domaines pratiques. Les agents raisonnables sont animés par des bases de connaissances qui leur permettent de comprendre (localement) le monde où ils sont amenés à intervenir. Ils disposent de modèles (ontologies ou graphes de connaissances en IEML) des situations pratiques auxquelles leurs utilisateurs sont confrontés. Ils sont capables de raisonner à partir de ces modèles. Ils sont capables de rapporter les données qu’ils acquièrent et les questions qu’on leur pose à ces modèles. 3) Interopérabilité sémantique. Les agents raisonnables partagent la même langue (IEML) et donc se comprennent entre eux. Ils peuvent s’échanger des modèles ou des sous-modèles. Ils transforment les expressions en langues naturelles en IEML et les expressions IEML en langues naturelles : ils peuvent donc comprendre les humains et se faire comprendre d’eux.
TÂCHE 1 : LE DICTIONNAIRE
1.0 Je dispose déjà d’environ trois mille mots du dictionnaire organisés en paradigmes, d’une grammaire formelle, d’un parseur pour valider les phrases et de fonctions pour générer des paradigmes.
1.1 La première étape consiste à créer des concepts-phrases pour exprimer les *ensembles de mots* (familles lexicales et champs sémantiques) que sont les paradigmes, leurs colonnes, leurs rangées, etc. Appelons les concepts définissant ces ensembles de mots des « concepts lexicaux ». Les mots d’une même famille lexicale ont des traits syntaxiques communs et appartiennent souvent aux mêmes paradigmes-racines. Ils devront être créés systématiquement au moyen de paradigmes.
Il me faut trouver les moyens de générer les paradigmes de concepts lexicaux automatiquement en langue naturelle avec IEML_GPT plutôt qu’au moyen de l’éditeur actuel qui n’est pas facile à utiliser.
1.2 La seconde étape consiste à créer toutes les « propositions analytiques » qui définissent les mots du dictionnaire et explicitent leurs relations au moyen de mots et de concepts lexicaux. Par exemple : « Une montagne est plus grande qu’une colline » ; « La sociologie appartient aux sciences humaines ». Les propositions analytiques de ce type sont toujours vraies et définissent une méta-ontologie. Il faudra donc créer les paradigmes des *relations du dictionnaire*. Et les faire générer par IEML_GPT à partir d’instructions en langues naturelles.
1.3 Toutes les relations internes au dictionnaire, matérialisées par des liens hypertextes, sont créés par des phrases. Sur le plan de l’interface utilisateur, cela revient à créer des liens hypertexte internes au dictionnaire (entre les mots et les concepts lexicaux) de telle sorte que leurs relations grammaticales soient les plus claires possibles. Le document dictionnaire-hypertexte doit également être généré automatiquement par IEML_GPT.
Pour chaque mot, on obtiendra une liste (une « page? ») de phrases justes contenant le mot. Cette liste sera organisée par rôle grammatical : mot défini en rôle de racine, mot défini en rôle d’objet, etc.
Ces phrases serviront non seulement à définir les mots, mais aussi à commencer à accumuler des exemples, voire des données d’entraînement, avec la correspondance entre phrases IEML formelles et traductions littéraires en français et en anglais. En somme, le premier produit fini sera un dictionnaire complet, avec mots, concepts lexicaux et relations d’inter-définition sous forme hypertextuelle, le tout en IEML, anglais et français.
TÂCHE 2 : L’ÉDITEUR D’ONTOLOGIES
La tâche 1 aura permis de tester les meilleurs moyens de créer des paradigmes au moyen de consignes en langues naturelles, voire au moyen de formulaires permettant de mâcher le travail des concepteurs d’ontologies.
L’output de l’éditeur d’ontologie pourra être en RDF, JSON-LD, ou sous forme d’un document hypertexte. On peut aussi imaginer un document multimédia interactif : tables, arbres, réseaux de concepts explorables, illustrations verbales/sonores…
Idéalement, l’ontologie créée devrait contenir nativement un moteur d’inférence et donc supporter le raisonnement automatique. La propriété intellectuelle des créateurs d’ontologies devra être reconnue.
IEML_GPT sera capable de faire fonctionner n’importe quelle ontologie ou ensemble d’ontologies IEML.
TÂCHE 3 LA CATÉGORISATION AUTOMATIQUE
L’étape suivante devra viser la construction d’un outil intégré de catégorisation automatique de données en IEML. On donne à l’IA un jeu de données et une ontologie IEML (idéalement sous forme de fichier de référence) et le résultat est un ensemble de données catégorisées selon les termes de l’ontologie. L’exécution de la tâche 3 ouvre la voie à la création d’un écosystème de bases de connaissances tel que décrit dans la vision plus haut et la figure ci-dessous.
Toutes ces étapes devront être d’abord réalisées « en petit » (preuves de concepts et méthode agile) avant de l’être intégralement.
Cette entrée de blog propose le texte de ma conférence d’ouverture du Forum “Montréal Connecte” d’octobre 2023 consacré à l’intelligence collective à support numérique. Pour ceux qui préfèrent la vidéo, elle est là (ça commence à la vingtième minute) : https://www.youtube.com/watch?v=dTMU-j8nYio&t=7s
INTRODUCTION
Il y a maintenant presque 30 ans j’ai publié un livre consacré à l’intelligence collective à support numérique qui était, modestie à part, le premier à traiter ce sujet. Dans cet ouvrage, je prévoyais que l’Internet allait devenir le principal medium de communication, que cela provoquerait un changement de civilisation, et je disais que le meilleur usage que nous pouvions faire des technologies numériques était d’augmenter l’intelligence collective (et j’ajoute : une intelligence collective émergente, de type “bottom up”).
Le public de ma conférence d’ouverture à “Montreal Connecte” le 10 octobre 2023
A cette époque moins de 1% de l’humanité était branchée sur l’Internet alors que nous avons aujourd’hui – en 2023 – dépassé les deux tiers de la population mondiale connectée. Le changement de civilisation semble assez évident, bien qu’il faille attendre normalement plusieurs générations pour confirmer ce type de mutation, sans oublier que nous ne sommes qu’au commencement de la révolution numérique. Quant à l’augmentation de l’intelligence collective, de nombreux pas ont été franchis pour mettre les connaissances à la portée de tous (Wikipédia, le logiciel libre, les bibliothèques et les musées numérisés, les articles scientifiques en accès libre, certains aspects des médias sociaux, etc.). Mais beaucoup reste à faire. Utiliser l’intelligence artificielle pour augmenter l’intelligence collective semble une voie prometteuse, mais comment avancer dans cette direction ? Pour répondre à cette question de manière rigoureuse, je vais devoir définir préalablement quelques concepts.
QU’EST-CE QUE L’INTELLIGENCE?
Avant même de traiter la relation entre l’intelligence collective humaine et l’intelligence artificielle, essayons de définir en quelques mots l’intelligence en général et l’intelligence humaine en particulier. On dit souvent que l’intelligence est la capacité de résoudre des problèmes. A quoi je réponds: oui, mais c’est aussi et surtout la capacité de concevoir ou de construire des problèmes. Or si l’on a un problème c’est que l’on essaye d’obtenir un certain résultat et que l’on est confronté à une difficulté ou à un obstacle. Autrement dit, il y a un soi, un même, qu’on appellera l’« Un », qui est pourvu d’une logique interne, qui doit se maintenir dans certaines limites homéostatiques, qui a des finalités immanentes comme la reproduction, l’alimentation ou le développement et il y a un « Autre », une extériorité, qui obéit à une logique différente, qui se confond avec l’environnement ou qui appartient à l’environnement de l’Un et avec qui l’Un doit transiger. L’entité intelligente doit avoir une certaine autonomie, sinon elle ne serait pas intelligente du tout, mais cette autonomie n’est pas une autarcie ou une indépendance absolue car, dans ce cas, elle n’aurait aucun problème à résoudre et n’aurait pas besoin d’être intelligente.
Figure 1
Le rapport entre l’Un et l’Autre peut se ramener à une communication ou une interaction entre des entités qui sont régies par des manières d’être, des codes, des finalités hétérogènes et qui imposent donc un processus incertain et perfectible de codage et de décodage, processus qui engendre forcément des pertes, des créations et qui est soumis à toutes sortes de bruits et de parasitages.
L’entité intelligente n’est pas forcément un individu, ce peut être une société ou un écosystème. D’ailleurs, à l’analyse, on trouvera souvent à sa place un écosystème de molécules, de cellules, de neurones, de modules cognitifs, et ainsi de suite. Quant au rapport entre l’Un et l’Autre, il constitue la maille élémentaire d’un réseau écosystémique quelconque. L’intelligence est le fait d’un écosystème en relation avec d’autres écosystèmes, elle est collective par nature. En somme le problème revient à optimiser la communication avec un Autre hétérogène en fonction des finalités de l’Un et la solution n’est autre que l’histoire effective de leurs relations.
LES COUCHES DE COMPLEXITÉ DE L’INTELLIGENCE
Nous nous interrogeons principalement sur l’intelligence humaine augmentée par le numérique. N’oublions pas, cependant que notre intelligence repose sur des couches de complexité bien antérieures à l’apparition de l’espèce Homo sur la Terre. Les couches de complexité organique et animale sont toujours actives et indispensables à notre propre intelligence puisque nous sommes des êtres vivants pourvus d’un organisme et des animaux pourvus d’un système nerveux. C’est d’ailleurs pourquoi l’intelligence humaine est toujours incarnée et située.
Figure 2
Avec les organismes, viennent les propriétés bien connues d’autoreproduction, d’auto-référence et d’auto-réparation qui s’appuient sur une communication moléculaire et sans doute aussi des formes de communication électromagnétique complexe. Je ne développerai pas ici le thème de l’intelligence organique. Qu’il suffise de signaler que certains chercheurs en biologie et en écologie parlent désormais d’une “cognition végétale”.
Le développement du système nerveux découle des nécessités de la locomotion. Il s’agit d’abord d’assurer la boucle sensori-motrice. Au cours de l’évolution, cette boucle réflexe s’est complexifiée en simulation de l’environnement, évaluation de la situation et calcul décisionnel menant à l’action. L’intelligence animale résulte d’un pli de l’intelligence organique sur elle-même puisque le système nerveux cartographie et synthétise ce qui se passe dans l’organisme et le contrôle en retour. L’expérience phénoménale naît de cette réflexion.
En effet, le système nerveux produit une expérience phénoménale, ou conscience, qui se caractérise par l’intentionnalité, à savoir le fait de se rapporter à quelque chose qui n’est pas forcément l’animal lui-même. L’intelligence animale se représente l’autre. Elle est habitée par des images sensorielles multimodales (cénesthésie, toucher, goût, odorat, audition, vue), le plaisir et la douleur, les émotions, le cadrage spatio-temporel indispensable à la locomotion, le rapport à un territoire, une communication sociale souvent complexe. Il est clair que les animaux sont capables de reconnaître des proies, des prédateurs ou des partenaires sexuels et d’agir en conséquence. Ceci n’est possible que parce que des circuits neuronaux codent des schémas d’interaction ou concepts qui orientent, coordonnent et donnent sens à l’expérience phénoménale.
L’INTELLIGENCE HUMAINE
Je viens d’évoquer l’intelligence animale, qui repose sur le système nerveux. Comment caractériser l’intelligence humaine, supportée par le codage symbolique ? Les catégories générales, concepts et schémas d’interaction qui étaient simplement codés par des circuits neuronaux dans l’intelligence animale sont maintenant aussi représentés dans l’expérience phénoménale par l’intermédiaire des systèmes symboliques, dont le plus important est le langage. Des images signifiantes (paroles, écrits, représentations visuelles, gestes rituels…) représentent des concepts abstraits et ces concepts peuvent se combiner syntaxiquement pour former des architectures sémantiques complexes.
Figure 3
Dès lors, la plupart des dimensions de l’expérience phénoménale humaine – y compris la sensori-motricité, l’affectivité, la spatio-temporalité et la mémoire – se projettent sur les systèmes symboliques et sont contrôlées en retour par la pensée symbolique. L’intelligence et la conscience humaines sont réflexives. En outre, pour que se forme cette pensée symbolique, il faut que des systèmes symboliques, qui sont toujours d’origine sociale, soient internalisés par les individus, deviennent partie intégrante de leur psychisme et s’inscrivent “en dur” dans leurs systèmes nerveux. Il en résulte que la communication symbolique embraye directement sur les systèmes nerveux humains. Nous ne pouvons pas ne pas comprendre ce que dit quelqu’un si nous connaissons la langue. Et les effets sur nos émotions et nos représentations mentales sont quasi inévitables. On pourrait également prendre l’exemple de la synchronisation psycho-physique et affective produite par la musique. C’est pourquoi la cohésion sociale humaine est au moins aussi forte que celle des animaux eusociaux comme les abeilles et les fourmis.
On remarquera que la figure 3, comme plusieurs des figures qui vont suivre, évoque un partage et une interdépendance entre virtuel et actuel. En 1995, j’ai publié un livre sur le virtuel qui était à la fois une méditation philosophique et anthropologique sur le concept de virtualité et un essai de mise au travail de ce concept sur des objets contemporains. Ma thèse philosophique est simple : ce qui n’est que possible, mais non réalisé, n’existe pas. Par contraste, ce qui n’est que virtuel mais non actualisé existe. Le virtuel, ce qui est en puissance, abstrait, immatériel, informationnel ou idéal pèse sur les situations, conditionne nos choix, provoque des effets et entre dans une dialectique ou dans un rapport d’interdépendance avec l’actuel.
L’ÉCOSYSTÈME DE L’INTELLIGENCE COLLECTIVE
La figure 4 ci-dessous cartographie les principaux pôles de l’intelligence collective humaine ou, si l’on préfère, la culture qui vient avec la pensée symbolique. Le diagramme est organisé par deux symétries qui se croisent. La première symétrie – binaire – est celle du virtuel et de l’actuel. L’actuel est plongé dans l’espace et le temps, il est plutôt concret alors que le virtuel est plutôt abstrait et n’a pas d’adresse spatio-temporelle. La seconde symétrie – ternaire – est celle du signe de l’être et de la chose, qui est inspiré du triangle sémiotique. La chose est ce que représente le signe et l’être est le sujet pour qui le signe représente la chose. A gauche (signe) se tiennent les systèmes symboliques, le savoir et la communication ; au milieu (être) se dressent la subjectivité, l’éthique et la société ; à droite (chose) s’étendent la capacité de faire, l’économie, la technique, la dimension physique. Il s’agit bien d’intelligence collective parce que les six sommets de l’hexagone sont interdépendants: les lignes vertes (les relations) sont aussi importantes, sinon plus, que les points où elles aboutissent.
Figure 4
Cette grille de lecture est valable pour la société en général mais également pour n’importe quelle communauté particulière. Au passage, virtuel, actuel, signe, être et chose sont (avec le vide) les primitives sémantiques du langage IEML (Information Economy MetaLanguage) que j’ai inventé et dont je dirai quelques mots plus bas.
Les six sommets de l’hexagone ne sont pas seulement les principaux points d’appui de l’intelligence collective humaine, ce sont aussi des univers de problèmes à résoudre:
problèmes de création de connaissance et d’apprentissage
problèmes de communication
problèmes de législation et d’éthique
problèmes sociaux et politiques
problèmes économiques
problèmes techniques, problèmes de santé et d’environnement.
Comment résoudre ces problèmes?
LE CYCLE AUTO-ORGANISATEUR DE L’INTELLIGENCE COLLECTIVE
La Figure 5 ci-dessous représente un cycle de résolution de problème en quatre étapes. Pour chacune des quatre phases du cycle (délibération, décision, action et observation), il existe un grand nombre de procédures différentes selon les traditions et les contextes où opère l’intelligence collective. Vous remarquerez que la délibération représente la phase virtuelle du cycle alors que l’action en représente la phase actuelle. Dans ce modèle, la décision fait la transition entre le virtuel et l’actuel tandis que l’observation passe de l’actuel au virtuel. Je voudrais insister ici sur deux concepts, la délibération et la mémoire, auxquels il arrive qu’on ne prête pas assez attention dans ce contexte.
Figure 5
Soulignons d’abord l’importance de la délibération, qui ne consiste pas seulement à discuter des meilleures solutions pour surmonter les obstacles mais aussi à construire et conceptualiser les problèmes de manière collaborative. Cette phase de conceptualisation va fortement impacter et même définir une bonne part des phases suivantes, elle va aussi déterminer l’organisation de la mémoire.
En effet, vous voyez sur le diagramme de la Figure 5 que la mémoire se trouve au centre du processus d’auto-organisation de l’intelligence collective. La mémoire partagée vient en appui de chacune des phases du cycle et contribue au maintien de la coordination, de la cohérence et de l’identité de l’intelligence collective. La communication indirecte par l’intermédiaire d’un environnement partagé est l’un des principaux mécanismes qui sous-tend l’intelligence collective des sociétés d’insectes, que l’on appelle la communication stigmergique dans le vocabulaire des éthologues. Mais alors que les insectes laissent généralement des traces de phéromones dans leurs environnements physiques pour guider l’action de leurs congénères, nous laissons des traces symboliques et cela non seulement dans le paysage mais aussi dans des dispositifs de mémoire spécialisés comme les archives, les bibliothèques et aujourd’hui les bases de données. Le problème de l’avenir de la mémoire numérique est devant nous : comment concevoir cette mémoire de telle sorte qu’elle soit la plus utile possible à notre intelligence collective?
VERS UNE INTELLIGENCE ARTIFICIELLE AU SERVICE DE L’INTELLIGENCE COLLECTIVE
Ayant acquis quelques notions de l’intelligence en général, des fondements de l’intelligence humaine et de la complexité de notre intelligence collective, nous pouvons maintenant nous interroger sur la relation de notre intelligence avec les machines.
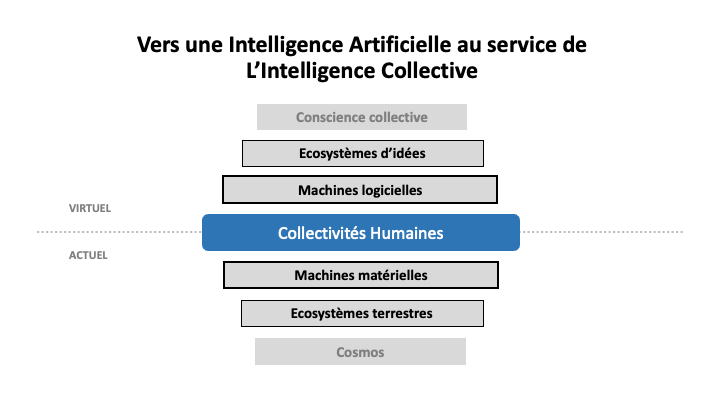
Figure 6
La figure 6 propose une vue d’ensemble de notre situation. Au milieu, le « vivant » : les populations humaines, avec les corps actuels et les esprits virtuels des individus. Immédiatement au contact des individus, les machines matérielles (ou corps mécanique) du côté actuel et, du côté virtuel, les machines logicielles (ou esprit mécanique). Les machines matérielles jouent de plus en plus un rôle d’interface ou de medium entre nous et les écosystèmes terrestres. Quant aux machines logicielles, elles sont en train de devenir le principal intermédiaire – un médium encore une fois – entre les populations humaines et les écosystèmes d’idées avec lesquelles nous vivons en symbiose. Quant à la conscience collective, nous n’y sommes pas encore. Elle représente plus un horizon, une direction d’évolution à viser qu’une réalité. Il faut comprendre la Figure 6 en y ajoutant mentalement des boucles de rétroaction ou d’interdépendance entre les couches adjacentes, entre le virtuel et l’actuel, entre le mécanique et le vivant. Sur un plan éthique, on peut faire l’hypothèse que les collectivités humaines vivantes reçoivent les bienfaits des écosystèmes terrestres et des écosystèmes d’idées en proportion du travail et du soin qu’elles apportent à leur entretien.
L’AUTOMATISATION DE L’INTELLIGENCE
Effectuons un zoom avant sur notre environnement mécanique avec la Figure 7. Une machine est un dispositif technique construit par les humains, un automate qui bouge ou fonctionne “tout seul”. Aujourd’hui les deux types de machines – logicielles et matérielles – sont interdépendantes. Elles ne pourraient pas exister l’une sans l’autre et elles sont en principe contrôlées par les collectivités humaines dont elles augmentent les capacités physiques et mentales. Parce que la technique externalise, socialise et réifie les fonctions organiques et psychiques humaines elle peut parfois paraître autonome ou à risque de s’autonomiser, mais c’est une illusion d’optique. Derrière “la machine” il faut entrevoir l’intelligence collective et les rapports sociaux qu’elle réifie et mobilise.
Figure 7
Les machines mécaniques sont celles qui transforment le mouvement, à commencer par la voile, la roue, la poulie, le levier, les engrenages, les ressorts, etc. Citons comme exemples de machines purement mécaniques les moulins à eau ou à vent, les horloges classiques, les presses à imprimer de la Renaissance ou les premiers métiers à tisser.
Les machines énergétiques sont celles qui transforment l’énergie en impliquant de la chaleur ou de l’électricité. Citons les fours, les forges, les machines à vapeur, les moteurs à explosion, les moteurs électriques, et les procédés contemporains pour produire, transmettre et stocker l’électricité.
Quand aux machines électroniques, elles contrôlent l’énergie et la matière au niveau des champs électromagnétiques et des particules élémentaires et servent bien souvent à contrôler les machines de couches inférieures dont, par ailleurs, elles dépendent. Pour ce qui nous intéresse ici, ce sont principalement les centres de données (le “cloud”), les réseaux et les appareils qui sont directement au contact des utilisateurs finaux (le “edge”) tels qu’ordinateurs, téléphones, consoles de jeux, casques de réalité virtuelle et autres.
Abordons la partie virtuelle qui correspond à la mémoire partagée que nous avions mise au centre de notre description du cycle auto-organisateur de l’action collective. Si l’échange de messages point à point a toujours lieu, la majeure part de la communication sociale s’effectue désormais de manière stigmergique dans la mémoire numérique. Nous communiquons par l’intermédiaire de la masse océanique de données qui nous rassemble. Chaque lien que nous créons, chaque étiquette ou hashtag apposée sur une information, chaque acte d’évaluation ou d’approbation, chaque « j’aime », chaque requête, chaque achat, chaque commentaire, chaque partage, toutes ces opérations modifient subtilement la mémoire commune, c’est-à-dire le magma inextricable des rapports entre les données. Notre comportement en ligne émet un flux continuel de messages et d’indices qui transforment la structure de la mémoire, contribuent à orienter l’attention et l’activité de nos contemporains et entraîne les intelligences artificielles. Mais tout cela se fait aujourd’hui d’une manière plutôt opaque, qui ne rend pas justice à la nécessaire phase de délibération et de conceptualisation consciente qui serait celle d’une intelligence collective idéale.
La mémoire comprend avant tout les données qui sont produites, retrouvées, explorées et exploitées par l’activité humaine. Les interfaces Homme-Machine représentent le “front-end” sans lequel rien n’est possible. Elles déterminent directement ce qu’on appelle l’expérience de l’utilisateur. Entre les interfaces et les données, s’interposent principalement deux types de modèles d’intelligence artificielle, les modèles neuronaux et les modèles symboliques. Nous avons vu plus haut que l’intelligence humaine « naturelle » reposait notamment sur un codage neuronal et sur un codage symbolique. Or nous retrouvons ces deux types de codage, ou plutôt leur transposition électronique, à la couche de la mémoire numérique. Remarquons que ces deux approches, neuronale et symbolique, existaient déjà aux premiers temps de l’IA, dès le milieu du XXe siècle.
Les modèles neuronaux sont entraînés sur la multitude des données numériques disponibles et ils en extraient automatiquement des patterns de patterns qu’aucun programmeur humain n’aurait pu tirer au clair. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et produire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de catégoriser correctement des formes (d’image, de texte, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. L’IA neuronale synthétise et mobilise la mémoire commune. Bien loin d’être autonome, elle prolonge et amplifie l’intelligence collective qui a produit les données. Ajoutons que des millions d’utilisateurs contribuent au perfectionnement des modèles en leur posant des questions et en commentant les réponses qu’ils en reçoivent. On peut prendre l’exemple de Midjourney, dont les utilisateurs s’échangent leurs consignes (prompts) et améliorent constamment leurs compétences en IA. Les serveurs Discord de Midjourney sont aujourd’hui les plus populeux de la planète, avec plus d’un million d’utilisateurs. On commence à observer un phénomène semblable autour de DALLE 3. Une nouvelle intelligence collective stigmergique émerge de la fusion des médias sociaux, de l’IA et des communautés de créateurs. Ce sont des exemples d’une contribution consciente de l’intelligence collective humaine à des dispositifs d’intelligence artificielle.
De nombreux modèles pré-entraînés généralistes sont open-source et plusieurs méthodes sont aujourd’hui utilisées pour les raffiner ou les ajuster à des contextes particuliers, que ce soit à partir de consignes élaborées, d’un entraînement supplémentaire avec des données spéciales ou au moyen de feed-back humain, ou d’une combinaison de ces méthodes. En somme nous disposons aujourd’hui des premiers balbutiements d’une intelligence collective neuronale, qui émerge à partir d’un calcul statistique sur les données. Observons toutefois que les modèles neuronaux, aussi utiles et pratiques qu’ils soient, ne sont malheureusement pas des bases de connaissance fiables. Ils reflètent forcément l’opinion commune et les biais que charrient les données. Du fait de leur nature probabiliste, ils commettent toutes sortes d’erreurs. Enfin, ils ne savent pas justifier leur résultats et cette opacité n’est pas faite pour inciter à la confiance. L’esprit critique est donc plus que jamais nécessaire, surtout si les données d’entrainement sont de plus en plus produites par l’IA générative, ce qui crée un dangereux cercle vicieux épistémologique.
Intéressons-nous maintenant aux modèles symboliques. On les appelle de différents noms : collections de tags ou d’étiquettes, classifications, ontologies, graphes de connaissance ou réseaux sémantique. Ces modèles peuvent se ramener à des concepts explicites et à des relations tout aussi explicites entre ces concepts, y compris des relations causales. Ils permettent d’organiser les données sur un plan sémantique en fonction des besoins pratiques des communautés utilisatrices et ils autorisent le raisonnement automatique. Avec cette approche, on obtient des connaissances fiables, explicables, directement adaptées à l’usage que l’on vise. Les bases de connaissances symboliques sont de merveilleux moyens de partage des savoirs et des compétences, et donc d’excellents outils d’intelligence collective. Le problème vient de ce que les ontologies ou graphes de connaissances sont créées “à la main”. Or la modélisation formelle de domaines de connaissance complexes est difficile. La construction de ces modèles prend beaucoup de temps à des experts hautement spécialisés et coûte donc cher. La productivité de ce travail intellectuel est faible. D’autre part, s’il existe une interopérabilité au niveau des formats de fichiers pour les métadonnées sémantiques (ou systèmes de classification), cette interopérabilité n’existe pas au niveau proprement sémantique des concepts, ce qui cloisonne l’intelligence collective. On utilise Wikidata pour les applications encyclopédiques, schema.org pour les sites web, le modèle CIDOC-CRM pour les institutions culturelles, etc. Il existe des centaines d’ontologies incompatibles d’un domaine à l’autre et souvent même au sein d’un même domaine.
Cela fait des années que de nombreux chercheurs plaident en faveur de modèles hybrides neuro-symboliques afin de bénéficier des avantages des deux approches. Mon message est le suivant: si nous voulons avancer vers une intelligence collective à support numérique digne de ce nom et qui se tienne à la hauteur de nos possibilités techniques contemporaines, il nous faut :
Renouveler l’IA symbolique en augmentant la productivité du travail de modélisation formelle et en décloisonnant les métadonnées sémantiques.
Coupler cette IA symbolique renouvelée avec l’IA neuronale en plein développement.
Mettre cette IA hybride encore inédite au service de l’intelligence collective.
IEML : VERS UNE BASE DE CONNAISSANCE SÉMANTIQUE
Nous avons automatisé et mutualisé la reconnaissance et la génération automatique de formes, qui est plutôt d’essence neuronale. Comment pouvons-nous automatiser et mutualiser la conceptualisation, qui est plutôt d’essence symbolique? Comment faire travailler ensemble la conceptualisation formelle par des êtres pensants et la reconnaissance de formes qui émerge des statistiques?
Figure 8
Parce que notre intelligence collective repose de plus en plus sur une mémoire numérique commune, cela fait trente ans que je cherche ce que pourrait être un système de coordonnées sémantiques pour la mémoire numérique, un système de métadonnées qui permettrait l’automatisation des opérations de conceptualisation et la mutualisation des modèles conceptuels.
Or la seule chose qui soit capable de générer tous les concepts que l’on voudra tout en maintenant la compréhension réciproque, c’est une langue. Mais les langues naturelles sont irrégulières, ambiguës et leur sémantique n’est pas calculable. J’ai donc construit une langue – IEML (Information Economy MetaLanguage) – dont les relations sémantiques internes sont des fonctions des relations syntaxiques. IEML est à la fois une langue et une algèbre. Cette langue est faite pour faciliter et automatiser autant que possible la construction de modèlessymboliques tout en assurant leur interopérabilité sémantique. En somme c’est un outil permettant d’automatiser et de mutualiser la conceptualisation qui a vocation à servir de système de métadonnées sémantiques universel.
Nous pouvons maintenant répondre à notre question principale : comment utiliser l’intelligence artificielle pour augmenter l’intelligence collective? Il faut imaginer un écosystème de bases de connaissances sémantiques organisées selon l’architecture décrite sur la figure 8. Vous voyez qu’entre l’interface Homme-Machine et les données s’interposent trois couches. Au centre la couche des métadonnées sémantiques organise les données sur un plan symbolique et permet, grâce à sa structure algébrique, toutes sortes de calculs uniformes de type logique, analogique et sémantique. Nous savons que la modélisation symbolique est difficile et les éditeurs d’ontologies contemporains ne facilitent pas vraiment la tâche. C’est pourquoi, sous la couche des métadonnées je propose d’utiliser un modèle neuronal pour traduire les systèmes de signes naturels en IEML et vice versa ce qui favoriserait l’édition et l’inspection la plus intuitive possible des modèles sémantiques. Entre la couche des métadonnées et celle des données se trouve encore un modèle neuronal qui permettra la génération automatique de données à partir de consignes (prompts) en IEML. En sens inverse, le modèle neuronal effectuerait la classification automatique des données et leur intégration dans le modèle sémantique de la communauté utilisatrice. Notons que les propriétés algébriques d’IEML visent notamment un perfectionnement de l’apprentissage neuronal.
L’interface Homme-Machine immersive utilisant des signes naturels permettrait à tout un chacun de collaborer à la conceptualisation des modèles au niveau des métadonnées sémantiques et de générer les données appropriées au moyen de consignes (prompts) transparentes. Enfin, cette base de connaissance automatiserait la catégorisation, l’exploitation et l’exploration multimédia des données.
Une telle approche permettrait à chaque communauté de s’organiser selon son propre modèle sémantique tout en supportant la comparaison et l’échange de concepts et de sous-modèles. En somme, un écosystème de bases de connaissances sémantiques utilisant IEML maximiserait simultanément, (1) l’augmentation de la productivité intellectuelle par l’automatisation partielle de la conceptualisation, (2) la transparence des modèles et l’explicabilité des résultats, si importantes d’un point de vue éthique, (3) la mutualisation des modèles et des données grâce à un système de coordonnées sémantique commun, (4) la diversité et la liberté créative puisque les réseaux de concepts formulés en IEML peuvent se différentier et se complexifier à volonté. Un beau programme pour l’intelligence collective. J’appelle de mes vœux une mémoire numérique qui nous permettra de cultiver des écosystèmes d’idées divers, féconds et d’en récolter le maximum de fruits pour le développement humain.
Pierre Lévy lors de la conférence du 10 Octobre 2023. Photo: Luc Courchesne.
“Ce texte propose quelques réflexions philosophiques sur la relation triangulaire entre l’intelligence collective, l’intelligence artificielle et la noble finalité de mettre la connaissance à la portée de tous.”
La valeur du savoir vérifié à l’heure de l’IA générative
Commençons par une citation de Denny Vrandečić, un des initiateurs de Wikidata, qui avait travaillé sur le graphe de connaissances de Google comme ontologiste et qui est aujourd’hui le chef de file du projet “Abstract Wikipedia”[1] visant à rendre les données des articles de Wikipédia indépendants des langues (c’est-à-dire traductibles dans toutes les langues). Denny a déclaré dans sa communication à la Knowledge Graph Conference de mai 2023[2] “In a world of infinite content, knowledge becomes valuable”. Ce monde où les contenus sont potentiellement infinis résulte évidemment de l’usage désormais massif de l’intelligence artificielle générative. Parmi tous les problèmes que posent cette nouvelle situation, citons-en deux, particulièrement prégnants du point de vue de l’accès à la connaissance. Premièrement, malgré les usages qui sont faits des modèles génératifs pour obtenir rapidement des réponses directes, il faut réaffirmer que, contrairement à l’IA symbolique classique du XXe siècle, l’IA statistique (dite aussi neuronale) d’aujourd’hui – limitée à ses seules capacités – n’offre aucune garantie de vérité. GPT4 comme les autres modèles du même genre ne sont pas des bases de connaissances. Les erreurs de fait et de raisonnement sont nombreuses et il suffit d’être spécialiste d’un domaine pour constater les faiblesses de ces IA, comme nous le faisons d’habitude lorsque nous lisons un article portant sur un de nos domaines de compétence quand il est rédigé par un journaliste pressé qui se contente de reformuler la doxa dans laquelle il baigne. Les réponses – probabilistes – de Chat GPT sont seulement vraisemblables. Deuxièmement, comme les modèles d’IA générative sont entraînés sur les données du Web et que celles-ci sont de plus en plus rédigées et illustrées par les modèles en question, on se trouve en présence d’un dangereux cercle vicieux, et cela d’autant plus que les travailleurs au rabais chargés d’aligner les modèles et de redresser leurs biais ou erreurs utilisent eux-mêmes des IA génératives pour accomplir leur tâche![3] Pour s’extraire de ces sables mouvants épistémologiques, il est donc nécessaire d’investir plus que jamais dans la construction de sources d’information fiables. En d’autres termes, l’explosion des usages de l’IA générative, loin de nous dispenser d’alimenter et d’utiliser Wikipédia, Wikidata et d’autres bases de connaissances vérifiées, rend l’effort d’y contribuer et le plaisir de les consulter encore plus nécessaires! Ceci dit, comme nous le verrons par la suite, l’IA neuronale a néanmoins vocation à jouer un rôle positif dans le partage du savoir.
Ce texte propose quelques réflexions philosophiques sur la relation triangulaire entre l’intelligence collective, l’intelligence artificielle et la noble finalité de mettre la connaissance à la portée de tous.
L’intelligence collective
Étroitement définis comme des moyens de résoudre des problèmes, les processus d’intelligence collective[4] se présentent sous de multiples formes, dont les plus étudiées sont les espèces statistique, délibérative et stigmergique[5].
Au début du XXe siècle, en Angleterre, le savant Francis Galton visitait une foire agricole. Un concours avait été organisé: on demandait aux huit cents participants, la plupart éleveurs, de deviner le poids d’un bœuf. Mais aucun d’eux n’avait trouvé le poids exact. Galton fit la moyenne de toutes les évaluations et trouva qu’elle était beaucoup plus proche du poids réel qu’aucune des estimations individuelles. La “sagesse” de la foule était supérieure à chacune des intelligences isolées[6]. Cette forme d’intelligence collective statistique – ou comptable – suppose que les individus ne communiquent pas entre eux et ne se coordonnent d’aucune manière. Elle fonctionne d’autant mieux que la distribution des choix ou des prédictions s’étend sur un large spectre, de sorte que les erreurs et les biais individuels se compensent. Ce type d’intelligence collective suppose – paradoxalement – l’ignorance mutuelle. Elle s’exprime dans les sondages ou dans les élections, lorsqu’il est interdit de communiquer les résultats partiels avant que tout le monde ait voté. Cette approche de l’intelligence collective statistique sans connexion entre ses membres a été notamment popularisée par James Surowiecki dans son livre « la Sagesse des Foules »[7]
Une seconde forme d’intelligence collective, délibérative, repose au contraire sur la communication directe entre les membres d’une communauté. Elle résulte de l’échange des arguments et des points de vue. Face à un problème commun, elle peut converger sur un consensus ou se partager entre quelques solutions dont on a – tous ensemble – pesé le pour et contre. Pourvu que l’écoute soit au rendez-vous, chacun amène son point de vue, sa compétence particulière, qui enrichit le débat général[8]. Ce type d’intelligence collective, apparemment idéale puisqu’elle est ouverte et réflexive, est d’autant plus difficile à mettre en œuvre que la collectivité est étendue. Il faut alors établir des formes de hiérarchie et de délégation, certes indispensables mais qui troublent la transparence de l’intelligence collective à elle-même.
Je voudrais maintenant introduire une forme d’intelligence collective moins connue mais qui n’en est pas moins à l’œuvre dans nombre de sociétés animales et qui a trouvé son plus haut degré d’achèvement dans l’humanité: la communication stigmergique. L’étymologie grecque explique assez bien le sens du mot « stigmergie » : des marques (stigma) sont laissées dans l’environnement par l’action ou le travail (ergon) de membres d’une collectivité, et ces marques guident en retour – et récursivement – leurs actions[9]. Le cas classique est celui des fourmis qui laissent une traîne de phéromones sur leur passage lorsqu’elles ramènent de la nourriture à la fourmilière. L’odeur des phéromones incite d’autres fourmis à remonter leurs traces pour découvrir le butin et ramener des vivres à la ville souterraine en laissant par terre à leur tour un message parfumé. Le langage confère à l’humanité un haut degré d’intelligence collective, supérieur à celui des autres mammifères et comparable à celui des abeilles ou des fourmis. Comme d’autres espèces eusociales, nous communiquons en grande partie de manière stigmergique, mais au lieu de marquer un territoire physique au moyen de phéromones ou d’autres types de signaux visuels, sonores ou olfactifs, nous laissons des traces symboliques. Au fur et à mesure de l’évolution culturelle, les signifiants s’accumulent dans des mémoires externes de plus en plus perfectionnées : pierres levées, totems, paysages sculptés, monuments, architectures, signes d’écriture, archives, bibliothèques, bases de données. On peut prétendre que toute forme d’écriture qui n’est pas précisément adressée est une forme de communication stigmergique : des traces sont déposées pour une lecture à venir et font office de mémoire externe d’une communauté.
Les différents processus d’intelligence collectives qui viennent d’être évoqués, statistique (sans communication), délibératifs (à communication directe) et stigmergique (à communication indirecte) ne sont évidemment pas exclusives l’une de l’autre et peuvent fort bien se succéder ou se combiner. Par exemple, les wikipédiens se coordonnent par l’intermédiaire de bases de données communes, délibèrent et votent.
A l’échelle de l’espèce, l’intelligence collective humaine se situe dans la continuité de l’intelligence collective animale, mais elle est plus perfectionnée à cause du langage, des techniques et des institutions politiques, économiques, légales et autres qui nous caractérisent. La principale différence entre les intelligences collectives animale et humaine tient à la culture. Dans une dimension diachronique, notre espèce est entraînée par une vitesse d’apprentissage supérieure à celle de l’évolution biologique. Nos savoir-faire s’accumulent et se transmettent d’une génération à l’autre grâce à nos mémoires externes, au moyen de systèmes de signes, de conventions sociales et d’outils. Aucun individu ne serait « intelligent » s’il n’héritait pas des connaissances créées par les ancêtres. Dans une dimension synchronique, nous participons à une intelligence collective coordonnée où résonnent et se relancent l’architecture conceptuelle de nos mémoires communes et l’organisation sociale de nos collectivités. La définition réciproque des identités et la reconnaissance des problèmes se décident à ce méta-niveau de la culture. Au-delà des procédures utiles (stigmergique, statistique et délibérative) pour résoudre des problèmes, il existe donc une intelligence collective plus holistique, qui circonscrit les capacités cognitives d’une société.
L’évolution culturelle a déjà franchi plusieurs seuils d’intelligence collective. En effet, les inventions de l’écriture, de l’imprimerie et des médias électroniques (enregistrement musical, téléphone, radio, télévision) ont déjà augmenté de manière irréversible nos capacités de mémoire et de communication sociale. Le surgissement d’une communication globale par l’intermédiaire de la mémoire numérique est probablement le plus grand changement social des vingt-cinq dernières années. Cette nouvelle forme de communication par lecture-écriture distribuée dans une mémoire numérique collective représente une mutation anthropologique de grande ampleur. Plongés dans le nouvel environnement numérique, nous interagissons par le moyen de la masse océanique de données qui nous rassemble. Les encyclopédistes de Wikipédia et les programmeurs de GitHub collaborent par l’intermédiaire d’une même base de données. A notre insu, chaque lien que nous créons, chaque étiquette ou hashtag apposée sur une information, chaque acte d’évaluation ou d’approbation, chaque « j’aime », chaque requête, chaque achat, chaque commentaire, chaque partage, toutes ces opérations modifient subtilement la mémoire commune, c’est-à-dire le magma inextricable des rapports entre les données. Notre comportement en ligne émet un flux continuel de messages et d’indices qui transforment la structure de la mémoire et contribuent à orienter l’attention et l’activité de nos contemporains. Nous déposons dans l’environnement virtuel des phéromones électroniques qui déterminent en boucle l’action des autres internautes et qui entraînent par-dessus le marché les neurones formels des intelligences artificielles (IA).
L’intelligence artificielle comme augmentation de l’intelligence collective
Abordons maintenant le thème de l’intelligence artificielle, mais sous l’angle – qui paraîtra peut-être insolite à quelques lecteurs – de l’intelligence collective. Les journalistes et le grand public ont tendance à classer dans “l’intelligence artificielle” les applications considérées comme avancées à l’époque où elles apparaissent. Mais quelques années plus tard ces mêmes applications, devenues banales et quotidiennes, seront le plus souvent réinterprétées comme appartenant à l’informatique ordinaire[10]. Par delà les titres apocalyptiques et les images de jeunes femmes au cerveau chromé censées illustrer “l’intelligence artificielle”, nous assistons depuis le milieu du XXe siècle à un processus de réification formelle et d’extériorisation des fonctions cognitives. L’augmentation de puissance et la baisse des coûts du matériel distribuent ces fonctions cognitives objectivées dans l’ensemble de la société. Des machines interconnectées enregistrent et retrouvent de l’information, effectuent des calculs arithmétiques ou algébriques, simulent des phénomènes complexes, raisonnent logiquement, respectent des syntaxes et des systèmes de règles, extraient des formes à partir de distributions statistiques enchevêtrées… L’informatique automatise et socialise nos capacités de communication, nos facultés de mémoire, de perception, d’apprentissage, d’analyse et de synthèse.
Du fait même de son nom, l’intelligence artificielle évoque naturellement l’idée d’une intelligence autonome de la machine, qui se pose en face de l’intelligence humaine, pour la simuler ou la dépasser. Mais si nous observons les usages réels des dispositifs d’intelligence artificielle, force est de constater que, la plupart du temps, ils augmentent, assistent ou accompagnent les opérations de l’intelligence humaine. Déjà, à l’époque des systèmes experts – lors des années 80 et 90 du XXe siècle – j’observais que les savoirs critiques de spécialistes au sein d’une organisation, une fois codifiés sous forme de règles animant des bases de connaissances, pouvaient être mis à la portée des membres qui en avaient le plus besoin, répondant précisément aux situations en cours et toujours disponibles. Plutôt que d’intelligences artificielles prétendument autonomes, il s’agissait de médias de diffusion des savoir-faire pratiques, qui avaient pour principal effet d’augmenter l’intelligence collective des communautés utilisatrices[11].
Dans la phase actuelle du développement de l’IA, le rôle de l’expert est joué par les foules qui produisent les données et le rôle de l’ingénieur cogniticien qui codifie le savoir est joué par les réseaux neuronaux. Au lieu de demander à des linguistes comment traduire ou à des auteurs reconnus comment produire un texte, les modèles statistiques interrogent à leur insu les multitudes de rédacteurs anonymisés du web et ils en extraient automatiquement des patterns de patterns qu’aucun programmeur humain n’aurait pu tirer au clair. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. L’IA neuronale synthétise et mobilise la mémoire commune. Bien loin d’être autonome, elle prolonge et amplifie l’intelligence collective. Des millions d’utilisateurs contribuent au perfectionnement des modèles en leur posant des questions et en commentant les réponses qu’ils en reçoivent. On peut prendre l’exemple de Midjourney, dont les utilisateurs s’échangent leurs consignes (prompts) et améliorent constamment leurs compétences en IA. Les serveurs Discord de Midjourney sont aujourd’hui les plus populeux de la planète, avec plus d’un million d’utilisateurs. Une nouvelle intelligence collective stigmergique émerge de la fusion des médias sociaux, de l’IA et des communautés de créateurs.
L’IA contemporaine fonctionne ainsi comme le conduit d’une boucle de rétroaction entre la mémoire numérique commune et les productions individuelles qui l’exploitent et s’accumulent à leur tour dans les centres de données. Derrière la machine il faut entrevoir l’intelligence collective qu’elle réifie et mobilise.
Le partage du savoir : vers une intelligence collective neurosymbolique
L’intelligence collective aujourd’hui supportée par l’intelligence artificielle n’est encore que partielle. En effet, l’utilisation des données de l’Internet pour entraîner les modèles mobilise les intelligences collectives stigmergique (la boucle de rétroaction entre les comportements individuels et la mémoire commune) et statistique (l’apprentissage neuronal). Au début des années 2020, la connexion et le renforcement mutuel de ces deux formes d’intelligence collective par les nouveaux dispositifs d’intelligence artificielle a provoqué un choc intellectuel – et des émotions fortes – chez ceux qui en ont aperçu la puissance. Mais une intelligence collective délibérative et réflexive manque encore à l’appel. A l’échelle où nous nous situons, cette intelligence collective délibérative doit porter sur l’organisation des données, c’est-à-dire sur la structure conceptuelle de la mémoire, inévitablement couplée aux pratiques des communautés. Comment faire en sorte que les réseaux de concepts qui informent la mémoire numérique puissent faire l’objet d’une conversation ouverte, transparente, attentive aux conséquences de ses choix? Le Web sémantique et son empilement de standards (XML, RDF, OWL, SPARQL) a certes établi une interopérabilité de formats, mais non pas l’interopérabilité proprement sémantique – celle des architectures de concepts – dont nous avons besoin. Les géants du web ont leurs graphes de connaissances, mais ces derniers sont malheureusement privés et secrets. Wikidata propose un exemple de graphe de connaissance ouvert, mais il est encore bien difficile à explorer et utiliser quotidiennement par le grand public. Il se présente de plus comme une ontologie, celle de l’encyclopédie Wikipédia, alors qu’il faudrait mettre en harmonie et en dialogue la multitude des ontologies qui émergent de pratiques aussi diverses que l’on voudra.
C’est pour résoudre ce problème de l’émergence d’une intelligence collective délibérative (ou réflexive) à support numérique que j’ai inventé IEML (Information Economy MetaLanguage) : une langue artificielle pourvue d’une structure algébrique régulière, dont la sémantique est calculable, qui permet de tout dire et qui peut traduire n’importe quel réseau de concept[12]. IEML est un langage à source ouverte, qui se place dans la perspective d’une augmentation des communs de la connaissance, et dont le développement doit faire l’objet d’une gouvernance décentralisée. Aussi hétérogènes ou divers qu’ils soient, IEML projette les ontologies, graphes de connaissances, collections d’étiquettes et modèles de données sur le même système de coordonnées sémantique : un univers virtuellement infini de différences conceptuelles donnant prise aux algorithmes. IEML peut servir de langage pivot entre les langues naturelles, entre les humains et les machines, entre les modèles d’IA. Il va sans dire que la plupart de ses bénéficiaires n’auront pas à l’apprendre puisque les interfaces des applications, y compris l’éditeur lui-même, seront en langues naturelles ou sous forme iconique. La face « code » d’IEML n’est destinée qu’aux ordinateurs. On peut dès lors envisager qu’une multitude de bases de connaissances aux architectures conceptuelles singulières puissent échanger des modules ontologiques et des informations grâce à l’interopérabilité sémantique assurée par ce langage de métadonnées commun.
Considérons maintenant l’idéal des lumières de mettre la connaissance à la portée de tous. Cette finalité dépasse l’objet « encyclopédie » – qui n’est finalement qu’un moyen particulier adapté aux possibilités techniques et culturelles d’une époque – pour ouvrir de vastes horizons et retentir jusque dans un avenir encore inimaginable.
Ce concept se décompose en deux exercices complémentaires: (a) celui de permettre à toutes les connaissances de s’exprimer, de s’accumuler et de communiquer ; (b) celui de faciliter l’exploration et l’appropriation des connaissances selon la gamme étendue des situations pratiques, des parcours d’apprentissage et des styles cognitifs. On voit l’affinité de cet idéal avec celui d’une intelligence collective – diamétralement opposée au “group think” – qui vise à maximiser simultanément la liberté créatrice et l’efficacité collaborative.
On pardonnera au philosophe que je suis l’évocation d’une utopie concrète, sans doute techniquement réalisable, mais qui – à court terme – vise d’abord à faire penser. Imaginons donc un dispositif destiné au partage des connaissances et qui tire le maximum des possibilités techniques contemporaines. Au cœur de ce dispositif évolue un écosystème ouvert de bases de connaissances catégorisées en IEML, qui émergent d’une multitude de communautés de recherche et de pratique. Entre ce noyau de bases de connaissances interopérables et les utilisateurs humains vivants s’interpose une interface neuronale (un écosystème de modèles) « no code » qui donne accès au contrôle, à l’alimentation, à l’exploration et à l’analyse des données. Tout se passe de manière intuitive et directe, selon les modalités sensori-motrices sélectionnées. C’est aussi par l’intermédiaire de ce giga-perceptron – un métavers immersif, social et génératif – que les collectifs échangent et discutent les modèles de données et réseaux sémantiques qui organisent leurs mémoires. En bonne gestion des connaissances, le nouveau dispositif de partage des savoirs favorise l’enregistrement des créations, accompagne les parcours d’apprentissage et présente les informations utiles aux acteurs engagés dans leurs pratiques.
Pour ce qui est commun, chaque base de connaissance – personnelle ou collective – affiche son univers de discours, ses données et ses statistiques, aussi transparente aux algorithmes qu’elle l’est aux regards humains. Mais pour ce qui est privé, notre dispositif de partage des connaissances assure la souveraineté pratique et légale des individus et des groupes sur les données qu’ils produisent et qu’ils ne divulguent qu’aux acteurs choisis.
L’augmentation décisive de la dimension délibérative de l’intelligence collective grâce à l’utilisation d’un langage de métadonnées commun a des effets multiplicateurs sur les intelligences collectives statistique et stigmergique déjà à l’œuvre aujourd’hui. Une nouvelle infrastructure neurosymbolique plonge l’intelligence collective du futur dans l’univers explorable émanant de ses propres activités cognitives. Il faut cependant bien distinguer l’intelligence collective qui anime les personnes et les collectivités humaines vivantes des extensions mécaniques et des représentations médiatiques qui l’augmentent. Ne faisons pas une idole de l’intelligence artificielle.
Citant Ibn Roshd (l’Averroes des latins), Dante écrit au chapitre I, 3 de sa Monarchie : “Le terme extrême proposé à la puissance de l’humanité est la puissance, ou vertu, intellective. Et parce que cette puissance ne peut, d’un seul coup, se réduire toute entière en acte par le moyen d’un seul homme ou d’une communauté particulière, il est nécessaire qu’il règne dans le genre humain une multitude par le moyen de laquelle soit mise en acte cette puissance toute entière.” Que cette multitude devienne transparente à elle-même dans le nouveau médium algorithmique et nous serons passés de la fourmilière à la cité.
[4] Lévy, Pierre. L’Intelligence collective. Pour une anthropologie du cyberespace. Paris: La Découverte, 1994.
[5] Voir par exemple : Baltzersen, Rolf. Cultural-Historical Perspectives on Collective Intelligence: Patterns in Problem Solving and Innovation. Cambridge, Mass: Cambridge University Press, 2022.
[6] Galton, Francis 1907, Vox populi, Nature, 75, 450-451.
[7] Surowiecki, James. The Wisdom of Crowds. Doubleday, 2004
[8] Voir par exemple : Zara, Olivier. Le chef parle toujours en dernier: Manifeste de l’intelligence collective, Axiopole, 2021, et Mulgan, Geoff. Big Mind. How Collective Intelligence Can Change Our World. Princeton: Princeton University Press, 2017.
[9] Heylighen, Francis. “Stigmergy as a Universal Coordination Mechanism I: Definition and Components.” Cognitive Systems Research 38 (2016): 4–13. https://doi.org/10.1016/j.cogsys.2015.12.002
Heylighen, Francis. “Stigmergy as a Universal Coordination Mechanism II: Varieties and Evolution.” Cognitive Systems Research, 2016, 50–59. https://doi.org/10.1016/j.cogsys.2015.12.007
[10] Lévy, Pierre. “Pour un changement de paradigme en Intelligence artificielle”, Giornale di Filosofia (Roma) numéro spécial sur Technology and Constructive Critical Thought, 15 décembre 2021
[11] Lévy, Pierre. “Les systèmes à base de connaissance comme médias de transmission de l’expertise”, Intellectica numéro spécial “Expertise et sciences cognitives”, ed. Violaine Prince. 1991. p. 187 – 219.
[12] Lévy, Pierre. La Sphère Sémantique. Computation, Cognition, Économie de l’information. Paris-London: Hermès-Lavoisier, 2011.
Comment penser la nouvelle sphère publique numérique? Je commencerai par évoquer le contexte anthropologique et démographique du basculement de la sphère publique dans l’environnement numérique. Dans un second temps, j’analyserai les nouvelles formes de mémoire et de communication supportées par le nouveau médium. J’évoquerai ensuite les figures de la domination et de l’aliénation propres à ce milieu de communication. Je terminerai, comme il se doit, par quelques perspectives d’émancipation.
1 Le contexte
Une nouvelle époque de la culture
Un des facteurs principaux de l’évolution des écosystèmes d’idées réside dans le dispositif matériel de production et de reproduction des symboles, mais aussi dans les systèmes « logiciels » d’écriture et de codage de l’information. Au cours de l’histoire, les symboles (avec les idées qu’ils portaient) ont été successivement pérennisés par l’écriture, allégés par l’alphabet et le papier, multipliés par l’imprimerie et les médias électriques.
A chaque étape, de nouvelles formes politiques sont apparues : villes, palais-temples et premiers états avec l’écriture, empires et cités avec l’alphabet ou le papier, états nations avec l’imprimerie et les médias électroniques.
Les symboles sont aujourd’hui numérisés et calculés, c’est-à-dire qu’une foule de robots logiciels – les algorithmes – les enregistrent, les comptent, les traduisent et en extraient des patterns. Les objets symboliques (textes, images fixes ou animées, voix, musiques, programmes, etc.) sont non seulement enregistrés, reproduits et transmis automatiquement, ils sont aussi générés et transformés de manière industrielle. En somme, l’évolution culturelle nous a menés au point où les écosystèmes d’idées se manifestent sous l’avatar de données animées par des algorithmes dans un espace virtuel ubiquitaire. Et c’est dans cet espace que se nouent, se maintiennent et se dénouent les liens sociaux, là que se jouent désormais les drames de la Polis…
Le basculement démographique
L’hypothèse d’une mutation anthropologique rapide et de grande ampleur se fonde sur des données quantitatives qui ne prêtent pas à controverse.
Accès aux ordinateurs
Concernant l’accès aux ordinateurs, on peut considérer que 0,1 pour cent de la population mondiale avait un accès direct à un ordinateur en 1975 (avant la révolution de l’ordinateur personnel). Cette proportion se montait à 20% dans les pays riches en 1990 (avant la révolution du Web). En 2022, pour les pays européens, la proportion oscillait entre 65% (Grèce) et 95% (Luxembourg). A noter que ces derniers chiffres ne prennent pas en compte les téléphones portables.
Accès à l’Internet
La proportion de la population mondiale qui avait accès à l’Internet était d’environ 1% en 1990 (donc avant le Web), de 4% en 1999, de 24% en 2009, de de 51% en 2018 et de 65% en 2023. Selon l’Organisation internationale des télécommunications, environ 5 milliards de personnes sont des internautes. Toujours pour 2023, mais seulement en Europe, la proportion de la population branchée à l’Internet se monte à 93% (ce sont les données de l’Union Européenne).
Prise de connaissance des nouvelles
Pour compléter ces statistiques avec des données concernant plus directement la politique, 40% des européens et 50% des américains et canadiens prennent connaissance des nouvelles par les médias sociaux (je dis bien les médias sociaux et pas l’Internet en général). On dépasse partout les 50% pour les moins de quarante ans. Pour les données spécifiques concernant la lecture des journaux par opposition à la lecture de textesen ligne, les moins de trente ans lisent les nouvelles en ligne à 80% (données du Pew Research Center).
2 Mémoire et communication numérique
La nouvelle sphère publique
En somme, moins d’un siècle après l’invention des premiers ordinateurs, plus de soixante cinq pour cent de la population mondiale est branchée à l’internet et la mémoire du monde est numérisée. Qu’une information se trouve en un point du réseau et la voici partout. Du texte statique sur papier, nous sommes passé à l’hypertexte ubiquitaire, puis à l’Architexte surréaliste qui rassemble tous les symboles. Une mémoire virtuelle s’est mise à croître, secrétée par des milliards de vivants et de morts, fourmillant de langues, de musiques et d’images, grosse de rêves et de fantasmes, mêlant la science et le mensonge. La nouvelle sphère publique est multimédia, interactive, mondiale, fractale, stigmergique et – désormais – médiée par l’intelligence artificielle.
La nouvelle sphère publique est mondiale. Aussi bien le web que les grands médias sociaux comme Facebook, Twitter, LinkedIn, Telegram, Reddit, etc. sont internationaux et multilingues. La traduction automatique a atteint un point ou l’on peut maintenant comprendre, avec quelques erreurs, ce qu’un internaute écrit dans une autre langue. J’ajoute que, parallèlement à la traduction, la synthèse automatique de longs textes progresse, ce qui ajoute à la porosité des diverses bulles cognitives et sémantiques.
La sphère publique numérique est fractale, c’est-à-dire qu’elle se subdivise en sous-groupes, eux-mêmes subdivisés en sous-groupes, et ainsi de suite récursivement, avec toutes les réunions et intersections imaginables. Ces subdivisions recoupent des distinctions de plateformes, de langues, de zones géographiques, de centres d’intérêts, d’orientations politiques, etc. On peut donner comme exemples les groupes Facebook ou LinkedIn, les serveurs Discord, les canaux YouTube ou Telegram, les communautés de Reddit, etc.
L’intelligence collective stigmergique
Si l’échange de messages point à point a toujours lieu, la majeure part de la communication sociale s’effectue désormais de manière stigmergique. La notion de stigmergie est une des clés de la compréhension du fonctionnement de la sphère publique numérique. On distingue traditionnellement trois schémas de communication : un-un, un-plusieurs et plusieurs-plusieurs. Le schéma un-un correspond au dialogue, au courrier postal classique ou au téléphone traditionnel. Le schéma un-plusieurs décrit le dispositif où un éditeur/émetteur central envoie ses messages à une masse de récepteurs dits « passifs ». Ce dernier schéma correspond à la presse, au disque, à la radio et à la télévision. Internet représente une rupture parce qu’il permet à l’ensemble des participants d’émettre pour un grand nombre de récepteurs selon un schéma en réseau décentralisé « plusieurs vers plusieurs ». Cette dernière description est néanmoins trompeuse. En effet, si tout le monde émet pour tout le monde (ce qui est le cas), tout le monde ne peut pas écouter tout le monde. Ce qui se passe en réalité est que les internautes contribuent à alimenter une mémoire commune et prennent connaissance en retour du contenu de cette mémoire par l’intermédiaire de procédures de recherche et de sélection automatisées. Ce sont les fameux algorithmes de Google, (Page Rank), de Facebook, de Twitter, d’Amazon (recommandations), etc.
L’étymologie grecque explique assez bien le sens du mot « stigmergie » : des marques (stigma) sont laissées dans l’environnement par l’action ou le travail (ergon) de membres d’une collectivité, et ces marques guident en retour – et récursivement – leurs actions. Le cas classique est celui des fourmis qui laissent une traîne de phéromones sur leur passage lorsqu’elles ramènent de la nourriture à la fourmilière. L’odeur des phéromones incite d’autres fourmis à remonter leurs traces pour découvrir le butin et ramener des vivres à la ville souterraine en laissant par terre à leur tour un message parfumé.
On peut prétendre que toute forme d’écriture qui n’est pas précisément adressée est une forme de communication stigmergique : des traces sont déposées pour une lecture à venir et font office de mémoire externe d’une communauté. Si le phénomène est fort ancien, il a pris depuis le début du siècle une nouvelle ampleur. Plongés dans la nouvelle sphère publique numérique, nous communiquons par l’intermédiaire de la masse océanique de données qui nous rassemble. Les encyclopédistes de Wikipédia et les programmeurs de GitHub collaborent par l’intermédiaire d’une même base de données. A notre insu, chaque lien que nous créons, chaque étiquette ou hashtag apposée sur une information, chaque acte d’évaluation ou d’approbation, chaque « j’aime », chaque requête, chaque achat, chaque commentaire, chaque partage, toutes ces opérations modifient subtilement la mémoire commune, c’est-à-dire le magma inextricable des rapports entre les données. Notre comportement en ligne émet un flux continuel de messages et d’indices qui transforment la structure de la mémoire et contribuent à orienter l’attention et l’activité de nos contemporains. Nous déposons dans l’environnement virtuel des phéromones électroniques qui déterminent en boucle l’action des autres internautes et qui entraînent par-dessus le marché les neurones formels des intelligences artificielles (IA).
Le rôle de l’Intelligence artificielle dans la nouvelle sphère publique
Le cerveau biologique abstrait le détail des expériences actuelles en schémas d’interactions, ou concepts, codés par des patterns de circuits neuronaux. De la même manière, les modèles neuronaux de l’IA condensent les données innombrables de la mémoire numérique. Ils virtualisent les données actuelles en patterns et en patterns de patterns. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative.
La mémoire numérique est détachée de son lieu d’émission et de réception, mise en commun, en attente de lecture, suspendue dans les “nuages” de l’Internet, logicielle. Cette masse de donnée est maintenant compressée par des modèles neuronaux. Et les patterns cachés dans les myriades de couches et de connexions des cerveaux électroniques font retomber en pluie des objets symboliques inédits. Nous ne semons des données que pour récolter du sens.
L’IA nous offre un nouvel accès à la mémoire numérique mondiale. C’est aussi une manière de mobiliser cette mémoire pour automatiser des opérations symboliques de plus en plus complexes, impliquant l’interaction d’univers sémantiques et de systèmes de comptabilité hétérogènes.
3 Le côté obscur
L’état-plateforme et la nouvelle bureaucratie dans les nuages
Si les analyses qui précèdent ont quelque validité, le pouvoir politique se joue pour une bonne part dans la sphère publique numérique. Or son contrôle ultime se trouve « dans les nuages », aux mains des bureaucraties célestes qui calculent les interactions sociales et la mémoire. Les nuages, c’est-à-dire les réseaux de centres de données possédées par l’oligopole des GAFAM, BATX et compagnie. C’est pourquoi les prétendants à l’hégémonie politique mondiale, essentiellement les américains et les chinois, s’allient avec les seigneurs des données – ou les soumettent – parce que les oligarques numériques détiennent le contrôle matériel de la mémoire mondiale et de la sphère publique. Eux seuls ont d’ailleurs la capacité de mémoire et la puissance de calcul nécessaires à l’entraînement des modèles d’IA généraux dits « fondationnels ». Ce que j’appelle un État-Plateforme résulte de l’imbrication d’une super-puissance politique avec une fraction de l’oligarchie numérique.
La bureaucratie des nuages est plus efficace que celle des états-nations, héritée de l’ère de l’imprimerie. Déjà, plusieurs fonctions gouvernementales ou régaliennes sont assurées par les grandes plateformes ou par des réseaux numériques « décentralisés ». La liste qui suit n’est pas close :
Vérification de l’identité des personnes, reconnaissance faciale
Cartographie et cadastre
Création monétaire
Régulation du marché
Éducation et recherche
Fusion de la défense et de la cyberdéfense
Contrôle de la sphère publique, censure, propagande, “nudge” (coup de pouce statitique)
Surveillance
Biosurveillance
Les médias sociaux : addictions et manipulations
Notre allégeance aux seigneurs des données vient de la puissance de leurs centres de calcul, de leur efficacité logicielle et de la simplicité de leurs interfaces. Elle trouve aussi sa source dans notre dépendance à une architecture sociotechnique toxique, qui utilise la stimulation dopaminergique et les renforcements narcissiques addictifs de la communication numérique pour nous faire produire toujours plus de données. On sait combien, de ce point de vue, la santé mentale des populations adolescentes est à risque. En plus de la biopolitique évoquée par Michel Foucault, il faut donc maintenant considérer une psychopolitique à base de neuromarketing, de données personnelles et de gamification du contrôle.
Il faut s’y faire : la Polis a basculé dans la grande base de données mondiale de l’Internet. Dès lors, les luttes de pouvoir – toutes les luttes de pouvoir, qu’elles soient économiques, politiques ou culturelles – sont reconduites et compliquées dans le nouvel espace numérique. Sur le terrain glissant des médias sociaux, les camps qui s’affrontent disposent leurs armées de trolls coordonnées en temps réel, équipées de bots dernier cri, renseignées par l’analyse automatique des données et augmentées par l’apprentissage machine. Dans la guerre civile mondiale qui fait rage, politique intérieure et extérieure inextricablement mêlées, les nouveaux mercenaires sont les influenceurs.
Mais toutes ces nouveautés n’invalident pas les règles classiques de la propagande, toujours d’actualité : répétition continuelle, simplicité des mots d’ordre, images mémorables, provocation affective et résonnance identitaire. Personne n’oublie non plus les conseils avisés de Machiavel pour amener l’ennemi à s’auto-détruire : « La guerre secrète consiste à se mettre dans la confidence d’une ville divisée, à se porter pour médiateur entre les deux partis jusqu’à ce qu’ils en viennent aux armes : et quand l’épée est enfin tirée à donner des secours prudemment dosés au parti le plus faible, autant dans le but de faire durer la guerre et de les laisser se consumer les uns par les autres, que pour se garder, par un secours trop massif, de révéler son dessein de les opprimer et de les maîtriser tous deux également. Si l’on suit soigneusement cette marche, on arrive presque toujours à son but. »[1]
La tête baissée sur nos smartphones, nous faisons tourner en boucle les stéréotypes qui renforcent nos identités éclatées et nos mémoires courtes sous le regard narquois des experts de l’intoxication, communicants stipendiés, spécialistes du marketing et agents d’influence géopolitiques…
IA et domination culturelle
Poursuivons cette revue des côtés obscurs de la nouvelle sphère publique par les enjeux de domination culturelle liés à l’Intelligence artificielle. On parle beaucoup des « biais » de tel ou tel modèle d’intelligence artificielle, comme s’il pouvait exister une IA non-biaisée ou neutre. Cette question est d’autant plus importante que, comme je l’ai suggéré plus haut, l’IA devient notre nouvelle interface avec les objets symboliques : stylo universel, lunettes panoramiques, haut-parleur général, programmeur sans code, assistant personnel. Les grands modèles de langue généralistes produits par les plateformes dominantes s’apparentent désormais à une infrastructure publique, une nouvelle couche du méta-médium numérique. Ces modèles généralistes peuvent être spécialisés à peu de frais avec des jeux de données issues d’un domaine particulier et de méthodes d’ajustement. On peut aussi les munir de bases de connaissances dont les faits ont été vérifiés.
Les résultats fournis par une IA découlent donc de plusieurs facteurs qui contribuent tous à son orientation ou si l’on préfère, à ses « biais ». a) Les algorithmes proprement dits sélectionnent les types de calcul statistique et les structures de réseaux neuronaux. b) Les données d’entraînement favorisent les langues, les cultures, les options philosophiques, les partis-pris politiques et les préjugés de toutes sortes de ceux qui les ont produites. c) Afin d’aligner les réponses de l’IA sur les finalités supposées des utilisateurs, on corrige (ou on accentue!) « à la main » les penchants des données par ce que l’on appelle le RLHF (Reinforcement Learning from Human Feed-back – en français : apprentissage par renforcement à partir d’un retour d’information humain). d) Finalement, comme pour n’importe quel outil, l’utilisateur détermine les résultats au moyen de consignes en langue naturelle (les fameux prompts). Il faut noter que des communautés d’utilisateurs s’échangent et améliorent collaborativement de telles consignes. La puissance de ces systèmes n’a d’égal que leur complexité, leur hétérogénéité et leur opacité. Le contrôle règlementaire de l’IA, sans doute nécessaire, semble difficile.
4 Perspectives d’émancipation
Littéracie numérique et pensée critique
Malgré tout ce qui vient d’être dit, la sphère publique du XXIe siècle est plus ouverte que celle du XXe siècle : les citoyens des pays démocratiques y jouissent d’une grande liberté d’expression et peuvent choisir leurs sources d’information parmi un vaste éventail de spécialisations thématiques, de langues et d’orientations politiques. Cette liberté d’expression et d’information, la nouvelle puissance distribuée de création et d’analyse de données, sans oublier les possibilités de coordination sociale offertes par le nouveau médium, tout cela ne représente que des potentialités émancipatrices. Seule une véritable éducation à la pensée critique dans le nouvel environnement de communication permettra d’actualiser ce potentiel de citoyenneté renouvelée. Pour fixer les idées, une étude de la BBC a récemment montré que 50% des jeunes gens de 12 à 16 ans croient aux nouvelles partagées sur les médias sociaux sans les vérifier. Et nous savons d’expérience que les enfants ne sont pas les seuls sujets crédules. Idéalement, la nouvelle éducation à la pensée critique devrait enseigner aux futurs citoyens à s’organiser comme de petites agences de renseignement autonomes qui rangent leurs centres d’intérêts par ordre de priorité, sélectionnent soigneusement des sources diversifiées, analysent les données à partir d’hypothèses explicites et maintiennent une classification pertinente de leur mémoire numérique personnelle. Il faut apprendre à discerner les sources de données en termes de catégories organisatrices, de récits dominants et d’agendas. On inculquera le réflexe journalistique élémentaire de croiser les sources ainsi identifiées. Enfin, les élèves devraient être entraînés à l’intelligence collective stigmergique et à l’apprentissage collaboratif.
Pour une gouvernance de la sphère publique numérique
Je me contenterai ici d’indiquer quelques grandes orientations d’une nécessaire gouvernance de la nouvelle sphère publique plutôt que de déterminer précisément les moyens d’y parvenir. Si le pilotage par gros temps peut nécessiter de nombreux détours, le cap est clair : il s’agit de perfectionner, autant que possible, la dimension réflexive d’une intelligence collective déjà en acte.
A l’appui de cette finalité, la transparence des processus en ligne semble une condition sine qua non. Je vise en particulier, mais pas seulement, une description claire, brève et en langue naturelle des algorithmes et des données d’entraînement des IA.
A l’exemple de Wikimédia, efforçons-nous de maximiser les « communs » de la connaissance.
Ouvrons les jeux de données et les algorithmes selon la voie tracée par le mouvement du logiciel libre.
Assurons la souveraineté pratique et légale des individus et des groupes sur les données qu’ils produisent.
Enfin, décentralisons la gouvernance des interactions en ligne en favorisant les procédures consensuelles. Le mouvement social qui porte la blockchain indique ici un chemin possible.
Afin d’apporter ma pierre au projet d’une intelligence collective réflexive j’ai inventé une langue (IEML, Information Economy MetaLanguage) ayant la même capacité d’expression et de traduction que les langues naturelles mais qui a aussi la régularité d’une algèbre, permettant ainsi un calcul de la sémantique. Cette langue pourrait servir de système de coordonnées sémantique à la nouvelle sphère publique. Elle contribuerait ainsi à transformer la mémoire numérique en miroir de nos intelligences collectives. Dès lors, une boucle de rétroaction plus fluide entre les écosystèmes d’idées et les communautés qui les entretiennent nous rapprocherait de l’idéal d’une intelligence collective réflexive au service du développement humain et d’une démocratie renouvelée. Il ne s’agit pas d’entretenir quelque illusion sur la possibilité d’une transparence totale, mais plutôt d’ouvrir la voie à l’exploration critique d’un univers de sens infini.
[1] Discours sur la première décade de Tite-Live. La Pléiade, Gallimard, Paris, p. 588
A mi-chemin entre l’impossible et le nécessaire, le possible est un concept logique. Par contraste, le virtuel est un mode d’être qui relève de la physique, de la biologie, de la psychologie et de la technologie. On peut le rapprocher de la notion dynamique de potentiel, quoiqu’il ne s’y réduise pas. La notion de virtuel ne se comprend que dans son opposition dialectique à l’actuel, chacun des deux concepts visant les pôles complémentaires d’un même cycle générateur. La virtualité émane des situations actuelles qu’elle conditionne en retour. A ce titre, et bien qu’il soit intangible, le virtuel existe en droit comme en fait.
Considérons l’exemple paradigmatique du gland qui contient le chêne sur un mode virtuel. La virtualité de l’arbre n’est pas une simple possibilité logique. Elle résulte d’un programme et d’un ensemble de mécanismes qui activent le développement de la plante ligneuse. L’arbre pousse à partir de la graine. Il est néanmoins impossible de prédire exactement la forme du chêne en ne considérant que le gland. Cette forme est partiellement indéterminée parce que les instructions contenues par la graine négocieront la croissance de l’arbre avec nombre de facteurs environnementaux tels que le sol, l’humidité, la lumière, la température, les symbiotes, les parasites et ainsi de suite. Bien que programmée, l’actualisation de l’arbre relève d’une adaptation créative. Si les circonstances sont favorables, l’arbre arrivé à maturation se virtualisera en une multitude de nouvelles graines qui chercheront aventure dans le monde. Vérifions ici l’une des principales propriétés du virtuel : il n’a pas d’adresse spatio-temporelle. On peut certes toucher la graine, mais pas l’arbre virtuel qu’elle promet. Nous voyons sur cet exemple végétal que la dialectique biologique du germen et du soma consonne avec celle du virtuel et de l’actuel.
LE CERVEAU ANIMAL
Passons maintenant à un exemple choisi dans le domaine de l’animalité. Lorsqu’on les compare aux plantes, la grande affaire des animaux est la locomotion, avec la boucle sensori-motrice qu’elle suppose. Le système nerveux, et le cerveau où il se concentre, s’est développé en parallèle dans les différents phylums biologiques comme une interface entre la sensation et le mouvement. Chaque élan entraîne une modification de la position de l’animal, ce qui détermine de nouvelles perceptions, qui appellent une réaction ou un repos provisoire. Au cours de l’évolution, la boucle sensori-motrice réflexe s’est complexifiée en simulation de l’environnement, évaluation de la situation et calcul décisionnel. Le virtuel devient ici un concept pratique. L’acte résout les tensions qui organisent une situation vitale et, ce faisant, il redonne naissance à un nuage de virtualités.
Intéressons-nous maintenant au rôle que joue le cerveau de l’animal dans cette dialectique pratique. Cet organe calcule l’action à accomplir et envoie ses ordres aux muscles par les nerfs efférents. Le mouvement de l’animal s’inscrit dans l’univers physique et possède certainement une adresse spatio-temporelle. Il est donc actuel. Quant à la perception, elle est calculée à partir des impulsions nerveuses venant des organes sensoriels le long des nerfs afférents. Si l’on met de côté le rêve, l’illusion et l’hallucination, la perception se rapporte au monde physique actuel. Mais peut-on dire qu’elle possède une adresse spatio-temporelle ? Selon nos connaissances scientifiques du XXIe siècle, le monde physique est peuplé de champs électromagnétiques, de vibrations atmosphériques et de molécules. Mais où se trouvent exactement la couleur bleue, les trilles du rossignol et l’odeur de la forêt en automne ? Certes, le système nerveux calcule les fameux qualia. Mais ces perceptions sont-elles dans le cerveau ? Une observation attentive de cet organe ne révèlera jamais que des concentrations de neurotransmetteurs et des dynamiques d’états d’excitations des neurones : ni coloris, ni sonorités, ni parfums. Cette remarque ne porte pas que sur les qualités sensibles, elle concerne aussi le plaisir et la douleur, les émotions, les intentions et tout ce qui constitue la vie intérieure de l’animal. L’expérience phénoménale ou, si l’on préfère, la conscience est virtuelle. Sans coordonnées spatiales, elle ne se situe pas dans le monde matériel. Tissée de mémoire et d’attente, d’habitudes et de surprises, l’expérience phénoménale ne s’inscrit pas non plus dans le temps linéaire, objectif et neutre chronométré par les sciences exactes. Elle serait plutôt temporalisante. Tendu vers un futur désiré, épais d’adhérer encore à son passé, loin de se réduire à un point sans dimension, le présent vécu entraîne le monde dans son orbite.
On pourrait objecter que l’expérience phénoménale n’est pas exactement un potentiel qui s’actualise en réalités tangibles. Sans doute. Mais observer quelque chose ici et maintenant arrive forcément dans une conscience, donc à partir du virtuel. Sans organisme animal, pas d’expérience phénoménale mais, symétriquement, l’extériorité actuelle ne se découvre que visée par une intériorité subjective, fut-ce celle d’une cigale. Actuel et virtuel sont chacun la condition de possibilité de l’autre le long d’une boucle étrange de génération ontologique.
Avec le cerveau, le concept – ou la catégorie générale – apparaît dans la nature. En effet, les animaux catégorisent leurs perceptions : voici un congénère, un rival, un partenaire sexuel, une proie, un prédateur, etc. Immanquablement, les séquences d’interactions pertinentes suivent la conceptualisation des situations et des émotions qui les teintent. Pensons aux concepts comme à des schémas d’interaction probabilistes plutôt que comme à des classes logiques nettement découpées. Ils correspondent à des circuits neuronaux plus ou moins plastiques qui mettent en relation des aires perceptives, affectives et motrices. La catégorie “prédateur”, la peur et la réaction de fuite qu’elle entraîne se trouvent codées dans un circuit neuronal du cerveau de la gazelle. Elle a donc un point d’appui dans l’actualité de l’organisme. Mais le concept de prédateur est virtuel dans la mesure même de sa généralité : il s’applique à quantité de rencontres datées et situées sans être lui-même attaché à un moment ou à un lieu précis. Il s’agit d’un schéma abstrait qui donne sens au vécu subjectif de l’animal et conduit son comportement ici et maintenant. En somme, l’expérience phénoménale – elle-même virtuelle par rapport à l’organisme actuel qui la supporte et qu’elle éclaire – se dédouble. Nous avons, d’une part, une expérience actuelle, singulière, au présent de la conscience et, d’autre part, un schéma d’interaction ou concept général, virtuel, sans qui l’expérience actuelle serait dépourvue de signification et d’orientation.
Passons maintenant de la cognition à la communication. Un animal reconnait une situation. Sa conceptualisation déclenche une libération d’hormones, une vocalisation, une posture : un signe est émis. Le concept qui organisait l’expérience actuelle de l’intérieur opaque du cerveau était déjà virtuel comparé à la situation concrète. Le voici maintenant traduit en image sensible et projeté dans le monde, à la merci d’un coup de vent, en attente du décodage d’un congénère pour s’actualiser de nouveau dans une expérience subjective. Le signal est un concept virtualisé. Les odeurs qui saturent l’atmosphère, les empreintes qui tapissent le sol, les paysages sonores des marais ou des forêts entrelacent des réseaux de signes. En un sens, la communication stigmergique est déjà une forme d’écriture. L’étymologie grecque du mot explique assez bien son sens : des marques (stigma) sont laissées dans l’environnement par l’action ou le travail (ergon) de membres d’une collectivité, et ces marques guident en retour – et récursivement – leurs actions. Le cas classique est celui des fourmis qui laissent une traîne de phéromones sur leur passage lorsqu’elles ramènent de la nourriture à la fourmilière. L’odeur des phéromones incite d’autres fourmis à remonter leurs traces pour découvrir le butin et ramener des vivres à la ville souterraine en laissant par terre à leur tour un message parfumé. On saisit l’analogie avec l’écriture : des traces sont déposées pour une lecture à venir et font office de mémoire externe d’une communauté.
Mise en commun par la communication stigmergique, cette mémoire externe est souvent brève, qu’elle soit étroitement localisée, comme le nuage de phéromones qui émane d’un attroupement d’éléphants, ou portant loin, comme le barrissement qui ponctue de sa note cuivrée la symphonie de la savane. Mais elle peut aussi être durable ou réactivée en boucle : l’urine du loup et le hurlement du singe roux marquent leur territoire. Quoiqu’il en soit, les animaux émettent et reconnaissent leurs signes en situation. Un message vise un effet pratique et se rapporte directement au contexte en cours. Performatif, son décodage déclenche quasi automatiquement l’activation d’un comportement. Métonymique, le signe fait lui-même partie du schéma d’interaction qu’il code. Indiciels, les flux de signes entretiennent une contiguïté locale ou causale avec les acteurs qui les échangent et les situations auxquels ils se rapportent.
LE CERVEAU HUMAIN
La sémiotique animale suppose des référents actuels. Voilà qui change avec l’entrée en scène d’Homo Sapiens, puisque nous racontons ce qui nous est arrivé la veille, prenons rendez-vous pour la semaine prochaine, inventons des histoires. Les référents des signes humains n’appartiennent pas nécessairement à la situation présente et nous entretenons une communication avec le monde invisible (ancêtres, esprits, dieux, valeurs…). L’animal symbolique peuple son existence d’objets et d’événements de nature intangible, ou qui ne sont plus là depuis longtemps, ou qui n’arriveront jamais.
Une langue possède généralement des milliers d’unités de sens élémentaires distinctes, ce qui est supérieur de plusieurs ordres de grandeur au répertoire de signaux des espèces animales. Surtout, les symboles s’organisent selon une grammaire récursive (les expressions peuvent s’emboîter les unes dans les autres comme des poupées russes), ce qui permet de construire et de reconnaître une quantité indéfinie de phrases et de textes pourvues de significations distinctes. Le verbe qui évoque l’action et les rôles grammaticaux qui décrivent les actants et les circonstances modélisent une “scène” complexe. Les primates parlants représentent les schémas qui organisent leur expérience avec un luxe de détail hyperréaliste. Les concepts immédiats et massifs des animaux font place aux généalogies, aux classifications fines, aux genres, aux espèces et à leurs différences, aux tissus de notions compliquées dont chaque nœud est un réseau à lui tout seul. Nos récits s’enchâssent et se répondent. Philosophes, nous dialoguons et mettons nos concepts en question. La conscience humaine ne se contente pas de s’organiser par des concepts, elle s’y réfléchit, et cette réflexion ajoute un nouveau tour à la virtualité de notre expérience.
Le symbole linguistique est coupé en deux puisqu’il possède (a) une partie actuelle ou signifiante : une image sonore, visuelle, tactile ou autre, comme le son “arbre”, et (b) une partie virtuelle ou signifiée : un concept général, comme celui de “plante ligneuse possédant des racines, un tronc et des branches”. Le signifiant lui-même se dédouble en forme abstraite (le phonème, le caractère, le geste) sans adresse, intemporelle, et une image concrète, située, datée : ce timbre de voix, cette lettre, une main qui s’agite. Quant au signifié, il possède à son tour une part virtuelle et une part actuelle. Le dictionnaire et la grammaire d’une langue définissent la partie virtuelle, générale, encore flottante, du sens d’une parole qu’on nous adresse. Notre connaissance de la langue nous permet de décoder cette séquence de phonèmes pour la traduire en réseaux de concepts, en récit suscitant des images, des émotions et des souvenirs. Un rhizome de sens illumine un instant l’opacité de notre expérience. Le sens s’est actualisé ainsi pour nous, mais il s’actualiserait différemment dans des circonstances dissemblables pour quelqu’un d’autre, pourvu d’une mémoire singulière.
Notre cerveau a toutes les propriétés de celui des vertébrés supérieurs, avec les capacités cognitives et communicatives que cela implique, mais il possède en plus une capacité de lecture et de production de symboles qui nous fait entrer dans un nouvel univers. En effet, l’évolution biologique qui mène à l’humain a profondément transformé le cerveau du primate initial pour l’ajuster à une spécialisation symbolique unique dans le règne animal : hypertrophie du cortex préfrontal, amplification du cervelet, apparition des aires de Broca et de Wernicke, division du travail plus poussée entre les hémisphères et réorganisation générale des circuits neuronaux. Le cerveau humain fonctionne alors comme un dispositif de codage-décodage entre le monde des idées et celui des corps plongés dans la biosphère. Interface ontologique, il conduit la symbiose et la coévolution des populations de bipèdes parlants et de leurs cultures. Nos sociétés se coordonnent par l’intermédiaire d’un monde virtuel des significations que nos esprits habitent en commun tandis que nos organismes interagissent actuellement dans le monde physique.
Le langage confère à l’humanité un haut degré d’intelligence collective, supérieur à celui des autres mammifères et comparable à celui des abeilles ou des fourmis. Comme d’autres espèces eusociales, nous communiquons en grande partie de manière stigmergique, mais au lieu de marquer un territoire physique au moyen de phéromones ou d’autres types de signaux visuels, sonores ou olfactifs, nous laissons des traces symboliques. Au fur et à mesure de l’évolution culturelle, les signifiants s’accumulent dans des mémoires externes de plus en plus perfectionnées : pierres levées, totems, paysages sculptés, monuments, architectures, signes d’écriture, archives, bibliothèques, bases de données.
LE CERVEAU ÉLECTRONIQUE
Sur le temps long d’une évolution culturelle qui s’accélère, les symboles se détachent de leurs lieux d’origine et survivent de mieux en mieux au moment de leur naissance. Les voici qui s’allègent, se multiplient, se diffusent, se traduisent et se transforment. Mais plus les symboles se font “soft“, logiciels, virtuels, plus ils s’approchent d’une forme omniprésente et malléable échappant à l’inertie de la matière, plus leur inscription nécessite de supports “hard”, d’instruments et d’installations lourdement actuelles. La manipulation symbolique relève d’une longue histoire technique où la virtualisation des codes et l’actualisation des médias s’entraînent mutuellement : tablettes d’argile, rouleaux de papyrus ou de soie, réseaux de routes et de ports des empires antiques, poste à cheval, fabrication du papier, machines à imprimer, bâtiments des écoles et des bibliothèques, transports mécanisés, poteaux télégraphiques au bord des voies ferrées, antennes et satellites, jusqu’aux centres de données qui consomment l’électricité d’une centrale et aux magazines, radios, tourne-disques, télévisions, ordinateurs et téléphones crachés par des usines qui finissent par s’entasser pêle-mêle dans des décharges.
Le virtuel et l’actuel alternent, se compénètrent et compliquent leur enchevêtrement. Chaque circuit de leur tourbillon auto-poïétique dépose une nouvelle couche de complexité qu’entraîne la révolution suivante. Il en est de ces deux modes d’être comme des rapports du Yin et du Yang dans la philosophie chinoise traditionnelle. Un des principaux classiques confucéens, le Yi-King (ou I-Ching) représente la dynamique des transformations cosmiques, politiques et personnelles au moyen de soixante-quatre hexagrammes : six lignes empilées dont certaines sont continues (Yang) et d’autres brisées (Yin). Ce vieux livre oraculaire présente un des premiers alignements entre structure signifiante et situation signifiée : les deux plans des hexagrammes et des configurations pratiques obéissent au même groupe de transformations. Faut-il faire remonter là le codage binaire et la manipulation réglée des signifiés au moyen des signifiants qui caractérise l’informatique ? Ou bien faut-il identifier les débuts du calcul automatique à la formalisation du raisonnement logique par Aristote ? Et que dire des mathématiciens indiens qui ont inventé la numération par position avec neuf chiffres et le zéro, rendant ainsi les calculs arithmétiques simples et uniformes ? Ou du développement de l’algèbre par les mathématiciens arabophones, andalous ou persans, comme Al Khawarizmi, qui a donné son nom à l’algorithme ? Dans tous ces cas, la manipulation réglée, quasi-mécanique, d’éléments visibles et tangibles – donc actuels – entraîne un mouvement d’objets virtuels : tropismes politiques, propositions logiques ou nombres insubstantiels.
Pendant les années cinquante du XXe siècle, on qualifiait les ordinateurs de “cerveaux électroniques”. Des machines à calculer mécaniques avaient été construites dès le XVIIe siècle par Pascal et Leibniz. Charles Babbage et Ada Lovelace ont construit des prototypes de machines à calculer complexes dans la Grande-Bretagne victorienne. Les caisses enregistreuses présentes dans de nombreuses boutiques effectuaient les opérations arithmétiques au début du XXe siècle. Mais pour atteindre des calculatrices électroniques programmables – beaucoup plus rapides et adaptables que les machines précédentes – il a fallu que plusieurs progrès théoriques et techniques soient accomplis au préalable. Du côté théorique, Turing avait dès 1937 décrit un automate abstrait capable d’effectuer n’importe quel calcul défini par un programme. Du côté technique, dès le début du XXe siècle, les diodes, ou tubes à vide, ont permis le contrôle fin des flux d’électrons. Utilisés par les premiers ordinateurs, ces composants volumineux et grands consommateurs d’énergie seront ensuite remplacés par les transistors, puis par les circuits imprimés dans la course à la vitesse et à la miniaturisation qui marque l’industrie électronique. Un pas décisif fut franchi par Claude Shannon en 1938, lorsqu’il démontra la corrélation entre le calcul logique et l’arrangement des circuits électriques, à la confluence du virtuel et de l’actuel. Un interrupteur ouvert ou fermé correspond à “vrai” ou “faux”, un montage des interrupteurs en série correspond à l’opérateur logique “et”, un montage en parallèle à l’opérateur “ou exclusif”. Or les connecteurs non, et, ou suffisent à exprimer l’algèbre de Boole, à savoir la formalisation de la logique ordinaire. L’arithmétique en base deux (0, 1) se prête également fort bien au calcul électronique. Traversant les portes logiques, courant dans le labyrinthe de circuits que forment et reforment les programmes, rapide comme l’éclair, l’électron devient signifiant. Automatiser la manipulation du sens virtuel en mécanisant celle du signe actuel, telle est la puissance du codage informatique.
Moins d’un siècle après l’invention des premiers ordinateurs, la mémoire du monde est numérisée et plus de soixante pour cent de la population mondiale est branchée à l’internet. Qu’une information se trouve en un point du réseau et la voici partout. Du texte statique sur papier, nous sommes passé à l’hypertexte ubiquitaire, puis à l’architexte surréaliste qui rassemble tous les symboles. Une mémoire virtuelle s’est mise à croître, secrétée par des milliards de vivants et de morts, fourmillant de langues, de musiques et d’images, grosse de rêves et de fantasmes, mêlant la science et le mensonge. Si l’échange de messages point à point a toujours lieu, la majeure part de la communication sociale s’effectue désormais de manière stigmergique. Plongés dans l’espace numérique, nous communiquons par l’intermédiaire de la masse océanique de données qui nous rassemble. Chaque lien que nous créons, chaque étiquette ou hashtag apposée sur une information, chaque acte d’évaluation ou d’approbation, chaque « j’aime », chaque requête, chaque achat, chaque commentaire, chaque partage, toutes ces opérations modifient subtilement la mémoire commune, c’est-à-dire le magma inextricable des rapports entre les données. Notre comportement en ligne émet un flux continuel de messages et d’indices qui transforment la structure de la mémoire et contribuent à orienter l’attention et l’activité de nos contemporains. Nous déposons dans l’environnement virtuel des phéromones électroniques qui déterminent en boucle l’action des autres internautes et qui entraînent par-dessus le marché les neurones formels des intelligences artificielles (IA).
Le cerveau biologique abstrait le détail des expériences actuelles en schémas d’interactions, ou concepts, codés par des patterns de circuits neuronaux. De la même manière, les modèles neuronaux de l’IA condensent les données innombrables de la mémoire numérique. Ils virtualisent les données actuelles en patterns et en patterns de patterns. Conditionnés par leur entraînement, les algorithmes peuvent alors reconnaître et reproduire des données correspondant aux formes apprises. Mais parce qu’ils ont abstrait des structures plutôt que de tout enregistrer, les voici capables de conceptualiser correctement des formes (d’image, de textes, de musique, de code…) qu’ils n’ont jamais rencontrées et de produire une infinité d’arrangements symboliques nouveaux. C’est pourquoi l’on parle d’intelligence artificielle générative. La mémoire numérique est virtuelle parce qu’elle est détachée de son lieu d’émission et de réception, mise en commun, en attente de lecture, suspendue dans les “nuages” de l’Internet, logicielle. Mais cette mémoire apparaît désormais comme une masse de données actuelles que virtualisent des modèles neuronaux. Et les patterns cachés dans les myriades de couches et de connexions des cerveaux électroniques font retomber en pluie des actualisations inédites. Nous ne semons des données que pour récolter du sens.
Le calcul électronique qui simule le fonctionnement des neurones donne-t-il naissance à une conscience autonome ? Non, parce que les machines manipulent seulement la partie matérielle des symboles et que les images, les textes, les mélodies n’ont de signification que pour nous lorsqu’elles sont émises aux interfaces. Non, parce que l’expérience phénoménale est la contrepartie d’un organisme animal. Les humains sensibles et intelligents n’ont une âme que parce qu’ils habitent un corps vivant. De l’autre côté du miroir, les signifiants tourbillonnent à l’aveugle, les galets s’entrechoquent sur le grand abaque, une furie électronique insensée se déchaîne dans les centres de données. De ce côté du miroir, les écrans nous présentent le visage d’un autre qui parle, mais c’est une projection anthropomorphe. Une bibliothèque ne se souvient pas plus qu’un algorithme ne pense : les deux virtualisent des fonctions cognitives par externalisation, transformation, mise en commun et ré-internalisation. Les nouveaux cerveaux électroniques synthétisent et mettent à l’œuvre – virtualisent et réactualisent – l’énorme mémoire numérique par l’intermédiaire de laquelle nous nous souvenons, communiquons et pensons ensemble. Derrière “la machine” il faut entrevoir l’intelligence collective qu’elle réifie et mobilise.
La crainte du virtuel qui agitait les esprits lors de la première édition de “Qu’est-ce que le Virtuel?” en 1995 (alors qu’à peine un pour cent de la population mondiale était connectée à l’Internet et que le World Wide Web venait d’éclore), s’est transformée aujourd’hui en grande peur de l’intelligence artificielle. Ni fin de la civilisation, ni fin de l’humanité, il s’agit encore d’une nouvelle étape de l’évolution culturelle, de la poursuite d’une hominisation, d’une virtualisation que nous devons penser avec justesse si nous voulons l’orienter.
IEML est une langue (mathématique) dont la finalité principale est de formaliser la description des concepts et de leurs connexions. On s’en servira pour produire des modèles de données, des systèmes de métadonnées sémantiques, des ontologies, des graphes de connaissances et autres réseaux sémantiques. Je dis que cette langue est “mathématique” parce que les nœuds conceptuels (les entités) et les relations – représentés par des phrases IEML – peuvent être générés de manière fonctionnelle et parce que cette langue non ambiguë instaure une bijection entre séquences de caractères (ou chaines phonétiques) et réseaux de concepts. Le grand avantage d’IEML est de rendre les différentes ontologies ou modèles de données sémantiquement compatibles puisque tous les concepts sont construits au moyen du même dictionnaire compact en utilisant la même grammaire régulière.
IEML ne vise pas principalement les sciences exactes, qui disposent déjà d’une formalisation mathématique adéquate et d’une conceptualisation univoque, mais plutôt les sciences humaines, dont la formalisation et la calculabilité laissent à désirer. À noter que l’ingénierie (notamment la documentation de systèmes complexes) et la médecine sont néanmoins des cas d’usages favorables.
COMMENT CONSTRUIRE UN CONCEPT EN IEML?
Pour construire un concept en IEML, il faut utiliser sa grammaire, résumée dans la figure ci-dessous.
Structure et composants de la phrase IEML, illustrés par un exemple
Après avoir pris connaissance de la grammaire, il faut se donner une définition du concept à construire. Voici ci-dessous une définition possible de la démocratie qui utilise la structure de la phrase en IEML.
@node fr: démocratie en: democracy ( 0 verbe: exercer le pouvoir 1 sujet: tous les citoyens 2 objet: unité politique / cité 4 cause/instrument: suffrage universel 7 intention/contexte: régime politique 8 manière: séparation des pouvoirs et protection des minorités ).
Beaucoup d’autres définitions IEML de la démocratie sont possibles, plus simples, plus complexes ou différentes, mais elles seront toutes explicites et on pourra les comparer.
Pour la définition que nous avons proposée, les concepts nécessaires existent déjà dans le dictionnaire IEML pour les rôles 0, 1, 2 et 7, mais pas pour les rôles 4 et 8. Il faut donc créer les concepts de suffrage universel, de séparation des pouvoirs et de protection des minorités. Ici encore, les définitions ci-dessous auraient pu être différentes. Chaque @node créé peut être réutilisé comme un #concept!
@node fr: protection des minorités en:protection of minorities ( 0 ~indicatif #protéger un groupe, 2 #minorités ).
Voici finalement un concept possible de démocratie formellement défini en IEML.
@node fr: démocratie en: democracy ( 0 #exercer le pouvoir, 1 ~tous #citoyen, 2 #unité politique, 4 *instrument #suffrage universel, 7 *se référant à #organisation politique, 8 *avec &et [ #séparation des pouvoirs #protection des minorités] ).
REMARQUES FINALES
À noter que, pour une utilisation concrète dans une ontologie, on ne construit jamais les concepts isolément (un par un) en IEML mais toujours dans des paradigmes ou champs sémantiques. Dans une ontologie des sciences politiques, un paradigme des régimes politiques conserverait les rôles 0-verbe, 2-objet et 7-contexte/intention, mais ferait varier les rôles 1-sujet, 4-cause/instrument et 8-manière. On construirait ainsi une matrice en 3 dimensions qui pourrait être représentée par plusieurs tables 2 D.
Par ailleurs, le sens (ou sémantique) d’un concept ne se réduit pas à sa définition. Il faut aussi prendre en compte le contexte d’utilisation, c’est-à-dire le réseau de relations auquel renvoie le concept dans une ontologie ou graphe de connaissances.
Pour naviguer dans le dictionnaire IEML et les débuts d’ontologies, aller à https://ieml.intlekt.io/login , choisir « read without account » puis « published projects ». Explorer le menu contextuel pour chaque mot, en particulier la visualisation de la table paradigmatique à laquelle le mot appartient.
[For an English version of this post, click here.]
Le langage permet une coordination dynamique entre les réseaux de concepts entretenus par les membres d’une communauté, de l’échelle d’une famille ou d’une équipe, jusqu’aux plus grandes unités politiques ou économiques. Il permet également de raconter des histoires, de dialoguer, de poser des questions et de raisonner. Le langage soutient non seulement la communication mais aussi la pensée ainsi que l’organisation conceptuelle de la mémoire, complémentaire de son organisation émotionnelle et sensorimotrice.
Mais comment le langage fonctionne-t-il ? Du côté de la réception, nous entendons une séquence de sons que nous traduisons en un réseau de concepts, conférant ainsi son sens à une proposition. Du côté de l’émetteur, à partir d’un réseau de concepts que nous avons à l’esprit – un sens à transmettre – nous générons une séquence de sons. Le langage fonctionne comme une interface entre des séquences de sons et des réseaux de concepts. Et gardons en tête que les relations entre les concepts sont eux-mêmes des concepts.
Les chaînes de phonèmes (des sons), peuvent être remplacées par des séquences d’idéogrammes, de lettres, ou de gestes comme dans le cas de la langue des signes. L’interfaçage quasi-automatique entre une séquence d’images sensibles (sonores, visuelles, tactiles), et un graphe de concepts abstraits (catégories générales) reste constant parmi toutes les langues et systèmes d’écriture.
Cette traduction réciproque entre une séquence d’images (le signifiant) et des réseaux de concepts (le signifié) suggère qu’une categorie mathématique pourrait modéliser le langage en organisant une correspondance entre une algèbre et une structure de graphe. L’algèbre réglerait les opérations de lecture et d’écriture sur les textes, tandis que la structure de graphe organiserait les opérations sur les nœuds et les liens orientés. A chaque texte correspondrait un réseau de concepts. Les opérations sur les textes reflèteraient dynamiquement les opérations sur les graphes conceptuels.
Nous avons besoin d’un langage régulier pour coder des chaînes de signifiants et nous pouvons transformer les séquences de symboles en arbres syntagmatiques (la syntaxe étant l’ordre du syntagme) et vice versa. Cependant, si son arbre syntagmatique – sa structure grammaticale interne – est indispensable à la compréhension du sens d’une phrase, il n’est pas suffisant. Parce que chaque expression linguistique repose à l’intersection d’un axe syntagmatique et d’un axe paradigmatique. L’arbre syntagmatique représente le réseau sémantique interne d’une phrase, l’axe paradigmatique représente son réseau sémantique externe et en particulier ses relations avec des phrases ayant la même structure, mais dont elle se distingue par quelques mots. Pour comprendre la phrase ” Je choisis le menu végétarien “, il faut bien sûr reconnaître que le verbe est “choisir”, le sujet “je” et l’objet “le menu végétarien” et savoir en outre que “végétarien” qualifie “menu”. Mais il faut aussi reconnaître le sens des mots et savoir, par exemple, que végétarien s’oppose à carné et à végétalien, ce qui implique de sortir de la phrase pour situer ses composantes dans les systèmes d’oppositions sémantiques de la langue. L’établissement de relations sémantiques entre concepts suppose que l’on reconnaisse les arbres syntagmatiques internes aux phrases, mais aussi les matrices paradigmatiques externes à la phrase qui organisent les concepts, que ces matrices soient propres à une langue ou à certains domaines pratiques.
Parce que les langues naturelles sont ambiguës et irrégulières, j’ai conçu une langue mathématique (IEML) traduisible en langues naturelles, une langue calculable qui peut coder algébriquement non seulement les arbres syntagmatiques, mais aussi les matrices paradigmatiques où les mots et les concepts prennent leur sens. Chaque phrase du métalangage IEML est située précisément à l’intersection d’un arbre syntagmatique et de matrices paradigmatiques.
Sur la base de la grille syntagmatique-paradigmatique régulière d’IEML, il devient possible de générer et de reconnaître des relations sémantiques entre concepts de manière fonctionnelle : graphes de connaissance, ontologies, modèles de données… Toujours du côté de l’IA, un codage des étiquettes ou de la catégorisation des données dans cette langue algébrique qu’est IEML faciliterait l’apprentissage machine. Au-delà de l’IA, ma vision pour IEML est de favoriser l’interopérabilité sémantique des mémoires numériques et de développer une synergie entre l’autonomisation cognitive personnelle et la réflexivité de l’intelligence collective.
Sur le plan technique, il s’agit d’un projet léger et décentralisé: un dictionnaire IEML-langues naturelles, un analyseur syntaxique (parseur) open-source supportant les fonctions calculables sur les expressions de la langue et une plate-forme d’édition collaborative et de partage des concepts et ontologies. Le développement, la maintenance et l’utilisation d’un protocole sémantique basé sur l’IEML nécessitera un effort de recherche et de formation à long terme.